

CloudSigma pozwala klientom na dodawanie procesorów graficznych (GPU) do ich maszyn wirtualnych i korzystanie z wysokowydajnych, opłacalnych obliczeń, które mogą sprostać najbardziej wymagającym obciążeniom. Sercem oferty GPU firmy CloudSigma jest procesor graficzny NVIDIA A100 Tensor Core zoptymalizowany pod kątem HPC, sztucznej inteligencji (AI) i analityki danych. A100 przewyższa wydajnością model NVIDIA TESLA V100 i posiada nowe funkcje, z których aplikacje AI mogą w pełni korzystać. Umożliwiamy klientom łatwe tworzenie zoptymalizowanych maszyn wirtualnych z NVIDIA A100 w trybie passthrough, dzięki czemu instancje maszyn wirtualnych mają bezpośrednią kontrolę nad procesorami GPU i ich wbudowaną pamięcią.
Przypadki użycia
Wzrost liczby aplikacji wymagających intensywnych obliczeń uruchamianych w chmurze doprowadził do niedawnej eksplozji przetwarzania w chmurze przyspieszanego przez GPU. Aplikacje te obejmują m.in. uczenie i wnioskowanie głębokiego uczenia AI, analitykę danych, obliczenia naukowe, genomikę, renderowanie grafiki i gry. Od skalowania w górę uczenia AI i obliczeń naukowych, przez skalowanie w poziomie aplikacji wnioskowania, po umożliwienie konwersacyjnej sztucznej inteligencji w czasie rzeczywistym, procesory GPU zapewniają moc niezbędną do przyspieszenia licznych złożonych i nieprzewidywalnych obciążeń uruchamianych w chmurze.
Procesor graficzny NVIDIA A100 Tensor Core stanowi gigantyczny krok naprzód, zapewniając bezprecedensowe przyspieszenie dla AI, analityki danych i HPC w każdej skali. Napędzany architekturą NVIDIA Ampere, A100 zapewnia do 20-krotnie wyższą wydajność w porównaniu z poprzednią generacją. CloudSigma udostępnia wersję z 80 GB pamięci, oferującą najszybszą na świecie przepustowość wynoszącą ponad 2 terabajty na sekundę (TB/s) do uruchamiania największych modeli i zbiorów danych.
Procesory graficzne NVIDIA należą do wiodących silników obliczeniowych napędzających sztuczną inteligencję, zapewniając znaczne przyspieszenie obciążeń związanych z uczeniem i wnioskowaniem AI. Ponadto procesory graficzne NVIDIA przyspieszają wiele rodzajów aplikacji i systemów HPC oraz analityki danych, przekształcając dane w gotowe wnioski.
AI i HPC
Trenuj złożone modele uczenia maszynowego szybciej i wydajniej dzięki akceleracji GPU. Radź sobie z zadaniami wymagającymi intensywnego przetwarzania danych i osiągaj przełomy w innowacjach napędzanych przez AI.NVIDIA AI Enterprise to kompleksowy, natywny dla chmury pakiet oprogramowania do sztucznej inteligencji i analityki danych, zoptymalizowany pod kątem umożliwienia każdej organizacji korzystania z AI. Posiada certyfikat do wdrażania w chmurze publicznej i obejmuje globalne wsparcie dla przedsiębiorstw, aby utrzymać projekty AI na właściwym torze. A100 pozwala naukowcom na szybkie dostarczanie rzeczywistych wyników i wdrażanie rozwiązań produkcyjnych na dużą skalę.
TRENOWANIE GŁĘBOKIEGO UCZENIA
Trenowanie modeli AI wymaga ogromnej mocy obliczeniowej i skalowalności. Rdzenie NVIDIA A100 Tensor z technologią Tensor Float (TF32) zapewniają do 20-krotnie wyższą wydajność w porównaniu z NVIDIA Volta przy zerowych zmianach w kodzie oraz dodatkowe 2-krotne przyspieszenie dzięki automatycznej mieszanej precyzji i FP16.
Obciążenie treningowe, takie jak BERT, może zostać rozwiązane na dużą skalę w czasie krótszym niż minuta przez 2048 procesorów graficznych A100, co stanowi rekord świata w czasie uzyskania rozwiązania.
