

La grep commande est un utilitaire puissant pour rechercher des motifs dans du texte. Elle est préinstallée dans n'importe quelle distribution Linux . Voici notre tutoriel qui explique comment configurer la pile LAMP - Linux, Apache, MySQL et PHP.
Le nom grep signifie « global regular expression print ». L'outil recherche le motif spécifié dans l'entrée. En principe, cela semble trivial. Cependant, sa véritable puissance réside dans la manière dont vous définissez le motif. Ce guide explique en détail comment utiliser grep avec des expressions régulières pour effectuer des recherches complexes. Commençons !
Comment utiliser Grep
La commande grep, en soi, n'est pas compliquée. Tout ce qu'elle requiert, c'est le motif et le contenu sur lequel effectuer la recherche. Voici à quoi ressemble la structure de base de la commande grep :
|
1 |
grep <regex> <file> |
Recherche de texte
Tout d'abord, récupérez un exemple de fichier sur lequel effectuer l'action. Téléchargez la GNU General Public License v3.0 (au format texte). C'est un fichier texte assez volumineux contenant beaucoup de mots et de phrases. Si vous utilisez Ubuntu vous pouvez le trouver dans le fichier ci-dessous. Suivez notre tutoriel pour une installation rapide et facile d'Ubuntu.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

Ensuite, vous pouvez effectuer une recherche de texte de base à l'aide de grep :
|
1 |
grep <pattern> <text_file> |
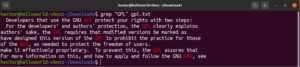
Il est possible de rediriger la sortie d'une commande vers grep :
|
1 |
cat gpl.txt | grep <pattern> |
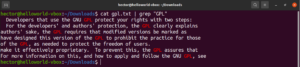
Sensibilité à la casse
Par défaut, grep est sensible à la casse. Dans de nombreuses situations, ignorer la sensibilité à la casse peut être optimal. Pour désactiver la recherche sensible à la casse, utilisez l'option « -i » ou « –ignore-case » :
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
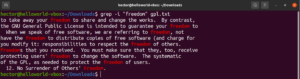
Inverser la recherche
Par défaut, le comportement de grep est d'afficher les lignes où le motif a été trouvé. L'inversion de correspondance fait référence au cas où vous ne souhaitez pas voir les lignes qui correspondent au motif. Pour inverser la correspondance, vous devez utiliser l'option « -v » ou « –invert-match » :
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
Numéro de ligne
Lorsque vous exécutez grep sur un fichier très volumineux, il est difficile de suivre l'emplacement du résultat de la recherche. Pour faciliter les choses, grep dispose d'une fonctionnalité permettant d'afficher le numéro de ligne. Pour activer la numérotation des lignes, utilisez l'option « -n » ou « –line-number » :
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
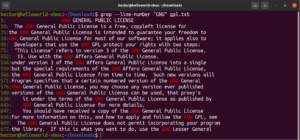
Il est possible de combiner plusieurs arguments grep. La commande grep suivante effectuera une inversion de correspondance tout en affichant les numéros de ligne :
|
1 |
grep -nv <pattern> <file> |
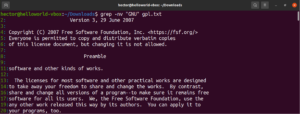
Expression régulière
Au début de ce guide, nous avons mentionné que grep signifie « global regular expression print ». Le terme « expression régulière » est défini comme une chaîne spéciale qui décrit le motif de recherche. Les expressions régulières ont leur propre structure et leurs propres règles.
Il existe de nombreux algorithmes et outils de recherche de chaînes qui utilisent des expressions régulières (regex en abrégé) pour effectuer des recherches et des actions de remplacement. Bien qu'elles soient populaires, différentes applications et langages de programmation implémentent les regex de manière légèrement différente. Dans cette section, nous présenterons quelques méthodes de regex utilisant grep.
Correspondance littérale
Dans les exemples grep précédents, grep effectuait la recherche d'une chaîne spécifique dans le fichier texte donné. Grep effectuait en fait sa recherche en utilisant une expression régulière très basique. Les motifs regex qui définissent la recherche d'une correspondance exacte pour une chaîne donnée sont appelés « littéraux ». Ce nom vient du fait qu'ils correspondent au motif littéralement, caractère par caractère.
La correspondance littérale fonctionne avec les caractères alphabétiques et numériques (ainsi que certains caractères spéciaux). Cependant, selon d'autres mécanismes d'expression, ce comportement peut changer :
|
1 |
grep "<string>" <file> |
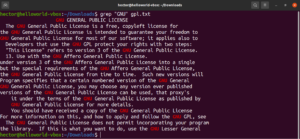
Correspondance d'ancre
Les ancres sont des caractères spéciaux qui définissent où doit se situer la correspondance dans la ligne pour être valide. Voici un exemple rapide pour simplifier. Si nous cherchons à trouver uniquement les lignes qui commencent par la chaîne « GNU », alors la commande grep avec expression régulière ressemblera à ceci. Ici, le caractère « ^ » est l'ancre, définissant que seules les correspondances au début de la ligne sont valides :
|
1 |
grep -n "^GNU" <file> |

