

Elastic Stack (wcześniej znany jako ELK Stack) to potężne rozwiązanie do scentralizowanego logowania. Jest to kolekcja oprogramowania open-source opracowana przez Elastic. Umożliwia administratorom wyszukiwanie, analizowanie i wizualizację logów generowanych z dowolnego źródła w dowolnym formacie. Jest to praktyka znana jako scentralizowane logowanie. Scentralizowane logowanie może być bardzo przydatne podczas próby precyzyjnego zlokalizowania problemów z serwerami i aplikacjami, ponieważ umożliwia przeszukiwanie wszystkich logów z jednego miejsca. Może również pomóc w identyfikacji problemów na wielu serwerach poprzez korelację logów w określonym czasie.
W tym poradniku dowiesz się, jak zainstalować Elastic Stack na Ubuntu 18.04. Najpierw postępuj zgodnie z naszym samouczkiem, aby łatwo zainstalować swój serwer Ubuntu na CloudSigma.
Elastic Stack na Ubuntu
Elastic Stack składa się z następujących komponentów:
- Elasticsearch: rozproszony silnik wyszukiwania RESTful. Przechowuje wszystkie zebrane dane.
- Logstash: Element przetwarzający dane w Elastic Stack. Przesyła przychodzące dane do Elasticsearch.
- Kibana: Interfejs webowy oferujący funkcje wyszukiwania i wizualizacji logów.
- Beats: Lekki transmiter danych o jednym przeznaczeniu. Może wysyłać dane z wielu maszyn do Logstash lub Elasticsearch.
Będziesz musiał ręcznie zainstalować każdy komponent stosu.
Wymagania wstępne
Przed przystąpieniem do instalacji Elastic Stack, należy spełnić kilka wymagań systemowych:
- Wymagania sprzętowe:
- Procesor: 2 procesory (dostępne dla użytkownika sudo innego niż root)
- RAM: 4GB
- OpenJDK 11 (najnowsze wydanie Java LTS). Aby je zainstalować, zapoznaj się z naszym samouczkiem dotyczącym konfiguracji Javy na Ubuntu 18.04.
- Nginx z odpowiednią konfiguracją. Możesz postępować zgodnie z naszym poradnikiem instalacji Nginx na Ubuntu 18.04, aby go skonfigurować.
Pamiętaj, że ilość miejsca na dysku zależy od liczby zbieranych i przechowywanych logów. Ponadto Elastic Stack przetwarza również cenne informacje o serwerze. Aby zapewnić bezpieczeństwo transmisji danych, zdecydowanie zalecamy skonfigurowanie certyfikatu TLS/SSL. Postępuj zgodnie z tym samouczkiem, aby uzyskać bezpłatny certyfikat SSL na swoim serwerze Nginx.
Oprócz zaszyfrowanego serwera konieczne będą również następujące kroki:
- FQDN (w pełni kwalifikowana nazwa domeny). W tym poradniku będzie to <domain>.
- Oba rekordy DNS następujących domen wskazują na serwer.
- Rekord A z <domain> wskazujący na publiczny adres IP serwera.
- Rekord A z www.<domain> wskazujący na publiczny adres IP serwera.
Instalacja Elastic Stack
-
Konfiguracja repozytorium Elastic
Komponenty Elastic Stack nie są dostępne bezpośrednio z oficjalnego repozytorium Ubuntu. Na szczęście Ubuntu pozwala na zewnętrzne repozytoria do instalacji pakietów. W naszym przypadku dodamy repozytorium pakietów Elastic. Repozytorium to oferuje najnowsze aktualizacje wszystkich pakietów Elastic. Wszystkie pakiety Elastic są podpisane kluczem podpisywania Elasticsearch, aby zapobiec fałszowaniu pakietów. Najpierw dodaj klucz do bazy kluczy Ubuntu:
|
1 |
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - |
Następnie dodaj listę źródeł Elastic w katalogu „sources.list.d”. Jest to dedykowany katalog, którego APT używa do wyszukiwania nowych źródeł:
|
1 |
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list |
Na koniec zaktualizuj pamięć podręczną APT:
|
1 |
sudo apt update |
Zgodnie z oficjalną dokumentacją zaleca się instalację każdego z komponentów w kolejności przedstawionej w tym poradniku. Zapewnia to, że komponenty, od których zależy każdy produkt, znajdują się we właściwym miejscu.
