

명령어 sed는 stream editor의 약자입니다. 이는 Linux/UNIX 시스템에서 널리 대중적인 도구입니다. Sed는 그 자체로 텍스트 에디터는 아닙니다. 하지만 주어진 텍스트를 조작하기 위해 다양한 수정을 수행할 수 있습니다. 텍스트 입력은 스트림으로 전송됩니다. Sed는 그런 다음 스트림에 지시된 작업을 수행합니다. 이 가이드는 gives an overview of the sed 명령어에 대한 개요와 Linux에서 텍스트를 성공적으로 조작하기 위해 이를 작동하는 방법을 제공합니다.
Linux에서의 Sed
The input stream of sed 의 입력 스트림은 텍스트 파일이나 STDIN(표준 입력)에서 올 수 있습니다. 다른 명령어의 출력으로 작업하거나 텍스트 파일로 직접 작업할 수 있습니다. sed 도구는 모든 Linux 배포판에 기본으로 설치되어 제공됩니다.
Sed 사용법 개요
The sed 명령어는 다음과 같은 구조를 따릅니다:
|
1 |
$ sed <options> <commands> <file> |
데모 목적으로, 다음의 텍스트 버전을 가져왔습니다: GPL license version 3:
|
1 |
$ wget https://www.gnu.org/licenses/gpl-3.0.txt |

다음 sed 명령어는 텍스트 파일의 내용을 출력합니다:
|
1 |
$ sed '' gpl-3.0.txt |
여기서 sed 는 작은따옴표 안에 설명된 작업을 수행하고 출력을 인쇄합니다. 정의된 옵션이 없으므로, sed 는 단순히 빈 작업을 수행하고 파일의 전체 내용을 출력합니다.
Sed 는 또한 다른 명령어의 출력을 입력 스트림으로 받아들입니다. 다음 예제에서는 GPL v3 텍스트 파일의 내용을 sed 로 파이프하여 빈 작업을 수행합니다:
|
1 |
$ cat gpl-3.0.txt | sed '' |
줄(라인)을 출력하는 방법
옵션을 지정하지 않으면 sed 는 파일의 모든 내용을 직접 출력합니다. 대신, 결과를 표준 출력(STDOUT)으로 직접 출력하도록 인쇄 명령을 명시적으로 보낼 수 있습니다.
출력을 인쇄하려면 문자 p:
|
1 |
$ sed 'p' gpl-3.0.txt |
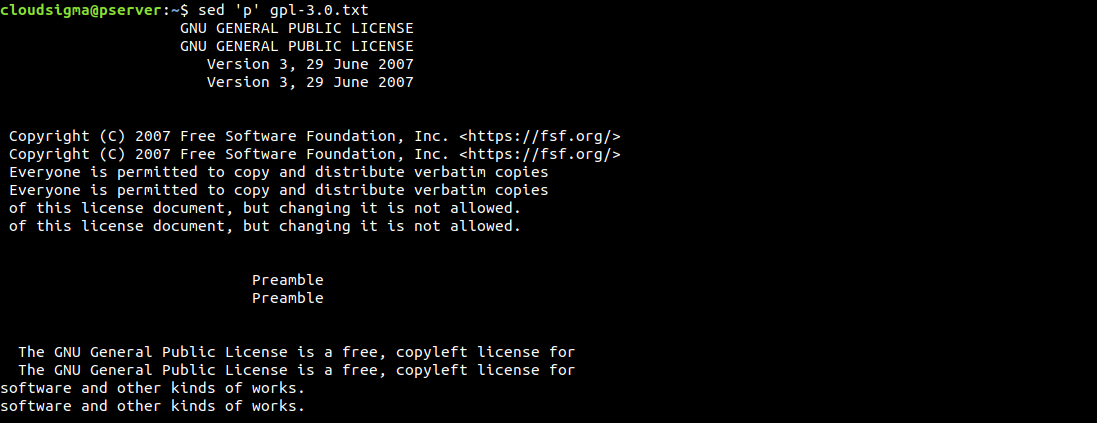
기본적으로 sed 는 출력을 화면에 인쇄합니다. 인쇄 명령을 구체적으로 사용했기 때문에, sed 는 각 줄을 두 번 인쇄합니다. Sed 는 한 줄씩 작동합니다. 한 줄을 읽고, 특정 작업을 수행하고, 이를 출력한 다음, 다음 줄로 이동합니다.
