

Ten samouczek poprowadzi Cię przez proces konfiguracji Kubernetes klastra od zera przy użyciu Ansible oraz Kubeadm i dalszego wdrażania skonteneryzowanej aplikacji Nginx za jego pomocą.
Wprowadzenie
Kubernetes (znany również jako k8s lub “kube”) to platforma orkiestracji kontenerów o otwartym kodzie źródłowym, która automatyzuje wiele ręcznych procesów związanych z wdrażaniem, zarządzaniem i skalowaniem skonteneryzowanych aplikacji. Kubernetes ma szybko rozwijającą się społeczność open-source, aktywnie wspierającą ten projekt. Zapoznaj się z naszym wpisem na blogu, który wprowadzi Cię we wszystko, co musisz wiedzieć o podstawach platformy Kubernetes.
Kubeadm to narzędzie, które konfiguruje kilka zintegrowanych elementów, części i podzespołów, takich jak serwer API, Controller Manager i Kube DNS. Pomaga również w automatyzacji instalacji. Nie tworzy jednak użytkowników ani nie obsługuje instalacji zależności na poziomie systemu operacyjnego i ich konfiguracji, a także nie może aprowizować infrastruktury.
Ansible to narzędzie o otwartym kodzie źródłowym do aprowizacji oprogramowania i wdrażania aplikacji. Saltstack to oprogramowanie o otwartym kodzie źródłowym do automatyzacji technologii informatycznych sterowanej zdarzeniami. Są to dwa narzędzia, które sprawiają, że tworzenie dodatkowych klastrów lub odtwarzanie istniejących klastrów jest mniej podatne na błędy i mogą być używane do tych wstępnych zadań.
Cele:
Twój klaster będzie obejmował następujące zasoby fizyczne:
1. Jeden węzeł główny (master node):
Węzeł główny (master node) to węzeł, który kontroluje i zarządza zestawem węzłów roboczych (środowiskiem uruchomieniowym obciążeń) i reprezentuje klaster w Kubernetes. Przechowuje również plan zasobów węzła w celu określenia właściwego działania dla wywołanego zdarzenia. Uruchamia on etcd, rozproszony magazyn klucz-wartość o otwartym kodzie źródłowym, używany do przechowywania i zarządzania danymi klastra wśród komponentów, które planują obciążenia na węzłach roboczych.
Na przykład harmonogram (scheduler) określa, który węzeł roboczy będzie hostował nowo zaplanowany POD.
2. Dwa węzły robocze (worker nodes):
Węzły robocze (worker nodes) to węzły, które kontynuują przydzieloną im pracę, nawet jeśli węzeł główny ulegnie awarii po zakończeniu planowania. Węzły robocze to serwery, na których będą uruchamiane Twoje obciążenia (tj. skonteneryzowane aplikacje i usługi). Możesz również zwiększyć pojemność klastra, dodając węzły robocze.
Po ukończeniu tego samouczka będziesz mieć w pełni funkcjonalny klaster gotowy do uruchamiania obciążeń (tj. skonteneryzowanych aplikacji i usług), zakładając, że serwery w klastrze mają wystarczające zasoby procesora (CPU) i pamięci RAM do działania aplikacji. Po pomyślnym skonfigurowaniu klastra można na nim uruchomić niemal każdą tradycyjną aplikację UNIX. Może ona zostać skonteneryzowana w klastrze, w tym aplikacje internetowe, bazy danych, demony i narzędzia wiersza poleceń.
Sam klaster zużyje około 300-500 MB pamięci i 10% procesora (CPU) na każdym węźle.
Wymagania wstępne:
- Musisz posiadać parę kluczy SSH na lokalnej maszynie z systemem Linux i wiedzieć, jak z nich korzystać. Jeśli jednak nie używałeś wcześniej kluczy SSH, możesz zapoznać się z tym samouczkiem, który pomoże Ci skonfigurować klucze SSH na lokalnej maszynie.
- Trzy serwery z systemem Ubuntu 18.04, każdy z co najmniej 4 GB pamięci RAM i 4 vCPU. Powinieneś mieć możliwość połączenia się przez SSH z każdym serwerem jako użytkownik root za pomocą swojej pary kluczy SSH. Postępuj zgodnie z tym samouczkiem, aby zainstalować serwer Ubuntu.
- Ansible zainstalowany na lokalnej maszynie.
- Musisz również znać scenariusze (playbooks) Ansible.
- Musisz również wiedzieć, jak uruchomić kontener z obrazu Docker. Zobacz “Krok 5 — Praca z obrazami Docker w systemie Ubuntu” w Jak zainstalować i korzystać z platformy Docker w systemie Ubuntu 18.04 jeśli potrzebujesz odświeżenia wiedzy.
