

Elastic Stack (이전에는 ELK Stack으로 알려짐)은 중앙 집중식 로깅을 위한 강력한 솔루션입니다. 이는 다음에서 개발한 오픈 소스 소프트웨어의 모음입니다: Elastic. 이를 통해 관리자는 모든 소스에서 모든 형식으로 생성된 로그를 검색, 분석 및 시각화할 수 있습니다. 이는 중앙 집중식 로깅으로 알려진 실무 형태입니다. 중앙 집중식 로깅은 단일 위치에서 모든 로그를 검색할 수 있으므로 서버 및 애플리케이션의 문제를 정확히 찾아낼 때 매우 유용할 수 있습니다. 또한 특정 시간의 로그를 상호 연관시켜 여러 서버의 문제를 식별하는 데 도움이 될 수 있습니다.
이 가이드에서는 다음 환경에 Elastic Stack을 설치하는 방법을 알아봅니다: Ubuntu 18.04. 먼저, 다음 튜토리얼을 따라 쉽게 CloudSigma에 Ubuntu 서버를 설치하세요.
Ubuntu에서의 Elastic Stack
Elastic Stack은 다음과 같은 구성 요소로 이루어져 있습니다:
- Elasticsearch: 분산형 RESTful 검색 엔진. 수집된 모든 데이터를 저장합니다.
- Logstash: Elastic Stack의 데이터 처리 구성 요소입니다. 들어오는 데이터를 Elasticsearch로 전송합니다.
- Kibana: 검색 및 로그 시각화 기능을 제공하는 웹 인터페이스입니다.
- Beats: 경량의 단일 목적 데이터 전송기입니다. 수많은 머신에서 Logstash 또는 Elasticsearch로 데이터를 보낼 수 있습니다.
스택의 각 구성 요소를 수동으로 설치해야 합니다.
전제 조건
설치를 진행하기 전에, Elastic Stack을 설치하기 위해 몇 가지 시스템 요구 사항을 충족해야 합니다:
- 하드웨어 요구 사항:
- CPU: CPU 2개 (root가 아닌 sudo 사용자로부터 액세스 가능)
- RAM: 4GB
- OpenJDK 11 (최신 Java LTS 릴리스). 이를 설치하려면 다음 Ubuntu 18.04에서 Java를 설정하는 방법에 대한 튜토리얼.
- 을 참고하세요. 적절한 구성이 포함된 Nginx. 다음 Ubuntu 18.04에 Nginx를 설치하는 가이드를 따라 설정할 수 있습니다.
저장 공간의 크기는 수집 및 저장할 로그의 수에 따라 달라집니다. 또한 Elastic Stack은 서버에 대한 중요한 정보도 다룹니다. 데이터 전송을 안전하게 유지하려면 TLS/SSL 인증서를 구성하는 것을 강력히 권장합니다. 다음 Nginx 서버에서 무료 SSL 인증서를 획득하는 튜토리얼.
을 따르십시오. 암호화된 서버 외에도 다음과 같은 단계가 필요합니다:
- FQDN (정규화된 도메인 이름). 이 가이드에서는 <domain>이 됩니다.
- 다음 도메인의 두 DNS 레코드 모두 서버를 가리킵니다.
- <domain>이 서버의 공인 IP를 가리키는 A 레코드.
- www.<domain>이 서버의 공인 IP를 가리키는 A 레코드.
Elastic Stack 설치하기
-
Elastic 리포지토리 구성하기
Elastic Stack의 구성 요소는 공식 Ubuntu 리포지토리에서 직접 제공되지 않습니다. 다행히 Ubuntu는 패키지 설치를 위해 3rd 파티(외부) 리포지토리를 허용합니다. 우리의 목적을 위해 Elastic 패키지 리포지토리를 추가하겠습니다. 이 리포지토리는 모든 Elastic 패키지의 최신 패키지 업데이트를 제공합니다. 패키지 위조를 방지하기 위해 모든 Elastic 패키지는 Elasticsearch 서명 키로 서명되어 있습니다. 먼저 Ubuntu 키링에 키를 추가합니다:
|
1 |
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - |
그 다음, “sources.list.d” 디렉터리 아래에 Elastic 소스 목록을 추가합니다. 이 디렉터리는 APT가 새 소스를 검색하는 데 사용하는 전용 디렉터리입니다:
|
1 |
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list |
마지막으로 APT 캐시를 업데이트합니다:
|
1 |
sudo apt update |
공식 문서에 따르면, 이 가이드에 표시된 순서대로 각 구성 요소를 설치하는 것이 권장됩니다. 이렇게 하면 각 제품이 의존하는 구성 요소가 올바른 위치에 배치됩니다.
