

비즈니스는 많은 데이터를 수반하며, 이로 인해 데이터를 처리하고 관리하는 문제가 더 어려워집니다. 전통적으로 업계에서는 수십 년 동안 RDBMS 시스템을 사용해 왔지만, 21세기에 빅데이터가 등장하면서 대규모 비정형 및 반정형 데이터를 처리하기 위해 NoSQL(Not only SQL) 데이터베이스가 등장했습니다.
이 포스트에서는 MongoDB 클러스터를 구축해 보겠습니다.
MongoDB 는 제공하는 높은 수준의 확장성과 유연성 덕분에 널리 사용되는 무료 오픈 소스 NoSQL 문서 데이터베이스입니다.
프로덕션 환경에 MongoDB를 배포하려면 Replica Set을 사용하는 것이 좋습니다. Replica Set은 관계형 데이터베이스 세계의 Master/Slave 설정에 해당하는 MongoDB의 기능이지만, 모든 것이 내장되어 있어 설정이 매우 간편하다는 차이점이 있습니다. Replica Set에 대한 자세한 내용은 다음을 참조하세요. 복제 프로세스에 대한 TutorialsPoint’s의 정의.
MongoDB 클라우드 서버 클러스터 계획하기
저는 3개의 노드로 구성된 클러스터를 생성할 것입니다. 이들 중 어느 것이든 기본(즉, 마스터) 서버가 될 수 있으므로 동일한 리소스를 부여하는 것이 중요합니다. 이 노드 또는 머신은 어떤 운영체제에서도 실행할 수 있지만, 이 튜토리얼에서는 Ubuntu 18.04 LTS를 사용할 것입니다. CloudSigma’s 라이브러리에서 사전 설치된 이미지를 연결하고 설정하는 방법은 다음을 참조하세요. 이 튜토리얼.
Replica Set의 핵심은 단일 노드가 다운되더라도 클러스터가 계속 작동해야 한다는 점이므로, 모든 서버가 동일한 물리적 호스트에 있는 것은 의미가 없습니다. 다행히도 CloudSigma는 다음과 같은 기능을 제공합니다. 가용성 그룹. 이는 시스템에 세 개의 서버를 모두 서로 다른 그룹으로 그룹화하도록 지시할 수 있음을 의미합니다. 이렇게 하면 서버들이 동일한 물리적 호스트에 절대 함께 상주하지 않습니다. 이 기능 및 기타 보안 및 비즈니스 연속성 기능에 대한 자세한 정보는 다음에서 확인할 수 있습니다. 여기.
또한 64비트 버전의 Linux를 사용하는 것이 중요합니다. 그 이유는 단순히 MongoDB가 32비트 시스템에서 제대로 작동하지 않기 때문입니다(이에 대한 자세한 내용은 여기).
클라우드에 MongoDB 설치하기
이 섹션은 매우 간단합니다. 사전 구성된 Ubuntu 18.04 이미지 중 하나를 사용하거나 직접 설치하세요.
CPU, RAM 및 디스크 구성은 실제로 개별적이며 부하에 따라 다릅니다. 소규모 설치의 경우 4 GHz CPU, 4 GB RAM 및 10 GB 디스크(시스템용)로 충분합니다. 드라이브를 연결할 때, VirtIO를 사용하고 있는지 확인하세요. IDE를 사용하면 성능이 크게 저하됩니다. 또한 Replica Set을 생성하므로 모든 노드(및 앱 서버)가 동일한 VLAN에 있어야 합니다.
다른 많은 클라우드 제공업체와 달리, 성능 향상을 위해 스토리지를 RAID10 등으로 구성할 필요가 없습니다. 많은 고객들이 보고하듯이, CloudSigma에서 SSD와 마그네틱 디스크를 모두 사용하면 즉시 놀라운 성능을 얻을 수 있습니다.
그래도 MongoDB 데이터는 별도의 드라이브에 보관하는 것을 권장합니다. 그 이유는 단순히 어느 시점에 전체 파일 시스템에 적용하고 싶지 않은 일부 파일 시스템 최적화를 수행해야 할 수도 있기 때문입니다.
이를 염두에 두고, 서버를 설정한 후에 이 드라이브를 추가하는 것이 가장 쉽습니다. 지금은 시스템 설치에만 집중해 보겠습니다. (사전 구성된 시스템을 사용하는 대신) 직접 설치하는 경우, 부팅 메뉴에서 F4를 누르고 다음을 선택하는 것을 권장합니다. ‘최소 가상 머신 설치’.
저는 각각 다음과 같은 사양을 가진 3대의 머신을 생성하고 있습니다:
- CPU: 4 GHz
- RAM: 4 GB
- SSD: 10 GB (Ubuntu 18.04 LTS), 20 GB (추가 드라이브)
SSD 부분에 나열된 대로, Ubuntu 18.04 LTS가 설치된 10 GB 크기의 드라이브를 연결하고 있습니다.
