
Django to wysokopoziomowy, otwartoźródłowy Python framework webowy, który pomoże Ci szybko zbudować aplikację w Pythonie. Wspiera on szybkie tworzenie oprogramowania oraz czysty, pragmatyczny design, opierając się na wzorcu architektonicznym model-szablon-widok (model–template–views). Po wyjęciu z pudełka framework oferuje niezbędne komponenty nowoczesnej aplikacji, takie jak uwierzytelnianie użytkowników, framework buforowania, mapowanie obiektowo-relacyjne, dyspenser adresów URL, system szablonów, oraz konfigurowalny interfejs administracyjny.
Gunicorn ‘Green Unicorn’ to serwer HTTP WSGI w języku Python dla systemów UNIX. Serwer Gunicorn jest kompatybilny z różnymi frameworkami webowymi, oferuje świetną wydajność i nie obciąża zasobów serwera. Docker to otwartoźródłowa platforma kontenerowa, która istnieje już od dłuższego czasu, czyniąc rozwój aplikacji szybkim, wydajnym i przewidywalnym.
W tym samouczku zdobędziesz umiejętności w zakresie tworzenia i wdrażania skalowalnych, skonteneryzowanych aplikacji webowych Django. Będziemy korzystać z aplikacji Django Polls stworzonej zgodnie z wprowadzającymi przewodnikami rozpoczęcia pracy z Django. W momencie pisania tego samouczka opieraliśmy się na Django 3.2 wspieranym przez Python 3.6 lub nowszym. Wdrożymy aplikację jako kontener za pomocą Dockera i uruchomimy ją przy użyciu serwera Gunicorn. Oczywiście przed wdrożeniem aplikacji Django w kontenerze konieczne będzie wprowadzenie pewnych modyfikacji w kodzie projektu, aby obsłużyć takie kwestie jak logowanie do standardowych strumieni wyjściowych czy praca ze zmiennymi środowiskowymi. Pliki statyczne, takie jak obrazy, CSS i JavaScript, mogą zostać przeniesione do usług przechowywania obiektowego, co ułatwi zarządzanie nimi z jednej lokalizacji w środowisku wielokontenerowym.
Pokażemy Ci, jak wdrożyć te modyfikacje w oparciu o dobrze opisaną metodologię twelve-factor służącą do budowania skalowalnych aplikacji webowych. Po zakończeniu modyfikacji zbudujesz obraz Docker aplikacji i wdrożysz skonteneryzowaną aplikację za pomocą Dockera. Zalecamy postępowanie zgodnie z krokami opisanymi w samouczku, aby w pełni go zrozumieć.
Wymagania wstępne
Ponieważ jest to praktyczny samouczek, zachęcamy do przygotowania poniższej konfiguracji, która ułatwi śledzenie kroków:
-
Serwer Ubuntu 20.04. Możesz wykonać kroki od 1 do 4 z tego samouczka krok po kroku, który pomoże Ci skonfigurować serwer Ubuntu na CloudSigma.
-
Upewnij się, że dodasz użytkownika z uprawnieniami sudo na obu węzłach, których użyjemy do uruchamiania poleceń opisanych w powyższym samouczku.
-
Zainstaluj Dockera na serwerze. Możesz wykonać kroki 1, 2 i 3 z naszego samouczka dotyczącego instalacji i obsługi Dockera. Pamiętaj, aby dodać utworzonego powyżej użytkownika sudo do grupy Docker.
-
Kompatybilna przestrzeń przechowywania obiektowego. Django obsługuje kilka usług przechowywania danych, wymienionych w dokumentacji django-storages. Możesz wybrać preferowaną usługę i postępować zgodnie z dokumentacją, aby ją skonfigurować. W tym samouczku będziemy używać MinIO będącego usługą przechowywania w chmurze kompatybilną z S3.
-
Instancja bazy danych SQL. Django obsługuje kilka baz danych SQL które możesz swobodnie wybrać. W tym samouczku będziemy używać PostgreSQL. Baza danych PostgreSQL nie zostanie wdrożona wewnątrz kontenera. Skonfigurujemy osobny serwer Ubuntu do hostowania instancji PostgreSQL, aby zapewnić konfigurację wielokontenerową oraz trwałość danych. Możesz utworzyć kolejną instancję Ubuntu 20.04 i postępować zgodnie z tym samouczkiem, aby Skonfigurować instancję bazy danych PostgreSQL na Ubuntu. Pamiętaj, aby dodać rolę w bazie danych PostgreSQL dla swojego użytkownika sudo, jak wyjaśniono w krokach 2 i 3. Rola ta pozwoli Ci na połączenie się z bazą danych z innych serwerów hostujących Twoje kontenery.
Zgodnie z tymi wymaganiami wstępnymi powinieneś mieć dwie instancje serwera Ubuntu. Na jednej instancji będzie działać Twój kontener Docker, a na drugiej instancja PostgreSQL. Zaczynajmy!
Krok 1: Konfiguracja instancji bazy danych PostgreSQL
W tej sekcji zmodyfikujemy konfiguracje Postgres na serwerze Ubuntu, na którym działa instancja Postgres. Pozwoli to na połączenia z zewnętrznego adresu IP. Po połączeniu będziemy mogli utworzyć bazę danych i rolę użytkownika, specyficzne dla wdrażanej aplikacji Django Polls.
Po pierwsze, jeśli skonfigurowałeś swoje środowisko zgodnie z Wymaganiami wstępnymi, powinieneś mieć rolę w bazie danych PostgreSQL dla swojego użytkownika sudo. Następnie musimy ustawić hasło dla tej roli. Będąc na serwerze z uruchomionym PostgreSQL, zaloguj się do terminala Postgres za pomocą następującego polecenia:
|
1 |
sudo -u postgres psql |
Po wejściu do terminala Postgres wydaj polecenie \password służące do zmiany hasła użytkownika. Składnia polecenia \password brzmi \password <username>. W naszym przypadku polecenie to:
|
1 |
\password cloudsigma |
Wprowadź hasło i potwierdź je. Zapisz to hasło w bezpiecznym miejscu, ponieważ użyjesz go później do uwierzytelnienia z drugiego serwera Ubuntu. Następnie wpisz exit i naciśnij Enter, aby wyjść z terminala Postgres.
Jeśli włączyłeś zaporę sieciową (ufw) na instancji serwera PostgreSQL, musisz zezwolić na ruch do domyślnego portu Postgres 5432. Możesz ograniczyć ruch tak, aby pochodził wyłącznie z określonego adresu IP drugiego serwera Ubuntu, na którym będzie uruchomiony kontener Docker. Wykonaj następujące polecenie, aby dodać regułę ufw, zastępując swój adres IP w wyróżnionym miejscu:
|
1 |
sudo ufw allow from ubuntu_server_ip_address to any port 5432 |
Zapewni to, że tylko Twój serwer będzie mógł połączyć się z instancją PostgreSQL. Chociaż pozwala to na ruch przez zaporę sieciową, musisz również zmodyfikować pliki konfiguracyjne PostgreSQL, aby umożliwić połączenie ze zdalnego adresu IP. Domyślnie konfiguracja pozwala tylko na połączenie z localhost. Pliki konfiguracyjne PostgreSQL znajdują się w katalogu /etc/postgresql/12/main . 12 w tym przypadku to wersja PostgreSQL zainstalowana na potrzeby tego samouczka. Mogłeś zainstalować inną wersję. W związku z tym możesz przejść do katalogu /etc/postgresql/ i wyświetlić zawartość, aby znaleźć numer wersji zainstalowanego PostgreSQL.