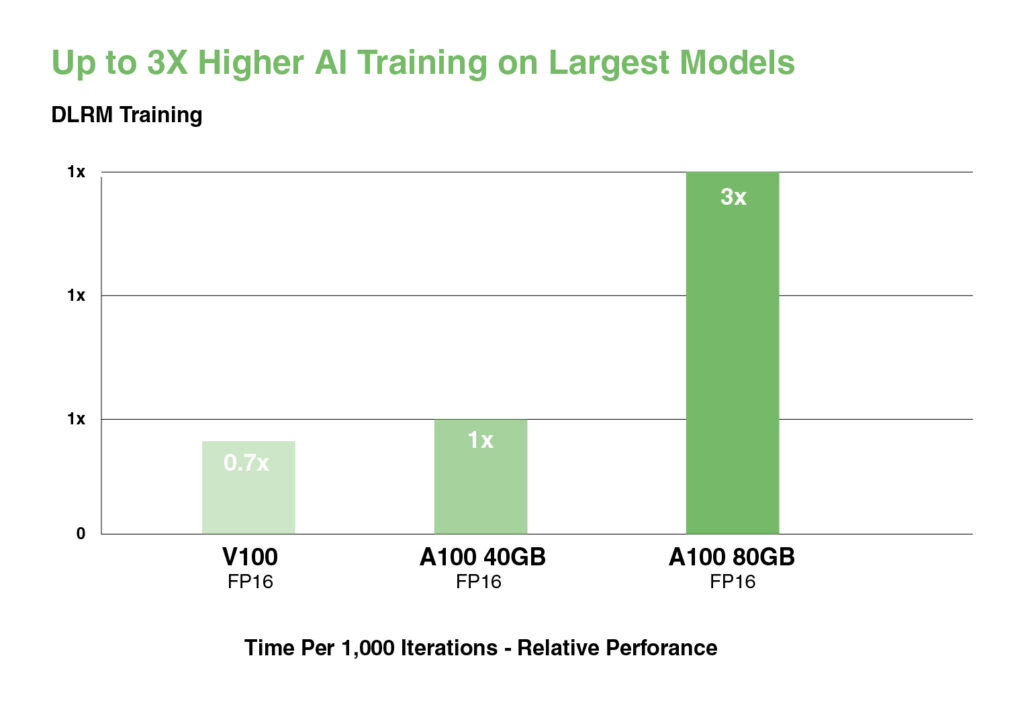
W przypadku największych modeli z ogromnymi tabelami danych, takich jak modele rekomendacyjne głębokiego uczenia (DLRM), A100 80GB osiąga do 1,3 TB zunifikowanej pamięci na węzeł i zapewnia do 3-krotnego wzrostu przepustowości w porównaniu z A100 40GB.
Liderująca pozycja firmy NVIDIA w MLPerf, ustanawiająca liczne rekordy wydajności w branżowym teście porównawczym dla trenowania AI.
WNIOSKOWANIE GŁĘBOKIEGO UCZENIA
A100 wprowadza przełomowe funkcje optymalizujące obciążenia związane z wnioskowaniem. Przyspiesza pełen zakres precyzji od FP32 do INT4. Technologia Multi-Instance GPU (MIG) umożliwia jednoczesne działanie wielu sieci na jednym układzie A100 w celu optymalnego wykorzystania zasobów obliczeniowych. Z kolei obsługa rzadkości strukturalnej (structural sparsity) zapewnia do 2-krotnie wyższą wydajność oprócz innych przyrostów wydajności wnioskowania A100.
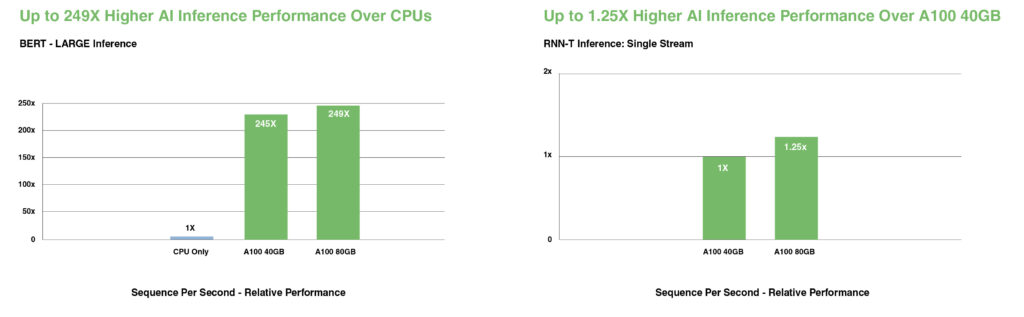
W najnowocześniejszych modelach konwersacyjnej sztucznej inteligencji, takich jak BERT, A100 przyspiesza przepustowość wnioskowania nawet 249-krotnie w porównaniu z procesorami CPU.
W przypadku najbardziej złożonych modeli o ograniczonej wielkości partii (batch-size), takich jak RNN-T do automatycznego rozpoznawania mowy, zwiększona pojemność pamięci A100 80GB podwaja rozmiar każdego MIG i zapewnia do 1,25-krotnie wyższą przepustowość w porównaniu z A100 40GB.
Wiodąca na rynku wydajność firmy NVIDIA została zademonstrowana w teście MLPerf Inference. A100 zapewnia 20-krotnie wyższą wydajność, aby jeszcze bardziej umocnić tę pozycję lidera.
