

Polecenie sed to skrót od stream editor (edytor strumieniowy). Jest to niezwykle popularne narzędzie w systemach Linux/UNIX. Sed sam w sobie nie jest edytorem tekstu. Może jednak wykonywać różne modyfikacje w celu manipulowania podanym tekstem. Tekst wejściowy jest przesyłany jako strumień. Sed wykonuje następnie zalecone akcje na strumieniu. Ten przewodnik zawiera omówienie polecenia sed i sposobu jego obsługi w celu skutecznej manipulacji tekstem w systemie Linux.
Sed w systemie Linux
Strumień wejściowy sed może pochodzić z pliku tekstowego lub ze standardowego wejścia (STDIN). Możemy pracować z wyjściem innego polecenia lub bezpośrednio z plikiem tekstowym. Narzędzie sed jest fabrycznie zainstalowane we wszystkich dystrybucjach systemu Linux.
Przegląd użycia Sed
Polecenie sed ma następującą strukturę:
|
1 |
$ sed <opcje> <polecenia> <plik> |
Do celów demonstracyjnych pobraliśmy tekstową wersję licencji GPL w wersji 3:
|
1 |
$ wget https://www.gnu.org/licenses/gpl-3.0.txt |

Następujące polecenie sed wyświetli zawartość pliku tekstowego:
|
1 |
$ sed '' gpl-3.0.txt |
W tym miejscu sed wykonuje operacje opisane w pojedynczych cudzysłowach i wyświetla wynik. Ponieważ nie zdefiniowano żadnej opcji, sed po prostu wykona pustą operację i wyświetli całą zawartość pliku.
Sed akceptuje również dane wyjściowe z innego polecenia jako strumień wejściowy. W następnym przykładzie prześlemy potokiem zawartość pliku tekstowego GPL v3 do sed w celu wykonania pustej operacji:
|
1 |
$ cat gpl-3.0.txt | sed '' |
Jak wyświetlać linie
Bez podania żadnej opcji sed wyświetli bezpośrednio całą zawartość pliku. Zamiast tego możemy jawnie wysłać polecenie drukowania, aby wypisać wyniki bezpośrednio na standardowe wyjście (STDOUT).
Aby wyświetlić wynik, użyj znaku p:
|
1 |
$ sed 'p' gpl-3.0.txt |
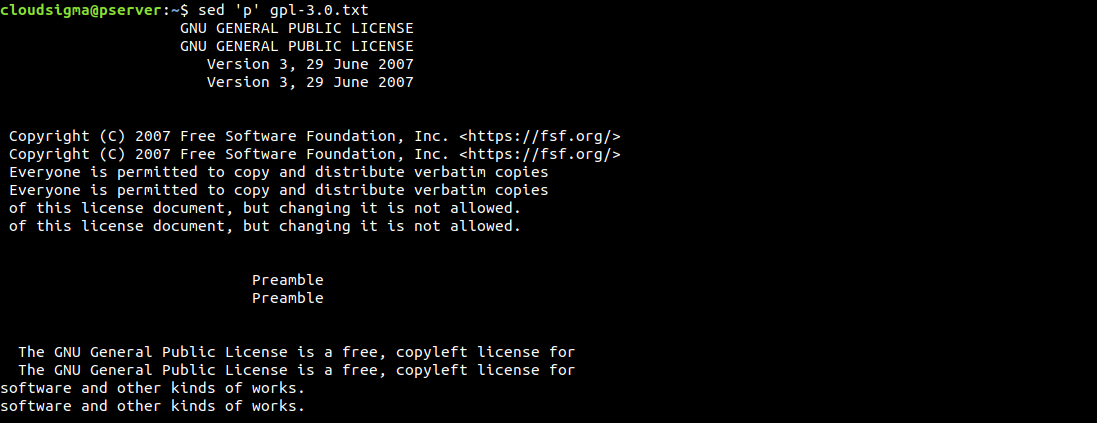
Domyślnie sed wypisuje dane wyjściowe na ekranie. Ponieważ użyliśmy konkretnie polecenia drukowania, sed wyświetli każdą linię dwukrotnie. Sed działa linia po linii. Odczytuje jedną linię, wykonuje określone operacje, wyświetla ją i przechodzi do następnej linii.