Krok 1 — Konfiguracja katalogu roboczego i pliku inwentarza Ansible
Najpierw musisz skonfigurować Ansible na swojej lokalnej maszynie. Pomoże Ci to wykonywać polecenia na zdalnym serwerze. Ułatwia to również ręczne wdrażanie poprzez jego automatyzację. W tym celu musisz utworzyć katalog na lokalnej maszynie, który będzie służył jako tymczasowy obszar roboczy (Workspace).
Po utworzeniu katalogu utworzysz plik hosts plik do przechowywania wszystkich informacji o adresach IP i grupach każdego serwera. Pomoże on zapisać w nim informacje o inwentarzu. Jak wspomniano wcześniej, będą trzy serwery: jeden master i dwa worker. Serwer master będzie masterem z adresem IP wyświetlanym jako master_ip. Pozostałe dwa serwery będą workerami i będą miały adresy IP worker_1_ip oraz worker_2_ip.
Musisz utworzyć katalog o nazwie ~/kube-cluster w katalogu domowym lokalnego komputera i wejść do niego za pomocą polecenia cd:
|
1 2 |
mkdir ~/kube-cluster cd ~/kube-cluster |
Katalog ~/kube-cluster będzie teraz działać jako tymczasowy cyfrowy obszar przechowywania (przestrzeń robocza), w którym będziesz uruchamiać wszystkie lokalne polecenia służące do tworzenia klastra Kubernetes za pomocą kubeadm. Katalog ten będzie zawierał wszystkie Twoje playbooki Ansible i będzie używany w dalszej części samouczka.
Tworzenie pliku hosts
Utwórz plik o nazwie ~/kube-cluster/hosts za pomocą nano lub innego ulubionego edytora tekstu:
|
1 |
nano ~/kube-cluster/hosts |
Teraz musisz dodać następujący tekst, który określi informacje o strukturze logicznej Twojego klastra:
|
1 2 3 4 5 6 7 8 9 |
[masters] master ansible_host=master_ip ansible_user=root [workers] worker1 ansible_host=worker_1_ip ansible_user=root worker2 ansible_host=worker_2_ip ansible_user=root [all:vars] ansible_python_interpreter=/usr/bin/python3 |
Jak wspomniano, ten plik inwentarza pomoże Ci zapisać wszystkie informacje o adresach IP Twoich serwerów oraz grupach, do których należy każdy serwer. ~/kube-cluster/hosts będzie Twoim plikiem inwentarza, a (masters i workers) będą dwiema grupami Ansible, które do niego dodałeś, określającymi strukturę logiczną Twojego klastra.
Grupa Master określa, że Ansible powinien uruchamiać zdalne polecenia jako użytkownik root. Zawiera ona również adres IP węzła master (master_ip), który może być wskazany przez wpis serwera o nazwie “master”. Podobnie grupa Workers ma dwa wpisy dla serwerów worker (worker_1_ip i worker_2_ip), które również określają ansible_user jako root.
Ostatnia linia pliku nakazuje Ansible używanie interpreterów Python 3 na zdalnych serwerach do operacji zarządzania. Na koniec, po dodaniu tekstu, musisz zapisać i zamknąć plik. Po skonfigurowaniu katalogu roboczego i pliku inwentarza Ansible przejdźmy do kolejnego kroku, jakim jest instalacja zależności na poziomie systemu operacyjnego i tworzenie ustawień konfiguracyjnych.
Krok 2 — Tworzenie użytkownika bez uprawnień roota na wszystkich zdalnych serwerach
W tym kroku dowiesz się, jak utworzyć użytkownika bez uprawnień roota z uprawnieniami sudo na wszystkich serwerach, aby móc logować się na nie ręcznie przez SSH jako użytkownik nieuprzywilejowany.
Może to być przydatne przy często wykonywanych operacjach związanych z utrzymaniem klastra. Ponadto ten krok pomoże Ci wykonać zadanie dokładniej i z mniejszym ryzykiem błędów, zmniejszając szanse na niezamierzoną modyfikację lub usunięcie ważnych plików. Jeśli chcesz zmienić konfigurację plików należących do roota lub wyświetlić informacje o systemie za pomocą poleceń takich jak top/htop i wyświetlić listę uruchomionych kontenerów, poniższy krok pomoże Ci wykonać wszystkie te zadania.
Tworzenie playbooka
Utwórz plik o nazwie ~/kube-cluster/initial.yml w przestrzeni roboczej:
|
1 |
nano ~/kube-cluster/initial.yml |
Następnie musisz dodać następujący play. Play w Ansible to zbiór kroków do wykonania, które są skierowane do określonych serwerów i grup. W playbooku może znajdować się jeden lub wiele playów.