De même, si nous cherchons à trouver uniquement les lignes qui se terminent par la chaîne « works », alors la commande grep avec expression régulière ressemblera à ceci. Ici, le caractère « $ » est l'ancre, définissant que seules les correspondances à la fin de la ligne sont valides :
|
1 |
grep -n "and$" <file> |
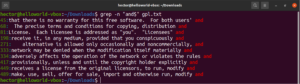
Correspondance de n'importe quel caractère
Lors d'une recherche de texte, vous pouvez vouloir définir qu'à un endroit spécifique, il peut y avoir n'importe quel caractère. En expression régulière, cela est exprimé par le caractère point (.).
Regardez cet exemple. Dans le fichier texte de la licence GNU GPL 3, les mots « accept » et « except » ont tous deux la partie « cept » en commun. De plus, les deux mots ont deux caractères avant la partie « cept ». La commande grep suivante correspondra à tout mot ayant deux caractères avant la partie « cept » :
|
1 |
grep -n "..cept" <file> |
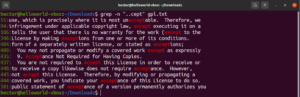
Selon cette expression régulière, d'autres mots comme suscept, unaccept, unexpected, etc. sont également des correspondances valides.
Crochets
En expression régulière, les expressions entre crochets définissent qu'à l'emplacement spécifié, il peut y avoir n'importe quel caractère déclaré à l'intérieur des crochets. Regardez la chaîne d'expression régulière suivante :
|
1 |
t[wo]o |
En la mettant en pratique, les mots too et two seront les correspondances valides :
|
1 |
grep -n "t[wo]o" <file> |
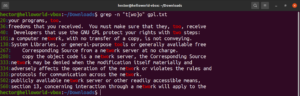
L'expression entre crochets ouvre la voie à des possibilités intéressantes. Il est possible d'utiliser des expressions entre crochets pour indiquer qu'à l'emplacement spécifié, il peut y avoir n'importe quel caractère autre que ceux déclarés à l'intérieur des crochets. Regardez la chaîne d'expression régulière suivante. La correspondance ne sera valide que s'il y a un caractère autre que « c » avant « ode » :
|
1 |
"[^c]ode" |
Exécutez-la sur le fichier texte de la licence GPL-3 :
|
1 |
grep -n "[^c]ode" <file> |

Outre le résultat du fichier, d'autres résultats valides seraient node, abode, anode, etc. Les expressions entre crochets peuvent également décrire une plage de caractères. L'expression régulière suivante indique que la correspondance est valide si le début de la ligne est un caractère majuscule :
|
1 |
"^[A-Z]" |
Exécutez-la sur le fichier texte de la licence GPL-3. Cela affichera toutes les lignes du fichier texte :
|
1 |
grep -n "^[A-Z]" <file> |
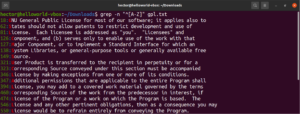
Pour plus de facilité d'utilisation, il existe certaines classes de caractères qui ont des étiquettes spécifiées. Dans l'exemple précédent, nous avons utilisé la plage « A-Z » pour définir les caractères majuscules. À la place, nous pouvons également utiliser « [:upper:] ». Le résultat sera le même :
|
1 |
grep -n "^[[:upper:]]" <file> |
Répéter un motif
Dans certaines situations, vous pouvez vouloir faire correspondre un motif spécifique ou une expression régulière zéro ou plusieurs fois. Pour ce faire, le méta-caractère est l'astérisque (*). L'expression régulière suivante correspondra à toutes les parenthèses contenant uniquement des lettres et des espaces simples entre elles. Notez que la déclaration des ensembles de caractères minuscules, majuscules et des espaces se fait ensemble sans aucune ponctuation :
|
1 |
"([a-zA-Z ]*)" |
Mettez l'expression régulière en pratique avec grep :
|
1 |
grep -n "([A-Za-z ]*)" <file> |

