

The grep 명령어는 텍스트에서 패턴을 검색하는 강력한 유틸리티입니다. 이 명령어는 모든 Linux 배포판에 기본으로 설치되어 제공됩니다. 다음은 저희의 LAMP 스택(Linux, Apache, MySQL, PHP) 설정 방법을 다루는 튜토리얼입니다..
grep이라는 이름은 global regular expression print의 약자입니다. 이 도구는 입력에서 지정된 패턴을 검색합니다. 원칙적으로는 간단해 보이지만, 진짜 강력함은 패턴을 정의하는 방식에 있습니다. 이 가이드는 복잡한 검색을 수행하기 위해 정규 표현식과 함께 grep을 사용하는 방법을 자세히 설명합니다. 시작해 봅시다!
Grep 사용 방법
grep 명령어 자체는 복잡하지 않습니다. 검색을 수행할 패턴과 내용만 있으면 됩니다. grep 명령어의 기본 구조는 다음과 같습니다:
|
1 |
grep <regex> <file> |
텍스트 검색하기
먼저, 작업을 수행할 샘플 파일을 준비합니다. 다음을 다운로드하세요: GNU General Public License v3.0 (텍스트 형식). 단어와 구절이 아주 많은 꽤 큰 텍스트 파일입니다. 만약 Ubuntu를 사용 중이라면 아래 파일에서 찾을 수 있습니다. 다음을 참고하세요: 빠르고 쉬운 Ubuntu 설치를 위한 튜토리얼.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

다음으로, grep을 사용하여 기본적인 텍스트 검색을 수행할 수 있습니다:
|
1 |
grep <pattern> <text_file> |
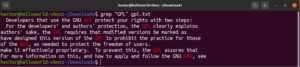
명령어의 출력을 grep으로 파이프(pipe)할 수도 있습니다:
|
1 |
cat gpl.txt | grep <pattern> |
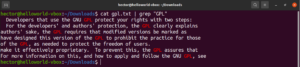
대소문자 구분
기본적으로 grep은 대소문자를 구분합니다. 많은 상황에서 대소문자 구분을 무시하는 것이 최선일 수 있습니다. 대소문자 구분 검색을 비활성화하려면 “-i” 또는 “–ignore-case” 플래그를 사용하세요:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
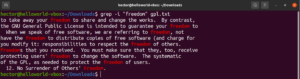
반전 검색
기본적으로 grep은 패턴이 발견된 줄을 출력합니다. 반전 매칭(Invert match)은 패턴과 일치하는 줄을 보고 싶지 않을 때 사용하는 기능입니다. 반전 매칭을 하려면 “-v” 또는 “–invert-match” 플래그를 사용해야 합니다:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
줄 번호
매우 큰 파일에서 grep을 실행할 때 검색 결과의 위치를 추적하기는 어렵습니다. 이를 더 쉽게 만들기 위해 grep에는 줄 번호를 표시하는 기능이 있습니다. 줄 번호 표시를 활성화하려면 “-n” 또는 “–line-number” 플래그를 사용하세요:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
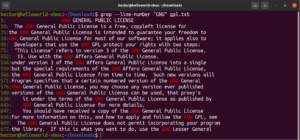
여러 grep 인수를 조합할 수도 있습니다. 다음 grep 명령어는 줄 번호를 출력하면서 반전 매칭을 수행합니다:
|
1 |
grep -nv <pattern> <file> |
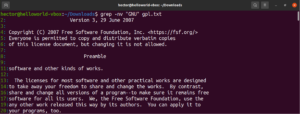
정규 표현식
이 가이드의 시작 부분에서 grep이 global regular expression print의 약자라고 언급했습니다. “정규 표현식”이라는 용어는 검색 패턴을 설명하는 특별한 문자열로 정의됩니다. 정규 표현식은 자체적인 구조와 규칙을 가지고 있습니다.
검색 및 바꾸기 작업을 수행하기 위해 정규 표현식(줄여서 regex)을 사용하는 수많은 문자열 검색 알고리즘과 도구가 있습니다. 널리 사용되지만, 애플리케이션과 프로그래밍 언어에 따라 정규 표현식을 구현하는 방식이 약간씩 다릅니다. 이 섹션에서는 grep을 사용하는 몇 가지 정규 표현식 방법을 소개합니다.
리터럴 매칭
이전 grep 예제에서 grep은 주어진 텍스트 파일에서 특정 문자열을 검색했습니다. 사실 grep은 아주 기본적인 정규 표현식을 사용하여 검색하고 있었습니다. 주어진 문자열과 정확히 일치하는 검색을 정의하는 정규 표현식 패턴을 “리터럴(literals)”이라고 합니다. 이 이름은 패턴과 문자 그대로 문자 단위로 일치한다는 사실에서 유래되었습니다.
리터럴 일치는 알파벳 및 숫자 문자(일부 특수 문자 포함)에서 작동합니다. 그러나 다른 표현식 메커니즘에 따라 이 동작이 변경될 수 있습니다:
|
1 |
grep "<string>" <file> |
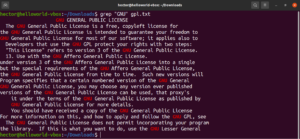
앵커 일치
앵커는 유효한 일치를 위해 줄에서 일치 항목의 위치가 어디여야 하는지 정의하는 특수 문자입니다. 이를 단순화하기 위한 빠른 예가 있습니다. "GNU"라는 문자열로 시작하는 줄만 찾으려면 정규식을 사용한 grep은 다음과 같습니다. 여기서 "^"; 문자는 줄의 시작 부분에서 일치하는 항목만 유효함을 정의하는 앵커입니다:
|
1 |
grep -n "^GNU" <file> |

