

La réplication MySQL est une fonctionnalité intéressante qui permet aux utilisateurs de gérer plusieurs copies d'une ou plusieurs bases de données MySQL. Les données sont copiées automatiquement depuis la base de données source vers la base de données réplica. Cela peut être utile dans de nombreuses situations, comme travailler avec les données sans compromettre la base de données principale, sauvegarder les données, ou faire évoluer l'accès à la base de données, etc.
Dans ce guide, nous allons passer en revue les étapes de configuration d'une instance MySQL sur un serveur en tant que base de données source, puis de configuration d'une instance MySQL sur un autre serveur pour qu'elle fonctionne comme son réplica.
Prérequis
Ce guide présentera un exemple très simple de réplication MySQL. Il implique une base de données source et une base de données réplica. La base de données source est la copie principale de la base de données tandis que la base de données réplica sera le réplica de la base de données source. Pour notre démonstration, deux serveurs sont configurés avec les adresses IP suivantes :
- Serveur source : 31.171.240.179
- Serveur réplica : 31.171.250.139
Chaque serveur est configuré avec la dernière configuration de serveur Ubuntu 20.04. Tout d'abord, suivez les étapes du tutoriel qui montrent comment configurer votre serveur Ubuntu. Notez que le nombre de bases de données réplicas peut être plus élevé. Ce guide suppose que vous avez déjà installé et configuré MySQL. Besoin d'aide pour l'installation de MySQL ? Ce guide présente en détail les étapes de l'installation et de l'utilisation de base de MySQL.
En résumé, voici les paquets dont vous avez besoin :
|
1 |
$ sudo apt install mysql-server mysql-client |
Les pare-feux des deux systèmes doivent être configurés pour autoriser le trafic provenant des deux systèmes sur le port 3306. C'est le port par défaut pour MySQL. Vous pouvez en savoir plus sur les bases d'UFW avec une démonstration dans notre article de blog.
Configuration de la base de données source
-
Ajustement de la configuration de MySQL
MySQL utilise my.cnf comme fichier de configuration principal. Nous allons mettre à jour my.cnf pour désigner le serveur comme le source. Tout d'abord, ouvrez le fichier de configuration avec un éditeur de texte :
|
1 |
$ sudo nano /etc/mysql/my.cnf |
Ensuite, ajoutez les lignes suivantes sous la section mysqld :
|
1 2 3 4 |
bind-address = 31.171.240.179 server-id = 1 log_bin = /var/log/mysql/mysql-bin.log binlog_do_db = newdatabase |
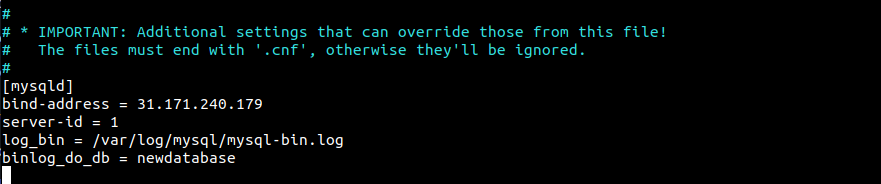
Que signifient ces lignes ?
bind-address: C'est l'entrée qui définit l'association entre un service et une adresse IP. Par défaut, la valeur peut être127.0.0.1(localhost). La nouvelle valeur sera l'adresse IP du serveur.server-id: Dans la réplication MySQL, chaque serveur doit avoir un identifiant de serveur unique. Cela peut être n'importe quel nombre. Par souci de simplicité, il est défini sur1.log_bin: Il stocke les détails réels de la réplication. La base de données réplica va copier tout ce qui est enregistré dans le journal.binlog_do_db: Cette entrée désigne la base de données qui fera l'objet de la réplication sur le serveur réplica. Il peut y avoir plus d'une base de données. Ici, la base de données d'exemple estnewdatabase.