OBLICZENIA O WYSOKIEJ WYDAJNOŚCI
Aby dokonać odkryć nowej generacji, naukowcy sięgają po symulacje, które pozwalają lepiej zrozumieć otaczający nas świat.
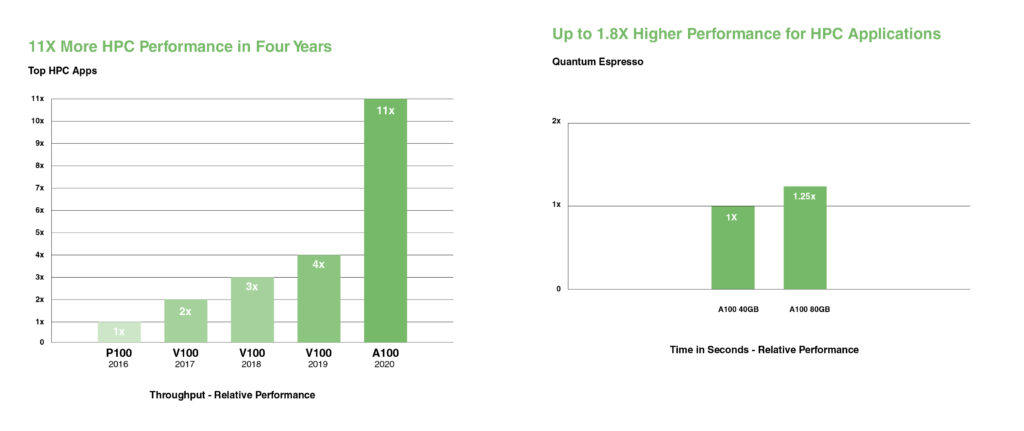
NVIDIA A100 wprowadza rdzenie Tensor o podwójnej precyzji, zapewniając największy skok wydajności HPC od czasu wprowadzenia procesorów GPU. Dzięki 80 GB najszybszej pamięci GPU badacze mogą skrócić 10-godzinną symulację o podwójnej precyzji do poniżej czterech godzin na układzie A100. Aplikacje HPC mogą wykorzystać format TF32, aby osiągnąć do 11-krotnie wyższą przepustowość w operacjach mnożenia macierzy gęstych o pojedynczej precyzji.
W przypadku aplikacji HPC z największymi zbiorami danych, dodatkowa pamięć procesora A100 80GB zapewnia nawet 2-krotny wzrost przepustowości w Quantum Espresso, symulacji materiałowej. Ta ogromna pamięć i bezprecedensowa przepustowość pamięci czynią z A100 80GB idealną platformę dla obciążeń nowej generacji.
ANALIZA DANYCH O WYSOKIEJ WYDAJNOŚCI
Analitycy danych muszą mieć możliwość analizowania, wizualizowania i przekształcania ogromnych zbiorów danych w praktyczne wnioski. Jednak rozwiązania skalowalne w poziomie są często spowalniane przez zbiory danych rozproszone na wielu serwerach.
Akcelerowane serwery z procesorami A100 zapewniają niezbędną moc obliczeniową — ogromną pamięć, ponad 2 TB/s przepustowości pamięci oraz skalowalność dzięki technologiom NVIDIA® NVLink® i NVSwitch™ — do obsługi tych obciążeń. W połączeniu z rozwiązaniami InfiniBand, NVIDIA Magnum IO™ oraz pakietem bibliotek open-source RAPIDS™, w tym RAPIDS Accelerator dla Apache Spark do akcelerowanej przez GPU analizy danych, platforma centrum danych NVIDIA przyspiesza te ogromne obciążenia, zapewniając bezprecedensowy poziom wydajności i efektywności.
W teście porównawczym analizy dużych zbiorów danych procesor A100 80GB dostarczył wyniki z 2-krotnym wzrostem wydajności w porównaniu do A100 40GB, co czyni go idealnym rozwiązaniem dla nowo powstających obciążeń o gwałtownie rosnących rozmiarach zbiorów danych.
SYMULACJE NAUKOWE: Przyspieszaj badania naukowe i symulacje, umożliwiając szybsze wyciąganie wniosków i dokonywanie odkryć w dziedzinie fizyki, chemii i nauk o środowisku.
MEDIA I ROZRYWKA: Renderuj grafikę o wysokiej rozdzielczości, wideo i animacje z błyskawiczną prędkością. Dostarczaj widzom wyjątkowe wrażenia wizualne bez kompromisów w kwestii jakości.
MODELOWANIE FINANSOWE: Analizuj ogromne zbiory danych i przeprowadzaj złożone modelowanie finansowe z niezrównaną prędkością, dostarczając kluczowych informacji do podejmowania świadomych decyzji.
Komentarze
Brak komentarzy. Bądź pierwszy.