-
Instalacja i konfiguracja Elasticsearch
Po skonfigurowaniu repozytorium Elastic, APT jest gotowy do pobrania i zainstalowania wszystkich pakietów Elastic. Uruchom następujące polecenie, aby zainstalować Elasticsearch:
|
1 |
sudo apt install elasticsearch |
Teraz możesz skonfigurować Elasticsearch. Plik „elasticsearch.yml” zawiera opcje konfiguracyjne dotyczące klastrów, węzłów, ścieżek, sieci, pamięci, bramy i innych. Większość z nich jest wstępnie skonfigurowana w pliku. Następnie otwórz plik konfiguracyjny Elasticsearch za pomocą wybranego edytora tekstu:
|
1 |
sudo vim /etc/elasticsearch/elasticsearch.yml |
Elasticsearch nasłuchuje na porcie 9200 z dowolnego miejsca. Zalecamy ograniczenie dostępu zewnętrznego do Elasticsearch, aby uniemożliwić osobom postronnym odczytywanie danych lub wyłączanie klastrów Elasticsearch za pomocą interfejsu REST API. Aby ograniczyć dostęp do Elasticsearch i zwiększyć jego bezpieczeństwo, odkomentuj poniższą linię i zastąp jej wartość:
|
1 |
network.host: localhost |
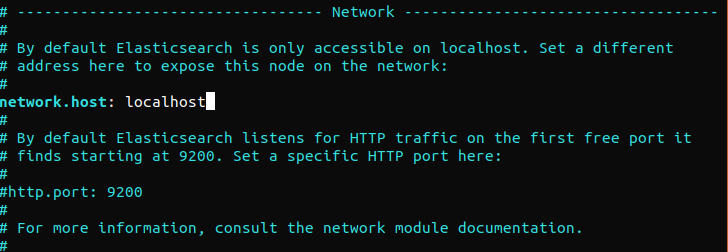
Jeśli Elasticsearch ma nasłuchiwać na określonym adresie IP, zastąp „localhost” docelowym adresem IP. Jest to minimalne wymaganie konfiguracyjne przed uruchomieniem Elasticsearch. Zapisz i zamknij plik konfiguracyjny. Następnie uruchom usługę Elasticsearch. Uruchomienie Elasticsearch może zająć chwilę:
|
1 |
sudo systemctl start elasticsearch |
Następnie musisz upewnić się, że Elasticsearch uruchamia się przy każdym uruchomieniu serwera:
|
1 |
sudo systemctl enable elasticsearch |
Poniższe polecenie zweryfikuje, czy usługa Elasticsearch działa. Wymaga ono jedynie wysłania żądania HTTP:
|
1 |
curl -X GET "localhost:9200" |
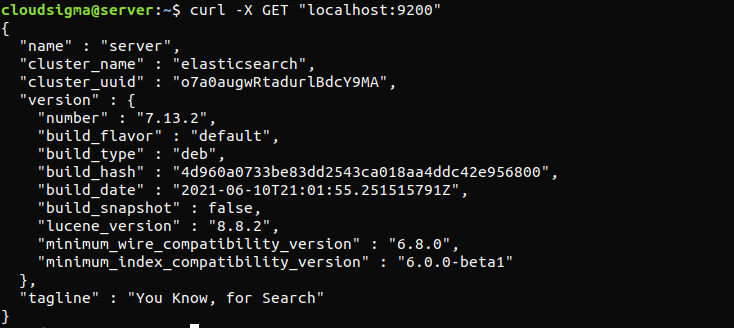
Odpowiedź będzie wyglądać mniej więcej tak. Będzie to odpowiedź pokazująca podstawowe informacje o lokalnym węźle.