Poniższy play utworzy użytkownika sudo bez uprawnień roota:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
- hosts: all become: yes tasks: - name: utwórz użytkownika 'ubuntu' użytkownik user: name=ubuntu append=yes state=present createhome=yes shell=/bin/bash - name: zezwól 'ubuntu' na posiadanie bezhasłowego sudo lineinfile: dest: /etc/sudoers line: 'ubuntu ALL=(ALL) NOPASSWD: ALL' validate: 'visudo -cf %s' - name: skonfiguruj up autoryzowane klucze dla użytkownika ubuntu użytkownik authorized_key: user=ubuntu key="{{item}}" with_file: - ~/.ssh/id_rsa.pub |
Poniżej znajduje się opis działania naszego playbooka:
- Ten playbook utworzy użytkownika niebędącego rootem o nazwie
ubuntu. - Ponieważ musisz uruchamiać polecenia
sudobez monitowania o hasło, to zadanie skonfiguruje pliksudoers, aby umożliwić to użytkownikowiubuntu. - Głównym celem powyższego zadania było umożliwienie połączenia SSH z każdym serwerem jako użytkownik
ubuntu. Ten playbook dodaje klucz publiczny Twojej lokalnej maszyny (zazwyczaj~/.ssh/id_rsa.pub) do listy autoryzowanych kluczy zdalnego użytkownikaubuntu.
Teraz, po dodaniu tekstu, musisz zapisać i zamknąć plik.
Uruchamianie playbooka
Następnie musimy wykonać nasz playbook, który utworzy użytkownika ubuntu niebędącego rootem, po prostu uruchamiając na lokalnych maszynach:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/initial.yml |
Wykonanie tego polecenia zajmie trochę czasu, po czym zobaczysz następujący wynik:
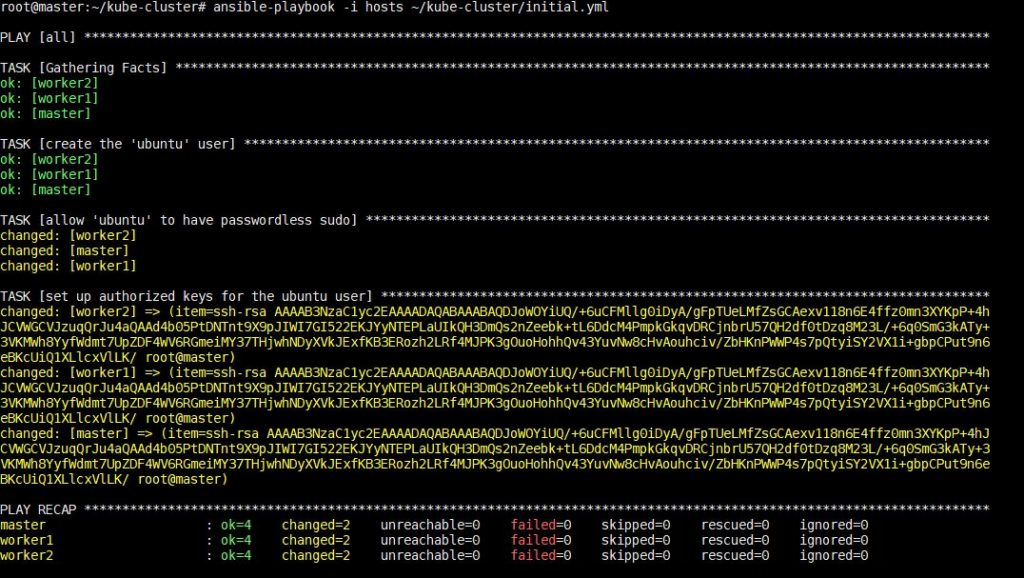
Po zakończeniu tego kroku możesz przejść do instalacji zależności specyficznych dla Kubernetes w następnym kroku.
Krok 3 — Instalacja zależności Kubernetes
W tym kroku dowiesz się, jak zainstalować pakiety na poziomie systemu operacyjnego wymagane przez Kubernetes za pomocą menedżera pakietów systemu Ubuntu.
Te pakiety to:
- Docker: Docker to platforma i narzędzie do budowania, dystrybucji i uruchamiania kontenerów Docker. Możesz łatwo skonfigurować Dockera, postępując zgodnie z naszym samouczkiem dotyczącym jak zainstalować i obsługiwać Dockera na Ubuntu w chmurze publicznej. Jednak wsparcie dla innych środowisk uruchomieniowych, takich jak rkt, jest aktywnie rozwijane w Kubernetes.
