

Wprowadzenie
Kubernetes to narzędzie open-source, które ma kluczowe znaczenie w orkiestracji kontenerów. Kubernetes działa poprzez orkiestrację i zarządzanie klastrami na dużą skalę w różnych środowiskach chmurowych, a nawet na serwerach lokalnych. Klaster to zestaw hostów przeznaczonych do uruchamiania skonteneryzowanych aplikacji i usług. Klaster wymaga do działania minimum dwóch węzłów – jednego master węzła oraz worker węzła. Mając na uwadze skalowalność, masz możliwość rozbudowy klastra o tyle węzłów worker, ile jest wymagane.
Węzeł w Kubernetes odnosi się do serwera. Węzeł master to serwer, który zarządza stanem klastra. Węzły worker to serwery, na których uruchamiane są obciążenia robocze – są to zazwyczaj skonteneryzowane aplikacje i usługi.
Ten przewodnik przeprowadzi Cię przez kroki instalacji i wdrożenia klastra Kubernetes składającego się z dwóch węzłów na systemie Ubuntu 20.04. Jak wspomniano, posiadanie dwóch węzłów to najbardziej podstawowa konfiguracja podczas pracy z Kubernetes. Masz również możliwość dodania kolejnych węzłów worker po zrozumieniu podstaw. Pokażemy Ci również, jak połączyć oba serwery, aby węzeł master mógł kontrolować węzeł worker.
Aby przetestować naszą konfigurację, wdrożymy Docker kontener z uruchomionym serwerem WWW Nginx do klastra. Jest to typowe, rzeczywiste zastosowanie Kubernetes. W miarę postępów dowiesz się więcej o niektórych kluczowych komponentach Kubernetes, takich jak kubectl oraz kubeadm . Wskazane jest również uprzednie zapoznanie się z naszym samouczkiem dotyczącym poznawania podstaw zestawu narzędzi Kubernetes , aby zapoznać się z podstawami platformy Kubernetes.
Zacznijmy!
Wymagania wstępne
Będziesz musiał przygotować dwa serwery działające na systemie Ubuntu 20.04. Aby uzyskać najlepszą wydajność, minimalne wymagania systemowe dla Kubernetes to 2 GB pamięci RAM i 2 procesory. Możesz wykonać kroki od 1 do 4 tego samouczka krok po kroku, który pomoże Ci skonfigurować serwer Ubuntu na CloudSigma. Jeden serwer będzie węzłem master, drugi węzłem worker. Trafnie nazwaliśmy nasze dwa serwery jako kubernetes-master oraz kubernetes-worker. Ułatwia to śledzenie samouczka. Możesz jednak swobodnie wybrać takie nazwy hostów jakie wolisz.
-
Upewnij się, że na obu węzłach dodasz użytkownika z uprawnieniami sudo , którego użyjemy do uruchamiania poleceń opisanych w powyższym samouczku. Postępuj zgodnie z tym samouczkiem dotyczącym konfiguracji pliku sudoers w systemie Linux, aby uzyskać instrukcje.
-
Łączność sieciowa – serwery w klastrze powinny móc się ze sobą komunikować. Po wdrożeniu maszyn wirtualnych z CloudSigma, będą one domyślnie połączone z Internetem za pomocą publicznego adresu IP. Jeśli pracujesz w sieci lokalnej, być może będziesz musiał edytować plik /etc/hosts na każdym serwerze i odpowiednio je powiązać.
-
Będziesz musiał zainstalować i włączyć Docker na każdym z węzłów. Kubernetes opiera się na środowisku uruchomieniowym kontenerów (container runtime) do uruchamiania kontenerów w podach. Chociaż do wyboru są inne platformy kontenerowe, w tym samouczku będziemy używać Dockera. Docker zapewni środowisko uruchomieniowe wymagane przez Ubuntu. Możesz wykonać kroki 1, 2 i 3 naszego samouczka dotyczącego instalacji i obsługi Dockera.
