
A CSV 파일은 표 형식으로 데이터를 저장하는 일반 텍스트 파일입니다. 대부분의 경우 CSV 파일은 쉼표(,)를 구분 기호로 사용하므로 CSV(Comma Separated Values)라는 이름이 붙었습니다. CSV는 모든 텍스트 편집기, 스프레드시트 앱 및 기타 특수 도구로 열 수 있으므로 데이터 호환성이 중요한 상황에서 사용됩니다. 실제로 많은 프로그래밍 언어가 CSV에 대한 내장 지원을 제공합니다.
이 가이드에서는 샘플 Node.js 애플리케이션에서 CSV를 사용하는 방법에 대해 알아봅니다.
Node.js에서의 CSV
Node.js는 오픈 소스이자 크로스 플랫폼 JavaScript 런타임 환경입니다. 인터넷상의 수많은 웹 서비스를 구동하는 가장 인기 있는 백엔드 중 하나가 되었습니다. Netflix 및 Uber와 같은 대기업도 Node.js를 사용하여 서비스를 구동합니다.
Node.js에는 프로젝트에 추가 기능을 더하기 위해 배포할 수 있는 수많은 모듈도 있습니다. CSV의 경우 사용할 수 있는 모듈이 많습니다. 예를 들어, node-csv, fast-csv, papaparse 등이 있습니다.
가이드의 제목에서 알 수 있듯이, 우리는 node-csv 를 사용하여 Node.js 스트림으로 CSV 파일을 읽을 것입니다. 또한 파싱된 데이터를 다루는 방법(예: 데이터를 SQLite 데이터베이스로 전송하는 방법)도 시연할 것입니다.
전제 조건
-
이 가이드에 설명된 단계를 수행하려면 다음 구성 요소가 필요합니다:
-
올바르게 구성된 Linux 시스템. 자세한 내용은 CloudSigma에서 Ubuntu 클라우드 서버 설치 및 구성하기.
-
다음 권한을 가진 non-root 사용자에 대한 액세스 권한: sudo 권한. 다음을 확인하세요: sudoers로 sudo 권한 관리하기.
-
적절한 텍스트 편집기(예: Brackets, VS Code, Sublime Text, Vim/NeoVim 등)
-
기타 소프트웨어:
-
Node.js LTS
-
SQLite
-
1단계 – 필수 소프트웨어 설치
이 가이드를 위해 Ubuntu 22.04 LTS를 실행하는 경량 서버를 생성했습니다(SSH를 통해 연결됨):
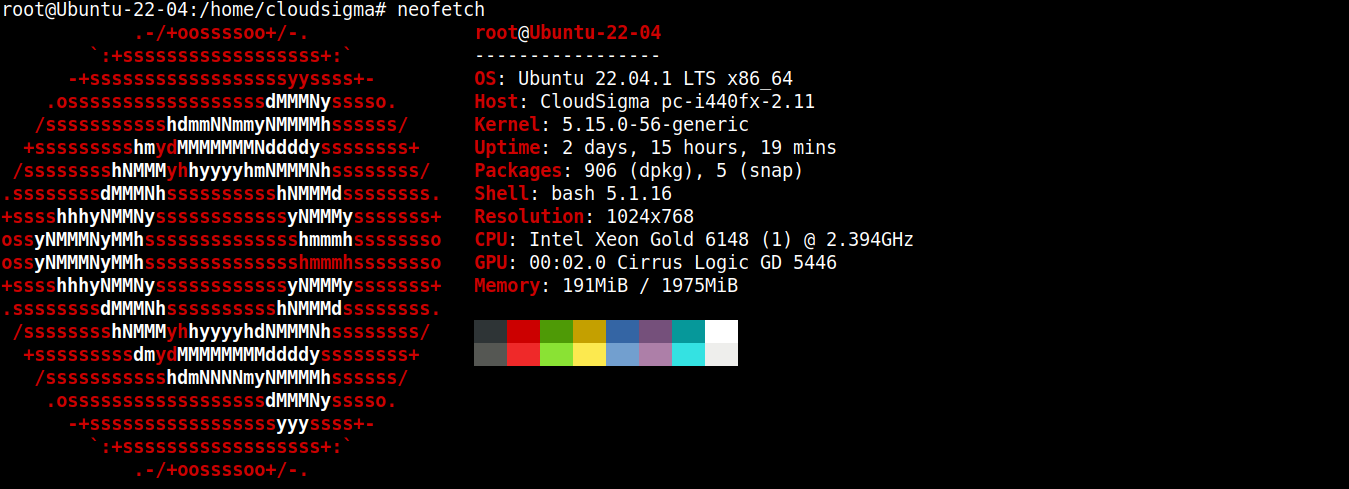
이제 여기에 Node.js와 SQLite를 설치하겠습니다.
-
Node.js LTS 설치
Node.js는 공식 Ubuntu 패키지 저장소에서 직접 설치할 수 있습니다. 하지만 최신 버전은 아닙니다. 그렇기 때문에 최신 Node.js 패키지를 얻기 위해 서드파티 저장소(Nodesource)에 의존할 것입니다.