-
Elasticsearch 설치 및 구성하기
Elastic 리포지토리가 구성되면 APT가 모든 Elastic 패키지를 다운로드하고 설치할 준비가 됩니다. 다음 명령을 실행하여 Elasticsearch를 설치합니다:
|
1 |
sudo apt install elasticsearch |
이제 Elasticsearch를 구성할 수 있습니다. “elasticsearch.yml” 파일은 클러스터, 노드, 경로, 네트워크, 메모리, 게이트웨이 등에 대한 구성 옵션을 제공합니다. 대부분은 파일에 미리 구성되어 제공됩니다. 다음으로, 원하는 텍스트 편집기로 Elasticsearch 구성 파일을 엽니다:
|
1 |
sudo vim /etc/elasticsearch/elasticsearch.yml |
Elasticsearch는 어디서나 9200번 포트에서 수신 대기합니다. 외부인이 데이터를 읽거나 REST API를 사용하여 Elasticsearch 클러스터를 종료하는 것을 방지하기 위해 Elasticsearch에 대한 외부 액세스를 제한하는 것을 권장합니다. Elasticsearch에 대한 액세스를 제한하고 보안을 강화하려면 다음 줄의 주석을 해제하고 해당 값을 바꾸십시오:
|
1 |
network.host: localhost |
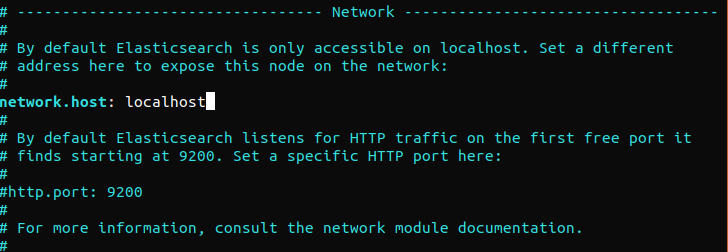
Elasticsearch가 특정 IP 주소에서 수신 대기하도록 하려면 “localhost”를 대상 IP 주소로 바꾸십시오. 이는 Elasticsearch를 실행하기 전의 최소 구성 요구 사항입니다. 구성 파일을 저장하고 닫습니다. 다음으로, Elasticsearch 서비스를 시작합니다. Elasticsearch를 시작하는 데 몇 분 정도 걸릴 수 있습니다:
|
1 |
sudo systemctl start elasticsearch |
그 후, 서버가 부팅될 때마다 Elasticsearch가 시작되도록 설정해야 합니다:
|
1 |
sudo systemctl enable elasticsearch |
다음 명령은 Elasticsearch 서비스가 실행 중인지 확인합니다. HTTP 요청을 보내기만 하면 됩니다:
|
1 |
curl -X GET "localhost:9200" |
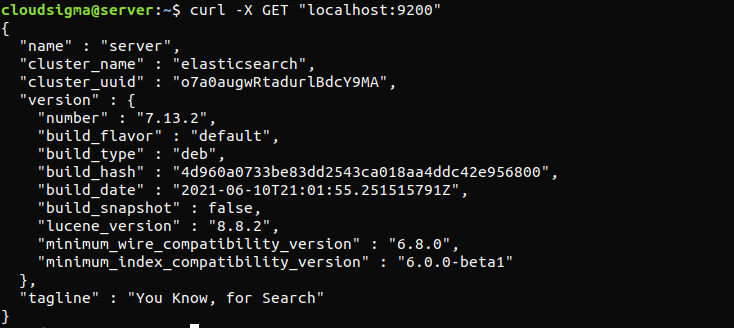
응답은 다음과 같이 표시됩니다. 로컬 노드에 대한 몇 가지 기본 정보를 보여주는 응답입니다.