마찬가지로 "works"라는 문자열로 끝나는 줄만 찾으려면 정규식을 사용한 grep은 다음과 같습니다. 여기서 "$" 문자는 줄의 끝부분에서 일치하는 항목만 유효함을 정의하는 앵커입니다:
|
1 |
grep -n "and$" <file> |
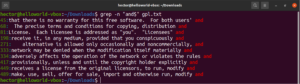
임의의 문자 일치
텍스트 검색을 수행할 때 특정 위치에 임의의 문자가 올 수 있도록 정의하고 싶을 수 있습니다. 정규식에서는 이를 마침표 문자(.)로 표현합니다.
이 예를 살펴보십시오. GNU GPL 3 텍스트 파일에서 "accept"와 "except"라는 단어는 모두 "cept"라는 부분을 공통으로 가지고 있습니다. 또한 두 단어 모두 "cept" 부분 앞에 두 개의 문자가 있습니다. 다음 grep 명령은 "cept" 부분 앞에 두 개의 문자가 있는 모든 단어와 일치합니다:
|
1 |
grep -n "..cept" <file> |
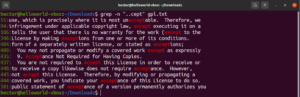
이 정규식에 따르면 suscept, unaccept, unexpected 등과 같은 다른 단어들도 유효한 일치 항목입니다.
대괄호
정규식에서 대괄호 표현식은 지정된 위치에 대괄호 내에 선언된 임의의 문자가 올 수 있음을 정의합니다. 다음 정규식 문자열을 살펴보십시오:
|
1 |
t[wo]o |
실제로 적용하면 too와 two라는 단어가 유효한 일치 항목이 됩니다:
|
1 |
grep -n "t[wo]o" <file> |
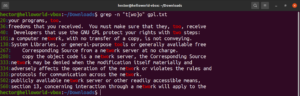
대괄호 표현식은 몇 가지 흥미로운 가능성을 열어줍니다. 대괄호 표현식을 사용하여 지정된 위치에 대괄호 내에 선언된 문자 이외의 임의의 문자가 올 수 있음을 나타낼 수 있습니다. 다음 정규식 문자열을 살펴보십시오. "ode" 앞에 "c" 이외의 문자가 있는 경우에만 일치가 유효합니다:
|
1 |
"[^c]ode" |
GPL-3 라이선스 텍스트 파일에서 실행해 보십시오:
|
1 |
grep -n "[^c]ode" <file> |

파일의 결과 외에도 node, abode, anode 등도 유효한 결과가 됩니다. 대괄호 표현식은 문자 범위를 설명할 수도 있습니다. 다음 정규식은 줄의 시작이 대문자인 경우 일치가 유효함을 나타냅니다:
|
1 |
"^[A-Z]" |
GPL-3 라이선스 텍스트 파일에서 실행해 보십시오. 텍스트 파일의 모든 줄이 해당됩니다:
|
1 |
grep -n "^[A-Z]" <file> |
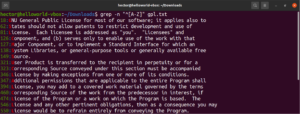
사용 편의성을 위해 지정된 레이블이 있는 특정 문자 클래스가 있습니다. 이전 예에서는 대문자를 정의하기 위해 "A-Z" 범위를 사용했습니다. 대신 "[:upper:]"를 사용할 수도 있습니다. 결과는 동일합니다:
|
1 |
grep -n "^[[:upper:]]" <file> |
패턴 반복
특정 상황에서는 특정 패턴이나 정규식을 0회 이상 일치시키고 싶을 수 있습니다. 이를 위한 메타 문자는 별표(*)입니다. 다음 정규식은 알파벳과 단일 공백만 포함된 모든 괄호와 일치합니다. 소문자, 대문자 세트 및 공백의 선언은 문장 부호 없이 함께 배치된다는 점에 유의하십시오:
|
1 |
"([a-zA-Z ]*)" |
grep을 사용하여 정규식을 실행해 보십시오:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