Node.js LTS용 저장소 추가:
|
1 |
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - |
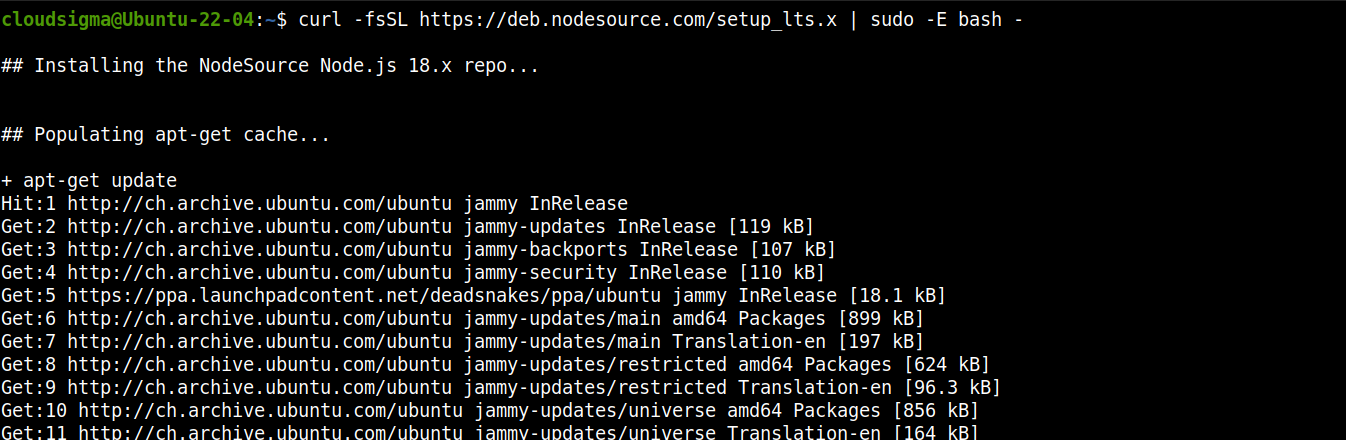
이제 Node.js LTS를 설치합니다:
|
1 |
sudo apt install nodejs -y |

-
SQLite 설치
Ubuntu 패키지 저장소에서 직접 SQLite를 설치하겠습니다. 다음 명령을 실행하세요:
|
1 |
sudo apt install sqlite3 -y |

2단계 – 프로젝트 디렉터리 설정
이 섹션에서는 프로젝트를 위한 전용 디렉터리를 준비하겠습니다. 이 디렉터리에는 추가 모듈과 함께 모든 프로젝트 파일이 저장됩니다.
새 디렉터리 생성:
|
1 |
mkdir -pv csv_practice |
디렉터리로 이동:
|
1 |
cd csv_practice/ |
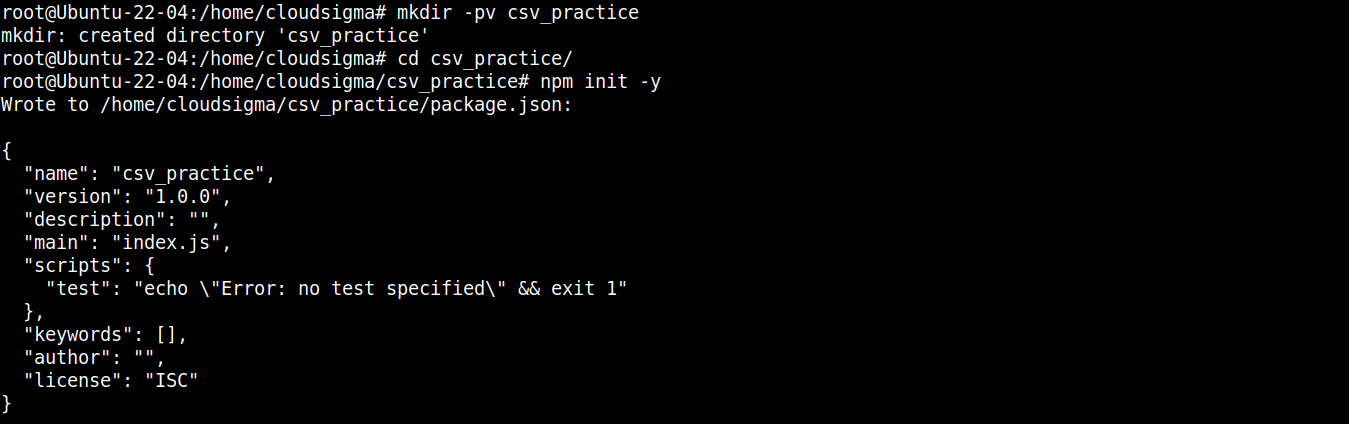
다음으로, 디렉터리를 npm 프로젝트로 선언하기 위해 다음 명령을 실행합니다:
|
1 |
npm init -y |
프로젝트 폴더가 초기화되면 필요한 패키지와 모듈 설치를 시작할 수 있습니다. 먼저, node-csv:
|
1 |
npm install csv |

node-csv 모듈은 실제로는 다음과 같은 여러 다른 모듈의 모음입니다: csv-generate, csv-parse (CSV 파일 파싱), csv-stringify (CSV에 데이터 쓰기), 그리고 stream-transform.