Kibana 대시보드 설치 및 구성
Kibana는 Elastic 리포지토리에서 직접 사용할 수 있습니다. Kibana는 이미 Elasticsearch를 설치한 후에만 설치해야 합니다. 리포지토리를 이미 사용할 수 있다고 가정하면, APT가 Kibana를 직접 가져와 설치할 수 있습니다:
|
1 |
sudo apt install kibana |
설치가 완료되면 Kibana 서비스를 활성화하고 시작합니다:
|
1 2 |
sudo systemctl enable kibana sudo systemctl start kibana |
기본적으로 Kibana는 “localhost”에서만 수신 대기하도록 구성되어 있습니다. 외부에서 액세스하려면 역방향 프록시(reverse proxy) 구성이 필요합니다. 여기서는 Nginx가 역방향 프록시가 됩니다. 관리자 Kibana 사용자를 생성하려면 openssl 명령을 사용하십시오. 이는 Kibana 웹 인터페이스에 액세스하기 위한 사용자 계정이 됩니다. 여기에서 예시 사용자 이름은 “kibana_admin”입니다. 더 나은 보안을 위해 표준이 아닌 사용자 이름을 사용하는 것을 권장합니다. 다음 명령은 Kibana의 관리자 사용자를 생성합니다. 사용자 이름과 비밀번호가 생성되어 “htpasswd.users” 파일에 저장됩니다. Nginx가 이 사용자 이름과 비밀번호를 사용하도록 구성해야 합니다:
|
1 |
echo "kibana_admin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users |
프롬프트에서 비밀번호를 입력하고 확인합니다. 이 비밀번호는 Kibana 인터페이스에 액세스하는 데 중요합니다. 그 후, Nginx 서버 블록 파일을 생성해야 합니다. 데모용으로 example.com을 사용하겠습니다. 다른 설명적인 이름이어도 상관없습니다. 서버에 FQDN 및 DNS 레코드가 구성되어 있는 경우, 파일 이름은 FQDN을 따를 수도 있습니다:
|
1 |
sudo vim /etc/nginx/sites-available/example.com |
기존 콘텐츠가 있는 경우 콘텐츠를 제거하고 다음 코드 줄로 바꾸십시오:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
server { listen 80; server_name example.com; auth_basic "Restricted Access"; auth_basic_user_file /etc/nginx/htpasswd.users; location / { proxy_pass http://localhost:5601; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } } |
파일을 저장하고 닫습니다. “sites-enabled” 디렉터리 아래에 새 구성의 심볼릭 링크를 생성합니다. 동일한 파일 이름으로 기존 링크가 이미 존재하는 경우 이 단계는 필요하지 않을 수 있습니다:
|
1 |
sudo ln -s /etc/nginx/sites-available/example.com /etc/nginx/sites-enabled/example.com |
다음 명령은 Nginx가 구문 오류가 있는지 확인하도록 요청합니다:
|
1 |
sudo nginx -t |
구문 문제가 있는 경우 파일의 내용이 올바르게 배치되었는지 확인하십시오. 다음으로 Nginx 서비스를 재시작합니다:
|
1 |
sudo systemctl restart nginx |
Tell UFW에 Nginx 연결을 허용하도록 설정합니다:
|
1 |
sudo ufw allow 'Nginx Full' |
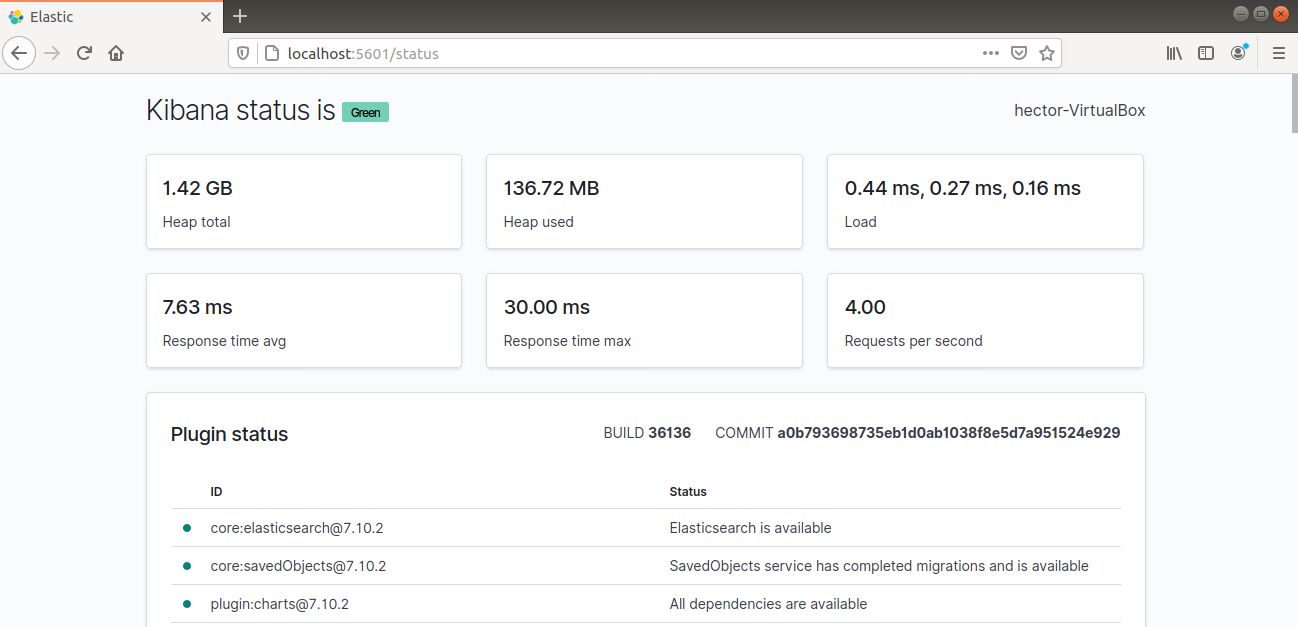
이제 Elastic Stack 서버의 FQDN 또는 공인 IP 주소를 통해 Kibana에 액세스할 수 있어야 합니다. Kibana 서버의 상태 페이지를 확인하십시오:
|
