

웹 스크래핑, 웹 크롤링, 웹 하베스팅 또는 웹 데이터 추출은 인터넷상의 웹 페이지에서 데이터를 마이닝하는 행위를 가리키는 동의어입니다. 웹 스크래퍼 또는 웹 크롤러는 프로그래밍 방식으로 웹 페이지를 탐색하여 필요한 데이터를 추출하는 도구입니다. 일반적으로 대량의 텍스트 세트인 이 데이터는 분석 목적, 제품 이해 또는 특정 웹 페이지에 대한 호기심을 충족하기 위해 사용될 수 있습니다.
웹 크롤링을 어떻게 시작해야 할지 고민이시라면, 간단한 데이터 세트를 통해 웹 스크래핑의 기초를 보여드리겠습니다. 프로그래밍 전문 지식 수준에 관계없이 이 튜토리얼을 따라 하실 수 있습니다. 실습 예제에서는 저희의 CloudSigma 블로그를 사용할 것입니다. 저희 블로그 페이지에 있는 튜토리얼에 대한 정보를 가져와 보겠습니다. 이 튜토리얼의 결론을 읽을 때쯤이면, 여러분은 Python 3으로 제작되어 저희 블로그 섹션의 여러 페이지를 크롤링한 다음 화면에 데이터를 표시하는 작동 가능한 웹 스크래퍼를 갖게 될 것입니다.
이 기본적인 웹 스크래퍼를 만들면서 얻은 지식을 활용하여 이를 확장하고 자신만의 웹 스크래퍼를 만들 수 있습니다. 재미있을 것입니다. 시작해 볼까요!
사전 요구 사항
이 튜토리얼은 실습 위주로 진행되므로, 잘 따라 하려면 Python 3용 로컬 개발 환경이 준비되어 있어야 합니다. 먼저, 다음 방법에 대한 튜토리얼을 참조할 수 있습니다. Ubuntu에 Python 3 설치 및 로컬 프로그래밍 환경 설정하기.
Scrapy
웹 스크래핑은 두 가지 단계로 구성됩니다. 첫 번째 단계는 웹 페이지를 찾아서 다운로드하는 것이고, 두 번째 단계는 해당 웹 페이지를 크롤링하여 정보를 추출하는 것입니다.
많은 프로그래밍 언어에서 처음부터 웹 스크래퍼를 구축하는 데 사용할 수 있는 여러 방법과 라이브러리가 있습니다. 하지만 이는 향후 웹 스크래퍼가 복잡해지거나 서로 다른 설정과 패턴을 가진 여러 페이지를 동시에 크롤링해야 할 때 문제를 일으킬 수 있습니다. 스크래핑한 데이터를 CSV, XML 또는 JSON과 같은 다양한 형식으로 변환하는 방법을 알아내는 것은 꽤 무거운 작업이 될 수 있습니다.
처음부터 자신만의 웹 스크래퍼를 구축하는 도전을 즐기는 사람도 있겠지만, 바퀴를 다시 발명하지 않고 이러한 모든 문제를 처리해 주는 기존 라이브러리를 기반으로 구축하는 것이 더 좋습니다. 저희는 이번 튜토리얼에서 웹 스크래퍼를 구현하기 위해 Scrapy라는 Python 라이브러리를 Python 3과 함께 사용할 것입니다. Scrapy는 오픈 소스 도구이자 가장 인기 있고 강력한 Python 웹 스크래핑 라이브러리 중 하나입니다. Scrapy는 모든 스크래퍼가 갖추어야 할 몇 가지 공통 기능을 처리하도록 구축되었습니다. 이렇게 하면 웹 크롤러를 구현하고 싶을 때마다 바퀴를 다시 발명할 필요가 없습니다. Scrapy를 사용하면 스크래퍼를 구축하는 과정이 쉽고 재미있어집니다.
Scrapy는 PyPi(흔히 pip로 알려진 Python 패키지 인덱스)에서 사용할 수 있습니다. PyPi는 대부분의 Python 패키지를 호스팅하는 커뮤니티 소유 저장소입니다. 로컬 개발 환경에 Python 3를 설치하고 설정하면 pip도 함께 설치되며, 이를 사용하여 Python 패키지를 설치할 수 있습니다.