Użyj nano, aby zmodyfikować plik konfiguracyjny:
|
1 |
sudo nano /etc/postgresql/12/main/postgresql.conf |
Znajdź poniższą linię, odkomentuj ją i ustaw tak, aby zezwalała na połączenia ze wszystkich adresów IP:
|
1 |
listen_addresses = '*' |
Zapisz i zamknij plik. Następnie musisz edytować również plik pg_hba.conf, znajduje się on w tym samym katalogu co postgresql.conf. Plik pg_hba.conf pozwala zdefiniować, z których komputerów można łączyć się z instancją PostgreSQL, a także metodę uwierzytelniania. Otwórz plik za pomocą nano:
|
1 |
sudo nano /etc/postgresql/12/main/pg_hba.conf |
Przeczytaj komentarze w tym pliku, aby zrozumieć słowa kluczowe. Sekcja, której szukamy, to:
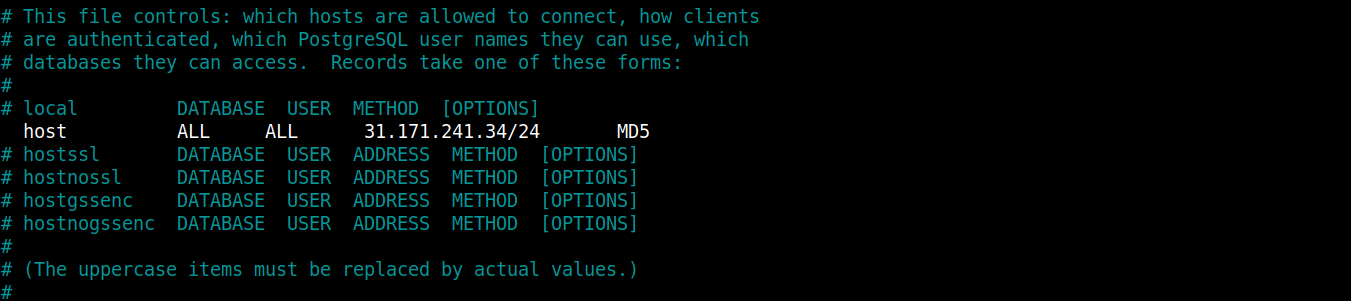
Skupimy się na drugiej linii, po odkomentowaniu powinna wyglądać jak poniższa linia:
|
1 |
host all all your_ubuntu_server_ip/24 md5 |
Zastąp wyróżnioną część adresem IP swojego serwera Ubuntu, aby umożliwić mu połączenie z instancją PostgreSQL. Zapisz plik, gdy będziesz gotowy. Uruchom ponownie bazę danych PostgreSQL, aby zmiany weszły w życie:
|
1 |
sudo service postgresql restart |
Nasz drugi serwer Ubuntu o określonym adresie IP powinien być teraz w stanie połączyć się z instancją Postgres.
Krok 2: Łączenie z instancją serwera PostgreSQL oraz tworzenie bazy danych i użytkownika
W tym kroku postaramy się upewnić, że instancja Ubuntu obsługująca nasz kontener Docker może połączyć się z drugim serwerem, na którym działa instancja PostgreSQL. Zaloguj się do instancji Ubuntu z zainstalowanym Dockerem i zainstaluj pakiet postgresql-client wewnątrz maszyny hosta Ubuntu (jeszcze nie wewnątrz kontenera).
Standardowo najpierw zaktualizuj pakiety apt, a następnie zainstaluj pakiet za pomocą następujących poleceń:
|
1 |
sudo apt update |
|
1 |
sudo apt install postgresql-client |
Zainstalowany powyżej pakiet pomoże Ci w utworzeniu bazy danych i użytkownika dla Twojej aplikacji. Następnie musimy połączyć się z instancją PostgreSQL, przekazując parametry połączenia do klienta PostgreSQL.
Parametry połączenia są zgodne z następującą składnią:
|
1 |
psql -U username -h host -p port -d database --set=sslmode=require |
W tym poleceniu username to użytkownik/rola dodana do bazy danych PostgreSQL. host to adres IP instancji Ubuntu, na której działa baza danych PostgreSQL. port to domyślny port, na którym Postgres nasłuchuje połączeń przychodzących, tj. 5432. W miejsce database, użyjemy domyślnej bazy danych o nazwie postgres dostarczanej wraz z instalacją PostgreSQL. Zastąp odpowiednio wartości w wyróżnionych częściach i naciśnij Enter. Po wyświetleniu monitu wprowadź ustawione hasło. Spowoduje to zalogowanie do wiersza poleceń Postgres, gdzie można zarządzać bazą danych.
Pomyślnie połączono z instancją PostgreSQL. Możesz teraz utworzyć bazę danych dla aplikacji ankiet Django (polls). Nazwijmy ją django_polls:
|
1 |
CREATE DATABASE django_polls; |
Upewnij się, że instrukcja kończy się średnikiem, aby uniknąć błędów. Następnie przełącz się na bazę danych django_polls za pomocą polecenia:
|
1 |
\c django_polls; |
Następnie utwórz użytkownika bazy danych dedykowanego dla tego projektu. Nazwijmy go django_user:
|
1 |
CREATE USER django_user WITH PASSWORD 'password'; |
Wybierz bezpieczne hasło dla swojego użytkownika. Po zakończeniu musimy zmodyfikować parametry połączenia dla właśnie utworzonego użytkownika. Pomaga to przyspieszyć operacje na bazie danych, zapewniając, że poprawne wartości nie są odpytywane i ustawiane przy każdym nawiązywaniu połączenia.
Uset domyślne kodowanie oczekiwane przez Django na UTF-8:
|
1 |
ALTER ROLE django_user SET client_encoding TO 'utf8'; |
Następnie ustaw domyślny schemat izolacji transakcji na „ read committed”, co blokuje odczyty z niezatwierdzonych transakcji:
|
1 |
ALTER ROLE django_user SET default_transaction_isolation TO 'read committed'; |
Ustaw swoją strefę czasową. Aby samouczek był uniwersalny, użyjemy UTC:
|
1 |
ALTER ROLE django_user SET timezone TO 'UTC'; |
Na koniec nadaj uprawnienia administracyjne do bazy danych nowemu użytkownikowi:
|
1 |
GRANT ALL PRIVILEGES ON DATABASE django_polls TO django_user; |
Wyjdź z wiersza poleceń PostgreSQL, gdy będziesz gotowy:
|
1 |
\q |
To wszystko w tym kroku. Po prawidłowym skonfigurowaniu aplikacji Django powinna ona być w stanie zarządzać Twoją bazą danych.
Krok 3: Pobieranie aplikacji z repozytorium Git i definiowanie zależności
W tym kroku sklonujemy repozytorium aplikacji Django-polls. To repozytorium zawiera kod do samouczka Django „Napisz swoją pierwszą aplikację w Django”.
Zaloguj się na serwer Ubuntu z uruchomionym Dockerem, utwórz katalog o nazwie django_project i przejdź do niego:
|
1 2 |
mkdir django_project cd django_project |
Następnie sklonuj repozytorium do katalogu za pomocą następującego polecenia:
|
1 |
git clone https://github.com/jaymoh/django-polls.git |
Przejdź do katalogu i wyświetl jego zawartość:
|
1 |
cd django-polls |
Wyświetl zawartość katalogu:
|
1 |
ls |

Zwróć uwagę na następujące elementy:
-
manage.py: ten plik jest punktem wejścia do narzędzia wiersza poleceń, które Django udostępnia do zarządzania aplikacją.
-
mysite: katalog zawierający zakres projektu Django i ustawienia kodu.
-
polls: katalog zawierający kod aplikacji polls .
-
templates: zawiera niestandardowe pliki szablonów dla stron administracyjnych.
Aby dowiedzieć się więcej o tym, jak faktycznie utworzyliśmy projekt, zapoznaj się z „Napisz swoją pierwszą aplikację w Django” w oficjalnej dokumentacji. Wewnątrz django-polls katalogu chcemy mieć nasze zależności Pythona zdefiniowane w pliku tekstowym. Nazwiemy go requirements.txt. Otwórz plik w swoim preferowanym edytorze:
|
1 |
nano requirements.txt |
Wklej następujące linie do pliku, aby zadeklarować zależności:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Django==3.2.9 gunicorn==20.1.0 docutils==0.18.1 sqlparse==0.4.2 jmespath==0.10.0 psycopg2==2.9.2 python-dateutil==2.8.2 pytz==2021.3 six==1.16.0 urllib3==1.26.7 django-storages==1.12.2 minio==7.1.6 django-minio-backend==3.3.2 django-dotenv==1.4.2 boto3==1.21.38 |
W tym pliku zdefiniowaliśmy zależności Pythona wraz z ich dokładnymi wersjami, które powinny zostać zainstalowane podczas budowania aplikacji. Niektóre z nich to Django, django-storages do interakcji z kontenerami obiektowej pamięci masowej, adapter psycopg2 dla PostgreSQL, serwer WSGI gunicorn oraz inne dodatkowe zależności. Zapisz i zamknij plik po zakończeniu.
Krok 4: Konfiguracja zmiennych środowiskowych dla aplikacji Django
Metodologia twelve-factor app zaleca wyodrębnienie zakodowanych na stałe konfiguracji z kodu źródłowego aplikacji. Dzięki temu zyskujesz swobodę zmiany zachowania aplikacji w czasie jej działania poprzez modyfikację zmiennych środowiskowych bez dotykania kodu źródłowego. Docker współpracuje z tą konfiguracją, więc zmodyfikujemy plik ustawień, aby działał ze zmiennymi środowiskowymi. Kubernetes również współpracuje z tą konfiguracją. Udostępnimy kolejny poradnik dotyczący wdrażania z Kubernetes na blogu CloudSigma.