Kubeadm: kubeadm to narzędzie CLI, które wykonuje działania niezbędne do uruchomienia minimalnego działającego klastra. Pomoże to w standardowy sposób zainstalować i zbudować różne komponenty klastra.kubelet: kubelet to główny “agent węzła” (node agent), który działa na każdym węźle i obsługuje operacje na poziomie węzła.kubectl: kubectl to również narzędzie CLI, które komunikuje się z klastrem i wydaje polecenia za pośrednictwem jego serwera API.
Tworzenie playbooka
Utwórz plik o nazwie ~/kube-cluster/kube-dependencies.yml w przestrzeni roboczej:
|
1 |
nano ~/kube-cluster/kube-dependencies.yml |
Teraz musisz dodać do pliku następujące zadania (plays), aby zainstalować te pakiety na swoich serwerach:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
- hosts: all become: yes tasks: - name: zainstaluj Docker apt: name: docker.io state: present update_cache: true - name: zainstaluj APT Transport HTTPS apt: name: apt-transport-https state: present - name: dodaj Kubernetes apt-klucz apt_key: url: https://packages.cloud.google.com/apt/doc/apt-key.gpg validate_certs: false state: present - name: dodaj Kubernetes repozytorium APT apt_repository: repo: deb http://apt.kubernetes.io/ kubernetes-xenial main state: present filename: 'kubernetes' - name: zainstaluj kubelet apt: name: kubelet=1.16.0-00 state: present update_cache: true - name: zainstaluj kubeadm apt: name: kubeadm=1.16.0-00 state: present - hosts: master become: yes tasks: - name: zainstaluj kubectl apt: name: kubectl=1.16.0-00 state: present force: yes |
Pierwszy play w playbooku wykonuje następujące czynności:
- Ten play pomoże Ci zainstalować pakiety na poziomie systemu operacyjnego, Docker – środowisko uruchomieniowe kontenerów.
- Instaluje
apt-transport-https, co pozwala na dodawanie zewnętrznych źródeł HTTPS do listy źródeł APT. - Dodaje klucz apt repozytorium APT Kubernetes w celu weryfikacji klucza.
- Dodaje repozytorium APT Kubernetes do listy źródeł APT na zdalnych serwerach.
- Instaluje
kubeletorazkubeadm.
Drugi play wykonuje ważne i samodzielne zadanie, które obejmuje instalację kubectl na węźle master. Teraz, po dodaniu tekstu, musisz zapisać i zamknąć plik.
Uruchamianie playbooka
Następnie musimy uruchomić nasz playbook, po prostu uruchamiając na lokalnych maszynach:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/kube-dependencies.yml |
Wykonanie tego polecenia zajmie trochę czasu, po czym zobaczysz następujące dane wyjściowe:
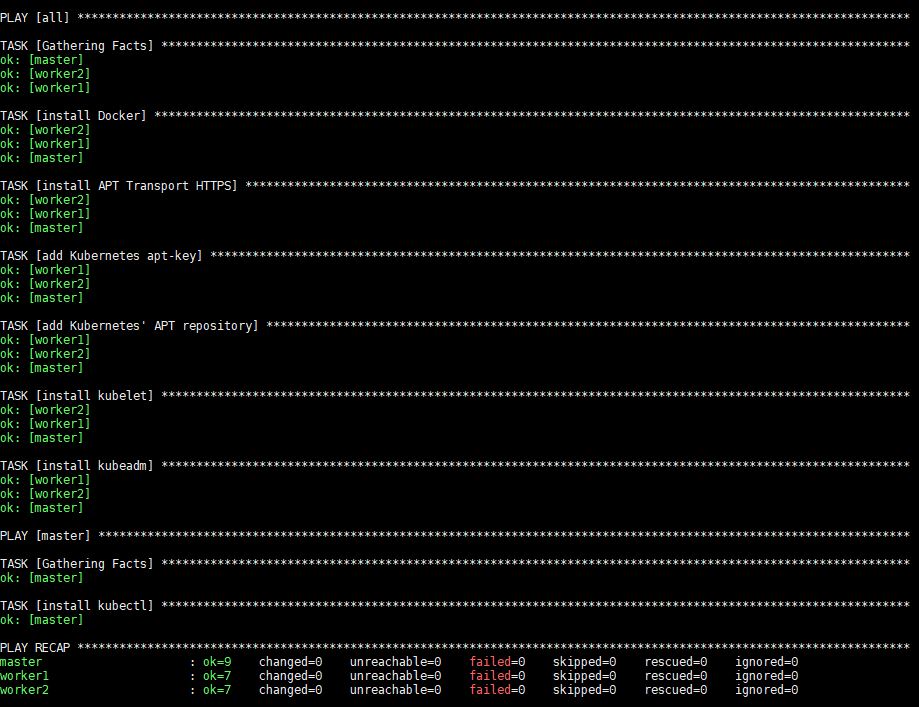
Po wykonaniu, Docker, kubeadm oraz kubelet zostaną zainstalowane na wszystkich zdalnych serwerach. Kubectl nie jest wymaganym komponentem i jest potrzebny tylko do wykonywania poleceń klastra. Instalowanie go tylko na węźle master ma sens w tym kontekście, ponieważ będziesz uruchamiać polecenia kubectl tylko z poziomu mastera. Pamiętaj jednak, że kubectl polecenia mogą być uruchamiane z dowolnego węzła roboczego lub z dowolnej maszyny, na której można je zainstalować i skonfigurować tak, aby wskazywały na klaster.
