

Web scraping, web crawling, web harvesting lub ekstrakcja danych internetowych to synonimy odnoszące się do procesu pozyskiwania danych ze stron internetowych w sieci. Web scrapery lub web crawlery to narzędzia, które programowo przeglądają strony internetowe, wyodrębniając wymagane dane. Dane te, będące zazwyczaj dużymi zbiorami tekstowymi, mogą być wykorzystywane do celów analitycznych, do zrozumienia produktów lub do zaspokojenia ciekawości na temat określonej strony internetowej.
Jeśli zastanawiasz się, jak zabrać się za web crawling, pokażemy Ci podstawy web scrapingu na przykładzie prostego zbioru danych. Powinieneś być w stanie śledzić ten samouczek bez względu na poziom Twojej wiedzy programistycznej. W praktycznym przykładzie użyjemy naszego bloga CloudSigma. Spróbujemy pobrać informacje o samouczkach na naszej stronie bloga. Zanim przeczytasz podsumowanie tego samouczka, będziesz mieć działający web scraper stworzony przy użyciu Python 3, który przeszukuje kilka stron w sekcji naszego bloga, a następnie wyświetla dane na ekranie.
Wykorzystując wiedzę zdobytą podczas tworzenia tego podstawowego web scrapera, możesz go rozbudować i tworzyć własne narzędzia do scrapowania. To powinna być świetna zabawa, zacznijmy!
Wymagania wstępne
To jest praktyczny samouczek, więc aby móc go bez problemu śledzić, powinieneś posiadać lokalne środowisko programistyczne dla języka Python 3. Najpierw możesz zapoznać się z naszym samouczkiem dotyczącym tego, jak zainstalować Python 3 i skonfigurować lokalne środowisko programistyczne na Ubuntu.
Scrapy
Web scraping składa się z dwóch kroków: pierwszym krokiem jest znalezienie i pobranie stron internetowych, drugim krokiem jest ich przeszukanie i wyodrębnienie z nich informacji.
Istnieje wiele sposobów i bibliotek, których można użyć do zbudowania web scrapera od zera w wielu językach programowania. Może to jednak powodować problemy w przyszłości, gdy Twój scraper stanie się skomplikowany lub gdy zajdzie potrzeba jednoczesnego przeszukiwania wielu stron o różnych ustawieniach i wzorcach. Dość trudnym zadaniem może okazać się wymyślenie, jak konwertować pobrane dane między różnymi formatami, takimi jak CSV, XML czy JSON.
Choć niektórzy mogą docenić wyzwanie, jakim jest budowanie własnego web scrapera od zera, lepiej nie wymyślać koła na nowo, lecz oprzeć go na istniejącej bibliotece, która radzi sobie ze wszystkimi tymi problemami. Będziemy używać Scrapy, biblioteki Pythona, wraz z Python 3 do zaimplementowania web scrapera w tym samouczku. Scrapy to narzędzie open-source i jedna z najpopularniejszych oraz najpotężniejszych bibliotek do web scrapingu w Pythonie. Scrapy zostało stworzone do obsługi typowych funkcjonalności, które powinny posiadać wszystkie scrapery. Dzięki temu nie musisz wymyślać koła na nowo za każdym razem, gdy chcesz wdrożyć web crawlera. Ze Scrapy proces budowania scrapera staje się łatwy i przyjemny.
Scrapy jest dostępne w PyPi, powszechnie znanym jako pip – Python Package Index. PyPi to repozytorium społecznościowe, w którym znajduje się większość pakietów Pythona. Kiedy instalujesz i konfigurujesz Python 3 w swoim lokalnym środowisku programistycznym, instaluje się również pip, którego możesz użyć do instalacji pakietów Pythona.