다음으로 SQLite와 통신하기 위한 모듈이 필요합니다. 다음 명령은 node-sqlite3 모듈을 설치합니다:
|
1 |
npm install sqlite3 |

우리 프로젝트에 필요한 구성 요소는 CSV 파일입니다. 데모 목적으로 뉴질랜드 이주 CSV 파일을 사용하겠습니다:
|
1 |
wget https://www.stats.govt.nz/assets/Uploads/International-migration/International-migration-September-2021-Infoshare-tables/Download-data/international-migration-September-2021-estimated-migration-by-age-and-sex-csv.csv -O migration_data.csv |
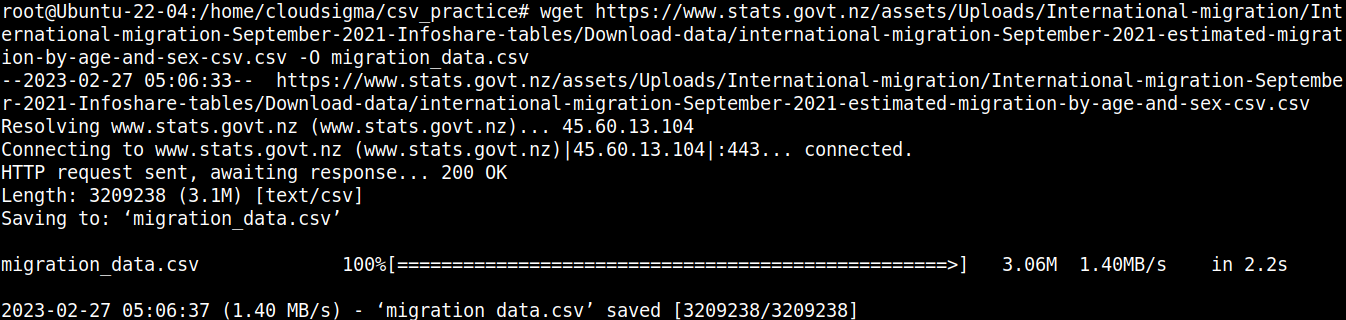
파일의 내용을 빠르게 살펴보겠습니다:
|
1 |
cat migration_data.csv | less |
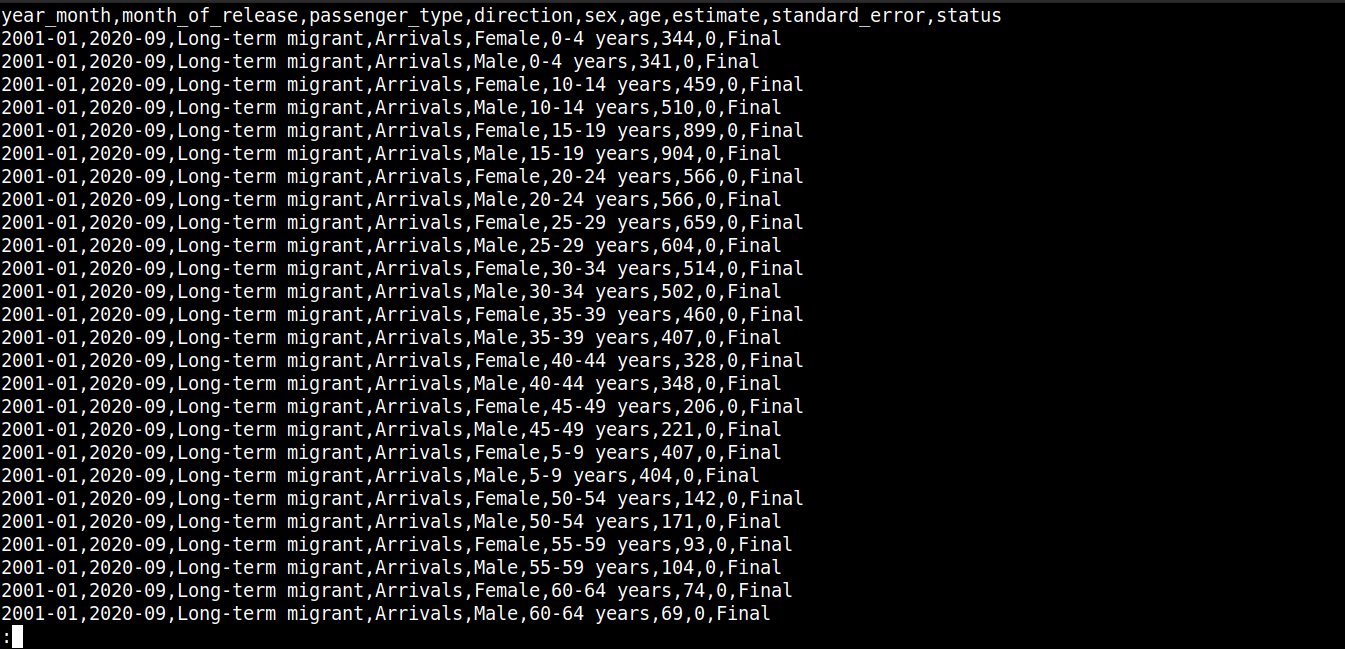
여기서,
-
첫 번째 줄은 열 이름을 설명합니다.
-
그 다음 줄들은 이 필드들의 값을 포함합니다.