Krok 1: Instalacja Kubernetes
W tym kroku zainstalujemy Kubernetes. Podobnie jak w przypadku Dockera w sekcji wymagania wstępne, musisz uruchomić polecenia na obu węzłach, aby zainstalować Kubernetes. Użyj ssh do zalogowania się na oba węzły i kontynuowania pracy. Rozpoczniesz od zainstalowania pakietu apt-transport-https , który umożliwia pracę z protokołami http oraz https w repozytoriach Ubuntu. Zainstaluj również curl , ponieważ będzie to niezbędne w kolejnych krokach. Wykonaj następujące polecenie:
|
1 |
sudo apt install apt-transport-https curl |
Następnie dodaj klucz podpisujący Kubernetes do obu węzłów, wykonując polecenie:
|
1 |
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add |
Następnie dodajemy repozytorium Kubernetes jako źródło pakietów na obu węzłach za pomocą następującego polecenia:
|
1 2 |
echo "deb https://apt.kubernetes.io/ kubernetes-xenial main" >> ~/kubernetes.list sudo mv ~/kubernetes.list /etc/apt/sources.list.d |
Następnie zaktualizuj węzły:
|
1 |
sudo apt update |
- Zainstaluj narzędzia Kubernetes
Po zakończeniu aktualizacji zainstalujemy Kubernetes. Wiąże się to z instalacją różnych narzędzi wchodzących w skład Kubernetes: kubeadm, kubelet, kubectl, oraz kubernetes-cni. Narzędzia te są instalowane na obu węzłach. Poniżej definiujemy każde z nich:
-
kubelet – agent, który działa na każdym węźle i obsługuje komunikację z węzłem nadrzędnym (master) w celu uruchamiania obciążeń w środowisku uruchomieniowym kontenera. Wprowadź następujące polecenie, aby zainstalować kubelet:
|
1 |
sudo apt install kubelet |
-
kubeadm – część projektu Kubernetes, która pomaga zainicjować klaster Kubernetes. Wprowadź następujące polecenie, aby zainstalować kubeadm:
|
1 |
sudo apt install kubeadm |
-
kubectl – narzędzie wiersza poleceń Kubernetes, które umożliwia uruchamianie poleceń wewnątrz klastrów Kubernetes. Wykonaj następujące polecenie, aby zainstalować kubectl:
|
1 |
sudo apt install kubectl |
-
kubernetes-cni – umożliwia sieciowanie wewnątrz kontenerów, zapewniając im możliwość komunikacji i wymiany danych. Wykonaj następujące polecenie, aby zainstalować:
|
1 |
sudo apt-get install -y kubernetes-cni |
Opcjonalnie możesz zainstalować wszystkie cztery za pomocą jednego polecenia:
|
1 |
sudo apt-get install -y kubelet kubeadm kubectl kubernetes-cni |
Krok 2: Wyłączenie pamięci wymiany (Swap)
Kubernetes nie działa w systemie, który korzysta z pamięci swap. Dlatego musi ona zostać wyłączona na węźle nadrzędnym (master) i wszystkich węzłach roboczych (worker). Wykonaj następujące polecenie, aby wyłączyć pamięć swap:
|
1 |
sudo swapoff -a |
To polecenie wyłącza pamięć swap do momentu ponownego uruchomienia systemu. Musimy upewnić się, że pozostanie ona wyłączona nawet po restarcie. Należy to zrobić na węźle master i wszystkich węzłach worker. Możemy to zrobić, edytując plik fstab file i komentując linię /swapfile za pomocą znaku #. Otwórz plik w edytorze tekstu nano, wprowadzając następujące polecenie:
|
1 |
sudo nano /etc/fstab |