Wszystkie zależności systemowe są teraz zainstalowane. Skonfigurujmy węzeł główny i zainicjujmy klaster.
Krok 4 — Konfiguracja węzła głównego
W tym kroku poznasz kilka pojęć, takich jak Pody oraz Wtyczki sieciowe Podów ponieważ Twój klaster będzie zawierał oba te elementy po skonfigurowaniu węzła głównego.
Pody to najmniejsze, najbardziej podstawowe obiekty wdrażalne w Kubernetes. Pody zawierają jeden lub więcej kontenerów, takich jak kontenery Docker. Gdy Pod uruchamia wiele kontenerów, kontenery te są zarządzane jako jedna jednostka i współdzielą zasoby Poda.
Każdy pod ma swój własny adres IP, a pod na jednym węźle powinien mieć możliwość dostępu do poda na innym węźle przy użyciu adresu IP tego poda. Jednak komunikacja między podami jest bardziej złożona. Wymaga osobnego komponentu, który może w przezroczysty sposób kierować ruch z poda na jednym węźle do poda na innym. Do tej funkcjonalności używane są wtyczki sieciowe podów. Dostępnych jest wiele wtyczek sieciowych podów, ale my użyjemy Flannel, ponieważ jest to stabilna i wydajna opcja.
Tworzenie playbooka
Utwórz playbook Ansible o nazwie master.yml na swoim lokalnym komputerze:
|
1 |
nano ~/kube-cluster/master.yml |
Następnie musisz dodać do pliku następujące zadanie, aby zainicjować klaster i zainstalować Flannel:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
- hosts: master become: yes tasks: - name: zainicjuj the klaster shell: kubeadm init --pod-network-cidr=10.244.0.0/16 >> cluster_initialized.txt args: chdir: $HOME creates: cluster_initialized.txt become: yes become_user: root - name: utwórz .katalog .kubedirectory become: yes become_user: ubuntu file: path: $HOME/.kube state: directory mode: 0755 - name: skopiuj admin.conf do konfiguracji kube 'użytkownika kube config copy: src: /etc/kubernetes/admin.conf dest: /home/ubuntu/.kube/config remote_src: yes owner: ubuntu - name: zainstaluj sieć Podów become: yes become_user: ubuntu shell: kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/2140ac876ef134e0ed5af15c65e414cf26827915/Documentation/kube-flannel.yml >> pod_network_setup.txt args: chdir: $HOME creates: pod_network_setup.txt |
Oto szczegółowy opis tego scenariusza (play):
- Pierwsze zadanie w tym scenariuszu skonfiguruje klaster poprzez uruchomienie
kubeadm init. Aby określić prywatną podsieć, do której zostaną przypisane adresy IP podów, przekazujemy argument--pod-network-cidr=10.244.0.0/16. Flannel domyślnie używa powyższej podsieci. Używamy tego, aby wskazaćkubeadm, aby użył tej samej podsieci. - Drugie zadanie służy do utworzenia katalogu
.kubew/home/ubuntu. Informacje konfiguracyjne, takie jak pliki kluczy administratora, które są wymagane do połączenia z klastrem, oraz adres API klastra, będą przechowywane w tym katalogu. - Trzecie zadanie służy do skopiowania pliku
/etc/kubernetes/admin.confwygenerowanego przezkubeadm initdo katalogu domowego użytkownika niebędącego rootem. Pozwoli to na użyciekubectldo uzyskania dostępu do nowo utworzonego klastra. - Ostatnie zadanie uruchamia
kubectl applyw celu zainstalowaniaFlannel.kubectl apply -f descriptor.[yml|json]to składnia służąca do wskazaniakubectl, aby utworzył obiekty opisane w plikudescriptor.[yml|json]. Plikkube-flannel.ymlzawiera opisy obiektów wymaganych do skonfigurowaniaFlannelw klastrze.
Teraz, po dodaniu tekstu, musisz zapisać i zamknąć plik.