Plik settings.py to główny plik ustawień projektu Django. Jest to moduł Pythona, który używa natywnych struktur danych do konfiguracji aplikacji. W przypadku naszej aplikacji plik znajduje się w lokalizacji django-polls/mysite/settings.py. Większość jego wartości jest zakodowana na stałe. Wymagałoby to modyfikacji pliku konfiguracyjnego w kodzie źródłowym w przypadku zmiany zachowania aplikacji. Chcemy to zmienić. Na szczęście Python oferuje funkcję getenv w module os . Możemy jej użyć, aby skonfigurować Django do odczytywania parametrów konfiguracyjnych z lokalnych zmiennych środowiskowych.
Kontynuujmy, modyfikując plik django-polls/mysite/settings.py, aby zastąpić zakodowane na stałe wartości zmiennych, które możemy chcieć aktualizować w czasie działania programu za pomocą wywołania os.getenv. Funkcja ta odczytuje wartość ustawioną dla podanej nazwy zmiennej środowiskowej. Opcjonalnie można podać drugi parametr, będący wartością domyślną, która zostanie użyta, jeśli zmienna środowiskowa nie jest ustawiona.
Oto przykład:
|
1 |
SECRET_KEY = os.getenv('DJANGO_SECRET_KEY') |
W powyższej linii nakazujemy Django pobranie klucza tajnego ze zmiennej środowiskowej. Nie podajemy wartości domyślnej, ponieważ klucz dostarczymy z zewnątrz. Jeśli nie istnieje, aplikacja nie powinna się uruchomić. Dostarczając klucz tajny z zewnątrz, chcemy również upewnić się, że wszystkie skonteneryzowane kopie aplikacji używają tego samego klucza na różnych serwerach. Pozwala to uniknąć potencjalnych problemów wynikających z używania różnych kluczy przez poszczególne kopie aplikacji.
Oto kolejny przykład z opcją domyślną:
|
1 |
DEBUG = os.getenv('DEBUG', False) |
W tej linii definiujemy zmienną środowiskową DEBUG, która powinna zostać odczytana. Jeśli jednak nie jest ona ustawiona, podaliśmy drugi parametr, który zostanie przekazany do zmiennej ustawień DEBUG. DEBUG jest ustawiona na False, aby upewnić się, że poufne informacje nie zostaną przekazane do frontendu w przypadku problemów z aplikacją. Jeśli jednak jesteśmy w trybie deweloperskim, chcemy, aby była ustawiona na True, co pozwoli nam zobaczyć informacje o błędach i ułatwi ich naprawianie.
Skoro już wiesz, jak ważne są zmienne środowiskowe, otwórz plik django_project/django-polls/settings.py w swoim edytorze. Najpierw zaimportuj moduł os, dodając tę linię na samej górze pliku settings.py:
|
1 |
import os |
Następnie znajdź te zmienne i zaktualizuj je w następujący sposób:
|
1 2 3 |
SECRET_KEY = os.getenv('DJANGO_SECRET_KEY') DEBUG = os.getenv('DEBUG', False) ALLOWED_HOSTS = os.getenv('DJANGO_ALLOWED_HOSTS', '127.0.0.1').split(',') |
W ustawieniu ALLOWED_HOSTS, określamy, że powinno ono pobierać wartość ze zmiennej środowiskowej DJANGO_ALLOWED_HOSTS i dzielić ją na listę Pythona przy użyciu przecinka ( ,) jako separatora. Jeśli zmienna nie istnieje, ALLOWED_HOSTS jest ustawiane na 127.0.0.1.
Następnie przewiń plik i znajdź sekcję DATABASES, skonfiguruj ją tak, aby również czytała ze zmiennych środowiskowych:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.{}'.format( os.getenv('DB_ENGINE', 'sqlite3') ), 'NAME': os.getenv('DB_DATABASE', 'django_polls'), 'USER': os.getenv('DB_USERNAME', 'your_db_username'), 'PASSWORD': os.getenv('DB_PASSWORD', 'your_secure_default_password'), 'HOST': os.getenv('DB_HOST', '127.0.0.1'), 'PORT': os.getenv('DB_PORT', 5432), 'OPTIONS': json.loads( os.getenv('DB_OPTIONS', '{}') ), } } |
Zauważ, że dodaliśmy moduł json.loads. Powinieneś również dodać import tego modułu na samej górze pliku settings.py:
|
1 |
import json |
Funkcja json.loads deserializuje obiekt JSON przekazany do DATABASES['default']['OPTIONS'] ze zmiennej środowiskowej DB_OPTIONS. Określenie tej opcji pozwala nam przekazać dowolną strukturę danych w celu zdefiniowania konfiguracji bazy danych. Silnik bazy danych zawiera zestaw prawidłowych opcji, które mają do niego zastosowanie. Opcja JSON daje nam elastyczność kodowania obiektu JSON z odpowiednimi parametrami dla silnika bazy danych, którego aktualnie używamy.
Opcja DATABASES['default']['NAME'] określa nazwę bazy danych w skonfigurowanym przez nas systemie zarządzania relacyjnymi bazami danych. W przypadku korzystania z bazy danych SQLite należy podać ścieżkę do pliku bazy danych.
Pamiętaj, że Python oferuje kilka metod na odczytywanie zewnętrznych zmiennych środowiskowych. Użyliśmy tylko jednej z nich. Możesz swobodnie zbadać i zastosować inne metody. W tym kroku dowiedziałeś się, jak pracować z zewnętrznymi zmiennymi środowiskowymi. Daje to elastyczność w zmianie zmiennych i modyfikowaniu zachowania aplikacji działającej w kontenerach. W następnym kroku dowiesz się, jak pracować z usługami przechowywania obiektów.
Krok 5: Praca z zewnętrznymi usługami przechowywania obiektów
Główną zaletą konteneryzacji aplikacji jest zapewnienie jej przenośności, co ułatwia wdrażanie wielu kopii aplikacji w przypadku wzrostu ruchu. Daje to możliwość skalowania. Wiąże się to jednak z problemem utrzymywania wersji plików statycznych i zasobów w różnych kontenerach. Dzięki ulepszeniom w technologii chmurowej możesz przenieść te współdzielone elementy statyczne do zewnętrznego magazynu. Następnie możesz udostępnić te pliki przez sieć wszystkim uruchomionym kontenerom. Zamiast próbować synchronizować pliki między różnymi działającymi kontenerami, masz jedno centralne miejsce do zarządzania nimi.
Koncepcja, którą próbujemy wyjaśnić powyżej, to korzystanie z usług chmurowego przechowywania obiektów, czyli Simple Storage Services (S3). Django posiada pakiet o nazwie django-storages , które pozwala na pracę ze zdalnymi backendami pamięci masowej. Django-storages współpracuje z większością usług pamięci obiektowej zgodnych z S3, takich jak m.in. FTP, SFTP, Amazon AWS S3, Google Cloud Storage, Dropbox i Azure Storage. W tym samouczku będziemy używać MinIO. Możesz śmiało użyć dowolnej innej usługi pamięci obiektowej zgodnej z S3. MinIO oferuje wysokowydajną pamięć obiektową zgodną z S3. Dzięki MinIO możesz zbudować infrastrukturę danych zgodną z S3 w dowolnej chmurze.
Pokażemy Ci, jak skonfigurować usługę pamięci masowej MinIO na platformie CloudSigma. Wykonaj następujące kroki:
-
Zacznij od utworzenia konta w CloudSigma. Jeśli napotkasz jakiekolwiek problemy podczas tworzenia pamięci MinIO, skontaktuj się z bezpłatnym wsparciem czatu na żywo 24/7 CloudSigma, a oni Ci pomogą.
-
Dodaj swoje dane rozliczeniowe.
-
Następnie poproś o swój publicznie dostępny bucket stąd: https://blog.cloudsigma.com/xxxx. Aby uzyskać dane dostępowe do konta, musisz skontaktować się ze wsparciem na czacie na żywo.
-
Po utworzeniu środowiska pamięci obiektowej MinIO otrzymasz dane dostępowe oraz inne instrukcje dotyczące dostępu do niego. Dane uwierzytelniające powinny zawierać Twój MINI_ACCESS_KEY, MINIO_SECRET_KEY, oraz MINIO_URL. Użyjesz tych kluczy w poniższych instrukcjach.