Wewnątrz pliku zakomentuj linię swapfile jak pokazano na poniższym zrzucie ekranu:
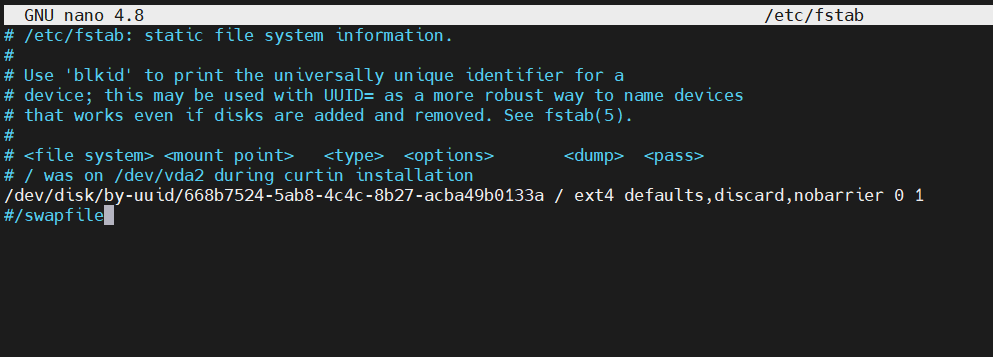
Jeśli nie widzisz linii swapfile, po prostu ją zignoruj. Zapisz i zamknij plik po zakończeniu edycji. Wykonaj ten sam proces dla obu węzłów. Teraz ustawienia pamięci swap pozostaną wyłączone, nawet po ponownym uruchomieniu serwera.
Krok 3: Ustawianie unikalnych nazw hostów
Twoje węzły must mieć unikalne nazwy hostów dla łatwiejszej identyfikacji. Jeśli wdrażasz klaster z wieloma węzłami, możesz ustawić nazwy identyfikujące dla węzłów roboczych, takie jak node-1, node-2 itp. Jak wspomnieliśmy wcześniej, nazwaliśmy nasze węzły jako kubernetes-master oraz kubernetes-worker. Ustawiliśmy je podczas tworzenia serwera. Możesz jednak dostosować lub ustawić swoje, jeśli jeszcze tego nie zrobiłeś z poziomu wiersza poleceń. Aby dostosować nazwę hosta na węźle master, uruchom następujące polecenie:
|
1 |
sudo hostnamectl set-hostname kubernetes-master |
Na węźle worker uruchom następujące polecenie:
|
1 |
sudo hostnamectl set-hostname kubernetes-worker |
Możesz zamknąć bieżącą sesję terminala i ssh zalogować się ponownie na serwer, aby zobaczyć zmiany.
Krok 4: Umożliwienie Iptables widzenia ruchu mostkowanego
Aby węzły master i worker poprawnie widziały ruch mostkowany, należy upewnić się, że parametr net.bridge.bridge-nf-call-iptables ma wartość 1 w konfiguracji. Najpierw upewnij się, że moduł br_netfilter jest załadowany. Możesz to potwierdzić, wydając polecenie:
|
1 |
lsmod | grep br_netfilter |
Opcjonalnie możesz go jawnie załadować za pomocą polecenia:
|
1 |
sudo modprobe br_netfilter |
Teraz możesz uruchomić to polecenie, aby ustawić wartość na 1:
|
1 |
sudo sysctl net.bridge.bridge-nf-call-iptables=1 |
Krok 5: Zmiana sterownika Cgroup platformy Docker
Domyślnie Docker instaluje się z “cgroupfs” jako sterownikiem cgroup. Kubernetes zaleca , aby Docker działał ze sterownikiem “systemd” jako sterownikiem. Jeśli pominiesz ten krok i spróbujesz zainicjować kubeadm w następnym kroku, w terminalu pojawi się następujące ostrzeżenie:
|
1 2 |
[preflight] Uruchamianie kontroli -wstępnych checks [OSTRZEŻENIE IsDockerSystemdCheck]: wykryto "cgroupfs" jako sterownik Docker cgroup driver. The Zalecanym sterownikiem jest "systemd". Proszę postępować zgodnie z instrukcją pod adresem https://kubernetes.io/docs/setup/cri/ |
Zarówno na węźle nadrzędnym (master), jak i roboczym (worker), zaktualizuj cgroupdriver za pomocą następujących poleceń:
|
1 2 3 4 5 6 7 8 9 |
sudo mkdir /etc/docker cat <<EOF | sudo tee /etc/docker/daemon.json { "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" }, "storage-driver": "overlay2" } EOF |
Następnie wykonaj następujące polecenia, aby zrestartować i włączyć platformę Docker przy uruchamianiu systemu:
|
1 2 3 |
sudo systemctl enable docker sudo systemctl daemon-reload sudo systemctl restart docker |
Po skonfigurowaniu tego możemy przejść do najciekawszej części, czyli wdrażania klastra Kubernetes!