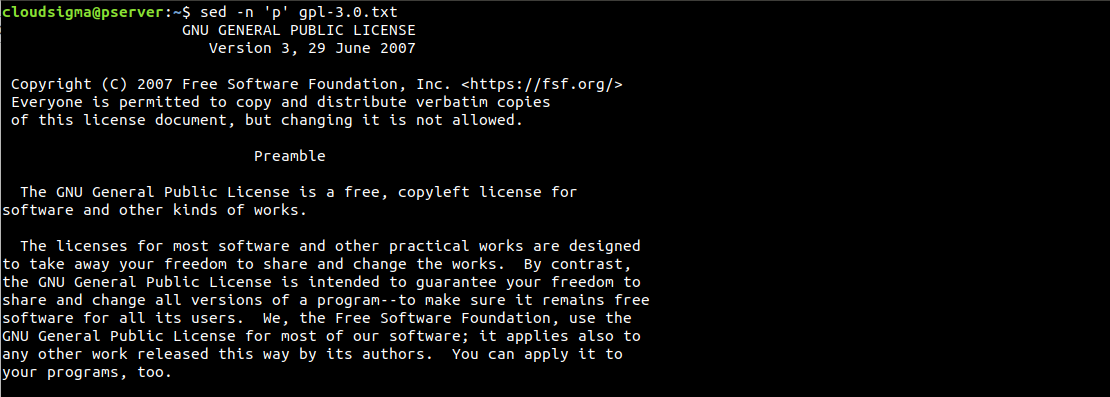
보시다시피 모든 줄이 두 번 인쇄됩니다. 이와 같이 결과가 혼란스러운 경우, -n 옵션을 사용하여 정리할 수 있습니다. 이 옵션은 자동 인쇄 기능을 억제합니다. 인쇄 명령을 보내고 있으므로 기본 출력 인쇄 기능을 활성화할 필요가 없습니다:
|
1 |
$ sed -n 'p' gpl-3.0.txt |
정규식 문자 클래스
정규식에는 다양한 문자 클래스가 있습니다. 이러한 각 클래스에는 범위가 있습니다. 많은 클래스에는 여러 표현식도 있습니다. 대부분의 클래스는 문자 범위입니다:
-
- [a-z]: 소문자
-
- [A-Z]: 대문자
-
- [0-9]: 숫자
-
- [a-zA-z]: 알파벳
-
- [a-zA-z0-9]: 모든 영숫자 문자
이러한 문자 클래스는 다른 표기법도 가집니다:
-
- [:lower:]: 소문자
-
- [:upper:]: 대문자
-
- [:digit:]: 숫자
-
- [:alpha:]: 알파벳
-
- [:alphanum:]: 영숫자 문자
예를 들어, 다음 명령어는 최소한 하나의 숫자가 포함된 모든 줄을 출력합니다:
|
1 |
$ sed -n 's/[[:digit:]]/&/p' gpl-3.0.txt |
주소 범위
작업할 텍스트 스트림의 특정 부분을 지정할 수 있습니다. 줄의 정적 위치이거나 줄의 범위일 수 있습니다. 첫 번째 예에서는 GPL v3 텍스트 파일에서 5번째 줄을 출력합니다:
|
1 |
$ sed -n '5p' gpl-3.0.txt |

단일 줄 대신 작업할 줄의 범위를 지정할 수도 있습니다. 여기서는 sed 가 작업할 5번째 줄부터 9번째 줄까지의 주소 범위(총 5줄)를 지정했습니다:
|
1 |
$ sed -n '5,9p' gpl-3.0.txt |

줄 주소를 지정하는 다른 방법도 있습니다. 줄 번호를 직접 결정하는 대신, 이전 예제를 재구성하여 sed 가 5번째 줄부터 시작하여 다음 5줄에 대해 작동하도록 할 수 있습니다:
|
1 |
$ sed -n '5,+5p' gpl-3.0.txt |

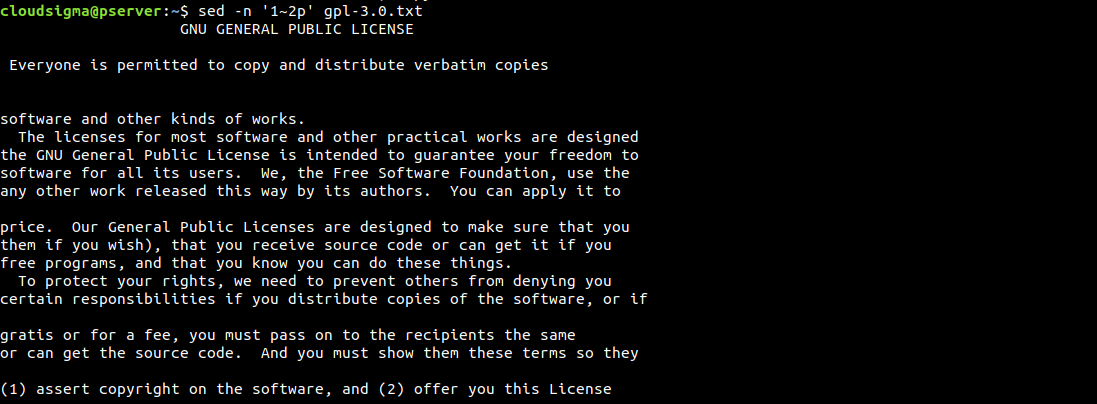