또한, MongoDB 데이터를 저장하기 위해 20 GB 크기의 다른 빈 드라이브를 함께 연결하고 있습니다. 이 크기는 사용량에 따라 크게 달라지지만, 소규모 시스템의 경우 20GB로도 충분할 것입니다. 하지만 저장할 데이터의 양을 예측하기 어려운 경우가 있으므로, 우리는 다음을 사용할 것입니다. LVM. 이렇게 하면 나중에 처음부터 다시 시작할 필요 없이 단순히 다른 드라이브를 추가하고 볼륨을 확장할 수 있습니다. 또는 단일 드라이브를 사용하고 나중에 다음을 통해 확장할 수 있습니다: resize2fs.
To add the disk, just go to the ‘Drives’ Section, click on ‘Create a new drive’ icon on the top, give the new disk a name and size it to 20 GB. Once it’s saved, go to the individual machine to which you want to attach it and under drives section of that machine’s details, I can click on ‘Attach a drive’ and select the disk.
이제 세 대의 머신이 준비되었으므로 각 머신에 MongoDB 데이터 스토리지를 위해 추가한 디스크를 마운트할 수 있습니다. 이 디스크를 파티션으로 추가하는 것을 권장합니다. 파티션을 사용하면 운영 체제가 각 영역의 정보를 별도로 관리할 수 있습니다. 디스크를 파티션으로 추가하기 위해 먼저 머신에 연결된 모든 디스크를 확인하겠습니다. 이를 위해 다음 명령을 실행합니다:
|
1 |
fdisk -l |
명령을 실행하면 머신의 디스크와 장치를 나타내는 출력이 표시됩니다.
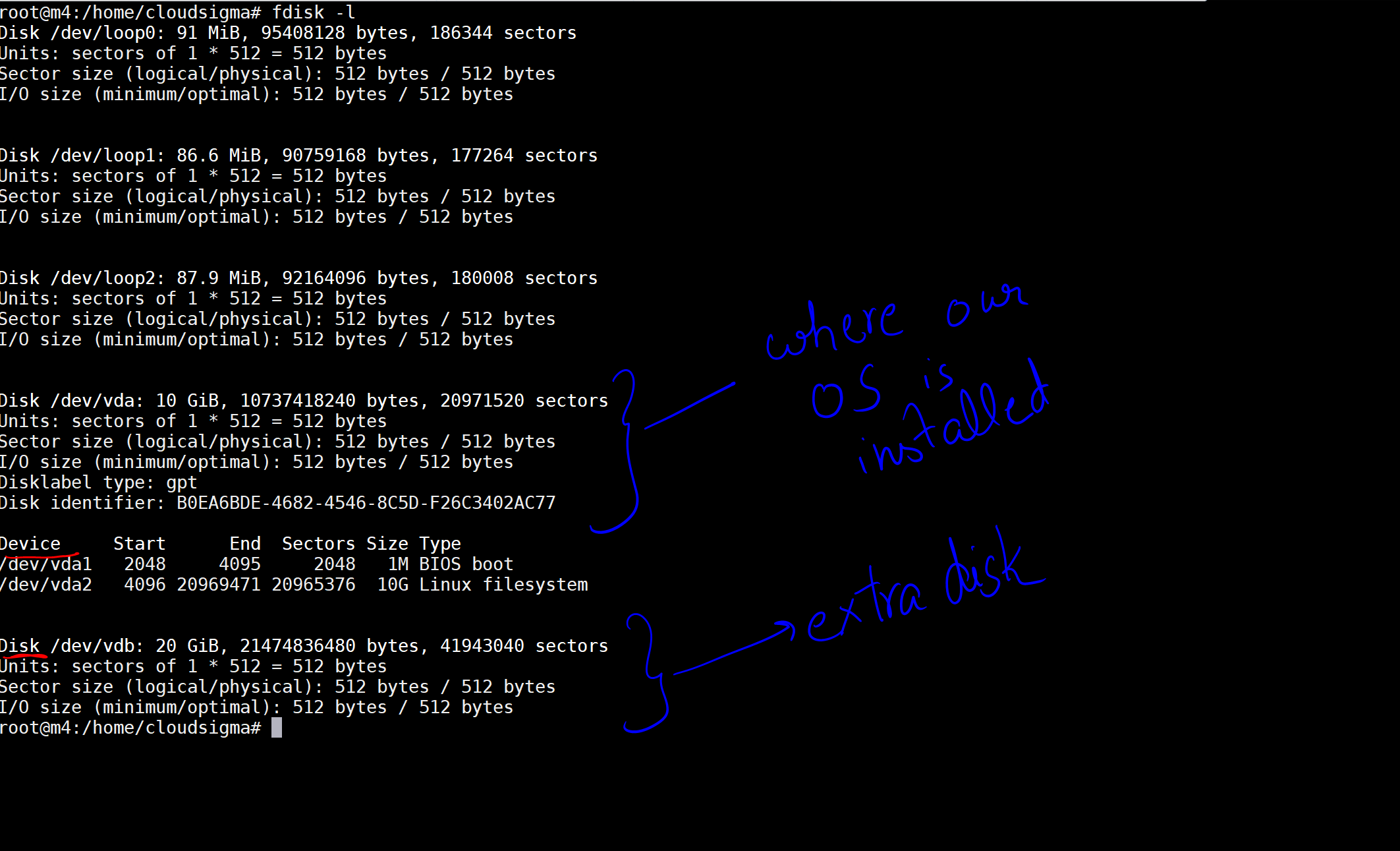
이미지에서 OS가 설치된 디스크를 10GB 디스크로 표시했습니다. 그리고 현재 연결된 20GB의 다른 디스크가 있습니다. 디스크 위치는 /dev/vdb. 다음 명령을 사용하여 이 디스크에 파티션을 생성할 수 있습니다:
|
1 |
sudo fdisk /dev/vdb |
그러면 디스크 파티션 기능을 제공하는 명령줄 유틸리티인 fdisk 유틸리티가 열리며, 여기서 디스크에 파티션을 생성할 수 있습니다. “Command (m for help):”라는 프롬프트가 표시되면 다음을 입력해야 합니다: n 을 입력하여 새 파티션을 생성한 다음, 기본값을 수락하려면 엔터를 계속 누르십시오. 파티션이 생성된 후에는 다음을 입력하십시오: w 을 입력하여 변경 사항을 저장합니다. 다음과 같이 표시됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Command (m for help): <strong>n</strong> Partition type p primary (0 primary, 0 extended, 4 free) e extended (container for logical partitions) Select (default p): Using default response p. Partition number (1-4, default 