-
각 행은 줄바꿈(\n)으로 구분됩니다.
-
각 데이터 포인트는 쉼표(,)로 구분됩니다.
하지만 CSV가 구분 기호로 쉼표만 사용하는 것은 아닙니다. 다른 일반적인 구분 기호로는 콜론(:), 세미콜론(;), 탭(\td) 등이 있습니다.
3단계 – CSV 읽기
이 섹션에서는 CSV 파일에서 데이터를 읽고 파싱하는 샘플 프로그램 구현을 보여드리겠습니다.
새로운 JavaScript 파일을 생성합니다:
|
1 |
touch read_csv.js |
원하는 텍스트 에디터로 파일을 엽니다:
|
1 |
nano read_csv.js |
먼저, 다음 모듈을 가져옵니다. fs 및 csv-parse 모듈:
|
1 2 |
const fs = require("fs"); const { parse } = require("csv-parse"); |
여기서,
-
먼저, fs 변수에는 fs 객체가 할당되며, 이는 모듈을 가져올 때 Node.js require() 메서드에 의해 반환됩니다.
-
다음으로, require() 메서드에 의해 반환된 객체에서 parse 메서드를 추출하여 parse 변수에 할당할 때 다음을 사용합니다: 구조 분해 구문.
다음으로, CSV 파일을 읽는 코드를 추가하겠습니다:
|
1 2 3 4 5 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) |
여기서,
-
우리는 createReadStream()을 fs 모듈에서 호출하고 읽으려는 CSV 파일을 인수로 전달합니다. 그런 다음 큰 파일을 더 작은 청크로 나누어 읽기 가능한 스트림을 생성합니다.
-
스트림을 생성한 후, pipe() 메서드는 스트림 데이터의 청크를 다른 스트림으로 전달합니다. 이 새로운 스트림은 parse() 메서드를 csv-모듈에서 호출할 때 생성됩니다..
-
The csv-모듈은 데이터 청크를 받아 다른 형태로 변환하는 읽기/쓰기 변환 스트림을 배포합니다.
-
The parse() 메서드는 속성을 가진 객체를 허용합니다. 이 객체는 파싱된 데이터를 추가로 처리합니다. 여기서 객체는 다음과 같은 속성을 가집니다:
-
delimiter: 값을 구분하는 구분 기호 문자입니다. 대상 CSV의 경우 쉼표(,)입니다.
-
from_line: 파서가 파싱을 시작할 라인 번호입니다. 제공된 값인 2를 사용하면 파서는 1번째 줄을 건너뛰고 2번째 줄부터 시작합니다. 이 설정을 통해 열 이름이 파싱된 데이터에 통합되는 것을 방지합니다.
-
다음으로, Node.js의 on() 메서드를 사용하여 스트리밍 이벤트를 연결하겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
여기서,
-
특정 이벤트가 발생하면, 스트리밍 이벤트를 통해 메서드가 데이터 청크를 소비할 수 있습니다.
-
When data parsed by parse() 메서드에 의해 파싱된 데이터를 소비할 준비가 되면, data 이벤트를 트리거합니다.
-
데이터에 액세스하기 위해, row 매개변수를 받는 콜백을 on() 메서드에 전달합니다.
-
row 매개변수는 배열 형태의 데이터 청크(파싱 결과)입니다.
-
마지막으로, 데이터는 다음을 사용하여 콘솔에 기록됩니다: console.log().
프로그램을 완료하기 위해, 오류를 처리하고 CSV 파일의 모든 데이터가 소비되었을 때 성공 메시지를 출력하는 추가 스트림 이벤트를 더하겠습니다. 코드를 다음과 같이 업데이트하세요:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
여기서,
-
end 이벤트는 CSV 파일의 모든 데이터가 소모되었을 때 발생합니다. 결과적으로 다음을 호출하게 됩니다. console.log() 메서드를 호출하여 성공 메시지를 출력합니다.
-
error 이벤트는 CSV 데이터를 파싱하는 동안 오류가 발생했을 때 발생합니다. 결과적으로 다음을 호출하게 됩니다. console.log() 메서드를 호출하여 오류 메시지를 출력합니다.
최종 코드는 다음과 같아야 합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const fs = require("fs"); const { parse } = require("csv-parse"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
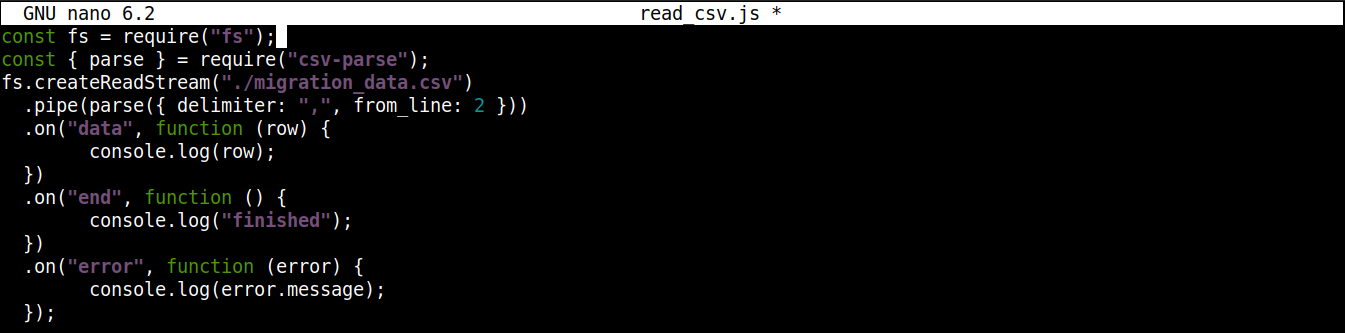
파일을 저장하고 편집기를 닫습니다. 이제 프로그램을 실행할 준비가 되었습니다. Node.js를 사용하여 실행하세요:
|
1 |
node read_csv.js |
출력은 다음과 같이 표시되어야 합니다:

데이터가 소모되고, 변환되어 콘솔에 출력되는 것을 확인하세요. 이는 연속적인 프로세스이므로 출력이 한 번에 모두 인쇄되는 것이 아니라 데이터가 다운로드되는 것처럼 보입니다.