Instalacja i konfiguracja panelu Kibana
Kibana jest bezpośrednio dostępna z repozytorium Elastic. Pamiętaj, że powinieneś zainstalować Kibanę dopiero po zainstalowaniu Elasticsearch. Zakładając, że repozytorium jest już dostępne, APT może bezpośrednio pobrać i zainstalować Kibanę:
|
1 |
sudo apt install kibana |
Po zainstalowaniu włącz i uruchom usługę Kibana:
|
1 2 |
sudo systemctl enable kibana sudo systemctl start kibana |
Domyślnie Kibana jest skonfigurowana tak, aby nasłuchiwać tylko na „localhost”. W przypadku dostępu zewnętrznego wymaga ona konfiguracji odwrotnego serwera proxy. W tym przypadku Nginx będzie odwrotnym serwerem proxy. Użyj polecenia openssl do utworzenia administratora Kibany. Będzie to konto użytkownika służące do uzyskiwania dostępu do interfejsu internetowego Kibana. W tym przykładzie nazwą użytkownika będzie „kibana_admin”. Aby zapewnić lepsze bezpieczeństwo, zalecamy użycie niestandardowej nazwy użytkownika. Poniższe polecenie utworzy użytkownika administratora dla Kibany. Nazwa użytkownika i hasło zostaną wygenerowane i zapisane w pliku „htpasswd.users”. Nginx będzie musiał zostać skonfigurowany do korzystania z tej nazwy użytkownika i hasła:
|
1 |
echo "kibana_admin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users |
Wprowadź i potwierdź hasło w monicie. To hasło będzie ważne przy uzyskiwaniu dostępu do interfejsu Kibana. Następnie musisz utworzyć plik bloku serwera Nginx. Na potrzeby demonstracji będzie to example.com. Może to być również dowolna inna opisowa nazwa. Jeśli dla serwera skonfigurowano rekordy FQDN i DNS, nazwa pliku może również odpowiadać FQDN:
|
1 |
sudo vim /etc/nginx/sites-available/example.com |
Jeśli istnieje już jakaś zawartość, usuń ją i zastąp poniższymi liniami kodu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
server { listen 80; server_name example.com; auth_basic "Restricted Access"; auth_basic_user_file /etc/nginx/htpasswd.users; location / { proxy_pass http://localhost:5601; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } } |
Zapisz i zamknij plik. Utwórz dowiązanie symboliczne nowej konfiguracji w katalogu „sites-enabled”. Jeśli istnieje już powiązanie o tej samej nazwie pliku, ten krok może nie być konieczny:
|
1 |
sudo ln -s /etc/nginx/sites-available/example.com /etc/nginx/sites-enabled/example.com |
Poniższe polecenie skłoni serwer Nginx do sprawdzenia, czy nie ma błędów składniowych:
|
1 |
sudo nginx -t |
Jeśli wystąpią jakiekolwiek problemy ze składnią, upewnij się, że zawartość pliku została poprawnie umieszczona. Następnie zrestartuj usługę Nginx:
|
1 |
sudo systemctl restart nginx |
Zezwól w UFW na połączenia z Nginx:
|
1 |
sudo ufw allow 'Nginx Full' |
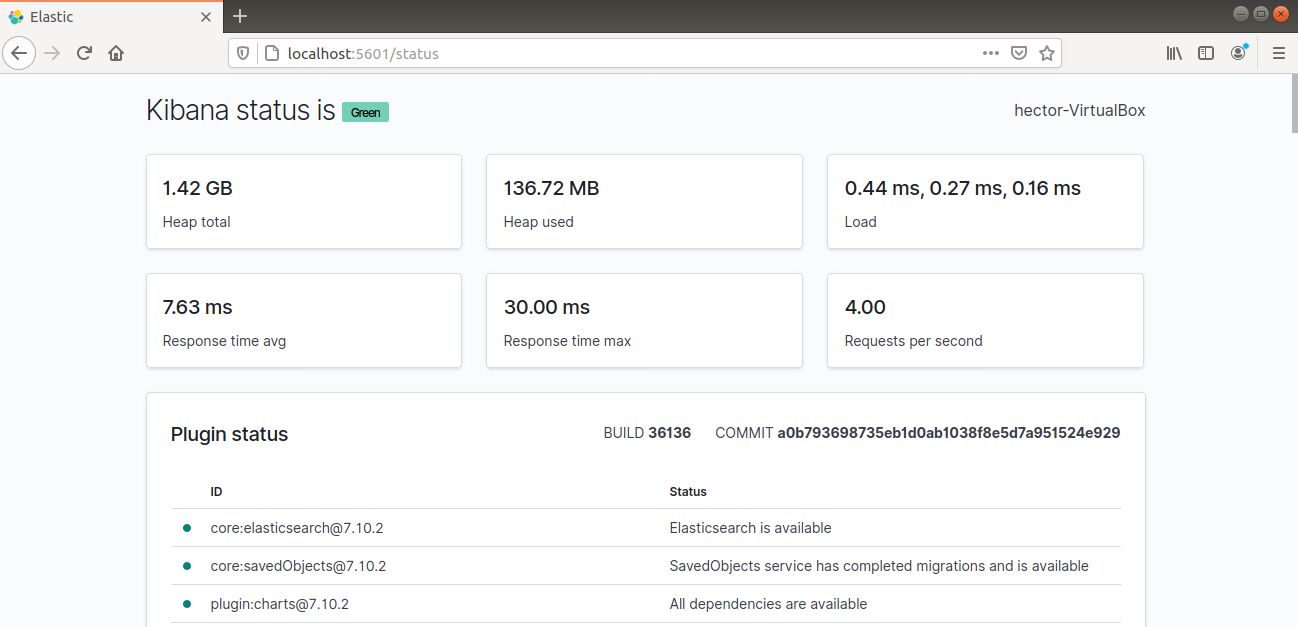
Kibana powinna być teraz dostępna za pośrednictwem FQDN lub publicznego adresu IP serwera Elastic Stack. Sprawdź stronę statusu serwera Kibana:
|
1 |
http://<server_ip>:5601/status |
Instalacja i konfiguracja Logstash