Wprowadźmy jeszcze kilka zmian w pliku mysite/settings.py, który modyfikowaliśmy w poprzednim kroku. W pliku dodaj aplikację storages do listy INSTALLED_APPS:
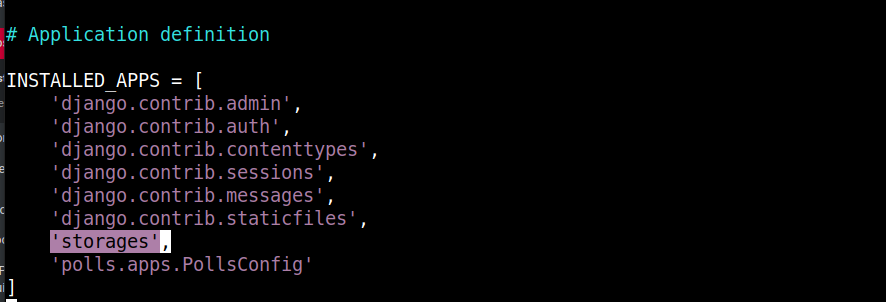
Aplikacja storages jest instalowana przez django-storages zgodnie z definicją w pliku requirements.txt. Przewiń na dół pliku i zastąp zmienną STATIC_URL następującym fragmentem kodu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# Pliki statyczne (CSS, JavaScript, Obrazy) # https://docs.djangoproject.com/en/3.2/howto/static-files/ DEFAULT_FILE_STORAGE = os.getenv('STATIC_DEFAULT_FILE_STORAGE', 'storages.backends.s3boto3.S3Boto3Storage') AWS_S3_ENDPOINT_URL = os.getenv('MINIO_URL') AWS_ACCESS_KEY_ID = os.getenv('MINIO_ACCESS_KEY') AWS_SECRET_ACCESS_KEY = os.getenv('MINIO_SECRET_KEY') AWS_STORAGE_BUCKET_NAME = os.getenv('STATIC_MINIO_BUCKET_NAME') AWS_S3_OBJECT_PARAMETERS = { 'CacheControl': 'max-age=86400', } AWS_LOCATION = 'static' AWS_DEFAULT_ACL = 'public-read' STATICFILES_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage' STATIC_URL = '{}/{}/'.format(AWS_S3_ENDPOINT_URL, AWS_LOCATION) STATIC_ROOT = "static/" |
Zauważ, że niektóre zmienne konfiguracyjne są zakodowane na stałe (hardcoded):
-
STATICFILES_STORAGE: definiuje backend pamięci masowej, którego Django będzie używać do obsługi plików statycznych. W naszym poradniku używamy pamięci MinIO, ale możesz użyć dowolnego backendu zgodnego z S3, jak wyjaśniono w dokumentacji Django Storages.
-
AWS_S3_OBJECT_PARAMETERS: definiuje nagłówki cache-control.
-
AWS_LOCATION: używamy tego do ustawienia katalogu w bucket pamięci masowej, w którym będą przechowywane wszystkie pliki statyczne. Możesz wybrać inną nazwę.
-
AWS_DEFAULT_ACL: ustawia listę kontroli dostępu (ACL) dla plików statycznych. Ustawienie wartości na ‘ public-Read’ sprawi, że pliki będą dostępne dla wszystkich użytkowników publicznych.
-
STATIC_URL: Django używa bazowego adresu URL ustawionego w tej zmiennej do generowania adresów URL dla plików statycznych. Bazowy adres URL w tym przypadku pochodzi z połączenia adresu URL punktu końcowego (endpoint URL) i podkatalogu plików statycznych.
-
STATIC_ROOT: definiuje, gdzie lokalnie zbierać pliki statyczne przed skopiowaniem ich do zdalnej pamięci obiektowej.
Mamy również kilka zewnętrznie zdefiniowanych zmiennych środowiskowych, aby zachować elastyczność i przenośność:
-
AWS_STORAGE_BUCKET_NAME: definiuje nazwę kontenera pamięci masowej, do którego Django będzie przesyłać zasoby.
-
AWS_S3_ENDPOINT_URL: definiuje adres URL punktu końcowego używany do uzyskiwania dostępu do usługi przechowywania obiektów. Będzie to adres URL zmapowany na serwer hostujący Twoją usługę MinIO.
Zapisz i zamknij plik po zakończeniu edycji.
Gdy wprowadzisz te ustawienia i zainstalujesz zadeklarowane zależności Pythona, możesz uruchomić polecenie Django manage.py collectstatic w dowolnym momencie, aby zgromadzić pliki statyczne projektu i przesłać je do zdalnego zaplecza przechowywania obiektów:
|
1 |
python manage.py collectstatic |
Jednak nie skonfigurowaliśmy jeszcze pliku env z konfiguracjami, więc prawdopodobnie zakończy się to niepowodzeniem.
Po uruchomieniu polecenia skopiowanie zasobów do pamięci chmurowej MinIO zajmie chwilę, w zależności od ich rozmiaru i szybkości połączenia internetowego.
To wszystko w tym kroku. Zobaczmy, jak możemy obsłużyć przesyłanie logów Django do silnika Docker, aby móc je przeglądać za pomocą polecenia docker logs w następnym kroku.
Krok 6: Konfiguracja logowania w aplikacji Django
W trybie debugowania, gdy opcja DEBUG jest ustawiona na True, Django zapisuje informacje logowania do standardowego wyjścia i standardowego błędu. Informacje z logów zazwyczaj pojawiają się w terminalu, z którego uruchomiono deweloperski serwer HTTP.
W środowisku produkcyjnym prawdopodobnie używasz innego serwera HTTP, a opcja DEBUG jest ustawiona na False. W takim przypadku Django użyje innej metody logowania. Django wysyła logi o priorytecie ERROR lub CRITICAL na zdefiniowane przez Ciebie administracyjne konto e-mail. To rozwiązanie świetnie sprawdza się w wielu sytuacjach.
W konfiguracjach kontenerowych i Kubernetes wysoce zalecane jest logowanie do standardowego wyjścia i standardowego błędu. Komunikaty logów są zbierane w jednym katalogu w systemie plików węzła i są łatwo dostępne za pomocą poleceń kubectl oraz docker . Dzięki scentralizowanemu punktowi logowania w systemie plików węzła, zespół operacyjny może łatwo uruchamiać procesy na każdym węźle w celu monitorowania i przekazywania logów. Dlatego musimy skonfigurować naszą aplikację tak, aby zapisywała logi w tej standardowej konfiguracji.
Z pewnością ucieszy Cię fakt, że Django wykorzystuje wysoce konfigurowalny moduł logging ze standardowej biblioteki Pythona. Pozwala to na zdefiniowanie słownika, który jest przekazywany do logging.config.dictConfig w celu zdefiniowania pożądanych wyjść i formatowania. Oto ciekawy artykuł na temat Django Logging, The Right Way, który pomoże Ci opanować techniki logowania w Django.
Otwórz plik django-polls/mysite/settings.py w swoim edytorze. Dodaj import biblioteki Pythona logging.config na samej górze pliku:
|
1 |
import logging.config |
Do tej pory, biorąc pod uwagę wszystkie dodane importy, sekcja importów w pliku settings.py powinna wyglądać następująco:

Biblioteka logging.config przyjmuje słownik nowej konfiguracji logowania poprzez funkcję dictConfig, aby nadpisać domyślne zachowanie logowania Django.
Przewiń na dół pliku i dodaj następujący fragment kodu konfiguracji logowania:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# Konfiguracja logowania # Wyłącz poprzednią konfigurację LOGGING_CONFIG = None # Pobierz poziom logowania ze środowiska LOGLEVEL = os.getenv('DJANGO_LOGLEVEL', 'info').upper() logging.config.dictConfig({ 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'console': { 'format': '%(asctime)s %(levelname)s [%(name)s:%(lineno)s] %(module)s %(process)d %(thread)d %(message)s', }, }, 'handlers': { 'console': { 'class': 'logging.StreamHandler', 'formatter': 'console', }, }, 'loggers': { '': { 'level': LOGLEVEL, 'handlers': ['console',], }, }, }) |
LOGGING_CONFIG jest ustawione na None w celu wyłączenia/wyczyszczenia domyślnych konfiguracji logowania zdefiniowanych przez Django. LOGLEVEL jest ustawiane przez zmienną środowiskową DJANGO_LOGLEVEL . Jeśli jednak ona nie istnieje, chcemy, aby była ustawiona na ‘ info’.
Moduł logging.config zaimportowany na samej górze dostarcza funkcję dictConfig, która służy do ustawiania nowego słownika konfiguracji. Słownik ten definiuje formatowanie tekstu za pomocą klucza formatters. Wyjście jest ustawiane za pomocą klucza handlers, a na koniec klucz loggers definiuje, które komunikaty powinny trafiać do którego handlera.
Po zdefiniowaniu tych ustawień, Docker udostępni logi za pomocą polecenia docker logs. Podobnie, w innym samouczku, który przygotujemy dla Kubernetes, możesz przeglądać logi za pomocą polecenia kubectl logs. Rozpocznijmy teraz proces konteneryzacji w kolejnym kroku.