Krok 1: Jak zbudować prosty web scraper
Najpierw, aby zainstalować Scrapy, uruchom następujące polecenie:
|
1 |
pip install scrapy |
Opcjonalnie możesz postępować zgodnie z oficjalnymi instrukcjami instalacji Scrapy na stronie dokumentacji. Jeśli pomyślnie zainstalowałeś Scrapy, utwórz folder dla projektu, używając dowolnej nazwy:
|
1 |
mkdir cloudsigma-crawler |
Przejdź do tego folderu i utwórz główny plik dla kodu. Ten plik będzie zawierał cały kod do tego samouczka:
|
1 |
touch main.py |
Jeśli chcesz, możesz utworzyć ten plik za pomocą edytora tekstu lub IDE zamiast powyższego polecenia.
Następnie otwórz plik i zacznijmy od stworzenia podstawowego scrapera korzystającego ze Scrapy. Utworzymy klasę Pythona, która rozszerza scrapy.Spider, podstawową klasę pająka (spider) ze Scrapy. Klasa ta będzie miała dwa wymagane atrybuty zdefiniowane poniżej:
- name — nazwa typu string służąca do identyfikacji pająka (możesz wpisać dowolną nazwę).
- start_urls — tablica zawierająca listę adresów URL, od których rozpocznie się przeszukiwanie. Zaczniemy od jednego adresu URL.
Dodaj następujący fragment kodu w otwartym pliku, aby utworzyć podstawowego spidera:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
Poniżej znajduje się wyjaśnienie każdej linii kodu:
Pierwsza linia importuje Scrapy, co pozwala nam na korzystanie z różnych klas dostarczanych przez ten pakiet.
W kolejnej linii rozszerzamy klasę Spider dostarczaną przez Scrapy i tworzymy podklasę o nazwie CloudSigmaCrawler. Poprzez rozszerzenie klasy (Spider) uzyskujemy dostęp do właściwości tej klasy, z których możemy teraz korzystać w naszym kodzie. W tym przypadku klasa Spider posiada metody i zachowania, które definiują, jak podążać za adresami URL i wyodrębniać dane ze stron internetowych. Nie wie jednak, za którymi adresami URL podążać ani jakie dane wyodrębniać. Rozszerzając ją, możemy dostarczyć wymagane informacje do tych metod. Aby dowiedzieć się więcej o tworzeniu podklas i rozszerzaniu, czytaj dalej Zasady programowania obiektowego.
W naszym CloudSigmaCrawler definiujemy wymagane atrybuty. Najpierw nazywamy naszego spidera cloudsigma_crawler. Następnie podajemy pojedynczy adres URL, od którego należy zacząć: https://blog.cloudsigma.com/blog/. Otwarcie tego adresu URL przeniesie Cię na pierwszą stronę bloga CloudSigma, która zawiera niektóre z wielu samouczków.
Czas przetestować scraper. Masz kilka opcji. Jeśli używasz środowiska IDE, na przykład PyCharm community edition od JetBrains, prawdopodobnie posiada ono przycisk, który wystarczy kliknąć, aby uruchomić skrypt. Inną opcją jest skorzystanie z typowego sposobu uruchamiania plików Pythona z wiersza poleceń: python path/to/file.py lub py path/to/file.py. Kolejną opcją jest interfejs wiersza poleceń Scrapy. Scrapy posiada własny interfejs wiersza poleceń, który pomaga w uruchomieniu scrapera. Wprowadź następujące polecenie, aby uruchomić scraper:
|
1 |
scrapy runspider main.py |
W zależności od zainstalowanej wersji biblioteki Scrapy, powinieneś zobaczyć dane wyjściowe podobne do poniższych:
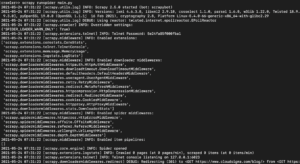
Jak widać, dane wyjściowe są dość długie, więc wybraliśmy tylko niektóre części. Oto co się stało po wykonaniu polecenia:
- Scraper został zainicjowany. W związku z tym załadował dodatkowe komponenty i rozszerzenia, których potrzebuje do śledzenia i odczytywania danych z adresów URL.
- Używając adresu URL podanego na liście start_urls, pobrał kod HTML ze strony. Jest to proces podobny do tego, który wykonuje przeglądarka podczas otwierania stron internetowych.