1단계: 간단한 웹 스크래퍼 구축 방법
먼저, Scrapy를 설치하려면 다음 명령을 실행합니다.
|
1 |
pip install scrapy |
선택 사항으로, 문서 페이지의 Scrapy 공식 설치 지침을 따를 수도 있습니다. Scrapy를 성공적으로 설치했다면 원하는 이름을 사용하여 프로젝트 폴더를 생성합니다.
|
1 |
mkdir cloudsigma-crawler |
폴더로 이동하여 코드의 메인 파일을 생성합니다. 이 파일에 이 튜토리얼의 모든 코드가 담기게 됩니다.
|
1 |
touch main.py |
원하는 경우 위의 명령 대신 텍스트 에디터나 IDE를 사용하여 파일을 생성할 수도 있습니다.
다음으로, 파일을 열고 Scrapy를 사용하는 기본 스크래퍼를 만드는 것부터 시작해 보겠습니다. Scrapy의 기본 스파이더 클래스인 scrapy.Spider를 상속받는 Python 클래스를 생성합니다. 이 클래스는 아래에 정의된 두 가지 필수 속성을 갖게 됩니다.
- name — 스파이더를 식별하기 위한 문자열 이름 (원하는 이름을 입력할 수 있습니다).
- start_urls — 크롤링할 URL 목록이 포함된 배열입니다. 하나의 URL로 시작해 보겠습니다.
열린 파일에 다음 코드 스니펫을 추가하여 기본 스파이더를 생성합니다:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
각 코드 줄에 대한 설명은 다음과 같습니다:
첫 번째 줄은 Scrapy를 임포트하여 패키지가 제공하는 다양한 클래스를 사용할 수 있도록 합니다.
다음 줄에서는 Scrapy가 제공하는 Spider 클래스를 확장하여 CloudSigmaCrawler라는 서브클래스를 생성합니다. 클래스(Spider)를 확장함으로써, 이제 코드에서 사용할 수 있는 클래스의 속성에 액세스할 수 있게 됩니다. 이 경우, Spider 클래스에는 URL을 추적하고 웹 페이지에서 데이터를 추출하는 방법을 정의하는 메서드와 동작이 있습니다. 하지만 어떤 URL을 추적해야 하는지 또는 어떤 데이터를 추출해야 하는지는 알지 못합니다. 이를 확장함으로써 메서드에 필요한 정보를 제공할 수 있습니다. 서브클래싱 및 확장에 대해 자세히 알아보려면 다음을 계속 읽어보세요. 객체 지향 프로그래밍 원칙.
CloudSigmaCrawler에서 필요한 속성을 정의합니다. 먼저 스파이더 이름을 cloudsigma_crawler로 지정합니다. 그런 다음 시작할 단일 URL을 제공합니다: https://blog.cloudsigma.com/blog/. 이 URL을 열면 여러 튜토리얼 중 일부가 포함된 CloudSigma 블로그 페이지 1로 이동합니다.
스크레이퍼를 테스트할 시간입니다. 몇 가지 옵션이 있습니다. 예를 들어, PyCharm community edition (제작사: JetBrains)과 같은 IDE를 사용 중이라면, 스크립트를 실행하기 위해 클릭만 하면 되는 버튼이 제공될 것입니다. 또 다른 옵션은 명령줄에서 Python 파일을 실행하는 일반적인 방법인 python path/to/file.py 또는 py path/to/file.py를 따르는 것입니다. 또 다른 옵션은 Scrapy의 명령줄 인터페이스입니다. Scrapy에는 스크레이퍼를 시작하는 데 도움이 되는 자체 명령줄 인터페이스가 함께 제공됩니다. 스크레이퍼를 시작하려면 다음 명령을 입력하세요:
|
1 |
scrapy runspider main.py |
설치한 Scrapy의 라이브러리 버전에 따라 다음과 같은 출력이 표시될 것입니다:
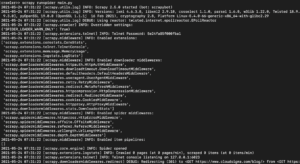
보시다시피 출력이 상당히 길기 때문에 일부 부분만 선택했습니다. 명령을 실행했을 때 발생한 상황은 다음과 같습니다:
- 스크레이퍼가 초기화되었습니다. 따라서 URL에서 데이터를 추적하고 읽는 데 필요한 추가 구성 요소와 확장 프로그램을 로드했습니다.
- start_urls 목록에 제공된 URL을 사용하여 페이지에서 HTML을 가져왔습니다. 이는 브라우저가 웹 페이지를 열 때 따르는 프로세스와 유사합니다.