1): First sector (2048-41943039, default 2048): Last sector, +sectors 또는 +size{K,M,G,T,P} (2048-41943039, default 41943039): Created a new partition 1 of type 'Linux' and of size 20 GiB. Command (m for help): <strong>w</strong> The partition table has been altered. Calling ioctl() to re-read partition table. Syncing disks. |
‘Linux’ 유형의 20 GiB 크기의 새 파티션 1이 생성되었습니다. 파티션이 생성되었으므로 이제 LVM 풀을 생성해 보겠습니다:
|
1 2 3 |
sudo pvcreate /dev/vdb1 sudo vgcreate mongodb /dev/vdb1 sudo lvcreate -n db -L 19.5g mongodb |
파티션 크기가 20g이므로 ‘19.5g’를 입력했습니다. 다음으로, 디스크 이름을 찾기 위해 다음 명령을 실행합니다:
|
1 |
fdisk -l | grep mongo | awk '{print $2'} |
그 후, 다음 명령을 사용하여 ext4 방식으로 디스크를 포맷합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
sudo mkfs.ext4 /dev/mapper/mongodb-db 출력: root@m4:/home/cloudsigma# sudo mkfs.ext4 /dev/mapper/mongodb-db mke2fs 1.44.1 (24-3월-2018) 생성 중 파일 시스템 으로 5217280 4k 블록 및 1305600 아이노드 파일 시스템 UUID: 695a62e6-021d-4fc0-945c-cc51a92d86da 수퍼블록 백업 저장됨 에 블록: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 할당 중 그룹 테이블: 완료 기록 중 아이노드 테이블: 완료 생성 중 저널 (32768 블록): 완료 기록 중 수퍼블록 및 파일 시스템 어카운팅 정보: 완료 |
다음으로, 디스크를 마운트할 위치와 MongoDB 데이터를 보관할 폴더를 생성해 보겠습니다.
|
1 |
sudo mkdir -p /mongodb/data |
마운트할 새 디스크에 대한 항목을 fstab에 추가하려면 아래 명령을 직접 사용할 수 있습니다.
|
1 |
echo -e "` blkid | grep mongodb | awk {'print $2'}`\t/mongodb\text4 auto,noexec,rw,sync,nouser\t0\t0" >> /etc/fstab |
이 명령에서 blkid 은 각 디스크의 범용 고유 식별자인 UUID–를 제공합니다. 여기서는 MongoDB 디스크에 대한 UUID를 grep으로 추출하고, 이 UUID를 각각 마운트 폴더의 위치, 파일 시스템 유형 및 디스크의 기타 옵션과 결합합니다. 이 줄을 /etc/fstab에 추가합니다. 그렇게 하지 않으면 디스크를 마운트하는 동안 오류가 발생합니다. 항목은 다음과 같습니다.