- Po pobraniu kodu HTML jest on przekazywany do metody parse, której jeszcze nie zdefiniowaliśmy. Na razie nic ona nie robi, dlatego spider po prostu kończy działanie bez wykonywania żadnego przetwarzania. Zachowanie metody parse zdefiniujemy w następnym kroku.
Krok 2: Jak wyodrębnić dane ze strony
W kroku 1 zaimplementowaliśmy jedynie podstawowy scraper, który pobiera stronę HTML, ale potem nic nie robi. W tej sekcji przedstawimy instrukcje dotyczące wyodrębniania danych. Na stronie CloudSigma Blog, z której chcemy wyodrębnić dane, można zauważyć kilka rzeczy, takich jak:
- Nagłówek, obecny na wszystkich stronach.
- Menu nawigacyjne i pole filtra wyszukiwania.
- Rzeczywista lista samouczków w formacie siatki.
Wyświetlenie kodu źródłowego strony HTML, którą zamierzasz scrapować, daje ogólne wyobrażenie o strukturze strony. Pomaga to w pisaniu scrapera. Kod źródłowy można wyświetlić, klikając prawym przyciskiem myszy na stronie i wybierając Pokaż źródło strony lub naciskając Ctrl + U. Oto fragment kodu źródłowego:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Bezpośredni odnośnik do: "Zabezpieczanie Apache za pomocą Let’s Encrypt na Ubuntu 18.04"">Zabezpieczanie Apache za pomocą Let’s Encrypt na Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Bezpieczeństwo stron internetowych i danych to tematy, których nie można lekceważyć. Bardzo poufne informacje, które obejmują dokumentację finansową i prywatne dane klientów, są stale przesyłane między komputerem użytkownika a Twoją witryną. Biorąc pod uwagę ten fakt, nietrudno zrozumieć, dlaczego niezabezpieczone strony internetowe mogą prowadzić do naruszenia bezpieczeństwa, które mogłoby poważnie zaszkodzić Twojej firmie. Istnieje … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Czytaj więcej</a></div> </div> </div> ... </article> </div> </body> |
Jak widać, każdy poradnik na blogu jest zamknięty w tagu HTML o nazwie <article>. Scrapowanie strony będzie składać się z dwóch kroków. Pierwszym krokiem będzie pobranie każdego poradnika z bloga poprzez przyjrzenie się częściom strony zawierającym dane, które chcemy uzyskać. Następnym krokiem jest wyciągnięcie pożądanych danych z każdego poradnika zidentyfikowanego przez tag HTML.
Scrapy identyfikuje dane do pobrania na podstawie podanych selektorów. Możemy użyć selektorów, aby znaleźć jeden lub więcej elementów na stronie i pobrać dane znajdujące się w tych elementach. Scrapy obsługuje selektory XPath oraz CSS.
Z kodu źródłowego, który przeglądaliśmy wcześniej, selektory CSS wydają się łatwiejsze. Dlatego też wybierzemy tę opcję, ponieważ pomoże nam ona znaleźć wszystkie poradniki na stronie. W kodzie źródłowym HTML każdy poradnik jest określony w klasie CSS o nazwie post. Nazwy klas CSS są zazwyczaj identyfikowane za pomocą .nazwa_klasy (kropka nazwa_klasy). W związku z tym jako naszego selektora CSS użyjemy .post. Wewnątrz kodu źródłowego naszego scrapera main.py przekażemy klasę .post do obiektu response, dzięki czemu Twój plik będzie teraz wyglądał tak:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
Ten fragment kodu pobierze wszystkie samouczki na stronie o określonym start_urls i przejdzie w pętli przez te samouczki, aby wyodrębnić dane. W następnym kroku będziesz chciał wyodrębnić i wyświetlić te dane. Jeśli ponownie przeanalizujesz kod źródłowy bloga CloudSigma ponownie, zobaczysz, że tytuł każdego samouczka jest przechowywany wewnątrz znacznika <a>, który znajduje się wewnątrz znacznika <h2>, na przykład:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
Każdy obiekt samouczka, po którym iterujemy, zawiera metodę CSS, do której możemy przekazać selektor w celu zlokalizowania i wyodrębnienia elementów podrzędnych. W tym przykładzie chcemy wyodrębnić tytuł, który jest zamknięty wewnątrz znacznika <a>. Ten znacznik znajduje się wewnątrz znacznika <h2> wewnątrz klasy .entry-header wewnątrz klasy .entry-wrap. Możemy przekazać te selektory CSS do metody obiektu, aby wyodrębnić tytuł, modyfikując kod w następujący sposób:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
Przecinek na końcu po extract_first() nie jest literówką, ponieważ poniżej tej sekcji będziemy dodawać kolejny kod.