4단계 – CSV 데이터를 데이터베이스로 전송하기
지금까지 우리는 다음을 사용하여 CSV 파일을 파싱하는 방법을 배웠습니다. node-csv. 이 섹션에서는 파싱된 데이터를 데이터베이스(SQLite)로 전송하는 방법을 보여줍니다.
데이터베이스와 상호 작용하기 위한 새 JavaScript 파일을 생성합니다:
|
1 |
touch csv-to-sqlite3.js |
이제 텍스트 편집기에서 파일을 엽니다:
|
1 |
nano csv-to-sqlite3.js |
![]()
다음 코드로 프로그램을 시작하겠습니다:
|
1 2 3 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; |

여기서,
-
첫 번째 줄에서는 다음을 가져옵니다. fs 모듈.
-
세 번째 줄에서 변수 filepath은 SQLite 데이터베이스의 경로를 포함합니다.
-
이 시점에서는 데이터베이스가 아직 존재하지 않습니다. 하지만 다음을 작업할 때 필요합니다. node-sqlite3.
다음으로, SQLite 데이터베이스에 대한 연결을 설정하기 위해 다음 줄을 추가합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } console.log("Connected to the database successfully"); }); return db; } } |
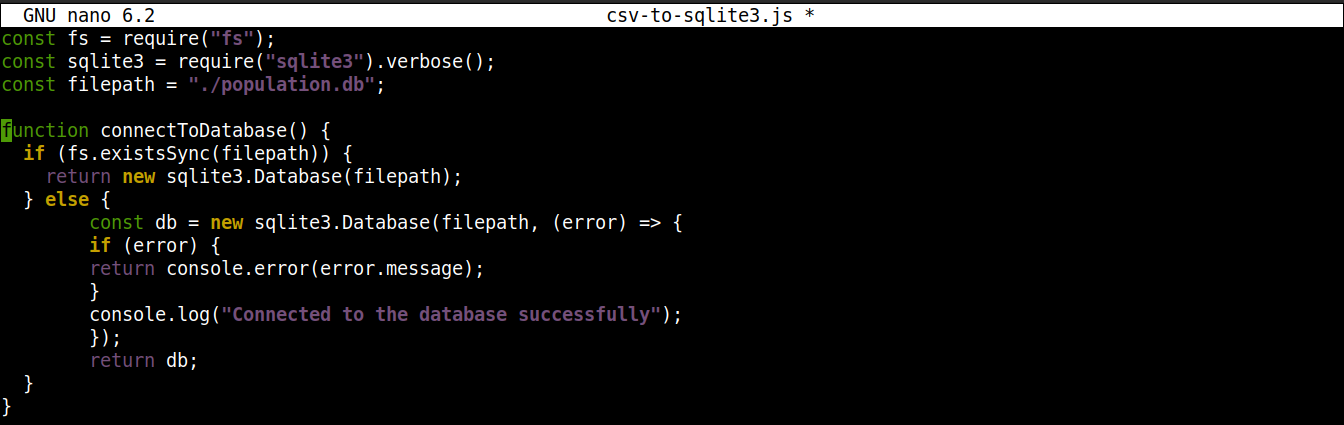
여기서,
-
메서드 connectoToDatabase()는 데이터베이스에 대한 연결을 설정합니다.
-
Within connectToDatabase() 내에서, 우리는 existsSync() 메서드를 if문 내의 fs 모듈에서 호출하고 있습니다. 이 if문은 지정된 위치에 데이터베이스가 존재하는지 확인합니다.
-
조건 평가가 true 이면, Database() 클래스가 node-sqlite3 모듈의 클래스입니다. 연결이 설정되면 함수는 객체를 반환하고 종료됩니다.
-
조건 평가가 false (데이터베이스가 존재하지 않음) 이면, 실행은 else 블록으로 이동합니다. 거기서 Database() 클래스는 데이터베이스 파일의 경로와 콜백이라는 두 개의 인수로 시작됩니다.
-
기본적으로 데이터베이스가 존재하지 않으면 생성됩니다. 그러나 생성 과정에서 오류가 발생하면 error 객체를 설정하고 오류 메시지를 출력합니다.