줄을 지정하는 또 다른 방법은 간격을 사용하는 것입니다. 다음 예에서 sed는 1번째 줄부터 시작하여 한 줄 건너 하나씩 작동합니다:
|
1 |
$ sed -n '1~2p' gpl-3.0.txt |
텍스트 삭제
지금까지 우리는 대상 텍스트 줄을 출력하는 작업을 했습니다. 출력하는 대신 출력에서 해당 줄을 제거할 수 있습니다. 다음 예제에서는 시작 부분부터 여러 줄을 제거해 보겠습니다. 여기서는 다음 옵션을 사용할 필요가 없습니다. -n 왜냐하면 우리는 sed 가 삭제되지 않은 다른 모든 것을 출력하기를 원하기 때문입니다. 줄 삭제를 위해 다음 옵션을 사용합니다. d:
|
1 |
$ sed '1~2d' gpl-3.0.txt |
원본 파일은 여전히 그대로 유지된다는 점에 유의하세요. Sed 는 출력 중에 줄 삭제를 수행할 뿐입니다. 원하는 경우 sed 출력을 파일에 저장할 수 있습니다. 원본 파일을 덮어쓰거나 다른 파일로 저장할 수 있습니다:
|
1 |
$ sed '1~2d' gpl-3.0.txt > gpl-3.0.modified.txt |
출력을 파일에 수동으로 쓰는 대신, sed는 원본 파일에서 바로 편집(in-place edit)을 수행할 수 있습니다. 간단히 말해, sed 가 원본 파일을 편집하고 변경 사항을 기록합니다. 이 방법은 원본 파일을 덮어쓰므로 주의해서 사용해야 합니다:
|
1 |
$ sed -i '1~2d' gpl-3.0.txt |
바로 편집하는 것은 위험하기 때문에, sed 에는 백업 기능이 제공됩니다. 바로 편집을 수행할 때, 편집하기 전에 백업을 만들기 위해 -i.bak 대신 -i를 사용하세요. Sed 는 다음과 같이 .bak 확장자로 백업 파일을 생성합니다:
|
1 |
$ sed -i.bak '1~2d' gpl-3.0.txt |
텍스트 치환
이것은 단연코 sed의 가장 일반적인 구현 중 하나입니다. 텍스트 패턴을 검색하고 해당 패턴을 지정된 텍스트로 바꿉니다. 여기서 텍스트 패턴은 정규 표현식(줄여서 regex)으로 설명됩니다. 정규 표현식 사용에 대해 자세히 알아보려면 파일에서 정규 표현식과 함께 Grep을 사용하여 텍스트 패턴을 검색하는 방법을 설명하는 이 튜토리얼을 따르세요.