Step 6: Inicjowanie węzła nadrzędnego (Master) Kubernetes
Pierwszym krokiem we wdrażaniu klastra Kubernetes jest uruchomienie węzła nadrzędnego (master). W terminalu węzła nadrzędnego wykonaj następujące polecenie, aby zainicjować kubernetes-master:
|
1 |
sudo kubeadm init --pod-network-cidr=10.244.0.0/16 |
Jeśli wykonasz powyższe polecenie, a Twój system nie spełnia oczekiwanych wymagań, takich jak minimalna ilość pamięci RAM lub procesora, jak wyjaśniono w sekcji Wymagania wstępne, otrzymasz ostrzeżenie i klaster nie zostanie uruchomiony:

Poniższy zrzut ekranu pokazuje, że inicjalizacja zakończyła się sukcesem. Dodaliśmy również flagę określającą sieć podów z adresem IP 10.244.0.0. Jest to domyślny adres IP, którego używa kube-flannel. Więcej o sieci podów powiemy w następnym kroku.
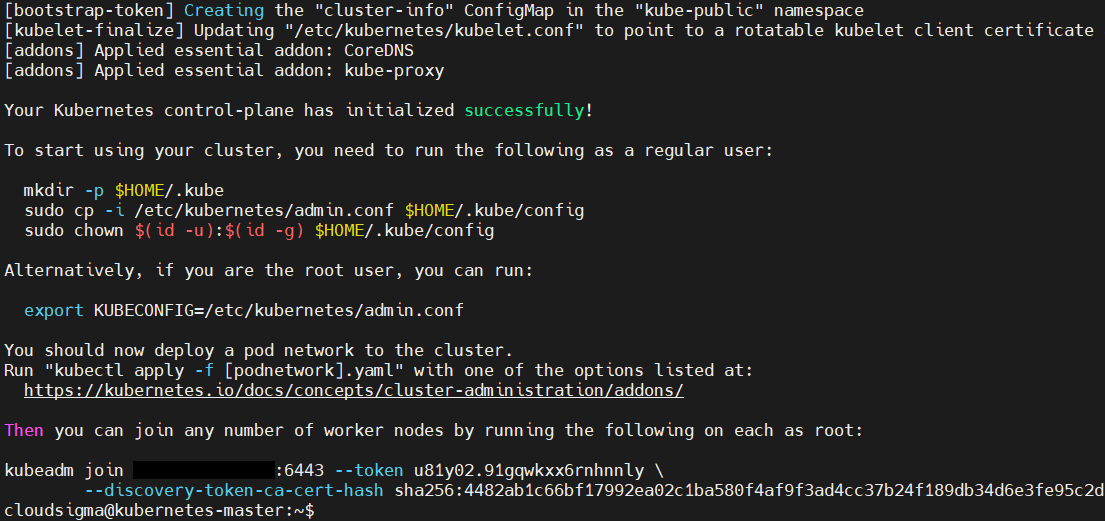
W danych wyjściowych widać polecenie kubeadm join (ukryliśmy nasz adres IP) oraz unikalny token, który należy uruchomić na węźle roboczym (worker) i wszystkich innych węzłach roboczych, które mają dołączyć do tego klastra. Następnie skopiuj i wklej to polecenie, ponieważ użyjesz go później na węźle roboczym.