Podczas gdy Beats może bezpośrednio wysyłać dane do bazy danych Elasticsearch’a, zaleca się używanie Logstash do przetwarzania danych. Logstash może zbierać dane i konwertować je do wspólnego formatu przed wyeksportowaniem do innej bazy danych. Uruchom następujące polecenie APT, aby zainstalować Logstash:
|
1 |
sudo apt install logstash |
Po zakończeniu instalacji nadszedł czas na konfigurację Logstash. Pliki konfiguracyjne Logstash są w formacie JSON. Wszystkie z nich można znaleźć w katalogu „/etc/logstash/conf.d”. Pomocne jest myślenie o Logstash jako o potoku, który pobiera dane z jednego końca, przetwarza je i wysyła do miejsca docelowego. Potok Logstash wymaga dwóch obowiązkowych elementów – input oraz output z jednym opcjonalnym elementem – filter. Wtyczka input pobiera dane, wtyczka filter przetwarza dane, a wtyczka output zapisuje dane w miejscu docelowym. Poniższe polecenie utworzy plik konfiguracyjny, który skonfiguruje Logstash dla wejścia Filebeat:
|
1 |
sudo vim /etc/logstash/conf.d/02-beats-input.conf |
Wprowadź następującą konfigurację input. Opisuje ona wejście beats, które będzie nasłuchiwać na porcie 5044 TCP:
|
1 2 3 4 5 |
input { beats { port => 5044 } } |
Kolejnym krokiem jest utworzenie pliku konfiguracyjnego o nazwie „10-syslog-filter.conf”. Użyjemy go do ustawienia filtra dla syslogów (logów systemowych):
|
1 |
sudo vim /etc/logstash/conf.d/10-syslog-filter.conf |
Wprowadź następujący kod konfiguracji syslog. Ten kod jest dostępny bezpośrednio w podręczniku Elastic. Ten kod wyjaśnia konfigurację input dla Logstash:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
input{ beats{ port => 5044 host => "0.0.0.0" } } filter { if [fileset][module] == "system" { if [fileset][name] == "auth" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] } pattern_definitions => { "GREEDYMULTILINE"=> "(.|\n)*" } remove_field => "message" } date { match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } geoip { source => "[system][auth][ssh][ip]" target => "[system][auth][ssh][geoip]" } } else if [fileset][name] == "syslog" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] } pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" } remove_field => "message" } date { match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } } } } |
Kolejny plik konfiguracyjny będzie dotyczył wyjścia. Otwórz nowy plik o nazwie „30-elasticsearch-output.conf”:
|
1 |
sudo vim /etc/logstash/conf.d/30-elasticsearch-output.conf |
Wprowadź następujący kod. Ten kod objaśnia konfigurację wyjściową dla Logstash:
|
1 2 3 4 5 6 7 |
output { elasticsearch { hosts => ["localhost:9200"] manage_template => false index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" } } |
Przetestuj konfigurację Logstash. Następnie uruchom następujące polecenie:
|
1 |
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t |
Jeśli nie ma błędu, Logstash wyświetli następujący komunikat o powodzeniu. Jeśli operacja się nie powiodła, upewnij się, że wszystkie pliki konfiguracyjne zawierają prawidłowy kod. Na koniec uruchom i włącz usługę Logstash:
|
1 2 |
sudo systemctl start logstash sudo systemctl enable logstash |
Teraz, gdy Logstash działa pomyślnie i jest w pełni skonfigurowany, zainstalujmy Filebeat.