UUID=”695a62e6-021d-4fc0-945c-cc51a92d86da” /mongodb ext4 auto,noexec,rw,sync,nouser 0 0
이제 /mongodb 위치에 디스크를 마운트할 수 있습니다.
|
1 |
sudo mount /mongodb |
MongoDB 설치하기
시스템이 준비되었으므로 이제 MongoDB 설치로 넘어가겠습니다. 우분투는 자체 리포지토리에서 MongoDB 버전을 제공하지만, 대신 공식 MongoDB 버전을 사용하는 것을 권장합니다. 우분투 리포지토리는 릴리스가 상당히 뒤처져 있기 때문에, MongoDB를 최대한 활용하려면 공식 릴리스를 이용해야 합니다.
MongoDB는 자체 리포지토리를 제공하므로, 이를 시스템에 추가한 다음 평소처럼 MongoDB를 설치하면 됩니다. 수행할 단계는 다음과 같습니다.
먼저, 패키지 관리 시스템에서 사용하는 공개 키를 가져옵니다.
|
1 |
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4 |
그런 다음, 리스트 파일을 생성합니다. 여기에는 MongoDB가 있는 리포지토리가 포함되어 시스템이 해당 위치에서 다운로드할 수 있게 됩니다.
|
1 |
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list |
이제 변경 사항을 반영하기 위해 로컬 패키지 데이터베이스를 업데이트합니다.
|
1 |
sudo apt-get update |
이제 다음 명령을 사용하여 패키지를 설치할 수 있습니다.
|
1 |
sudo apt-get install -y mongodb-org |
각 머신에 MongoDB를 설치했습니다.
|
1 |
sudo service mongod start |
이제 생성된 드라이브의 데이터와 함께 MongoDB가 실행 중입니다. 과부하 및/또는 많은 연결이 예상되는 경우, ulimit 값을 높여야 할 수도 있습니다.
데이터에 대해 더 많은 통찰력을 얻고 싶다면, MongoDB의 MMS에 가입할 수도 있습니다. 이는 MongoDB를 위한 무료 클라우드 기반 모니터링 서비스입니다.
MongoDB 클라우드를 위한 복제 세트(Replica Set) 생성하기
이제 복제 세트를 생성해 보겠습니다. 그 전에 각 머신이 서로 통신할 수 있는지 확인해야 합니다. 이를 위해 /etc/hosts에 다음 항목들을 추가합니다.
|
1 2 3 |
IP-1 m1.mongo.cluster m1 IP-2 m2.mongo.cluster m2 IP-3 m3.mongo.cluster m3 |
확인을 위해 호스트 이름을 사용하여 머신에 핑(ping)을 시도해 볼 수 있습니다. 예를 들어 제 머신 1’의 IP가 IP-1, 즉 213.189.123.12라면, 다음과 같이 쓰는 대신
|
1 |
ping 123.189.123.12 |
다음과 같이 작성합니다.
|
1 2 3 |
ping m1.mongo.cluster 또는 ping m1. |
방화벽을 활성화한 경우(반드시 활성화해야 합니다), 노드가 내부 인터페이스의 28017 및 27017 포트에서 TCP 트래픽을 송수신할 수 있는지 확인하십시오.
이제 각 머신에서 다음 명령을 사용하여 mongod 서비스를 시작하십시오.
머신 m1에서,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m1.mongo.cluster |
다음으로 머신 m2에서,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m2.mongo.cluster |
머신 m3에서,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m3.mongo.cluster |
여기서,
mongod 은(는) 서비스의 이름입니다
dbpath 은(는) 데이터베이스 디렉터리의 위치입니다
replSet 은(는) 복제 세트의 이름입니다. 동일한 복제 세트에 속한 각 머신에 대해 동일해야 합니다
bind_ip 은(는) 이를 실행 중인 해당 머신의 호스트 이름입니다.
mongod 서비스를 시작한 후, 기본(primary) 서버(제 경우에는 m1을 선택했습니다)로 이동하여 mongo를 실행하십시오.
|
1 |
mongo |
그러면 MongoDB 터미널이 시작됩니다. 터미널에서 아래 명령을 사용하여 replicaSet을 초기화하십시오. 기본 구성으로 replicaSet이 생성됩니다:
|
1 |
rs.initiate() |
이제 다음 명령을 사용하여 다른 두 머신을 복제본으로 추가해 보겠습니다:
|
1 2 |
rs.add("m2.mongo.cluster") rs.add("m3.mongo.cluster") |
다음 명령을 사용하여 상태를 모니터링할 수 있습니다:
|
1 |
rs.status() |
이것으로 끝입니다. 이제 CloudSigma’의 매우 빠른 클라우드에서 MongoDB 클러스터를 가동하여 실행할 수 있습니다.
댓글
아직 댓글이 없습니다. 첫 번째로 작성해 보세요.