Krok 7: Definiowanie pliku Dockerfile aplikacji
W tym kroku zdefiniujemy konfigurację do uruchomienia obrazu kontenera, w którym będzie działać aplikacja Django obsługiwana przez serwer WSGI Gunicorn. Zdefiniujemy środowisko uruchomieniowe do budowy obrazu kontenera, zainstalujemy aplikację i jej zależności oraz przeprowadzimy końcową konfigurację.
-
Obraz bazowy dla aplikacji Django
Wybór obrazu bazowego, na którym oprzesz swój kontener, to pierwsza decyzja, jaką podejmiesz przy wdrażaniu aplikacji w kontenerach. Oczywiście masz możliwość budowania obrazów kontenerów od zera (SCRATCH), czyli od pustego systemu plików, lub oparcia ich na istniejącym obrazie kontenera. Ponieważ nie chcemy wymyślać koła na nowo, zbudujemy nasz obraz na podstawie obrazu bazowego. Istnieje wiele otwartoźródłowych obrazów kontenerów dostępnych w oficjalnym repozytorium obrazów kontenerów Docker. O ile nie budujesz obrazu od zera, zdecydowanie zaleca się korzystanie z oficjalnego rejestru Docker Hub. Wynika to z faktu, że Docker weryfikuje te obrazy pod kątem zgodności z najlepszymi praktykami oraz zapewnia regularne aktualizacje i poprawki bezpieczeństwa.
Ponieważ Django to framework Pythona, skorzystamy z obrazu ze standardowym środowiskiem Python, które ma już zainstalowane potrzebne nam narzędzia i biblioteki. Na oficjalnej stronie obrazów Pythona w Docker Hub, można znaleźć obrazy oparte na Pythonie dla jego różnych wersji.
W naszych różnych samouczkach opartych na Dockerze, zauważysz, że używamy obrazów opartych na Alpine Linux. Alpine Linux oferuje solidne, ale odchudzone środowisko systemu operacyjnego do uruchamiania skonteneryzowanych aplikacji. Choć jego system plików jest niewielki, jest on rozszerzalny i wyposażony w kompletny system zarządzania pakietami z możliwością dodawania nowych funkcji.
Wybierając obraz bazowy w Docker Hub, możesz zauważyć wiele dostępnych tagów dla każdego obrazu. W przypadku Python, mamy do dyspozycji 3-alpine, który wskazuje na najnowszą wersję Pythona 3 w najnowszej wersji Alpine. Oznacza to, że jeśli Twój projekt działa ze starszą wersją obrazu, może przestać działać, gdy twórcy obrazu Docker dokonają aktualizacji. Aby uniknąć takich scenariuszy w przyszłości, zawsze zaleca się wybieranie jak najbardziej szczegółowych tagów dla obrazu, którego chcesz użyć.
W tym samouczku użyjemy 3.8.12-alpine3.15 obraz jako obraz bazowy dla naszej aplikacji Django. Ten konkretny tag zostanie określony w pliku Dockerfile przy użyciu instrukcji FROM. Plik Dockerfile będzie znajdować się w głównym katalogu projektu: django_project.
Zacznij od wyjścia z katalogu Django-polls z powrotem do katalogu django_project :
|
1 |
cd .. |
Po wejściu do katalogu użyj swojego ulubionego edytora, aby otworzyć plik o nazwie Dockerfile :
|
1 |
nano Dockerfile |
Następnie wklej poniższą linię, aby ustawić bazę swojego obrazu:
|
1 |
FROM python:3.8.12-alpine3.15 |
Słowo kluczowe FROM definiuje punkt startowy niestandardowego obrazu Docker. Po jego zdefiniowaniu możemy kontynuować dodawanie instrukcji w celu skonfigurowania aplikacji. Instrukcje te zainstalują niezbędne zależności, skopiują pliki aplikacji i skonfigurują środowisko uruchomieniowe.
Dodaj następujący fragment kodu wewnątrz pliku Dockerfile:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
ADD django-polls/requirements.txt /app/requirements.txt RUN set -ex \ && apk add --no-cache --virtual .build-deps postgresql-dev build-base \ && python -m venv /env \ && /env/bin/pip install --upgrade pip \ && /env/bin/pip install --no-cache-dir -r /app/requirements.txt \ && runDeps="$(scanelf --needed --nobanner --recursive /env \ | awk '{ gsub(/,/, "\nso:", $2); print "so:" $2 }' \ | sort -u \ | xargs -r apk info --installed \ | sort -u)" \ && apk add --virtual rundeps $runDeps \ && apk del .build-deps ADD django-polls /app WORKDIR /app ENV VIRTUAL_ENV /env ENV PATH /env/bin:$PATH EXPOSE 8000 |
W tym fragmencie kodu nakazujemy Dockerowi skopiowanie pliku requirements.txt do /app/requirements.txt, aby upewnić się, że zależności aplikacji są dostępne w systemie plików obrazu. Wymagania obejmują wszystkie pakiety Pythona wymagane do uruchomienia aplikacji. Zależności są kopiowane jako pierwsze, aby Docker mógł zapisać warstwę obrazu w pamięci podręcznej. Dzieje się tak, ponieważ Docker buforuje każdy krok w pliku Dockerfile. Pierwsze budowanie obrazu zazwyczaj trwa dłużej. Docker pobierze zależności, a następnie zapisze je w pamięci podręcznej. Jeśli plik requirements.txt nie ulegnie zmianie, Docker zbuduje obraz z pamięci podręcznej, co przyspieszy kolejne procesy budowania.
Kolejny krok zawiera instrukcję RUN, która wykonuje listę poleceń systemu Linux, połączonych operatorem && systemu Linux. Polecenia te wykonują następujące czynności:
-
Użycie menedżera pakietów apk systemu Alpine do zainstalowania plików deweloperskich PostgreSQL oraz podstawowych zależności budowania.
-
Utworzenie wirtualnego środowiska Pythona.
-
Zainstalowanie zależności Pythona zdefiniowanych w pliku requirements.txt przy użyciu pip.
-
Skompilowanie niezbędnych pakietów uruchomieniowych poprzez analizę wymagań zainstalowanych pakietów Pythona.
-
Usunięcie wszelkich zależności budowania, które nie są już potrzebne.
Powodem łączenia poleceń w kroku RUN jest zmniejszenie liczby warstw obrazu. Docker tworzy nową warstwę obrazu na bazie istniejącego systemu plików za każdym razem, gdy napotka instrukcję ADD, COPY, lub RUN instrukcja w pliku Dockerfile. Kompresowanie poleceń tam, gdzie ma to zastosowanie, zminimalizuje liczbę tworzonych warstw obrazu.
Elementy dodane do warstw obrazu nie mogą zostać usunięte w kolejnej warstwie. Musisz zadeklarować instrukcje usunięcia niechcianych elementów przed przejściem do następnej instrukcji. Jest to konieczne, aby zmniejszyć rozmiar obrazu. Powinieneś zauważyć, że dodaliśmy apk del polecenie na końcu RUN polecenia. Zrobiono to, aby usunąć zależności budowania po tym, jak użyliśmy ich do zbudowania pakietów aplikacji.
Następnie mamy kolejną ADD instrukcję, której używamy do skopiowania kodu aplikacji do /app katalogu. Następnie użyjemy WORKDIR instrukcji, aby ustawić katalog roboczy obrazu na /app katalog, który zawiera teraz kod aplikacji.
Następnie mamy instrukcje ENV , których używamy do ustawienia dwóch zmiennych środowiskowych, które obraz udostępni uruchomionym kontenerom. Najpierw ustawiamy VIRTUAL_ENV zmienną na /env. Po drugie, ustawiamy PATH zmienną, aby zawierała /env/bin katalog. W tych dwóch liniach wykonujemy polecenie source dla skryptu /env/bin/activate , co jest sposobem na aktywację środowiska wirtualnego w środowisku Linux. Możesz przeczytać więcej o pracy ze środowiskami wirtualnymi w Pythonie na innych systemach operacyjnych. Ostatnią instrukcją jest polecenie EXPOSE , które ustawia port 8000 , na którym kontener będzie nasłuchiwał w czasie działania.
W tym momencie Twój plik Dockerfile jest już prawie gotowy, poza domyślnym poleceniem, które zostanie uruchomione po starcie kontenerów. Zdefiniujmy je w następnej sekcji.
-
Zrozumienie domyślnego polecenia obrazu Docker
Podczas uruchamiania kontenera Docker możesz podać polecenie do wykonania. Jeśli jednak nie podasz polecenia, domyślne polecenie obrazu Docker określi, co stanie się po uruchomieniu kontenera. Używamy instrukcji ENTRYPOINT lub CMD pojedynczo lub razem, aby zdefiniować domyślne polecenie w pliku Dockerfile.