Niektóre kwestie warte uwagi w powyższym kodzie źródłowym to:
- ::text dołączone do selektora – jest to pseudoselektor CSS który instruuje kod, aby pobrał tekst wewnątrz znacznika, a nie sam znacznik.
- wywołanie metody extract_first() w obiekcie – instruuje kod, aby wybrał tylko pierwszy element pasujący do selektora. W rezultacie otrzymujemy ciąg znaków (string), a nie listę elementów.
Następnie zapisz plik i uruchom kod, wpisując następujące polecenie w terminalu:
|
1 |
scrapy runspider main.py |
W wynikach powinieneś zobaczyć tytuły samouczków:
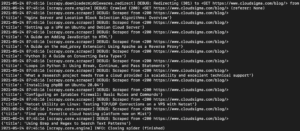
Możemy to dalej rozwijać, dodając więcej selektorów, aby uzyskać inne szczegóły dotyczące samouczka, takie jak adres URL samouczka, wyróżniony obrazek i podpis.
Przyjrzyjmy się ponownie kodowi HTML pojedynczego samouczka:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="Bezpośredni odnośnik do: "Securing Apache with Let’s Encrypt on Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Bezpośredni odnośnik do: "Zabezpieczanie Apache za pomocą Let’s Encrypt na Ubuntu 18.04"">Zabezpieczanie Apache za pomocą Let’s Encrypt na Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Bezpieczeństwo stron internetowych i danych to tematy, których nie można lekceważyć. Bardzo poufne informacje, które obejmują dokumentację finansową i prywatne informacje klientów, są zawsze przesyłane między komputerem użytkownika a Twoją witryną. Biorąc pod uwagę ten fakt, łatwo zrozumieć, dlaczego niezabezpieczone strony internetowe mogą doprowadzić do naruszenia bezpieczeństwa, które mogłoby poważnie zaszkodzić Twojej firmie. Istnieje … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Czytaj więcej</a></div> </div> </div> </article> </div> </body> |
Chcemy spróbować wyodrębnić wyróżnione elementy, tj. adres URL samouczka, wyróżniony obrazek i podpis.
- Z powyższego fragmentu kodu wynika, że obrazek dla bloga jest przechowywany w atrybucie data-lazy-src znacznika img wewnątrz znacznika <a> wewnątrz znacznika div na początku samouczka na blogu. Możemy użyć selektora CSS, aby pobrać tę wartość, tak jak to zrobiliśmy z tytułami samouczków.
- Uzyskanie adresu URL samouczka jest proste, ponieważ mamy znacznik <a> wewnątrz elementu <div>.
- Podpis jest zamknięty wewnątrz znacznika <p>, który znajduje się wewnątrz znacznika <div>.
Użyjemy klas CSS, aby uzyskać to, co chcemy. Zmodyfikujmy kod, aby wyglądał tak:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
Zapisz zmiany i uruchom kod za pomocą następującego polecenia:
|
1 |
scrapy runspider main.py |
W danych wyjściowych zobaczysz więcej danych, takich jak dodany przez nas adres URL, obraz i podpis:

To wszystko, jeśli chodzi o pobieranie danych z pojedynczej strony. Następnie zobaczmy, jak możemy stworzyć scraper, który podąża za linkami.
Krok 3: Jak pobierać dane z wielu stron
Do tego momentu stworzyliśmy scraper, który potrafi pobierać dane z pojedynczej strony. Chcemy jednak czegoś więcej. Potrzebujesz spidera, który potrafi podążać za linkami i programowo pobierać dane z wielu stron witryny.