Instalacja i konfiguracja Filebeat
Elastic Stack używa programów do przesyłania danych, znanych jako „Beats”, do zbierania danych z różnych źródeł i transportowania ich do Logstash/Elasticsearch. Oto krótka lista dostępnych Beats od Elastic:
- Filebeat: Zbieranie/przesyłanie plików dziennika.
- Metricbeat: Zbieranie/przesyłanie metryk z systemów i usług.
- Packetbeat: Zbieranie/analizowanie danych sieciowych.
- Winlogbeat: Zbieranie dzienników zdarzeń systemu Windows.
- Auditbeat: Zbieranie danych ze środowiska audytu systemu Linux i monitorowanie integralności plików.
- Heartbeat: Monitorowanie dostępności usług.
Na potrzeby tego samouczka będziemy potrzebować Filebeat do przesyłania lokalnych logów do Elastic Stack. Najpierw zainstaluj Filebeat:
|
1 |
sudo apt install filebeat |
Możesz teraz skonfigurować Filebeat. Najpierw musi on połączyć się z Logstash. Użyjemy przykładowej konfiguracji dostarczonej z Filebeat. Otwórz plik konfiguracyjny w edytorze tekstu. Pamiętaj, że ponieważ plik jest w formacie YAML, ważne jest odpowiednie wcięcie:
|
1 |
sudo vim /etc/filebeat/filebeat.yml |
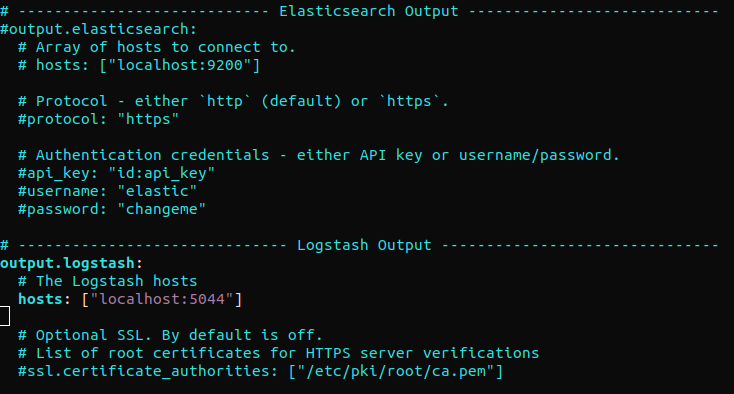
Znajdź sekcję „output.elasticsearch” i zakomentuj poniższe linie. Skonfiguruje to Filebeat do bezpośredniego wysyłania zdarzeń do Elasticsearch/Logstash w celu dodatkowego przetwarzania. Następnie przejdź do sekcji „output.logstash”. Następnie odkomentuj linie:
|
1 2 3 4 5 6 7 |
#output.elasticsearch: # Tablica hostów, z którymi należy się połączyć. # hosts: ["localhost:9200"] output.logstash: # Hosty Logstash hosts: ["localhost:5044"] |
Filebeat obsługuje moduły, które mogą rozszerzyć jego funkcjonalność. W tym samouczku użyjemy modułu system, który zbiera i analizuje logi generowane przez usługę logowania systemowego popularnych dystrybucji Linuksa. Włącz moduł system w Filebeat:
|
1 |
sudo filebeat modules enable system |
Poniższe polecenie Filebeat wyświetli listę wszystkich włączonych i wyłączonych modułów:
|
1 |
sudo filebeat modules list |
Domyślnie Filebeat jest skonfigurowany tak, aby śledzić domyślne ścieżki dla logów syslog i autoryzacji. Parametry modułów są dostępne w pliku konfiguracyjnym „/etc/filebeat/modules.d/system.yml”.