Utiliser des méta-caractères comme caractères littéraux
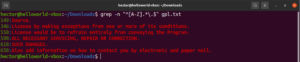
Jusqu'à présent, nous avons découvert différents méta-caractères comme l'astérisque (*), le point (.), les ancres (^ et $), etc. Chacun d'eux désigne une fonction unique dans le contexte des expressions régulières (regex). Le problème se pose lorsqu'ils doivent être utilisés comme des littéraux, et non comme des méta-caractères. Dans de telles situations, une barre oblique inverse (\) devant le méta-caractère indiquera qu'il doit être utilisé au sens littéral, et non comme un méta-caractère. Jetez un œil à cet exemple de regex. Il correspondra à toutes les lignes qui commencent par un caractère majuscule et se terminent par un point :
|
1 |
grep -n "^[A-Z].*\.$" <file> |
Alternance
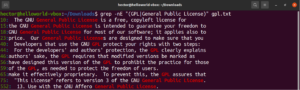
En utilisant des expressions entre crochets, nous pouvons spécifier différents choix possibles pour la correspondance d'un seul caractère. Les regex ont la particularité de pouvoir faire de même avec des mots et des phrases. Pour indiquer une alternance, le caractère barre verticale (|) est utilisé. Les options restent entre parenthèses tandis que la barre verticale les sépare les unes des autres. Il peut y avoir deux options possibles ou plus pour que la correspondance soit valide. Jetez un œil à l'exemple de regex suivant. Il correspondra à la fois à « GPL » et à « General Public License » :
|
1 |
grep -nE "(GPL|General Public License)" <file> |
Quantificateurs
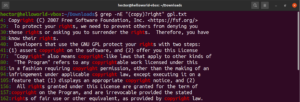
En utilisant le méta-caractère astérisque (*), nous avons pu définir un motif répété zéro, une ou plusieurs fois. Cependant, il y a plus à explorer. Il est plus facile d'expliquer les quantificateurs avec un exemple. L'expression régulière suivante décrit que « copyright » et « right » sont tous deux des correspondances valides. Le point d'interrogation (?) signifie que la partie « copy » est facultative pour la correspondance :
|
1 |
grep -nE "(copy)?right" <file> |
Le quantificateur suivant est le symbole d'addition (+). Il se comporte de manière similaire à l'astérisque. Cependant, le motif défini doit correspondre au moins une fois. Dans l'exemple suivant, l'expression régulière correspondra à « soft » suivi d'un ou plusieurs caractères qui ne sont pas des espaces :
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
Spécifier la répétition de la correspondance
Il est possible de spécifier le nombre de fois qu'une correspondance est répétée. Pour ce faire, utilisez les accolades ({}). L'expression régulière suivante correspondra à tout mot contenant un minimum de trois voyelles :
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

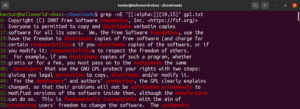
Cette fonctionnalité vous permet également de définir la limite inférieure et la limite supérieure de la longueur de la correspondance. Dans l'exemple suivant, la regex correspondra à tout mot d'une longueur de 10 à 15 caractères :
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
Conclusion
Rechercher dans des fichiers texte avec grep est très pratique. Les expressions régulières rendent la recherche avec grep plus intéressante et utile. Elles permettent également d'ajuster le motif de recherche selon vos moindres désirs.
Bien que nous ayons présenté certaines des expressions régulières les plus courantes, ce n'est que le début. Il existe des expressions régulières plus avancées qui offrent un contrôle extrêmement précis sur le comportement de recherche. Outre grep, les expressions régulières sont également largement utilisées par d'autres outils et langages de programmation.
Bonne informatique !
Commentaires
Aucun commentaire pour l'instant. Soyez le premier.