Jeśli przejdziesz na dół strony bloga CloudSigma, zauważysz linki do stron (paginację) oraz małą strzałkę skierowaną w prawo, wskazującą następną stronę. Oto fragment kodu HTML:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Strona 1 z 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Ostatnia strona">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Fragment kodu pokazuje kilka linków nawigacji stron wewnątrz tagów <li>, pod tagiem <div> z klasą CSS .x-pagination. Skupiamy się na linku prowadzącym do następnej strony. Znajduje się on w tagu <a> ostatniego elementu <li> w tagu <ul>.
Link prowadzący do następnej strony ma klasę .prev-next wewnątrz tagu <a>, jak widać w powyższym fragmencie kodu. Jeśli jednak przejdziesz do następnej strony, zauważysz również, że linki do poprzedniej i następnej strony mają tę klasę CSS. Rozważ ten fragment kodu dla Strony 2:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Strona 2 z 45</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Ostatnia strona">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Jeśli użyjemy metody Scrapy extract_first(), zadziała ona na pierwszej stronie. Kiedy dotrze do następnej strony, wybierze pierwszy link z klasą .prev-next, który w powyższym fragmencie kodu wskazuje na pierwszą stronę. Spowoduje to powstanie pętli. Dlatego użyjemy metody Scrapy extract(). Metoda ta wyodrębnia wszystkie elementy pasujące do danego przypadku użycia i umieści je w tablicy. Z tej tablicy możemy wybrać ostatni element, który będzie zawierał rzeczywisty link prowadzący do następnej strony. Zmodyfikuj swój kod, aby wyglądał następująco:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Przejdźmy przez kod służący do wyboru next_page.
Najpierw definiujemy selektor dla linków do następnej i poprzedniej strony. Następnie używamy metody extract(), aby wyodrębnić adresy URL i umieścić je w tablicy. Zmienna next_page będzie tablicą z dwoma elementami, takimi jak:
|
1 |
next_page = [prev_page_url, next_page_url] |
Ponieważ przechodzimy do następnej strony, wybierzemy ostatni element z tablicy. Next_page[-1] wybiera ostatni element z tablicy.
Blok if sprawdza, czy zmienna next_page coś zawiera, a następnie wywołuje metodę scrapy.Request(). W naszym kodzie instruujemy tę metodę, aby przeszukała stronę o podanym adresie URL i przekazała ją z powrotem do metody parse(), dzięki czemu możemy ją przeanalizować w celu wyodrębnienia danych i powtórzyć proces dla następnej strony. Proces ten jest powtarzany, dopóki nie zostanie znaleziony link do następnej strony, a raczej jeśli blok się nie powiedzie, wtedy się zatrzymuje.
Zapisz swój kod i uruchom go. Zauważysz, że iteracja kontynuuje pętlę po stronach, gdy znajduje więcej stron do pobrania danych. W ten sposób definiuje się scraper, który podąża za linkami na stronie internetowej. Nasz przykład jest dość prosty. Wchodzimy tylko na stronę, znajdujemy link do następnej strony i powtarzamy proces. W innych przypadkach użycia możesz chcieć podążać za tagami lub linkami prowadzącymi do zewnętrznych źródeł i nie tylko. Oto kompletny kod źródłowy podstawowego scrapera internetowego w języku Python 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Podsumowanie
W tym samouczku zbudowaliśmy podstawowy web scraper, który może przeszukiwać blog CloudSigma i wyświetlać informacje o samouczkach na blogu w zaledwie około 27 linijkach kodu.
Oczywiście jest to możliwe, ponieważ zbudowaliśmy go w oparciu o bibliotekę Scrapy dla języka Python. To tylko fundament, który powinien pomóc Ci budować bardziej złożone scrapery, śledzące więcej tagów, wyniki wyszukiwania witryn i nie tylko. Możesz sprawdzić oficjalną dokumentację Scrapy, aby uzyskać więcej informacji na temat pracy ze Scrapy.
Miłego programowania!
Komentarze
Brak komentarzy. Bądź pierwszy.