W danych wyjściowych Kubernetes wyświetla również dodatkowe polecenia, które należy uruchomić jako zwykły użytkownik na węźle nadrzędnym przed rozpoczęciem korzystania z klastra. Uruchommy te polecenia:
|
1 2 3 |
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config |
Zainicjowaliśmy już węzeł nadrzędny. Musimy jednak również skonfigurować sieć podów na węźle nadrzędnym przed dołączeniem węzłów roboczych.
Krok 7: Wdrażanie sieci podów
Sieć podów ułatwia komunikację między serwerami i jest niezbędna do prawidłowego funkcjonowania klastra Kubernetes. Więcej informacji na temat sieci klastra Kubernetes można znaleźć w oficjalnej dokumentacji. W tym samouczku będziemy używać sieci podów Flannel. Flannel to prosta sieć nakładkowa (overlay), która spełnia wymagania Kubernetes.
Przed wdrożeniem sieci podów musimy sprawdzić stan zapory sieciowej. Jeśli włączyłeś zaporę sieciową po wykonaniu kroku 5 samouczka dotyczącego konfiguracji serwera Ubuntu, musisz najpierw dodać regułę zapory sieciowej aby utworzyć wyjątki dla portu 6443 (domyślny port dla Kubernetes). Uruchom następujące ufw polecenia zarówno na węźle master, jak i na węzłach roboczych:
|
1 2 |
sudo ufw allow 6443 sudo ufw allow 6443/tcp |
Następnie możesz uruchomić następujące dwa polecenia, aby wdrożyć sieć podów na węźle master:
|
1 2 |
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/k8s-manifests/kube-flannel-rbac.yml |
Może to zająć od kilku sekund do minuty, w zależności od środowiska, aby załadować sieć flannel. Uruchom następujące polecenie, aby potwierdzić, że wszystko zostało uruchomione:
|
1 |
kubectl get pods --all-namespaces |
Dane wyjściowe polecenia powinny pokazywać status wszystkich usług jako uruchomiony, jeśli wszystko zakończyło się pomyślnie:
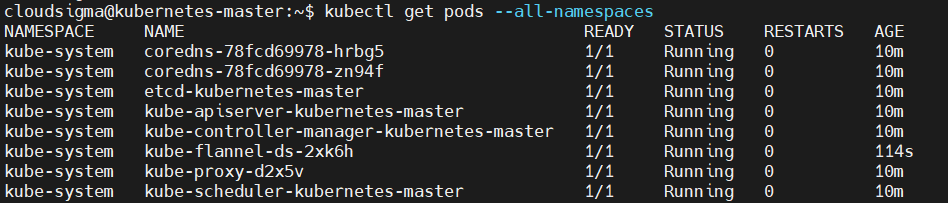
Możesz również wyświetlić stan komponentów za pomocą polecenia get component status:
|
1 |
kubectl get componentstatus |

To polecenie ma skróconą formę cs:
|
1 |
kubectl get cs |

Jeśli widzisz status unhealthy, zmodyfikuj następujące pliki i usuń linię w (spec->containers->command) zawierającą tę frazę - --port=0 :
|
1 |
sudo nano /etc/kubernetes/manifests/kube-scheduler.yaml |
Zrób to samo dla tego pliku:
|
1 |
sudo nano /etc/kubernetes/manifests/kube-controller-manager.yaml |
Na koniec zrestartuj usługę Kubernetes:
|
1 |
sudo systemctl restart kubelet.service |
Krok 8: Dołączanie węzłów roboczych do klastra Kubernetes
Gdy węzeł kubernetes-master jest uruchomiony, a sieć podów gotowa, możemy dołączyć nasze węzły robocze do klastra. W tym samouczku mamy tylko jeden węzeł roboczy, więc będziemy pracować z nim. Jeśli masz więcej węzłów roboczych, zawsze możesz wykonać te same kroki, które wyjaśnimy poniżej, aby dołączyć do klastra.