정규 표현식을 사용한 가장 기본적인 텍스트 치환의 예는 다음과 같습니다:
|
1 |
$ 's/<search_pattern>/<replacement>' |
여기서 s는 치환을 위한 명령입니다. 슬래시는 패턴과 치환할 텍스트의 구분 기호입니다. 실제로 적용해 보겠습니다:
|
1 |
$ echo "hello world" | sed 's/hello/HELLO/' |
![]()
다음 예제는 밑줄(_)의 사용법을 보여줍니다. 여기서 밑줄은 구분 기호 역할을 합니다:
|
1 |
$ echo http://example.com/index.html | sed 's_com/index_net/home_' |
여기서 우리는 com/index를 net/home으로 변경하려고 합니다. 밑줄의 위치가 매우 중요하므로 주의하세요. 예를 들어, 마지막 밑줄이 누락되면 sed 가 오류를 발생시킵니다:
|
1 |
$ echo "http://www.example.com/index.html" | sed 's_com/index_net/home' |
![]()
치환을 연습하려면 더미 파일이 필요합니다. 여기 GPL v3 텍스트 파일의 잘린 버전이 있습니다:
|
1 |
$ cat gpl-3.0.cropped.txt |
몇 가지 기본적인 텍스트 치환을 수행해 보겠습니다:
|
1 |
$ cat gpl-3.0.cropped.txt | sed 's/GNU/GNU is Not Unix/' |
다음 예제를 살펴보세요. 우리는 the를 THE :
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/' |
![]()
무엇인가 알아차리셨나요? Sed 가 the를 모두 변경하지는 않았습니다. 실제로는 첫 번째 인스턴스만 변경되었습니다. 어떻게 된 일일까요? 이것은 옵션 s의 기본 동작입니다. 지정된 줄의 첫 번째 일치 항목만 일치시키고 다음 줄로 이동합니다. sed 가 검색 패턴에 대해 전체 줄을 확인하도록 하려면 선택적 플래그인 g를 사용해야 합니다. 명령을 수정해 보겠습니다:
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/g' |
이제 의도한 대로 작동합니다. 이 명령을 사용하는 또 다른 흥미로운 방법은 변경할 인스턴스의 수를 지정하는 것입니다. 이전 예제에서는 the가 3개 있었죠? 3번째 인스턴스만 변경하도록 지정하면 어떨까요? 변경은 선택적 플래그에서 발생합니다:
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/3' |
If you’re working with a big text file, then it may help if sed printed only those lines where the substitutions took place. To achieve that, we need to add another additional flag p:
|
1 |
$ sed -n 's/GNU/GNU is Not Unix/gp' gpl-3.0.txt |

Case Sensitivity
By default, all the sed operations are case-sensitive. The following command will demonstrate the default behavior of case sensitivity:
|
1 |
$ echo "HELLO WORLD" | sed 's/hello/hElLo/' |
![]()
Because of the case mismatch, there’s no change. In such a situation, we can tell sed to disable case sensitivity. To do so, add the optional flag i:
|
1 |
$ echo "HELLO WORLD" | sed 's/hello/hElLo/i' |
How to Replace and Reference Texts
The power of sed is mostly within its capability of using regular expression. With more advanced and complex regex patterns, we can accomplish a lot more. For example, we can substitute text from the beginning of a file to a certain location. Have a look at the following expression:
|
1 |
$ sed 's/^.*GNU/GNU_replaced/' gpl-3.0.txt |
Here, the caret text (^) denotes the start of the line. The match-any-character operator is signified using full-stop (.). The asterisk (*) is the wildcard expression, matching from the beginning of the line up to GNU.
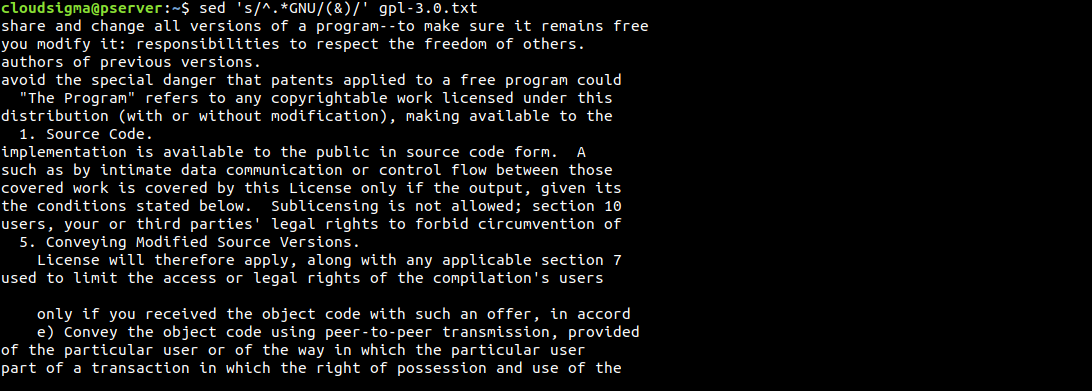
Another interesting trick is using the & symbol. We can use it to highlight the areas that sed finds the search pattern:
|
1 |
$ sed 's/^.*GNU/(&)/' gpl-3.0.txt |
Final Thoughts
In this tutorial, we explored the basics of the sed command. We learned how to print specific lines, search texts, delete and replace texts, overwrite texts, and use regular expressions. A properly constructed sed command can dramatically transform a text document. You can now successfully manipulate text in Linux with the help of sed.
Happy Computing!
댓글
아직 댓글이 없습니다. 첫 번째로 작성해 보세요.