메타 문자를 리터럴 문자로 사용
지금까지 우리는 별표(*), 마침표(.), 앵커(^ 및 $) 등 다양한 메타 문자를 소개받았습니다. 이들은 각각 정규식 컨텍스트에서 고유한 기능을 나타냅니다. 문제는 이들을 메타 문자가 아닌 리터럴로 사용해야 할 때 발생합니다. 이러한 상황에서 메타 문자 앞에 백슬래시(\\)를 붙이면 메타 문자가 아닌 리터럴 의미로 사용됨을 나타냅니다. 다음 정규식 예시를 살펴보세요. 대문자로 시작하고 마침표로 끝나는 모든 줄과 일치합니다:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
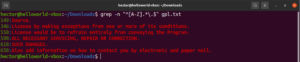
선택
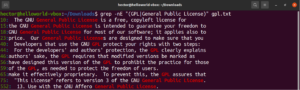
대괄호 표현식을 사용하면 단일 문자 일치에 대해 서로 다른 가능한 선택지를 지정할 수 있습니다. 정규식에는 단어와 구절에 대해서도 동일한 작업을 수행하는 기능이 있습니다. 선택을 나타내기 위해 파이프 문자(|)가 사용됩니다. 옵션은 괄호 안에 유지되며 파이프 문자가 이들을 서로 구분합니다. 일치가 유효하려면 두 개 이상의 가능한 옵션이 있을 수 있습니다. 다음 정규식 예시를 살펴보세요. “GPL”과 “General Public License” 모두와 일치합니다:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
수량자
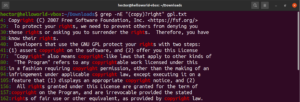
별표(*) 메타 문자를 사용하여 패턴을 0회 이상 반복해서 정의할 수 있었습니다. 하지만 더 많은 기능이 있습니다. 수량자는 예시를 통해 설명하는 것이 더 쉽습니다. 다음 정규식은 “copyright”와 “right”가 모두 유효한 일치 항목임을 설명합니다. 물음표(?)는 일치시킬 “copy” 부분이 선택 사항임을 나타냅니다:
|
1 |
grep -nE "(copy)?right" <file> |
다음 수량자는 더하기 기호(+)입니다. 별표와 유사하게 작동합니다. 하지만 정의된 패턴이 최소한 한 번은 일치해야 합니다. 다음 예시에서 정규식은 “soft” 뒤에 공백이 아닌 문자가 하나 이상 있는 단어와 일치합니다:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
일치 반복 횟수 지정
일치가 반복되는 횟수를 지정할 수 있습니다. 그렇게 하려면 중괄호({})를 사용하세요. 다음 정규식은 모음이 최소 3개 포함된 모든 단어와 일치합니다:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

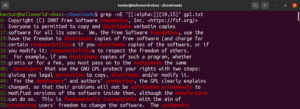
이 기능을 사용하면 일치하는 길이의 하한과 상한을 정의할 수도 있습니다. 다음 예시에서 정규식은 길이가 10~15자인 모든 단어와 일치합니다:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
결론
grep으로 텍스트 파일을 검색하는 것은 매우 편리합니다. 정규식은 grep을 사용한 검색을 더욱 흥미롭고 유용하게 만듭니다. 또한 검색 패턴을 원하는 대로 미세 조정할 수 있습니다.
몇 가지 일반적인 정규식을 보여드렸지만, 이는 시작에 불과합니다. 검색 동작을 가장 정밀하게 제어할 수 있는 더 고급 정규식이 있습니다. grep 외에도 정규식은 다른 도구 및 프로그래밍 언어에서도 널리 사용됩니다.
즐거운 컴퓨팅 되세요!
댓글
아직 댓글이 없습니다. 첫 번째로 작성해 보세요.