Uruchamianie playbooka
Następnie musisz uruchomić nasz playbook, wykonując na lokalnej maszynie polecenie:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/master.yml |
Wykonanie tego polecenia zajmie trochę czasu, po czym zobaczysz następujący wynik:
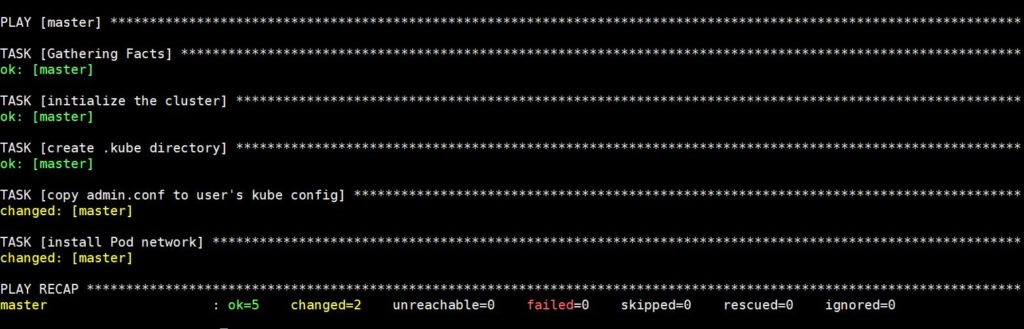
Nowy SSH do niego za pomocą następującego polecenia, aby sprawdzić status węzła master:
|
1 |
ssh ubuntu@master_ip |
Po wejściu do węzła master wykonaj:
|
1 |
kubectl get nodes |
Zobaczysz teraz następujący wynik:

Po otrzymaniu powyższego wyniku można uznać, że wszystkie zadania konfiguracyjne zostały wykonane przez węzeł master, który może zacząć akceptować węzły robocze (worker) i wykonywać zadania, gdy przejdzie w stan Ready. Możesz teraz dodać węzły robocze ze swojej lokalnej maszyny.
Krok 5 — Konfiguracja węzłów roboczych (Worker Nodes)
Po skonfigurowaniu węzła master możemy przejść do kolejnego kroku, jakim jest konfiguracja węzłów roboczych. Dodawanie węzłów roboczych do klastra można wykonać w prosty sposób, uruchamiając jedno polecenie na każdym serwerze roboczym. Polecenie to zawiera ważne informacje, takie jak adres IP, port serwera API węzła master oraz bezpieczny token. Należy jednak pamiętać, że nie wszystkie węzły będą mogły dołączyć do klastra – dołączą tylko te, które przekażą prawidłowy, bezpieczny token.
Tworzenie playbooka
To polecenie pomoże Ci wrócić do obszaru roboczego i utworzyć playbook o nazwie workers.yml:
|
1 |
nano ~/kube-cluster/workers.yml |
Dodaj następujący tekst do pliku, aby dodać węzły robocze do klastra:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
- hosts: master become: yes gather_facts: false tasks: - name: get join command shell: kubeadm token create --print-join-command register: join_command_raw - name: set join command set_fact: join_command: "{{ join_command_raw.stdout_lines[0] }}" - hosts: workers become: yes tasks: - name: join cluster shell: "{{ hostvars['master'].join_command }} >> node_joined.txt" args: chdir: $HOME creates: node_joined.txt |
Oto co robi playbook. W powyższym kodzie znajdują się dwa zadania:
- Pierwsze zadanie służy do pobrania polecenia dołączania, które należy uruchomić na węzłach roboczych. Format polecenia będzie następujący:
kubeadm join --token sha256:<hash><token><master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>;. Zadanie musi pobrać poprawne wartości tokenu i skrótu. Po otrzymaniu poprawnych danych wejściowych zadanie ustawia je jako fakt, aby drugie zadanie miało dostęp do tych informacji. - Drugie zadanie zostało napisane wyłącznie w celu wykonania jednego zadania – włączenia dwóch węzłów roboczych do klastra poprzez proste uruchomienie polecenia dołączenia na wszystkich węzłach roboczych.
Po dodaniu tekstu należy zapisać i zamknąć plik.