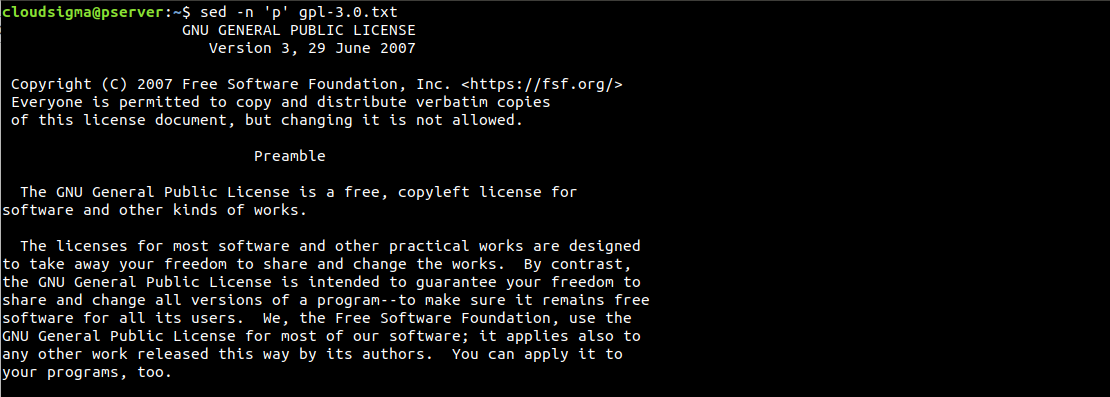
Jak widać, każda linia jest drukowana dwukrotnie. Jeśli taki wynik jest mylący, możemy go uporządkować za pomocą opcji -n. Tłumi ona funkcję automatycznego drukowania. Ponieważ wysyłamy polecenie drukowania, nie potrzebujemy włączonej domyślnej funkcji wyświetlania danych wyjściowych:
|
1 |
$ sed -n 'p' gpl-3.0.txt |
Klasy znaków wyrażeń regularnych
W wyrażeniach regularnych istnieją różne klasy znaków. Każda z tych klas ma swój zakres. Wiele klas ma również wiele wyrażeń. Większość klas to zakresy znaków:
-
- [a-z]: Mała litera
-
- [A-Z]: Wielka litera
-
- [0-9]: Cyfry
-
- [a-zA-z]: Litery alfabetu
-
- [a-zA-z0-9]: Dowolny znak alfanumeryczny
Te klasy znaków mają również różne zapisy:
-
- [:lower:]: Mała litera
-
- [:upper:]: Wielka litera
-
- [:digit:]: Cyfry
-
- [:alpha:]: Litery alfabetu
-
- [:alphanum:]: Znak alfanumeryczny
Na przykład poniższe polecenie wyświetli wszystkie linie zawierające co najmniej jedną cyfrę:
|
1 |
$ sed -n 's/[[:digit:]]/&/p' gpl-3.0.txt |
Zakresy adresów
Możemy określić konkretną część strumienia tekstu, na której chcemy pracować. Może to być statyczna lokalizacja linii lub zakres linii. W pierwszym przykładzie wydrukujemy linię 5 z pliku tekstowego GPL v3:
|
1 |
$ sed -n '5p' gpl-3.0.txt |

Zamiast pojedynczej linii możemy również określić zakres linii, na których chcemy pracować. Tutaj podaliśmy zakres adresów od linii 5 do linii 9 (łącznie 5 linii), na których sed będzie pracować:
|
1 |
$ sed -n '5,9p' gpl-3.0.txt |

Istnieją również inne sposoby określania adresu linii. Zamiast samodzielnie ustalać numery linii, możemy zmodyfikować poprzedni przykład tak, aby sed rozpoczął od linii 5 i działał na kolejnych 5 liniach:
|
1 |
$ sed -n '5,+5p' gpl-3.0.txt |

Innym sposobem określania linii jest użycie przedziałów. W kolejnym przykładzie sed rozpocznie od linii 1 i będzie działać na co drugiej linii:
|
1 |
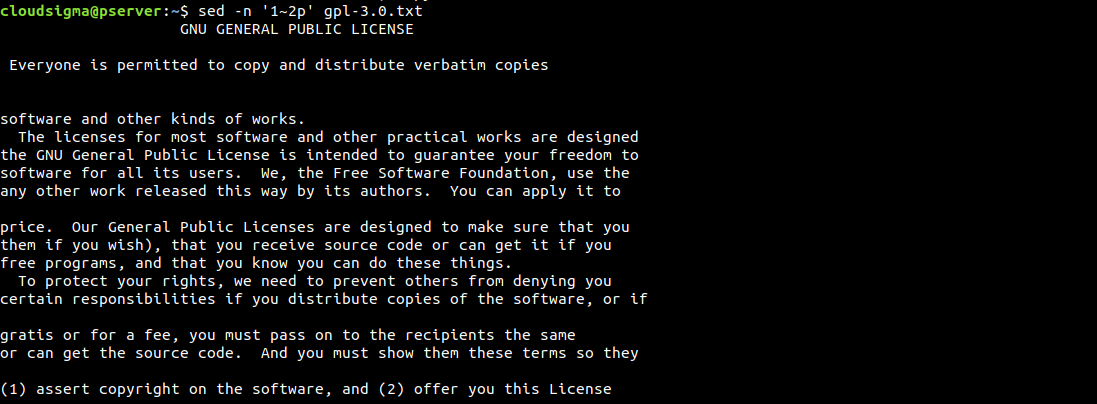
$ sed -n '1~2p' gpl-3.0.txt |
Usuwanie tekstu
Do tej pory pracowaliśmy nad drukowaniem docelowych linii tekstu. Zamiast drukować, możemy usunąć te linie z danych wyjściowych. W poniższym przykładzie usuniemy wiele linii od początku. Tutaj nie musimy używać opcji -n ponieważ chcemy, aby sed drukował wszystko inne, co nie zostało usunięte. Do usuwania linii użyjemy opcji d:
|
1 |
$ sed '1~2d' gpl-3.0.txt |
Zauważ, że plik źródłowy jest nadal nienaruszony. Sed po prostu wykonuje usuwanie linii podczas generowania danych wyjściowych. Jeśli chcesz, możesz zapisać dane wyjściowe sed do pliku. Możesz nadpisać oryginalny plik lub zapisać go jako inny:
|
1 |
$ sed '1~2d' gpl-3.0.txt > gpl-3.0.modified.txt |
Zamiast ręcznie zapisywać dane wyjściowe do pliku, sed może wykonać edycję w miejscu na oryginalnym pliku. Krótko mówiąc, sed zmodyfikuje oryginalny plik i zapisze wszelkie wprowadzone zmiany. Ta metoda nadpisze oryginalny plik, dlatego należy jej używać ostrożnie:
|
1 |
$ sed -i '1~2d' gpl-3.0.txt |
Ponieważ edycja w miejscu jest niebezpieczna, sed oferuje funkcję tworzenia kopii zapasowej. Podczas edycji w miejscu użyj -i.bak zamiast -i, aby utworzyć kopię zapasową przed edycją. Sed utworzy plik kopii zapasowej z rozszerzeniem .bak:
|
1 |
$ sed -i.bak '1~2d' gpl-3.0.txt |
Podstawianie tekstu
To zdecydowanie jedno z najczęstszych zastosowań sed. Przeszukuje ono tekst pod kątem wzorca i zastępuje go podanym tekstem. Tutaj wzorzec tekstu jest opisany za pomocą wyrażeń regularnych (w skrócie regex). Aby dowiedzieć się więcej o korzystaniu z regex, zapoznaj się z tym samouczkiem, który opisuje, jak używać Grep z regex do wyszukiwania wzorców tekstu w plikach.
Oto przykład najbardziej podstawowego podstawiania tekstu przy użyciu regex:
|
1 |
$ 's/<search_pattern>/<replacement>' |
W tym miejscu s jest poleceniem podstawienia. Ukośniki są ogranicznikami dla wzorca i zamiennika. Przejdźmy do działania:
|
1 |
$ echo "hello world" | sed 's/hello/HELLO/' |
![]()
Kolejny przykład zademonstruje użycie podkreślenia (_). Tutaj podkreślenia będą działać jako ograniczniki:
|
1 |
$ echo http://example.com/index.html | sed 's_com/index_net/home_' |
W tym miejscu szukamy com/index, aby zamienić na net/home. Zwróć uwagę na rozmieszczenie podkreśleń, ponieważ są one bardzo istotne. Na przykład, jeśli brakuje ostatniego podkreślenia, sed zgłosi błąd:
|
1 |
$ echo "http://www.example.com/index.html" | sed 's_com/index_net/home' |
![]()
Potrzebujemy przykładowego pliku, aby poćwiczyć podstawianie. Mam tutaj przyciętą wersję pliku tekstowego GPL v3:
|
1 |
$ cat gpl-3.0.cropped.txt |
Wykonajmy kilka podstawowych podstawień tekstu:
|
1 |
$ cat gpl-3.0.cropped.txt | sed 's/GNU/GNU is Not Unix/' |
Spójrz na kolejny przykład. Chcemy zmienić wszystkie wystąpienia the na THE :
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/' |
![]()
Zauważyłeś coś? Sed nie zmienił wszystkich wystąpień the. W rzeczywistości zmienił tylko pierwsze wystąpienie. O co chodzi? To jest domyślne zachowanie opcji s. Dopasowuje ona tylko pierwsze wystąpienie w danej linii i przechodzi do następnej. Aby upewnić się, że sed sprawdza całą linię pod kątem szukanego wzorca, musimy użyć opcjonalnej flagi g. Naprawmy to polecenie:
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/g' |
Teraz działa to zgodnie z oczekiwaniami. Innym ciekawym sposobem użycia tego polecenia jest określenie liczby wystąpień do zmiany. W poprzednim przykładzie były 3 wystąpienia the, prawda? A co, jeśli określimy, aby zmienić tylko 3. wystąpienie? Zmiana nastąpi przy opcjonalnej fladze:
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/3' |
Jeśli pracujesz z dużym plikiem tekstowym, pomocne może być, gdy sed wydrukuje tylko te linie, w których nastąpiły podstawienia. Aby to osiągnąć, musimy dodać kolejną dodatkową flagę p:
|
1 |
$ sed -n 's/GNU/GNU is Not Unix/gp' gpl-3.0.txt |

Rozróżnianie wielkości liter
Domyślnie wszystkie operacje sed rozróżniają wielkość liter. Poniższe polecenie zademonstruje domyślne zachowanie rozróżniania wielkości liter:
|
1 |
$ echo "HELLO WORLD" | sed 's/hello/hElLo/' |
![]()
Z powodu niezgodności wielkości liter nie nastąpi żadna zmiana. W takiej sytuacji możemy nakazać programowi sed zignorowanie wielkości liter. Aby to zrobić, dodaj opcjonalną flagę i:
|
1 |
$ echo "HELLO WORLD" | sed 's/hello/hElLo/i' |
Jak zastępować i odwoływać się do tekstów
Siła narzędzia sed tkwi głównie w jego możliwościach korzystania z wyrażeń regularnych. Dzięki bardziej zaawansowanym i złożonym wzorcom regex możemy osiągnąć znacznie więcej. Na przykład możemy zastąpić tekst od początku pliku do określonego miejsca. Spójrz na następujące wyrażenie:
|
1 |
$ sed 's/^.*GNU/GNU_replaced/' gpl-3.0.txt |
W tym miejscu znak daszka (^) oznacza początek linii. Operator dopasowania dowolnego znaku jest oznaczany kropką (.). Gwiazdka (*) jest wyrażeniem wieloznacznym, dopasowującym od początku linii aż do GNU.
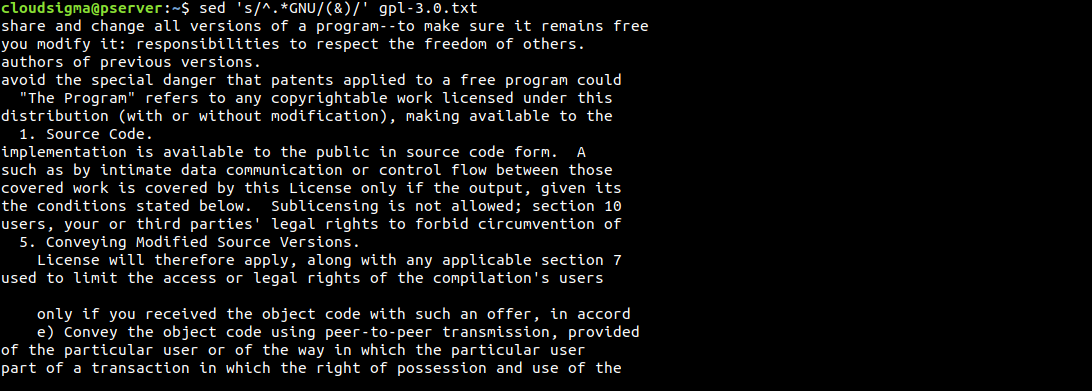
Inną ciekawą sztuczką jest użycie symbolu &. Możemy go użyć do podświetlenia obszarów, w których sed znajduje wyszukiwany wzorzec:
|
1 |
$ sed 's/^.*GNU/(&)/' gpl-3.0.txt |
Podsumowanie
W tym samouczku poznaliśmy podstawy polecenia sed . Dowiedzieliśmy się, jak drukować określone linie, przeszukiwać teksty, usuwać i zastępować teksty, nadpisywać teksty oraz używać wyrażeń regularnych. Odpowiednio skonstruowane polecenie sed może radykalnie przekształcić dokument tekstowy. Możesz teraz z powodzeniem manipulować tekstem w systemie Linux za pomocą sed.
Miłej pracy z komputerem!
Komentarze
Brak komentarzy. Bądź pierwszy.