Kolejnym krokiem jest załadowanie szablonu indeksu do Elasticsearch. Indeks Elasticsearch oznacza kolekcję dokumentów o podobnych cechach. Każdy indeks ma swoją nazwę. Nazwa jest niezbędna podczas wykonywania różnych operacji w jego obrębie. Szablon indeksu jest automatycznie stosowany za każdym razem, gdy generowany jest nowy indeks. Następnie załaduj szablon:
|
1 |
sudo filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]' |
Filebeat domyślnie zawiera przykładowy pulpit nawigacyjny (dashboard) dla Kibana. Pomaga on wizualizować dane Filebeat w Kibana. Jednak przed użyciem pulpitu nawigacyjnego konieczne jest utworzenie wzorca indeksu i załadowanie pulpitów do Kibana. Podczas ładowania pulpitów Filebeat kontaktuje się z Elasticsearch w celu uzyskania informacji o wersji. Aby załadować pulpity nawigacyjne, gdy Logstash jest włączony, wymagane jest wyłączenie wyjścia Logstash i włączenie wyjścia Elasticsearch. Poniższe polecenie wykona to zadanie:
|
1 |
sudo filebeat setup -e -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601 |
Na koniec możesz uruchomić Filebeat:
|
1 2 |
sudo systemctl start filebeat sudo systemctl enable filebeat |
Teraz nadszedł czas na przetestowanie konfiguracji Elastic Stack. Jeśli została ona poprawnie skonfigurowana, wynik będzie wyglądał mniej więcej tak:
|
1 |
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty' |
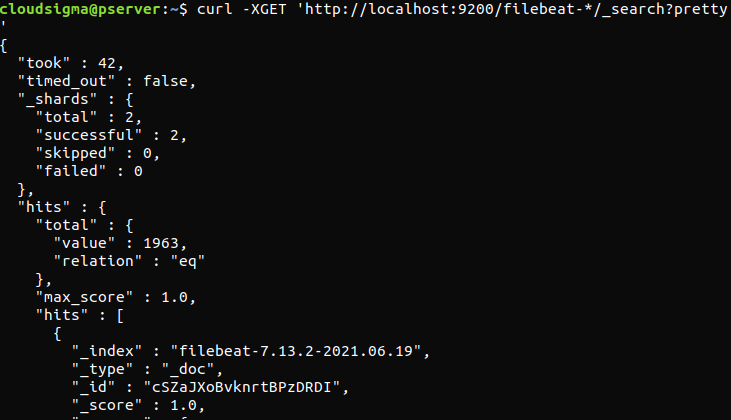
Jeśli wynik wskazuje 0 trafień (total hits), oznacza to, że Elasticsearch nie ładuje żadnych logów w indeksie, którego szukaliśmy. Wskazuje to na błąd w konfiguracji. Jeśli wynik był zgodny z oczekiwaniami, oznacza to, że Elastic Stack został pomyślnie skonfigurowany.