Jeśli zdecydujesz się zdefiniować zarówno ENTRYPOINT jak i CMD, w instrukcji ENTRYPOINT definiujesz plik wykonywalny, który zostanie uruchomiony przez kontener. W instrukcji CMD definiujesz domyślną listę argumentów dla polecenia wykonywalnego. Możesz nadpisać domyślną listę argumentów, dołączając alternatywne argumenty w wierszu poleceń podczas uruchamiania kontenera w formacie:
|
1 |
docker run <image> <arguments> |
Ten format uniemożliwia programistom łatwe nadpisanie polecenia ENTRYPOINT . Polecenie ENTRYPOINT jest zdefiniowane tak, aby wywoływało skrypt, który skonfiguruje środowisko i wykona różne akcje na podstawie dostarczonej listy argumentów.
Możesz użyć samej instrukcji ENTRYPOINT , aby skonfigurować plik wykonywalny kontenera. Jednak ten format nie pozwala na zdefiniowanie domyślnej listy argumentów. Możesz podać argumenty podczas uruchamiania kontenera za pomocą polecenia docker run .
Jeśli zdecydujesz się na użycie samego CMD , Docker interpretuje to jako domyślne polecenie i listę argumentów, które można nadpisać w czasie działania. Więcej informacji można znaleźć w oficjalnej dokumentacji referencyjnej Dockerfile.
Zobaczmy, jak możemy zastosować informacje, które zdobyłeś o domyślnych poleceniach, do naszego przykładowego kontenera. Domyślnie chcemy serwować aplikację za pomocą serwera gunicorn . Chociaż lista argumentów przekazywana do serwera gunicorn nie musi być konfigurowalna w czasie działania, chcemy mieć elastyczność uruchamiania innych poleceń w celach takich jak debugowanie lub zarządzanie konfiguracją (inicjalizacja bazy danych, zbieranie zasobów statycznych itp.). Jak widać, w naszym najlepszym interesie jest użycie CMD do zdefiniowania domyślnego polecenia, co pozwoli nam je nadpisać w razie potrzeby.
Oto kilka składni, których możesz użyć do zdefiniowania polecenia CMD :
- CMD ["command", "argument 1", "argument 2", . . . ,"argument n"]: Format exec (zalecany format) przyjmuje polecenie i listę argumentów. Wykonuje polecenie bezpośrednio, bez przetwarzania przez powłokę (shell).
- CMD command "argument 1" "argument 2" . . . "argument n": Format powłoki (shell format) definiuje polecenie i listę argumentów. Przekazuje listę poleceń do powłoki w celu przetworzenia. Może to być przydatne, jeśli chcesz zastąpić zmienne środowiskowe w poleceniu, jednak nie jest to całkowicie przewidywalne.
- CMD ["argument 1", "argument 2", . . . ,"argument n"]: Format listy argumentów, definiuje on jedynie domyślną listę argumentów i jest używany razem z instrukcją ENTRYPOINT .
Będziemy używać formatu exec do zdefiniowania naszej końcowej instrukcji w Dockerfile. Dodaj następującą linię na końcu swojego Dockerfile:
|
1 |
CMD ["gunicorn", "--bind", ":8000", "--workers", "3", "mysite.wsgi:application"] |
Możesz teraz zapisać i zamknąć Dockerfile.
Gdy uruchomisz kontenery przy użyciu tego obrazu, wykonają one gunicorn powiązany z portem localhost 8000 z 3 procesami roboczymi i wywołają funkcję application w pliku wsgi.py znajdującym się w katalogu mysite . Możesz podać inne polecenie, aby nadpisać domyślne polecenie w czasie uruchomienia i wykonać inny proces zamiast gunicorn. Możesz dowiedzieć się więcej o procesach roboczych Gunicorn.
Twój Dockerfile jest teraz gotowy i możesz użyć docker build do zbudowania obrazu aplikacji. Możesz użyć docker run do uruchomienia kontenera na lokalnej maszynie deweloperskiej.
-
Budowanie obrazu Docker
Polecenie docker build domyślnie szuka pliku Dockerfile w bieżącym katalogu, aby znaleźć instrukcje budowania. Wysyła również „kontekst” budowania (build context) do demona Docker. kontekst budowania to zestaw plików, które powinny być dostępne podczas procesu budowania. Domyślnie bieżący katalog, w którym uruchamiasz polecenie docker build jest ustawiony jako kontekst budowania.
Będąc w tym samym katalogu, który zawiera Twój Dockerfile, uruchom polecenie docker build. Podaj obraz i tag za pomocą flagi -t i ustaw bieżący katalog jako kontekst budowania za pomocą kropki ( .) na końcu polecenia:
|
1 |
docker build -t django-polls:v1 . |
W tym poleceniu nazwaliśmy obraz django-polls a tag v1. Zwróć uwagę na kropkę na końcu polecenia – używamy jej do oznaczenia bieżącego katalogu jako kontekstu budowania.
Po zakończeniu docker build powinieneś zobaczyć dane wyjściowe podobne do następujących:

Twój obraz Docker jest już gotowy. Gdybyśmy nie przenieśli części konfiguracji do zewnętrznych zmiennych środowiskowych, mógłbyś łatwo uruchomić swój kontener za pomocą polecenia docker run. Ponieważ jednak nie skonfigurowaliśmy zewnętrznych zmiennych środowiskowych, które ustawiliśmy w pliku settings.py, uruchomienie zakończy się niepowodzeniem. Sfinalizujmy to w następnym kroku.
Krok 8: Ustawianie środowiska uruchomieniowego i testowanie aplikacji
Zbliżamy się do końca tego samouczka. In tym kroku skonfigurujemy zmienne środowiskowe w pliku env . Mając ustawione zmienne w pliku env , możemy utworzyć schemat bazy danych, wygenerować i przesłać pliki statyczne do zewnętrznej usługi przechowywania obiektów, a na koniec przetestować aplikację.
Docker oferuje kilka metod, których można użyć do przekazywania zmiennych środowiskowych do kontenera. W naszym przypadku chcemy dostarczyć listę zmiennych środowiskowych za pośrednictwem pliku. Dlatego użyjemy metody --env-file .
Używając preferowanego edytora, utwórz plik o nazwie env w katalogu django_project:
|
1 |
nano env |
Wklej następującą lista zmiennych:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
DJANGO_SECRET_KEY=twój_tajny_klucz DEBUG= DJANGO_LOGLEVEL=info DJANGO_ALLOWED_HOSTS=adres_IP_twojego_serwera DB_ENGINE=postgresql_psycopg2 DB_DATABASE=polls_db DB_USERNAME=hackins DB_PASSWORD=hasło_twojej_bazy_danych DB_HOST=host_twojej_bazy_danych DB_PORT=port_twojej_bazy_danych STATIC_DEFAULT_FILE_STORAGE=storages.backends.s3boto3.S3Boto3Storage STATIC_MINIO_BUCKET_NAME=test-bucket MINIO_ACCESS_KEY=twój_klucz_dostępu_minio MINIO_SECRET_KEY=twój_tajny_klucz_minio MINIO_URL=twój_url_minio:twój_port_minio |
Zmienne na liście to te, które zostały zdefiniowane w poprzednich krokach:
-
DJANGO_SECRET_KEY: Wygeneruj unikalną, nieprzewidywalną wartość, jak wyjaśniono w dokumentacji Django. Możesz użyć tego polecenia, aby wygenerować losowy ciąg znaków i przypisać go do zmiennej:
|
1 |
python -c 'from django.core.management.utils import get_random_secret_key; print(get_random_secret_key())' |
-
DEBUG: Ustawiliśmy tę wartość na True, ale w przypadku wdrożenia produkcyjnego pamiętaj, aby ustawić ją na False pozostawiając ją pustą.
-
DJANGO_LOGLEVEL: ustawiliśmy to na info, możesz dostosować ten poziom do własnych potrzeb.
-
DJANGO_ALLOWED_HOSTS: ustaw tę wartość na adres IP serwera Ubuntu, na którym działają kontenery Docker. Opcjonalnie ustaw ją na *, czyli symbol wieloznaczny pasujący do wszystkich hostów w trybie deweloperskim.
-
DB_DATABASE: jeśli użyłeś innej nazwy bazy danych, ustaw ją tutaj odpowiednio.
-
DB_USERNAME: ustaw tę wartość na nazwę użytkownika wybraną dla bazy danych.
-
DB_PASSWORD: ustaw tę wartość na hasło wybrane dla bazy danych.