Uruchamianie playbooka
Następnie musimy wykonać nasz playbook, uruchamiając następujące polecenie na maszynach roboczych:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/workers.yml |
Wykonanie tego polecenia zajmie trochę czasu, po czym zobaczysz następujący wynik:
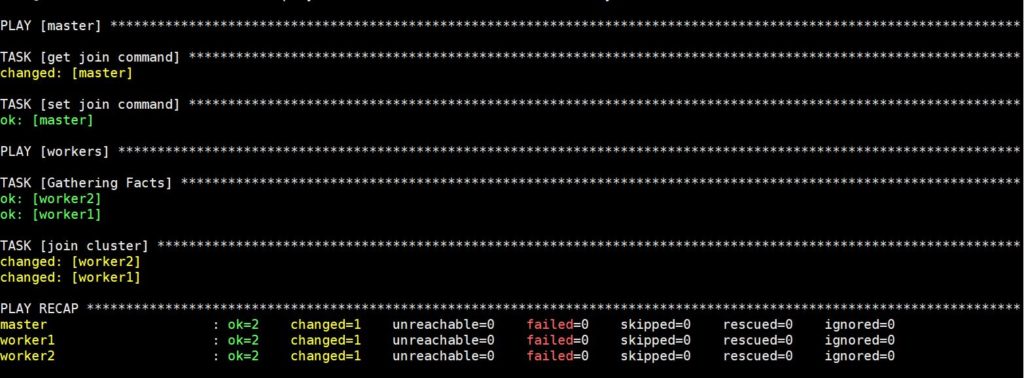
Teraz Twój klaster Kubernetes jest w pełni skonfigurowany i funkcjonalny, a węzły robocze są gotowe do uruchamiania obciążeń. Przed przejściem do następnego kroku zweryfikujmy, czy klaster działa zgodnie z planem.
Krok 6 — Weryfikacja klastra
Mogą wystąpić sytuacje, w których konfiguracja klastra zakończy się niepowodzeniem. Może to być spowodowane błędem sieciowym między węzłem nadrzędnym a roboczym lub problemem z samym węzłem. Dlatego musimy zweryfikować klaster przed zaplanowaniem aplikacji i upewnić się, że nie występują żadne nieprawidłowości. W tym celu należy sprawdzić bieżący stan klastra z poziomu węzła nadrzędnego, aby upewnić się, że węzły są gotowe. Jeśli węzły nie są gotowe lub połączenie zostało przerwane, możesz je przywrócić za pomocą następującego polecenia:
|
1 |
ssh ubuntu@master_ip |
Użyj następujących poleceń, aby uzyskać status klastra:
|
1 |
kubectl get nodes |
Wykonanie tego polecenia zajmie trochę czasu, po czym zobaczysz następujący wynik:

Musisz sprawdzić, czy wszystkie węzły wchodzące w skład klastra są w stanie gotowości. Jeśli kilka węzłów ma status Not Ready jako STATUS, oznacza to, że węzły robocze nie zakończyły jeszcze swojej konfiguracji. Jednak przed ponownym uruchomieniem kubectl get nodes i sprawdzeniem zaktualizowanego wyniku należy odczekać kolejne pięć do dziesięciu minut. Jeśli niektóre węzły nadal pokazują Not Ready jako swój status, należy zweryfikować poprzednie kroki i ponownie uruchomić polecenia. Tylko jeśli węzły mają wartość Ready dla STATUS, są one częścią klastra i są gotowe do uruchamiania obciążeń. Po pomyślnym wykonaniu szóstego kroku Twój klaster jest zweryfikowany. Teraz zaplanujmy przykładową aplikację Nginx w klastrze.
Krok 7 — Uruchamianie aplikacji w klastrze
Creating Deployment
Po pomyślnym utworzeniu klastra możesz wdrożyć w nim dowolną skonteneryzowaną aplikację. Jeśli znajdujesz się w węźle nadrzędnym, możesz użyć poniższych poleceń dla innych skonteneryzowanych aplikacji. Następnie wykonaj następujące polecenie, aby utworzyć wdrożenie o nazwie nginx :
|
1 |
kubectl create deployment nginx --image=nginx |
Musisz zmienić nazwę obrazu Docker i wszelkie odpowiednie flagi (takie jak porty i wolumeny). Aby zachować znajome środowisko, możesz wdrożyć Nginx za pomocą wdrożeń (deployments) i usług (services), aby zobaczyć, jak aplikacje mogą być wdrażane w klastrze.
Wdrożenie Kubernetes to obiekt zasobu w Kubernetes, który zapewnia deklaratywne aktualizacje aplikacji. Wdrożenie (deployment) pozwala opisać cykl życia aplikacji, taki jak obraz kontenera, repliki i strategia aktualizacji. Wdrożenie zapewnia, że pożądana liczba podów działa i jest dostępna przez cały czas. Jeśli pod ulegnie awarii w trakcie działania klastra, zostanie uruchomiony ponownie. Proces aktualizacji jest również w pełni rejestrowany i wersjonowany, z opcjami wstrzymania, kontynuowania i przywrócenia poprzednich wersji. Powyższe polecenie utworzenia wdrożenia o nazwie Nginx pomoże Ci wdrożyć pod z jednym kontenerem z obrazu Docker Nginx z rejestru Docker.