Przegląd pulpitów nawigacyjnych Kibana
Teraz nadszedł czas na zapoznanie się z zainstalowanym już interfejsem webowym Kibana. Najpierw otwórz pulpit nawigacyjny Kibana. Powinien on znajdować się pod adresem FQDN lub publicznym adresem IP serwera Elastic Stack:
|
1 |
http://<server_ip>:5601 |
Wprowadź wygenerowane wcześniej dane logowania. Po zalogowaniu pulpit nawigacyjny będzie wyglądał następująco:
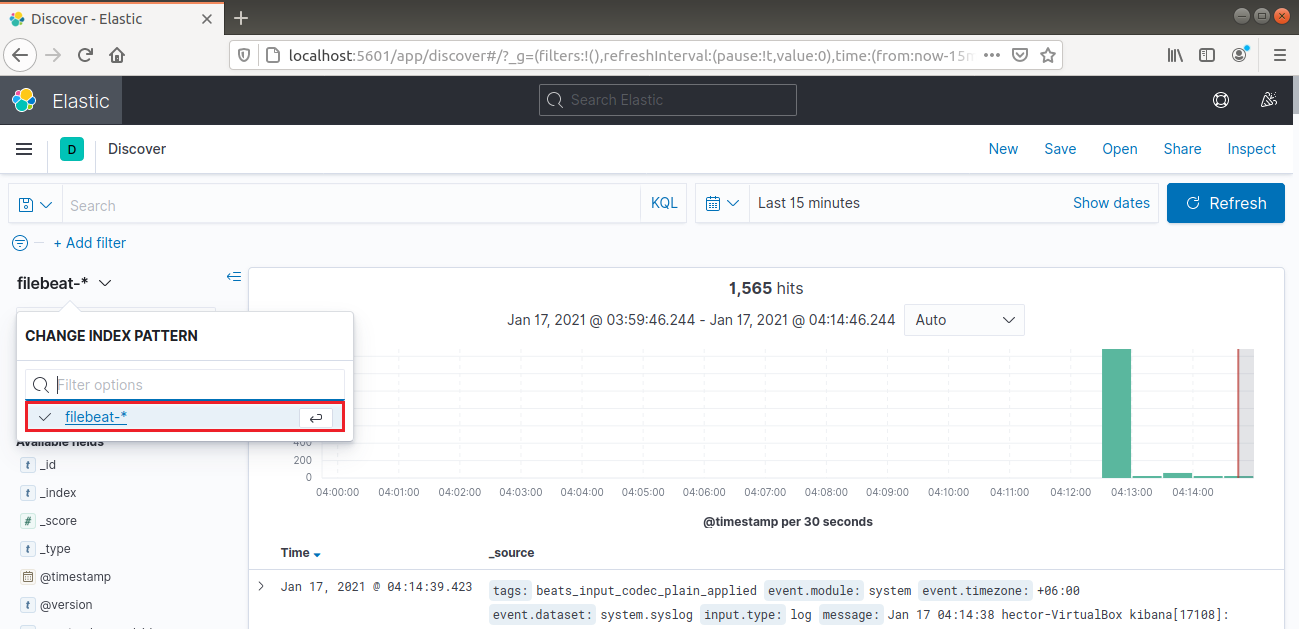
Z lewego paska nawigacyjnego wybierz „Discover”. Następnie wybierz wzorzec „filebeat-*”. Pokazuje on wszystkie logi zebrane w ciągu ostatnich 15 minut. Możliwe jest przeszukiwanie i przeglądanie logów oraz dostosowywanie pulpitu nawigacyjnego:
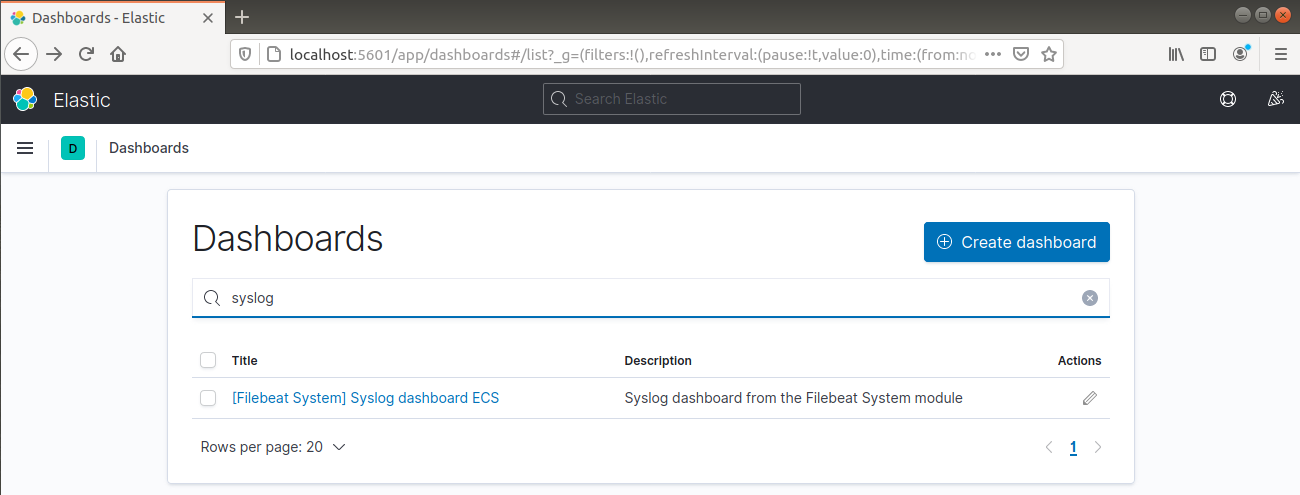
Z lewego paska nawigacyjnego przejdź do Dashboard >> Filebeat System. Tutaj dostępne są wszystkie przykładowe pulpity nawigacyjne z modułu systemowego Filebeat.