-
DB_HOST: ustaw tę wartość na hosta, na którym działa instancja bazy danych, tak jak skonfigurowano w Kroku pierwszym.
-
DB_PORT: ustaw tę wartość na port bazy danych.
-
STATIC_MINIO_BUCKET_NAME: ustaw tę wartość na nazwę kontenera (bucket) utworzonego na koncie MinIO Cloud Storage.
Zapisz i zamknij plik po zakończeniu edycji.
Konfiguracje środowiskowe są gotowe. Musimy uruchomić kontener, przekazując argumenty nadpisujące domyślne polecenie CMD i utworzyć schemat bazy danych za pomocą poleceń manage.py makemigrations oraz manage.py migrate.
Oto polecenie:
|
1 |
docker run --env-file env django-polls:v1 sh -c "python manage.py makemigrations && python manage.py migrate" |
W tym poleceniu uruchamiamy obraz kontenera django-polls:v1, używając flagi –env-file do przekazania pliku zmiennych środowiskowych. Nadpisujemy również domyślne polecenie CMD za pomocą sh -c "python manage.py makemigrations && python manage.py migrate" Po uruchomieniu tego polecenia w celu startu kontenera, utworzy ono schemat bazy danych zgodnie z definicją w kodzie aplikacji.
W przypadku powodzenia powinieneś zobaczyć dane wyjściowe podobne do poniższych:
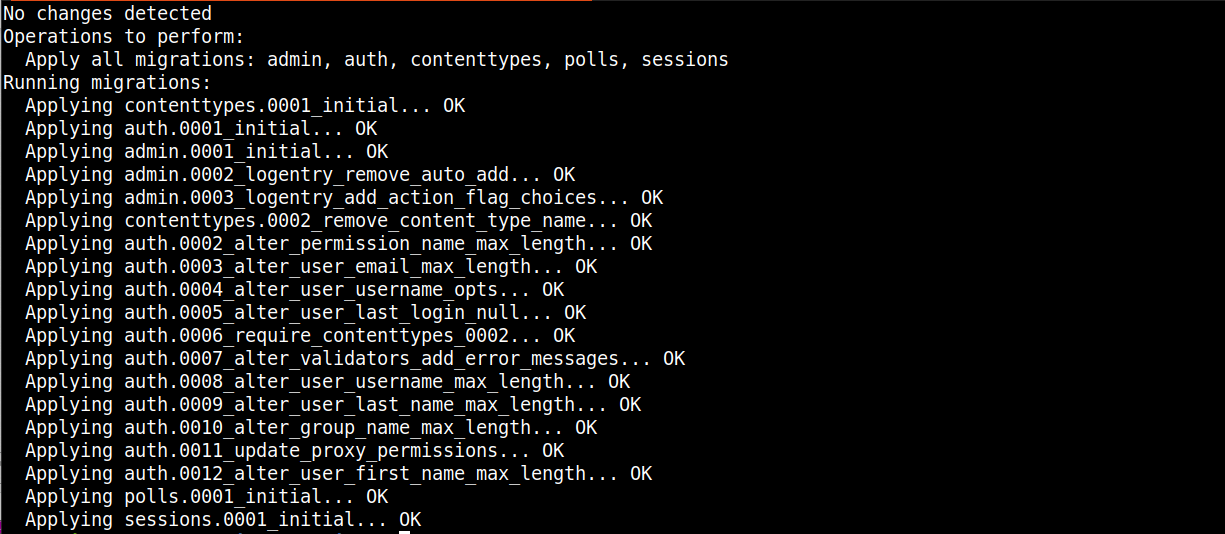
Dane wyjściowe wskazują, że schemat bazy danych został pomyślnie utworzony.
Kolejnym krokiem jest utworzenie użytkownika administracyjnego dla aplikacji Django. Uruchomimy kontener i włączymy w nim interaktywną powłokę za pomocą następującego polecenia:
|
1 |
docker run -i -t --env-file env django-polls:v1 sh |
Polecenie uruchamia kontener z wierszem poleceń powłoki, którego można użyć do interakcji z powłoką Pythona. Utwórzmy użytkownika:
|
1 |
python manage.py createsuperuser |
Postępuj zgodnie z monitami, aby podać nazwę użytkownika, adres e-mail, hasło, wpisz ponownie hasło i naciśnij Enter, aby utworzyć użytkownika. Wyjdź z powłoki i zamknij kontener, naciskając CTRL+D.
Następnie musimy ponownie uruchomić kontener, nadpisując domyślne polecenie poleceniem Django collectstatic , aby wygenerować pliki statyczne dla aplikacji i przesłać je do usługi przechowywania w chmurze MinIO:
|
1 |
docker run --env-file env django-polls:v1 sh -c "python manage.py collectstatic --noinput" |
Po zakończeniu powinieneś zobaczyć dane wyjściowe podobne do poniższych, wskazujące, że kontener pomyślnie połączył się z usługą przechowywania MinIO i przesłał pliki statyczne:
![]()
Nasz bucket pamięci masowej wygląda teraz tak, wraz z katalogami utworzonymi przez Django:
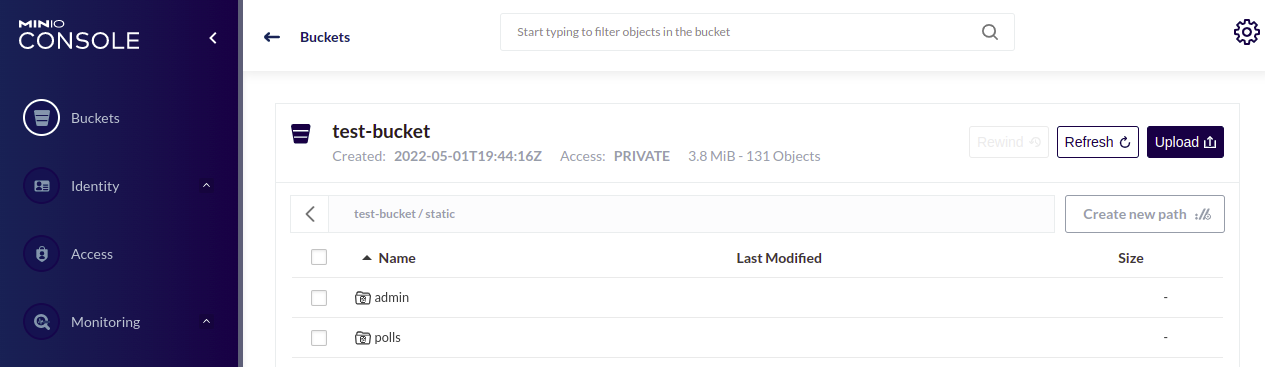
Na koniec możemy teraz uruchomić aplikację za pomocą polecenia:
|
1 |
docker run --env-file env -p 80:8000 django-polls:v1 |
Oto wynik:

Po wykonaniu powyższego polecenia uruchamia ono domyślną instrukcję CMD w Twoim obrazie i udostępnia port 8000 zgodnie z definicją. Teraz Ubuntu na porcie 80 zostaje zmapowane na 8000 port kontenera django-polls:v1 .
Możemy teraz przetestować aplikację w przeglądarce. Przejdź do publicznego adresu IP swojego serwera w przeglądarce: http://your_server_public_ip.
Spodziewaj się błędu 404 Page Not Found, ponieważ zgodnie z Django Tutorial, nie zdefiniowaliśmy trasy dla / ścieżki:
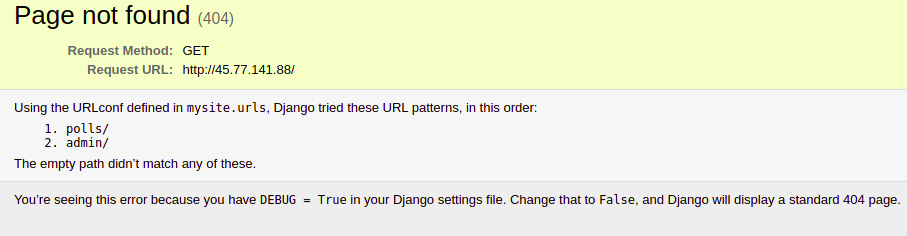
Mamy zmienną DEBUG ustawioną na True, dlatego widzimy tę stronę błędu z wieloma kluczowymi informacjami. Usuńmy ustawienie zmiennej DEBUG. Najpierw musisz zatrzymać uruchomiony kontener za pomocą CTRL+C. Następnie otwórz plik env:
|
1 |
nano env |
Następnie znajdź zmienną DEBUG i usuń jej wartość lub pozostaw ją pustą. Pozostawiamy ją pustą, ponieważ funkcja getenv interpretuje False jako ciąg znaków, zwracając w ten sposób wartość true:
|
1 |
DEBUG= |
Zapisz plik i uruchom ponownie kontener za pomocą polecenia:
|
1 |
docker run --env-file env -p 80:8000 django-polls:v1 |
Jeśli odwiedzisz ten adres http://your_server_public_ip w przeglądarce, powinieneś zobaczyć domyślną stronę 404:
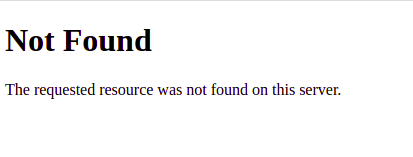
Zobaczyłeś, jak możesz manipulować zachowaniem aplikacji Django w czasie rzeczywistym za pomocą zmiennych środowiskowych, bez modyfikowania kodu źródłowego.