Konfigurowanie Node Port
Następnie musimy utworzyć NodePort. NodePort to otwarty port na każdym węźle klastra. Kubernetes w przezroczysty sposób kieruje ruch przychodzący na NodePort do Twojej usługi, nawet jeśli aplikacja działa na innym węźle. W tym celu możemy użyć tego polecenia, aby utworzyć zasób NodePort o nazwie Nginx, który udostępni aplikację publicznie:
|
1 |
kubectl expose deploy nginx --port 80 --target-port 80 --type NodePort |
Usługa (service) to kolejny obiekt Kubernetes odpowiedzialny za udostępnianie interfejsu dla tych podów, co umożliwia dostęp sieciowy zarówno z wnętrza klastra, jak i pomiędzy procesami zewnętrznymi a usługą. Można ją zdefiniować jako abstrakcję nad podami, która zapewnia pojedynczy adres IP i nazwę DNS, za pomocą których można uzyskać dostęp do podów. Dzięki usłudze bardzo łatwo jest zarządzać konfiguracją równoważenia obciążenia (load balancing).
Uruchom następujące polecenie:
|
1 |
kubectl get services |
Spowoduje to wyświetlenie tekstu podobnego do następującego:

Po otrzymaniu danych wyjściowych Kubernetes automatycznie przypisze losowy port większy niż 30000, upewniając się jednocześnie, że przypisany port nie jest już powiązany z inną usługą. Trzecia linia powyższego wyjścia pomoże Ci odczytać port, na którym działa Nginx.
Aby zweryfikować, czy to działa, odwiedź http://worker_1_ip:nginx_port lub http://worker_2_ip:nginx_port w przeglądarce na swoim lokalnym komputerze. Zobaczysz znajomą stronę powitalną Nginx.
Usuwanie wdrożenia
Jeśli chcesz usunąć aplikację Nginx, musisz najpierw usunąć usługę nginx z węzła master:
|
1 |
kubectl delete service nginx |
Aby zweryfikować, czy aplikacja została ostatecznie usunięta, musisz uruchomić to polecenie:
|
1 |
kubectl get services |
Otrzymasz następujące dane wyjściowe:

Następnie musisz usunąć wdrożenie za pomocą następującego polecenia:
|
1 |
kubectl delete deployment nginx |
Możesz użyć tego polecenia, aby zweryfikować, czy wdrożenie zostało ostatecznie usunięte:
|
1 |
kubectl get deployments |
![]()
Podsumowanie:
Ten samouczek pomoże Ci poprawnie skonfigurować klaster na Ubuntu 18.04 przy użyciu Kubeadm i Ansible. Teraz, gdy Twój klaster jest skonfigurowany, możesz łatwo rozpocząć wdrażanie własnych aplikacji i usług.
Oto lista linków z dodatkowymi szczegółami, które poprowadzą Cię przez ten proces:
- Dokeryzacja aplikacji – Ten link zawiera przykłady, które pokazują, jak uruchamiać aplikacje za pomocą Dockera. Takie jak dokeryzacja PostgreSQL, usługi CouchDB itp.
- Przegląd podów (Pod Overview) – Ten link przedstawia szczegółowe informacje na temat korzystania z podów, ich działania oraz tego, jak pody są powiązane z innymi obiektami Kubernetes. Pody są ważną częścią Kubernetes, więc ich zrozumienie pomoże Ci odnieść sukces w realizacji zadania.
- Przegląd wdrożeń (Deployments Overview) – Pomoże Ci dowiedzieć się więcej o wdrożeniach. Wdrożenie zapewnia deklaratywne aktualizacje dla podów i zestawów replik (ReplicaSets). Dowiesz się, jak aktualizować, zastępować i wycofywać wdrożenia.
- Przegląd usług (Services Overview) - Ten link poprowadzi Cię przez temat usług, które są kolejnym często używanym obiektem w klastrach Kubernetes. Usługa w Kubernetes to abstrakcja, która definiuje logiczny zestaw podów oraz politykę dostępu do nich. Zrozumienie typów usług i dostępnych opcji jest kluczowe dla uruchamiania zarówno aplikacji bezstanowych, jak i stanowych.
Ponadto zachęcamy do zapoznania się z naszymi innymi poradnikami dotyczącymi Dockera i Kubernetes, które można znaleźć na naszym blogu:
- Wprowadzenie do Kubernetes
- Czyszczenie zasobów Dockera – obrazy, kontenery i wolumeny
- Jak uruchomić Docker na CloudSigma (z CloudInit) Zaktualizowano
- Instalacja i konfiguracja Dockera na CentOS 7
- Jak zainstalować & obsługiwać Dockera na Ubuntu w chmurze publicznej
Istnieje również wiele innych ważnych pojęć, takich jak Wolumeny, Ingressy, i Sekrety których można używać podczas wdrażania aplikacji produkcyjnych.
Miłego korzystania!
Komentarze
Brak komentarzy. Bądź pierwszy.