1 |
http://<server_ip>:5601/status |
Logstash 설치 및 구성
Beats는 Elasticsearch’s 데이터베이스로 데이터를 직접 보낼 수 있지만, 데이터를 처리하기 위해 Logstash를 사용하는 것이 권장됩니다. Logstash는 데이터를 수집하고 다른 데이터베이스로 내보내기 전에 공통 형식으로 변환할 수 있습니다. 다음 APT 명령을 실행하여 Logstash를 설치합니다:
|
1 |
sudo apt install logstash |
설치가 완료되면 Logstash를 구성할 차례입니다. Logstash의 구성 파일은 JSON 형식입니다. “/etc/logstash/conf.d” 디렉터리에서 모두 찾을 수 있습니다. Logstash를 한쪽 끝에서 데이터를 받아 처리하고 대상지로 내보내는 파이프라인으로 생각하면 도움이 됩니다. Logstash 파이프라인에는 두 가지 필수 요소인 input 및 output과 하나의 선택적 요소인 filter가 필요합니다. input 플러그인은 데이터를 가져오고, filter 플러그인은 데이터를 처리하며, output 플러그인은 대상지에 데이터를 기록합니다. 다음 명령은 Filebeat 입력을 위해 Logstash를 설정하는 구성 파일을 생성합니다:
|
1 |
sudo vim /etc/logstash/conf.d/02-beats-input.conf |
다음 input 구성을 입력합니다. 이는 TCP의 5044 포트에서 수신 대기할 beats 입력을 정의합니다:
|
1 2 3 4 5 |
input { beats { port => 5044 } } |
다음 단계는 “10-syslog-filter.conf”라는 구성 파일을 만드는 것입니다. 이 파일은 syslogs (시스템 로그)에 대한 필터를 설정하는 데 사용됩니다:
|
1 |
sudo vim /etc/logstash/conf.d/10-syslog-filter.conf |
다음 syslog 구성 코드를 입력합니다. 이 코드는 Elastic guide에서 직접 제공됩니다. 이 코드는 Logstash에 대한 input 구성을 설명합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
입력{ beats{ 포트 => 5044 호스트 => "0.0.0.0" } } 필터 { if [파일세트][모듈] == "시스템" { if [파일세트][이름] == "인증" { grok { 일치 => { "메시지" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] } pattern_definitions => { "GREEDYMULTILINE"=> "(.|\n)*" } remove_field => "message" } date { match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } geoip { source => "[system][auth][ssh][ip]" target => "[system][auth][ssh][geoip]" } } else if [fileset][name] == "syslog" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] } pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" } remove_field => "message" } date { match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } } } } |
다음 설정 파일은 출력을 처리합니다. “30-elasticsearch-output.conf”라는 새 파일을 엽니다:
|
1 |
sudo vim /etc/logstash/conf.d/30-elasticsearch-output.conf |
다음 코드를 입력합니다. 이 코드는 Logstash에 대한 출력 설정을 설명합니다:
|
1 2 3 4 5 6 7 |
output { elasticsearch { hosts => ["localhost:9200"] manage_template => false index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" } } |
Logstash 설정을 테스트합니다. 그런 다음, 다음 명령을 실행합니다:
|
1 |
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t |
오류가 없으면 Logstash가 다음과 같은 성공 메시지를 출력합니다. 성공하지 못했다면 모든 설정 파일에 올바른 코드가 있는지 확인하세요. 마지막으로 Logstash 서비스를 시작하고 활성화합니다:
|
1 2 |
sudo systemctl start logstash sudo systemctl enable logstash |
이제 Logstash가 성공적으로 실행되고 완전히 설정되었으므로 Filebeat를 설치해 보겠습니다.
Filebeat 설치 및 설정
Elastic Stack은 다양한 소스에서 데이터를 수집하여 Logstash/Elasticsearch로 전송하기 위해 “Beats”라고 하는 데이터 수집기(data shipper)를 사용합니다. 다음은 Elastic에서 제공하는 Beats 목록입니다:
- Filebeat: 로그 파일을 수집/전송합니다.
- Metricbeat: 시스템 및 서비스에서 메트릭을 수집/전송합니다.
- Packetbeat: 네트워크 데이터를 수집/분석합니다.
- Winlogbeat: Windows 이벤트 로그를 수집합니다.
- Auditbeat: Linux 감사 프레임워크 데이터를 수집하고 파일 무결성을 모니터링합니다.
- Heartbeat: 서비스의 가용성을 모니터링합니다.
이 튜토리얼에서는 로컬 로그를 Elastic Stack으로 전송하기 위해 Filebeat가 필요합니다. 먼저 Filebeat를 설치합니다:
|
1 |
sudo apt install filebeat |
이제 Filebeat를 구성할 수 있습니다. 먼저 Logstash에 연결해야 합니다. Filebeat와 함께 제공되는 예제 구성을 사용하겠습니다. 텍스트 편집기에서 구성 파일을 엽니다. 파일이 YAML 형식이므로 올바른 들여쓰기가 중요합니다:
|
1 |
sudo vim /etc/filebeat/filebeat.yml |
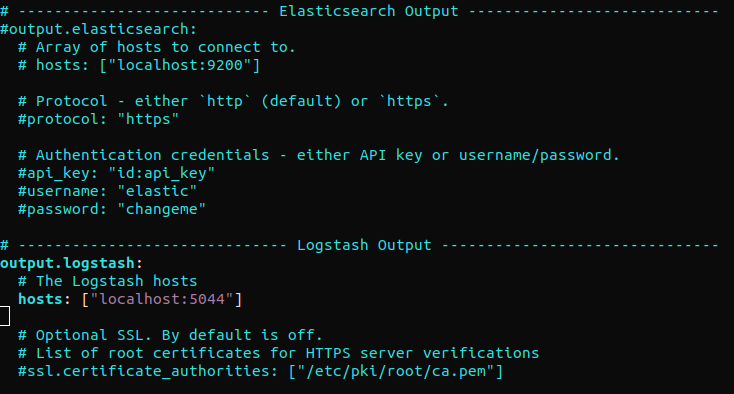
“output.elasticsearch” 섹션을 찾아 다음 줄을 주석 처리합니다. 이렇게 하면 Filebeat가 추가 처리를 위해 이벤트를 Elasticsearch/Logstash로 직접 보내도록 구성됩니다. 다음으로 “output.logstash” 섹션으로 이동합니다. 그런 다음 다음 줄의 주석을 해제합니다:
|
1 2 3 4 5 6 7 |
#output.elasticsearch: # 연결할 호스트 배열. # hosts: ["localhost:9200"] output.logstash: # Logstash 호스트 hosts: ["localhost:5044"] |
Filebeat는 모듈을 지원하여 기능을 확장할 수 있습니다. 이 튜토리얼에서는 시스템 모듈을 사용하여 일반적인 Linux 배포판의 시스템 로깅 서비스에서 생성된 로그를 수집하고 분석합니다. Filebeat 시스템 모듈을 활성화합니다:
|
1 |
sudo filebeat modules enable system |
다음 Filebeat 명령은 활성화 및 비활성화된 모든 모듈을 나열합니다:
|
1 |
sudo filebeat modules list |
기본적으로 Filebeat는 syslog 및 인증 로그의 기본 경로를 따르도록 설정되어 있습니다. 모듈의 매개변수는 “/etc/filebeat/modules.d/system.yml” 구성 파일에서 확인할 수 있습니다.