- HTML을 가져온 후, 아직 정의하지 않은 parse 메서드로 전달됩니다. 현재로서는 아무 작업도 수행하지 않으므로 스파이더는 아무런 처리 없이 종료됩니다. 다음 단계에서 parse 메서드의 동작을 정의하겠습니다.
2단계: 페이지에서 데이터를 추출하는 방법
1단계에서는 HTML 페이지를 가져오기만 하고 그 이후에는 아무것도 하지 않는 기본 스크레이퍼만 구현했습니다. 이 섹션에서는 데이터를 추출하기 위한 지침을 제공합니다. 데이터를 추출하고자 하는 CloudSigma 블로그 페이지에서 다음과 같은 몇 가지 사항을 확인할 수 있습니다:
- 모든 페이지에 존재하는 헤더.
- 탐색 메뉴 및 검색 필터 상자.
- 그리드 형식의 실제 튜토리얼 목록.
스크랩하려는 HTML 페이지의 소스 코드를 보면 페이지 구조에 대한 대략적인 아이디어를 얻을 수 있습니다. 이는 스크레이퍼를 작성하는 데 도움이 됩니다. 페이지를 마우스 오른쪽 버튼으로 클릭하고 '소스 보기'를 선택하거나 Ctrl + U를 눌러 소스 코드를 볼 수 있습니다. 다음은 소스 코드의 일부입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="고유링크: "Ubuntu 18.04에서 Let’s Encrypt로 Apache 보안 강화하기"">보안 강화: Ubuntu 18.04에서 Let’s Encrypt를 통한 Apache</a> </h2> </header> <div class="entry-content excerpt"> <p>웹사이트 및 데이터 보안은 가볍게 여길 수 없는 주제입니다. 금융 기록과 고객의 개인 정보를 포함한 매우 민감한 정보는 항상 사용자의 컴퓨터와 웹사이트 사이에서 전송됩니다. 이 사실을 고려하면, 보안되지 않은 웹사이트가 비즈니스에 심각한 피해를 줄 수 있는 보안 침해로 이어질 수 있는 이유를 쉽게 알 수 있습니다. 여기에는 … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">더 읽어보기</a></div> </div> </div> ... </article> </div> </body> |
보시다시피 각 블로그 튜토리얼은 <article>이라는 HTML 태그로 둘러싸여 있습니다. 페이지를 스크래핑하는 작업은 두 단계로 진행됩니다. 첫 번째 단계는 우리가 원하는 데이터가 포함된 페이지 부분을 찾아 각 블로그 튜토리얼을 가져오는 것입니다. 다음 단계는 HTML 태그로 식별된 각 튜토리얼에서 원하는 데이터를 추출하는 것입니다.
Scrapy는 제공된 선택자(selector)를 기반으로 가져올 데이터를 식별합니다. 선택자를 사용하여 페이지에서 하나 이상의 요소를 찾고 해당 요소 내의 데이터를 가져올 수 있습니다. Scrapy는 XPath 및 CSS 선택자를 지원합니다.
앞서 살펴본 소스 코드에서는 CSS 선택자가 더 쉬워 보입니다. 따라서 페이지의 모든 튜토리얼을 찾는 데 도움이 되는 이 옵션을 선택하겠습니다. HTML 소스 코드에서 각 튜토리얼은 post라는 CSS 클래스 내에 지정되어 있습니다. CSS 클래스 이름은 일반적으로 .class_name(점 클래스_이름)으로 식별됩니다. 따라서 CSS 선택자로 .post를 사용하겠습니다. main.py 스크래퍼 소스 코드 내에서 response 객체에 .post 클래스를 전달하면 파일이 다음과 같이 표시됩니다.
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
이 코드 스니펫은 지정된 start_urls가 있는 페이지의 모든 튜토리얼을 가져와서 튜토리얼을 루프하며 데이터를 추출합니다. 다음 단계에서는 이 데이터를 추출하여 표시하고자 할 것입니다. 만약 CloudSigma 블로그의 소스 코드를 다시 확인해 보면, 각 튜토리얼의 제목이 <h2> 태그 내의 <a> 태그 안에 저장되어 있는 것을 볼 수 있습니다. 예를 들면 다음과 같습니다:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
우리가 루프를 돌고 있는 각 튜토리얼 객체에는 자식 요소를 찾아 추출하기 위해 선택자(selector)를 전달할 수 있는 CSS 메서드가 포함되어 있습니다. 이 예제에서는 <a> 태그 안에 감싸여 있는 제목을 추출하고자 합니다. 이 태그는 .entry-wrap 클래스 내부의 .entry-header 클래스 내부의 <h2> 태그 내부에 있습니다. 이러한 CSS 선택자를 객체 메서드에 전달하여 제목을 추출할 수 있으며, 코드를 다음과 같이 수정합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
extract_first() 뒤의 쉼표는 오타가 아니며, 이 섹션 아래에 코드를 더 추가할 예정이기 때문입니다.