다음으로, 데이터베이스가 존재하지 않을 때 테이블을 생성하는 코드를 소개하겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } createTable(db); console.log("Connected to the database successfully"); }); return db; } } function createTable(db) { db.exec(` CREATE TABLE migration ( year_month VARCHAR(10), month_of_release VARCHAR(10), passenger_type VARCHAR(50), direction VARCHAR(20), sex VARCHAR(10), age VARCHAR(50), estimate INT ) `); } module.exports = connectToDatabase(); |
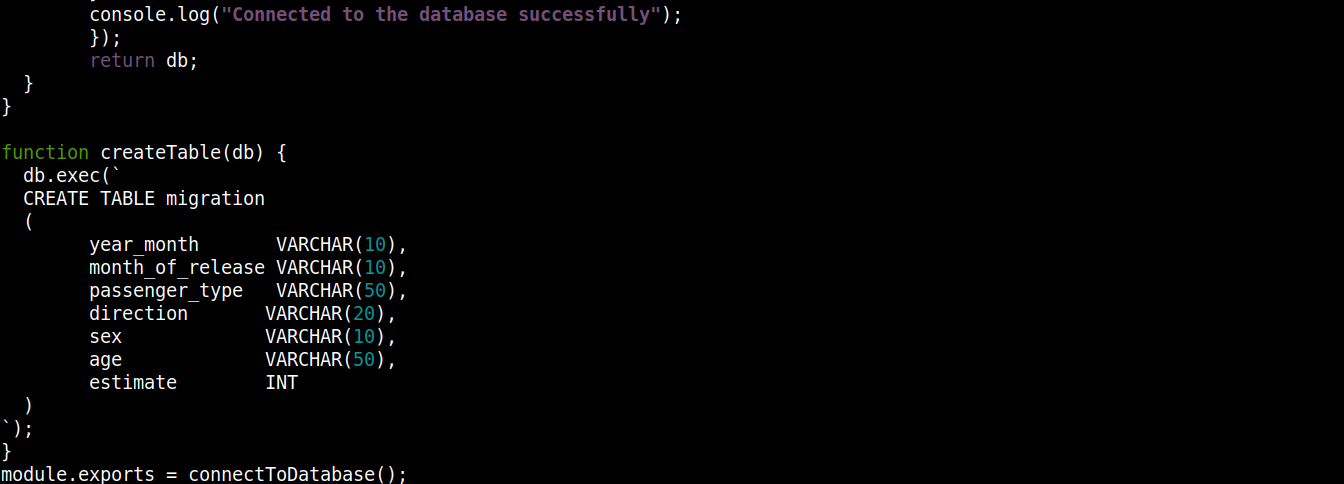
여기서,
-
The connectToDatabase() 함수는 createTable() 함수를 호출하며, 이 함수는 db에 저장된 객체를 인수로 받습니다.
-
외부에,connectToDatabase() 우리는 createTable() 메서드를 정의했으며, 이 메서드는 연결 객체 db 를 매개변수로 받습니다.
-
The exec() 메서드는 db에서 SQL 문을 인수로 받습니다. 이 SQL 문 내에서 우리는 migration 테이블을 7개의 열로 생성하도록 정의했으며, 각 열은 migration_data.csv 파일의 열 제목에 대응됩니다.
-
마지막으로, 우리는 connectToDatabase() 메서드 및 그것이 반환하는 연결 객체를 내보내어 다른 파일에서 사용할 수 있도록 합니다.
파일을 저장하고 편집기를 닫습니다.
다음으로, 파싱된 데이터를 데이터베이스에 삽입하는 또 다른 프로그램을 생성하겠습니다.
|
1 |
nano insert_data.js |
다음 코드를 다음에 입력합니다: insert_data.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const fs = require("fs"); const { parse } = require("csv-parse"); const db = require("./csv-to-sqlite3"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { db.serialize(function () { db.run( `INSERT INTO migration VALUES (?, ?, ? , ?, ?, ?, ?)`, [row[0], row[1], row[2], row[3], row[4], row[5], row[6]], function (error) { if (error) { return console.log(error.message); } console.log(`Row inserted, ID: ${this.lastID}`); } ); }); }); |
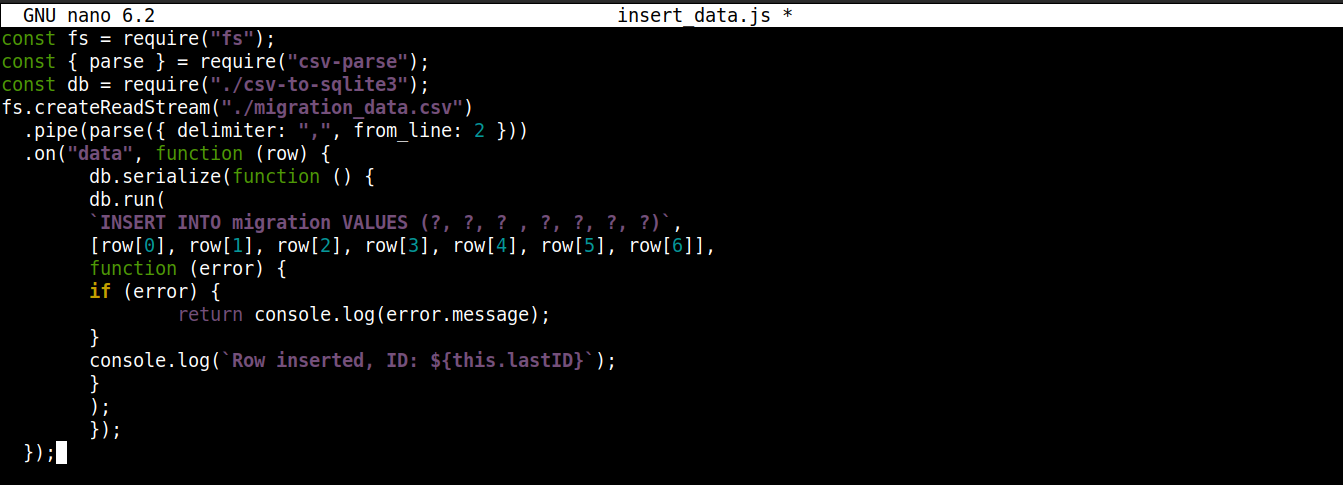
여기서,
-
다음에서 가져온 연결 객체를 csv-to-sqlite3.js 변수에 저장합니다. db.