Najpierw zaloguj się do swojego węzła roboczego w oddzielnej sesji terminala. Użyjesz swojego polecenia kubeadm join, które zostało wyświetlone w terminalu podczas inicjalizacji węzła master w Kroku 6. Wykonaj polecenie:
|
1 |
sudo kubeadm join 127.0.0.188:6443 --token u81y02.91gqwkxx6rnhnnly --discovery-token-ca-cert-hash sha256:4482ab1c66bf17992ea02c1ba580f4af9f3ad4cc37b24f189db34d6e3fe95c2d |
Po zakończeniu dołączania do klastra powinieneś zobaczyć dane wyjściowe podobne do tych na poniższym zrzucie ekranu:
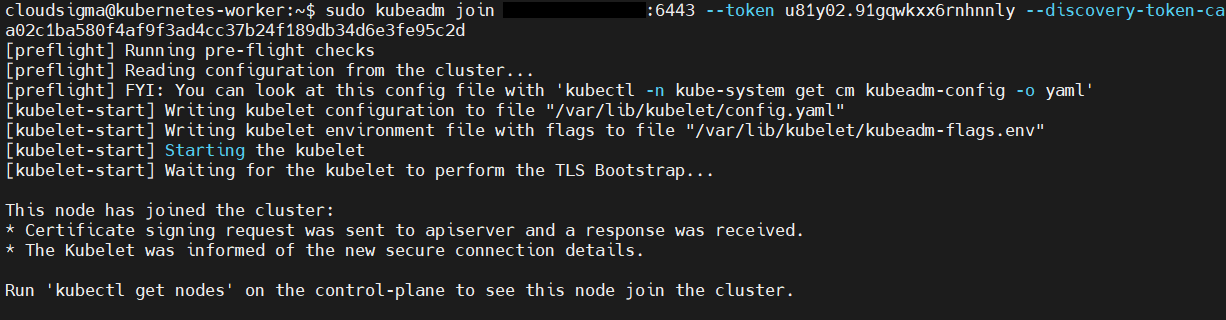
Po zakończeniu procesu dołączania przełącz się na terminal węzła master i wykonaj następujące polecenie, aby potwierdzić, że węzeł roboczy dołączył do klastra:
|
1 |
kubectl get nodes |
Na zrzucie ekranu z danymi wyjściowymi powyższego polecenia widzimy, że węzeł roboczy dołączył do klastra:

Krok 9: Wdrażanie aplikacji w klastrze Kubernetes
W tym momencie pomyślnie skonfigurowałeś klaster Kubernetes. Sprawmy, aby klaster był użyteczny, wdrażając w nim usługę. Nginx to popularny serwer WWW oferujący niesamowitą prędkość nawet przy tysiącach połączeń. Wdrożymy serwer WWW Nginx w klastrze, aby udowodnić, że można użyć tej konfiguracji w rzeczywistej aplikacji.