위의 소스 코드에서 주의 깊게 살펴볼 점은 다음과 같습니다:
- 선택자 뒤에 붙은 ::text – 이것은 CSS 가상 선택자로, 태그 자체가 아닌 태그 내부의 텍스트를 가져오도록 코드에 지시합니다.
- 객체 내의 extract_first() 메서드 호출 – 선택자와 일치하는 첫 번째 요소만 선택하도록 코드에 지시합니다. 따라서 요소 목록이 아닌 문자열을 얻게 됩니다.
다음으로, 파일을 저장하고 터미널에 다음 명령어를 입력하여 코드를 실행합니다:
|
1 |
scrapy runspider main.py |
출력에서 튜토리얼의 제목을 볼 수 있습니다:
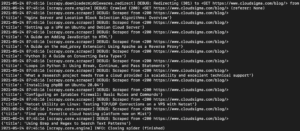
튜토리얼의 URL, 대표 이미지, 캡션 등 튜토리얼에 대한 다른 세부 정보를 가져오기 위해 더 많은 선택자를 추가하여 이를 계속 확장할 수 있습니다.
단일 튜토리얼의 HTML 코드를 다시 살펴보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="영구 링크: "Securing Apache with Let’s Encrypt on Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="고유링크: "Ubuntu 18.04에서 Let’s Encrypt로 Apache 보안 설정하기"">Ubuntu 18.04에서 Let’s Encrypt로 Apache 보안 설정하기</a> </h2> </header> <div class="entry-content excerpt"> <p>웹사이트 및 데이터 보안은 가볍게 여길 수 없는 주제입니다. 다음과 같은 매우 민감한 정보는 금융 기록 및 고객의 개인 정보를 포함하여 항상 사용자의 컴퓨터와 웹사이트 사이에서 전송됩니다. 이 사실을 고려할 때, 보안이 설정되지 않은 웹사이트가 비즈니스에 심각한 피해를 줄 수 있는 침해 사고로 이어질 수 있는 이유를 쉽게 알 수 있습니다. 여기에는 여러 … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">더 읽어보기</a></div> </div> </div> </article> </div> </body> |
우리는 강조 표시된 부분, 즉 튜토리얼의 URL, 대표 이미지 및 캡션을 추출하려고 합니다.
- 위의 코드 스니펫에서 블로그 이미지는 블로그 튜토리얼 시작 부분의 div 태그 내 <a> 태그 내 img 태그의 data-lazy-src 속성 안에 저장됩니다. 튜토리얼 제목에서 했던 것처럼 CSS 선택기를 사용하여 이 값을 가져올 수 있습니다.
- <div> 요소 안에 <a> 태그가 있으므로 튜토리얼의 URL을 가져오는 것은 간단합니다.
- 캡션은 <div> 태그 안에 있는 <p> 태그 내에 둘러싸여 있습니다.
원하는 것을 얻기 위해 CSS 클래스를 사용할 것입니다. 코드를 다음과 같이 수정해 보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
변경 사항을 저장하고 다음 명령어로 코드를 실행합니다:
|
1 |
scrapy runspider main.py |
출력 결과에서 우리가 추가한 URL, 이미지, 캡션과 같은 더 많은 데이터를 볼 수 있습니다:

단일 페이지 크롤링은 이것으로 끝입니다. 다음으로, 링크를 따라가는 스크래퍼를 만드는 방법을 알아보겠습니다.
3단계: 여러 페이지를 크롤링하는 방법
지금까지 우리는 단일 페이지에서 데이터를 가져올 수 있는 스크래퍼를 만들었습니다. 하지만 우리는 그 이상을 원합니다. 링크를 따라가며 웹사이트의 여러 페이지에서 프로그래밍 방식으로 데이터를 추출할 수 있는 스파이더가 필요합니다.