W poniższym przykładzie szczegółowo przedstawiono różne statystyki oparte na komunikatach syslog:
Może również raportować, którzy użytkownicy wykonali polecenia za pomocą sudo:
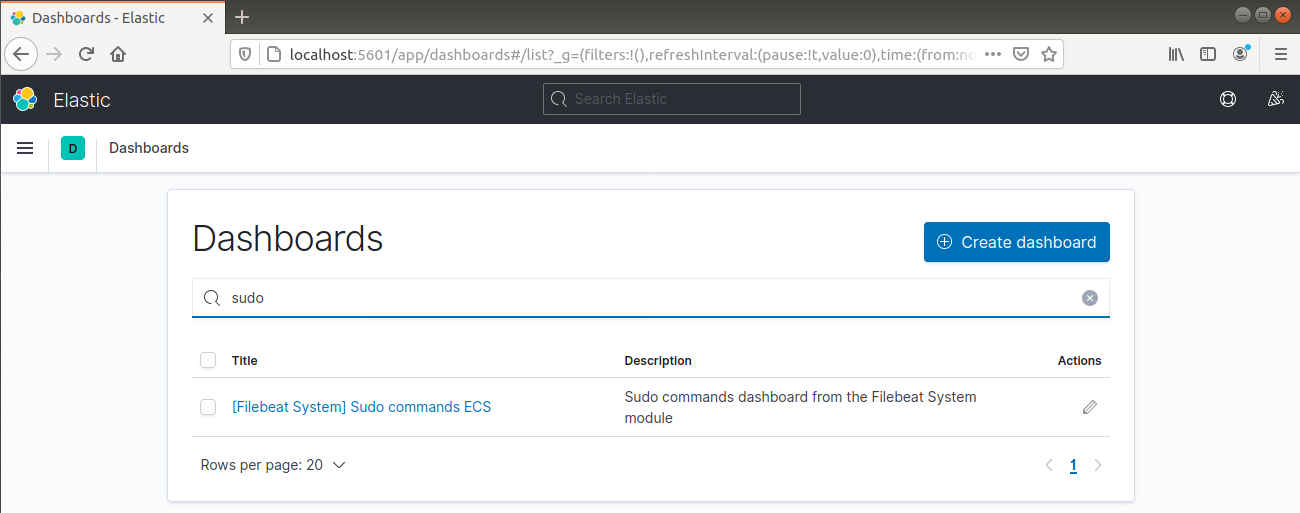
Na koniec Kibana daje możliwość zapoznania się z wieloma innymi funkcjonalnościami, takimi jak tworzenie wykresów i filtrowanie, więc zachęcamy do samodzielnego odkrywania.
Podsumowanie
Elastic Stack to potężne rozwiązanie do analizy logów systemowych. Pamiętaj, że chociaż wszelkie logi lub indeksowane dane mogą być wysyłane do Logstash za pomocą Beats, stają się one bardziej użyteczne, gdy zostaną przeanalizowane i ustrukturyzowane za pomocą filtrów Logstash.
Udanego korzystania!
Komentarze
Brak komentarzy. Bądź pierwszy.