다음 단계는 인덱스 템플릿을 Elasticsearch에 로드하는 것입니다. Elasticsearch 인덱스는 유사한 특성을 공유하는 문서 모음을 나타냅니다. 각 인덱스에는 이름이 있습니다. 인덱스 내에서 다양한 작업을 수행할 때 이름이 필요합니다. 인덱스 템플릿은 새 인덱스가 생성될 때마다 자동으로 적용됩니다. 다음으로 템플릿을 로드합니다:
|
1 |
sudo filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]' |
Filebeat에는 기본적으로 Kibana용 샘플 대시보드가 포함되어 있습니다. 이는 Kibana에서 Filebeat 데이터를 시각화하는 데 도움이 됩니다. 그러나 대시보드를 사용하기 전에 인덱스 패턴을 생성하고 대시보드를 Kibana에 로드해야 합니다. 대시보드가 로드되는 동안 Filebeat는 버전 정보를 위해 Elasticsearch에 접속합니다. 대시보드를 로드하려면 Logstash가 활성화되어 있는 동안 Logstash 출력을 비활성화하고 Elasticsearch 출력을 활성화해야 합니다. 다음 명령이 이 작업을 수행합니다:
|
1 |
sudo filebeat setup -e -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601 |
마지막으로 Filebeat를 실행할 수 있습니다:
|
1 2 |
sudo systemctl start filebeat sudo systemctl enable filebeat |
이제 Elastic Stack 구성을 테스트할 차례입니다. 올바르게 구성되었다면 출력은 다음과 같이 표시됩니다:
|
1 |
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty' |
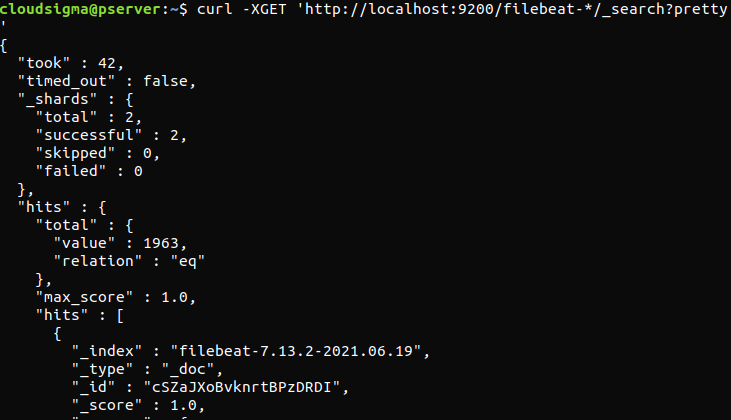
출력에 총 조회수(total hits)가 0으로 보고되면 Elasticsearch가 검색한 인덱스 아래에 어떠한 로그도 로드하지 않고 있는 것입니다. 이는 구성에 오류가 있음을 나타냅니다. 출력이 예상대로 나왔다면 Elastic Stack이 성공적으로 구성된 것입니다.