Przejdź do http://your_server_public_ip/polls aby zobaczyć stronę główną Polls:

Nie mamy żadnych ankiet, ponieważ dopiero co wdrożyliśmy aplikację.
Przejdź do panelu administracyjnego: http://your_server_public_ip/admin, aby wyświetlić okno uwierzytelniania administratora:
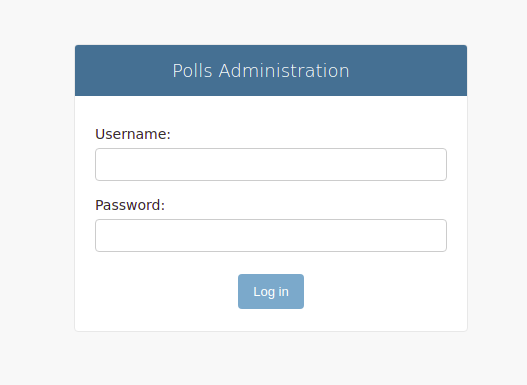
Podaj dane uwierzytelniające ustawione za pomocą polecenia createsuperuser, aby się zalogować. Powinieneś teraz znajdować się w interfejsie strony administracyjnej:
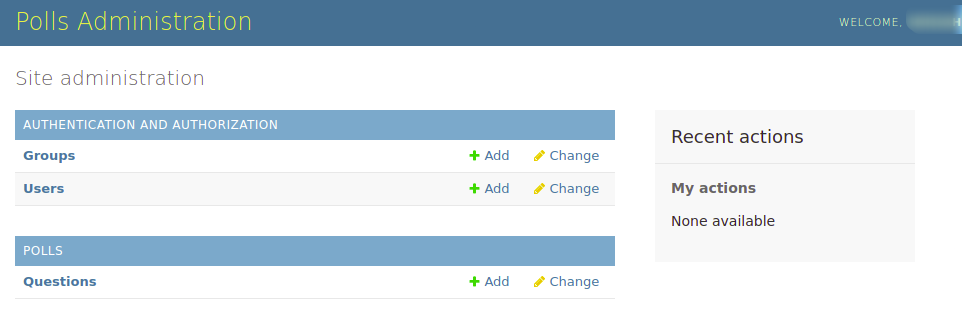
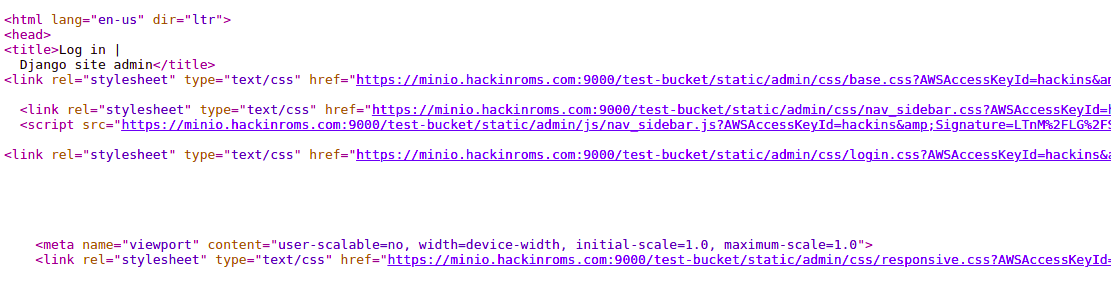
Pamiętaj, że wszystkie pliki statyczne są serwowane z zewnętrznej usługi przechowywania danych, którą skonfigurowaliśmy. Możesz kliknąć prawym przyciskiem myszy w oknie przeglądarki i wybrać Wyświetl źródło strony:
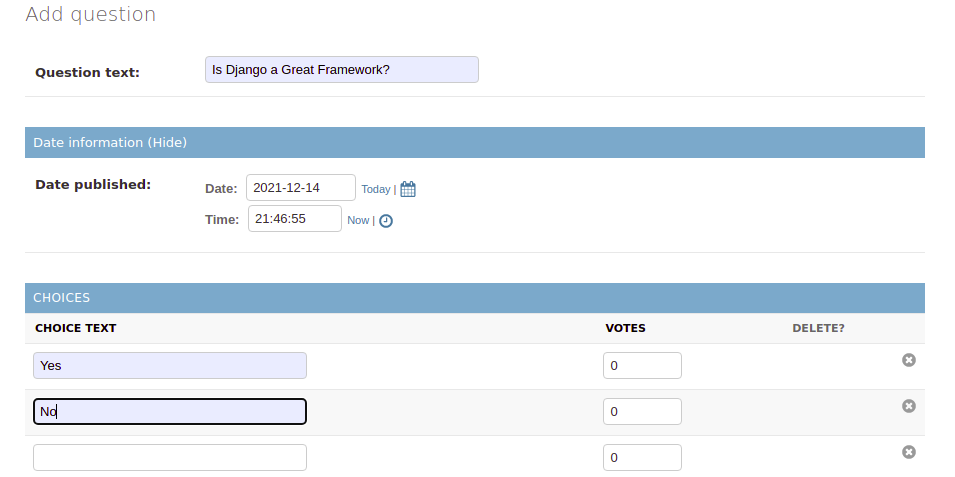
Możesz dodać kilka pytań oraz opcji odpowiedzi i przetestować ogólne działanie aplikacji:
Wróć do strony głównej Polls http://your_server_public_ip/polls i spróbuj zagłosować na pytanie:

Po przetestowaniu i potwierdzeniu, że wszystko działa zgodnie z oczekiwaniami, możesz zatrzymać kontener.
Podsumowanie
Pomyślnie skonfigurowałeś aplikację internetową Django do pracy w środowisku opartym na kontenerach. Wymagało to dostosowania aplikacji do pracy z zewnętrznymi zmiennymi środowiskowymi, ustawienia aplikacji tak, aby korzystała z usługi przechowywania w chmurze dla plików statycznych, oraz utworzenia pliku Dockerfile dla obrazu kontenera. Możesz zobaczyć zmiany, które wprowadziliśmy w celu zdokeryzowania aplikacji, w gałęzi django-polls-docker gałęzi repozytorium django-polls na GitHubie.
Od tego momentu możliwości są ograniczone jedynie Twoją wyobraźnią. Możesz skonfigurować odwrotne proxy Nginx, które będzie pośredniczyć między klientami a serwerem Guinicorn. Możesz także dodać Certbota, aby uzyskać certyfikaty TLS w celu zabezpieczenia serwera Nginx. Zalecamy dodanie proxy HTTP w celu buforowania wolnych klientów i ochrony serwera Gunicorn przed atakami typu DoS (denial of service).
Chociaż w poleceniu startowym pliku Dockerfile zdefiniowaliśmy 3 procesy robocze (workers), możesz ustawić preferowaną liczbę w zależności od zasobów dostępnych na serwerze. Więcej informacji znajdziesz w oficjalnej dokumentacji projektowej Gunicorn. Jeśli chcesz, możesz przesłać zbudowany obraz Docker do Dockerhub i spróbować wdrożyć go w kilku środowiskach z zainstalowanym Dockerem. Jeśli chcesz dowiedzieć się więcej, śledź nasz blog z samouczkami, ponieważ przygotujemy kolejny samouczek, w którym zabezpieczymy aplikację Django za pomocą Nginx i Let’s Encrypt.
Na koniec oto więcej zasobów, które pomogą Ci w korzystaniu z Dockera:
- Jak hostować repozytorium obrazów Docker i budować obrazy Docker za pomocą własnej instancji GitLab na Ubuntu 20.04
- Praca z wolumenami danych Docker na Ubuntu 20.04
- Budowanie i wdrażanie aplikacji Flask za pomocą Dockera na Ubuntu 20.04
- Jak wdrożyć WordPressa za pomocą kontenerów Docker na Ubuntu 20.04
Udanego kodowania!
Komentarze
Brak komentarzy. Bądź pierwszy.