-
데이터 이벤트 콜백(fs 모듈 스트림에 연결됨) 내부에서 다음 메서드를 호출합니다. serialize() 메서드를 연결 객체에서 호출합니다. 이 메서드는 하나의 SQL 문이 실행을 마친 후 다음 문이 시작되도록 보장하여 데이터베이스 경쟁 상태(시스템이 동시에 경쟁적인 작업을 실행하는 현상)를 방지합니다.
-
다음 serialize()은(는) 세 개의 인수를 받습니다:
-
첫 번째 인수는 SQL 문입니다.
-
두 번째 인수는 배열입니다.
-
세 번째 인수는 데이터가 데이터베이스에 성공적으로 삽입되거나 삽입에 실패했을 때 실행되는 콜백입니다.
-
프로그램을 실행할 준비가 되었습니다. 다음을 실행하세요. insert_data.js (Node.js 사용):
|
1 |
node insert_data.js |
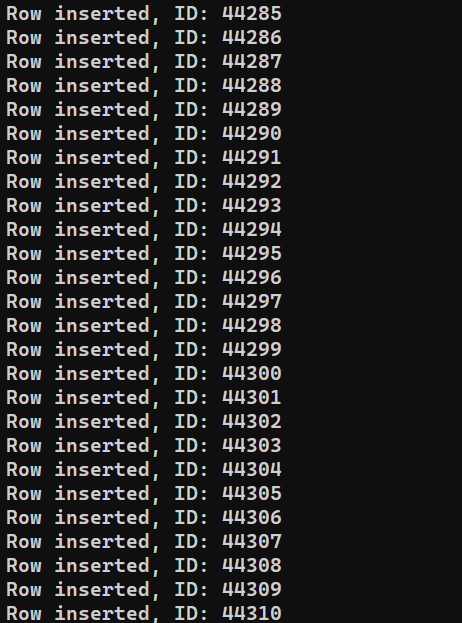
시스템 성능에 따라 프로세스가 완료되는 데 시간이 좀 걸릴 수 있습니다. 하지만 완료되면 출력은 다음과 같이 표시되어야 합니다:
5단계 – CSV에 데이터 쓰기
이전 섹션을 마친 후, 우리는 다음에서 파싱한 모든 레코드가 포함된 데이터베이스를 갖게 되었습니다. migration_data.csv. 이 섹션에서는 데이터베이스에서 데이터를 읽어 별도의 CSV 파일에 작성해 보겠습니다.
프로그램을 저장할 새 JavaScript 파일을 생성합니다:
|
1 |
nano write_csv.js |
먼저, 다음을 가져오기 위해 다음 줄을 추가합니다. fs 및 csv-stringify 그리고 다음의 데이터베이스 연결 객체도 함께 가져옵니다. csv-to-sqlite3.js:
|
1 2 3 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); |
다음으로, 쓰기 가능한 스트림과 함께 데이터를 기록할 CSV 파일의 이름이 포함된 변수를 추가하겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 |
const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; |
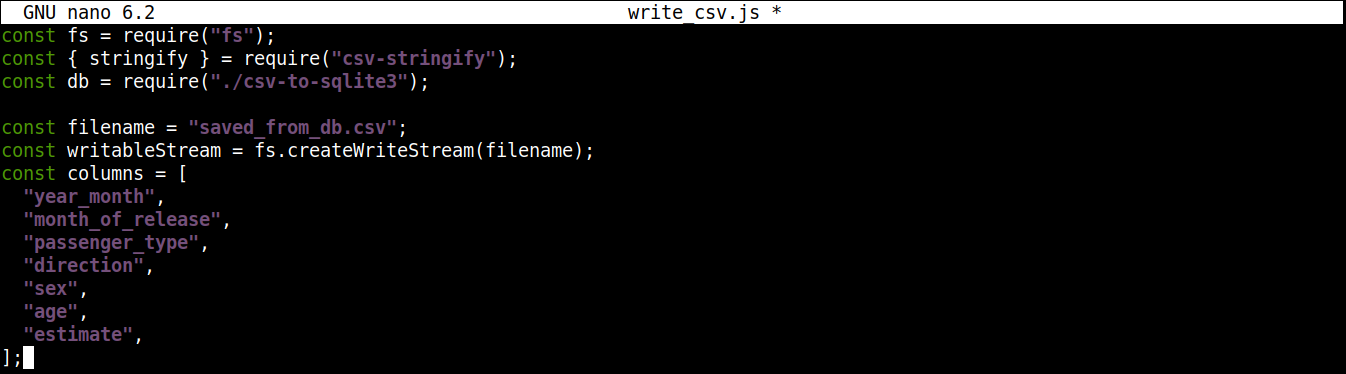
여기서,
-
이 createWriteStream() 메서드는 기록할 파일 이름을 인수로 받습니다. 파일 이름을 saved_from_db.csv로 지정하겠습니다..