Kibana 대시보드 개요
이제 이미 설치한 Kibana 웹 인터페이스를 탐색할 차례입니다. 먼저 Kibana 대시보드를 엽니다. Elastic Stack 서버의 FQDN 또는 공인 IP 주소에 위치해야 합니다:
|
1 |
http://<server_ip>:5601 |
이전에 생성한 로그인 자격 증명을 입력합니다. 로그인하면 대시보드가 다음과 같이 표시됩니다:
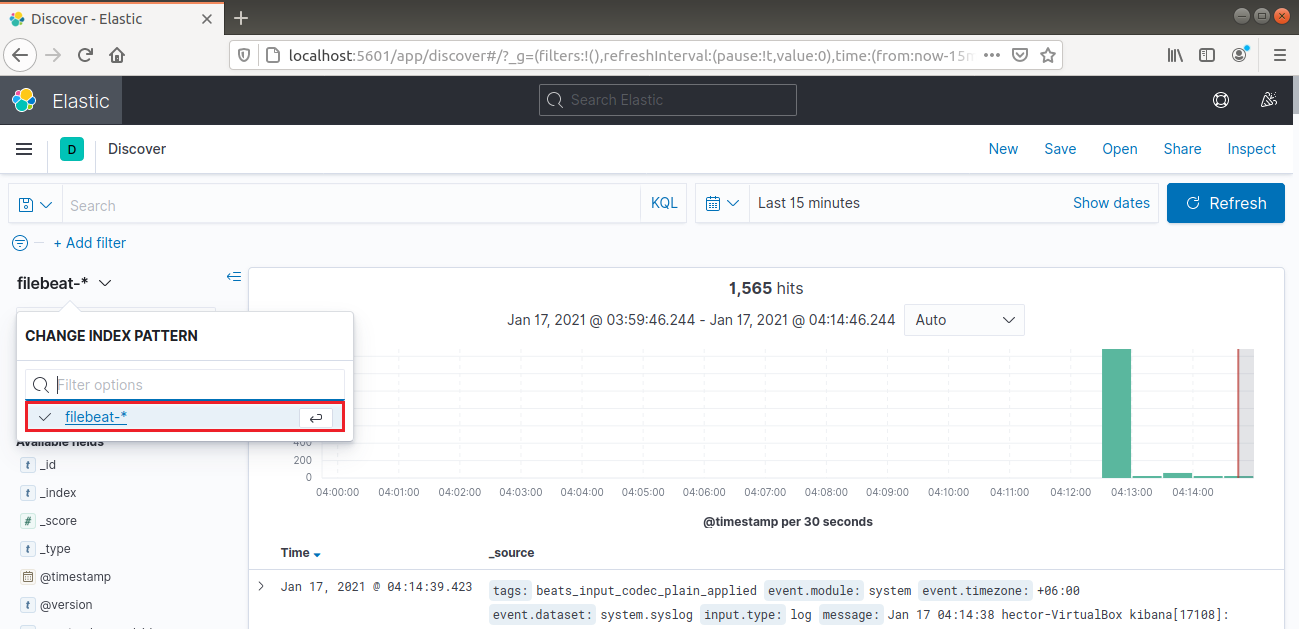
왼쪽 탐색 바에서 “Discover”를 선택합니다. 그런 다음 “filebeat-*” 패턴을 선택합니다. 지난 15분 동안 수집된 모든 로그가 표시됩니다. 로그를 검색 및 탐색하고 대시보드를 사용자 정의할 수 있습니다:
왼쪽 탐색 바에서 Dashboard >> Filebeat System으로 이동합니다. 여기에서 Filebeat 시스템 모듈의 모든 샘플 대시보드를 사용할 수 있습니다.
다음 예시에서는 syslog 메시지를 기반으로 한 다양한 통계를 자세히 보여줍니다:
어떤 사용자가 sudo로 명령을 실행했는지도 보고할 수 있습니다:
마지막으로, Kibana는 그래프 작성 및 필터링과 같은 다른 많은 기능을 탐색할 수 있는 기회를 제공하므로 자유롭게 직접 탐색해 보세요.
마치며
Elastic Stack은 시스템 로그를 분석하기 위한 강력한 솔루션입니다. 어떤 로그나 인덱싱된 데이터든 Beats를 사용하여 Logstash로 보낼 수 있지만, Logstash 필터를 통해 파싱되고 구조화될 때 더욱 유용해진다는 점을 기억하세요.
즐거운 컴퓨팅 되세요!
댓글
아직 댓글이 없습니다. 첫 번째로 작성해 보세요.