CloudSigma 블로그 페이지 하단으로 이동하면 페이지네이션 링크와 다음 페이지를 가리키는 오른쪽 방향의 작은 화살표를 볼 수 있습니다. 다음은 HTML 코드 스니펫입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">45페이지 중 1페이지</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="마지막 페이지">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
이 스니펫은 .x-pagination CSS 클래스가 있는 <div> 태그 아래, <li> 태그 내의 여러 페이지 탐색 링크를 보여줍니다. 우리가 주목할 부분은 다음 페이지를 가리키는 링크입니다. 이는 <ul> 태그 내 마지막 <li>의 <a> 태그에 있습니다.
위의 스니펫에서 볼 수 있듯이 다음 페이지를 가리키는 링크는 <a> 태그 내에 .prev-next 클래스를 가지고 있습니다. 하지만 다음 페이지로 이동하면 이전 페이지와 다음 페이지로 가는 링크 모두 이 CSS 클래스를 가지고 있음을 알 수 있습니다. 페이지 2에 대한 다음 스니펫을 참고하세요:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">45페이지 중 2페이지</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="마지막 페이지">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Scrapy의 extract_first() 메서드를 사용하면 첫 번째 페이지에서 작동합니다. 다음 페이지에 도달하면 위의 코드 조각에서 첫 번째 페이지를 가리키는 .prev-next 클래스가 있는 첫 번째 링크를 선택하게 됩니다. 이로 인해 무한 루프가 발생합니다. 따라서 Scrapy의 extract() 메서드를 사용하겠습니다. 이 메서드는 사용 사례와 일치하는 모든 요소를 추출하여 배열에 넣습니다. 이 배열에서 다음 페이지를 가리키는 실제 링크가 포함된 마지막 요소를 선택할 수 있습니다. 다음과 같이 코드를 수정하세요:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
next_page 선택을 위한 코드를 살펴보겠습니다.
먼저 다음 및 이전 페이지 링크에 대한 선택자를 정의합니다. 그런 다음 extract() 메서드를 사용하여 URL을 추출하고 배열에 넣습니다. next_page 변수는 다음과 같이 두 개의 요소를 가진 배열이 됩니다.
|
1 |
next_page = [prev_page_url, next_page_url] |
다음 페이지로 이동하므로 배열의 마지막 요소를 선택합니다. Next_page[-1]은 배열의 마지막 요소를 선택합니다.
if 블록은 next_page 변수에 값이 있는지 확인한 다음 scrapy.Request() 메서드를 호출합니다. 코드에서는 이 메서드가 제공된 URL로 페이지를 크롤링하고 이를 다시 parse() 메서드로 전달하도록 지시하여, 데이터를 추출하기 위해 구문 분석하고 다음 페이지에 대해 이 프로세스를 반복할 수 있도록 합니다. 이 프로세스는 다음 페이지로 가는 링크를 찾지 못하거나 블록이 실패할 때까지 반복된 후 중지됩니다.
코드를 저장하고 실행해 보세요. 스크랩할 페이지를 더 찾으면서 페이지를 계속 반복하여 탐색하는 것을 확인할 수 있습니다. 이것이 웹사이트의 링크를 따라가는 스크레이퍼를 정의하는 방법입니다. 우리의 예제는 매우 간단합니다. 단지 페이지로 이동하여 다음 페이지로 가는 링크를 찾고 이 과정을 반복할 뿐입니다. 다른 사용 사례에서는 외부 소스 등을 가리키는 태그나 링크를 따라가고 싶을 수도 있습니다. 다음은 Python 3 기본 웹 스크레이퍼의 완성된 소스 코드입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
결론
이번 튜토리얼에서는 CloudSigma 블로그 디렉토리를 크롤링하고 블로그 튜토리얼에 대한 몇 가지 정보를 단 27줄 정도의 코드로 표시할 수 있는 기본적인 웹 스크래퍼를 구축했습니다.
물론 Scrapy 파이썬 라이브러리를 기반으로 구축했기 때문에 이것이 가능합니다. 이는 더 많은 태그, 웹사이트 검색 결과 등을 추적하는 더 복잡한 스크래퍼를 구축하는 데 도움이 되는 기초일 뿐입니다. 자세한 내용은 Scrapy 공식 문서를 참조하여 Scrapy 작업에 대해 자세히 알아볼 수 있습니다.
즐거운 컴퓨팅 되세요!
댓글
아직 댓글이 없습니다. 첫 번째로 작성해 보세요.