-
이 column 변수는 CSV 데이터의 헤더 이름이 모두 포함된 배열을 저장합니다.
다음으로, 데이터베이스에서 데이터를 읽어 saved_from_db.csv에 기록하는 다음 코드 줄을 추가합니다::
|
1 2 3 4 5 6 7 8 9 10 11 |
const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
여기서,
-
우리는 stringify() 메서드를 객체를 인수로 하여 호출합니다. 이 메서드는 객체의 데이터를 CSV 형식으로 변환하는 변환(transform) 스트림을 생성합니다. stringify()에 전달되는 객체는 두 개의 속성을 가집니다:
-
header: 불리언(Boolean) 값을 허용합니다. 값이 true 이면 헤더가 생성됩니다.
-
columns: header가 true인 경우, CSV 파일의 첫 번째 줄에 기록될 열 이름이 포함된 배열을 허용합니다..
-
-
이 each() 메서드는 csv-to-sqlite3 연결 객체에서 두 개의 인수, 즉 SQL 문(데이터베이스에서 데이터 읽기)과 콜백(성공/오류 처리)과 함께 호출됩니다.
-
Upon each iteration of each(), pipe()의 매 반복마다, ( stringifier 스트림의) pipe가 쓰기 가능한 스트림인 writableStream으로 데이터를 청크 단위로 전송하기 시작합니다. 그런 다음 각 데이터 청크는 saved_from_db.csv에 기록됩니다..
-
모든 데이터가 CSV 파일에 기록되면 콘솔 화면에 성공 메시지가 출력됩니다.
최종 코드는 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("CSV 파일 쓰기 완료"); |
파일을 저장하고 편집기를 닫습니다. 이제 Node.js를 사용하여 프로그램을 실행할 수 있습니다:
|
1 |
node write_csv.js |
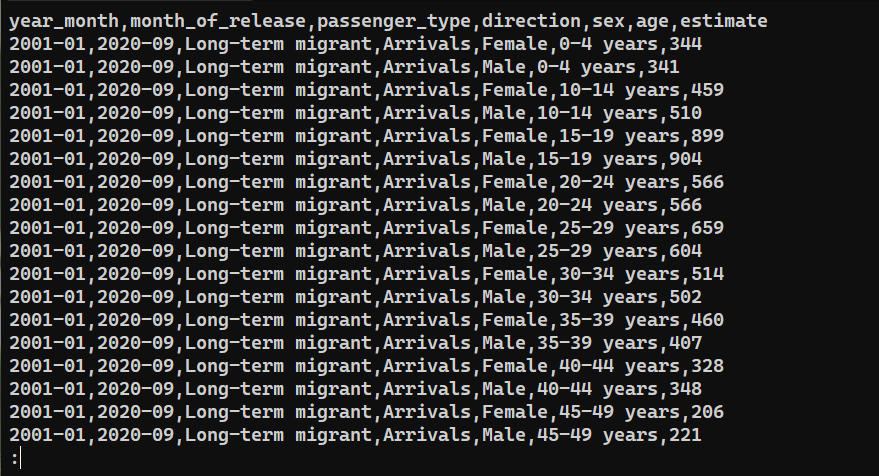
데이터가 성공적으로 내보내졌는지 확인하려면 다음 파일의 내용을 확인하십시오. saved_from_db.csv:
|
1 |
cat saved_from_db.csv | less |
마치며
이 가이드에서는 node-csv 및 node-sqlite3 모듈을 사용하여 Node.js에서 CSV 파일을 다루는 방법을 살펴보았습니다. CSV에서 데이터 파싱하기, SQLite 데이터베이스에 데이터 삽입하기, 새 CSV 파일에 데이터 쓰기 등 다양한 작업을 수행하기 위해 여러 프로그램을 만들었습니다.
이 가이드는 다음 모듈 기능의 아주 일부분만을 보여줍니다. node-csv 모듈. 다음에서 모든 기능에 대해 자세히 알아보십시오. CSV 프로젝트. node-sqlite3에 대해 자세히 알아보려면 다음을 확인하십시오. GitHub의 공식 문서. 언급할 만한 또 다른 모듈은 event-stream 입니다. 이 모듈은 스트림 작업을 간소화합니다.
Node.js 프로젝트를 더 확장하고 싶으신가요? 확인해 볼 만한 몇 가지 Node.js 튜토리얼을 소개합니다:
즐거운 코딩 되세요!
댓글
아직 댓글이 없습니다. 첫 번째로 작성해 보세요.