Wykonaj następujące polecenie na węźle master, aby utworzyć wdrożenie Kubernetes dla Nginx:
|
1 |
kubectl create deployment nginx --image=nginx |
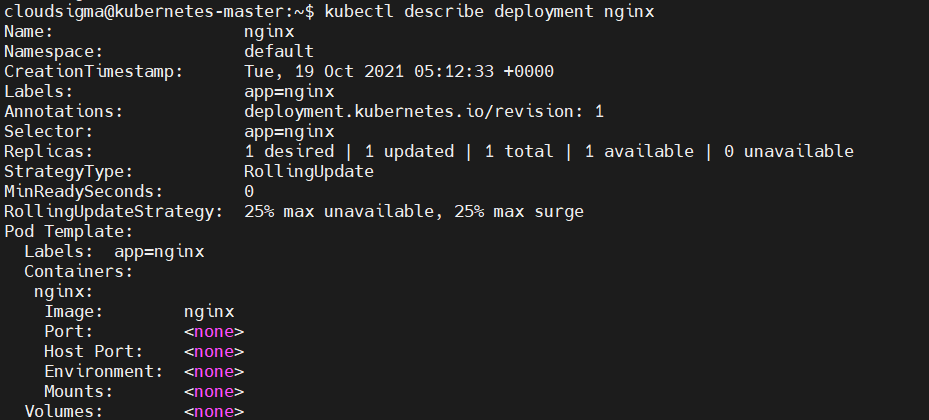
Możesz wyświetlić utworzone wdrożenie za pomocą polecenia describe deployment :
|
1 |
kubectl describe deployment nginx |
To make the nginx service accessible via the internet, run the following command:
|
1 |
kubectl create service nodeport nginx --tcp=80:80 |

The command above will create a public-facing service for the Nginx deployment. This being a nodeport deployment, Kubernetes assigns the service a port in the range of 32000+.
You can get the current services by issuing the command:
|
1 |
kubectl get svc |

You can see that our assigned port is 32264. Take note of the port displayed in your terminal to use in the next step.
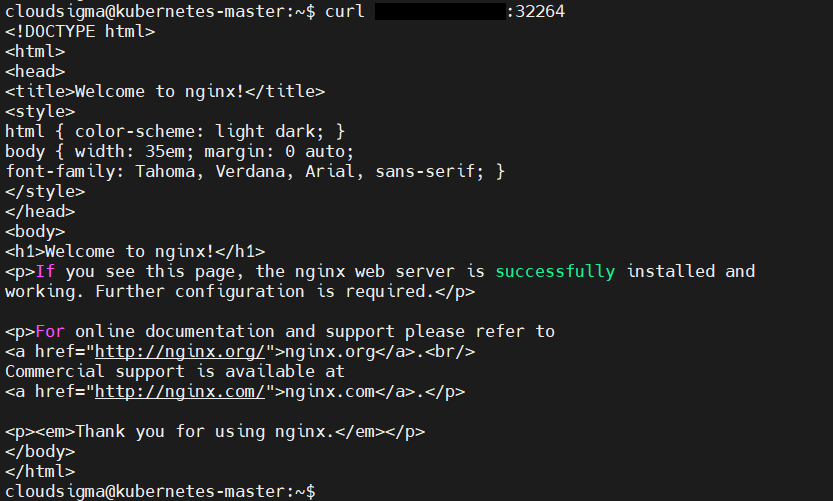
To verify that the Nginx service deployment is successful, issue a curl call to the worker node from the master. Replace your worker node IP and the port you got from the above command:
|
1 |
curl your-kubernetes-worker-ip:32264 |
You should see the output of the default Nginx index.html:
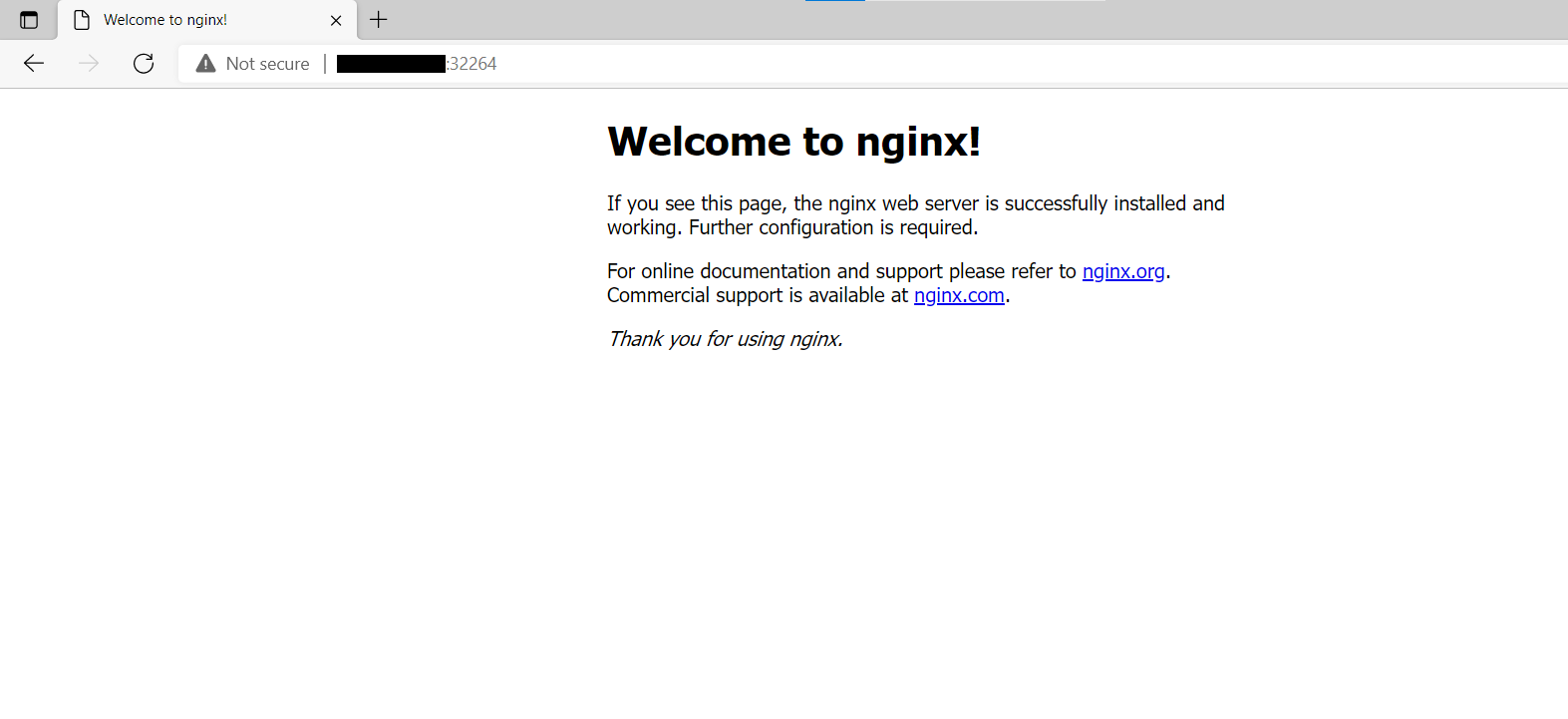
Optionally, you can visit the worker node IP address and port combination in your browser and view the default Nginx index page:
You can delete a deployment by specifying the name of the deployment. For example, this command will delete our deployment:
|
1 |
kubectl delete deployment nginx |
We have now successfully tested our cluster!
Conclusion
In this tutorial, you have learned how to install a Kubernetes cluster on Ubuntu 20.04. You set up a cluster consisting of a master and worker node. You were able to install the Kubernetes toolset, created a pod network, and joined the worker node to the master node. We also tested our concept by doing a basic deployment of an Nginx webserver to the cluster. This should work as a foundation to working with Kubernetes clusters on Ubuntu.
While we only used one worker node, you can extend your cluster with as many nodes as you wish. If you would like to get deeper into DevOps with automation tools like Ansible, we have a tutorial that delves into provisioning Kubernetes cluster deployments with Ansible and Kubeadm, check it out. If you want to learn how to deploy a PHP application on a Kubernetes cluster check this tutorial.
Happy Computing!
Komentarze
Brak komentarzy. Bądź pierwszy.