Après avoir effectué les modifications, enregistrez le fichier de configuration. MySQL doit être redémarré pour charger les modifications dans le my.cnf:
|
1 |
$ sudo service mysql restart |
-
Accorder des autorisations à l'utilisateur réplica
L'étape suivante consiste à créer un utilisateur réplica et à lui accorder les privilèges appropriés. Cela doit être fait depuis le shell MySQL. Tout d'abord, lancez le shell MySQL :
|
1 |
$ sudo mysql -u root -p |
Ensuite, créez un utilisateur dédié pour la base de données réplica. Modifiez le nom d'utilisateur et le mot de passe de manière appropriée :
|
1 |
$ CREATE USER 'cloudsigma_s'@'31.171.240.179' IDENTIFIED BY 'password_123'; |
Maintenant, accordez les privilèges appropriés à l'utilisateur :
|
1 |
$ GRANT REPLICATION SLAVE ON *.* TO 'cloudsigma_s'@'31.171.240.179'; |
Vous pouvez en savoir plus sur les utilisateurs et autorisations MySQL dans notre article de blog. Ensuite, rechargez la table des privilèges pour que les modifications prennent effet :
|
1 |
$ FLUSH PRIVILEGES; |

-
Ajustement de la base de données
Nous avons besoin d'une copie de la base de données source sur le réplica. Il est possible de construire manuellement la structure. Cependant, dans la plupart des cas, c'est assez peu pratique. C'est pourquoi l'exportation directe de la base de données est la solution la plus optimale. Dans cet exemple, la base de données source est newdatabase. Changez la base de données actuelle :
|
1 |
$ USE newdatabase; |
La commande suivante va verrouiller la base de données, empêchant toute nouvelle modification :
|
1 |
$ FLUSH TABLES WITH READ LOCK; |
Ensuite, vérifiez le statut de la base de données :
|
1 |
$ SHOW MASTER STATUS; |
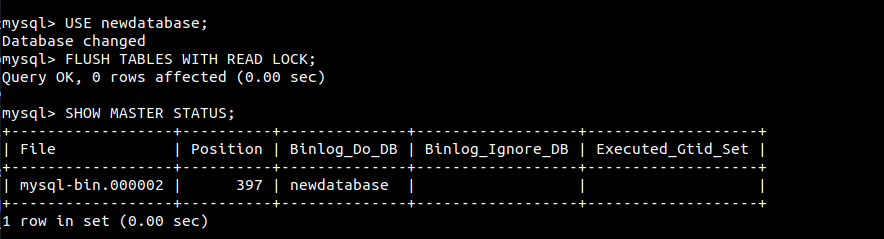
À partir de cette position, la base de données réplica commencera à se répliquer depuis la source. Ces chiffres seront utiles plus tard, alors conservez-en une trace. Si des modifications sont apportées depuis la même fenêtre, MySQL déverrouillera automatiquement la base de données. Il est donc recommandé d'effectuer les étapes suivantes sur un autre onglet ou une autre fenêtre de terminal. La base de données est toujours verrouillée. Exportez-la vers un fichier SQL portable :
|
1 |
$ mysqldump -u root -p --opt newdatabase > newdatabase.sql |
La tâche est maintenant terminée. Ensuite, déverrouillez la base de données :
|
1 |
$ UNLOCK TABLES; |
Enfin, quittez le shell :
|
1 |
$ QUIT; |
Configuration du réplica
Il est maintenant temps de configurer la base de données réplica.
-
Importation de la base de données source
Nous avons besoin d'une copie de la base de données source sur le serveur réplica. Nous utiliserons le fichier SQL exporté précédemment pour ce faire. Lancez le shell MySQL :
|
1 |
$ sudo mysql -u root -p |
Après cela, créez une base de données vide en utilisant le même nom de base de données :
|
1 |
$ CREATE DATABASE newdatabase; |
Ensuite, quittez le shell :
|
1 |
$ EXIT; |
Maintenant, importez le fichier SQL dans la base de données :
|
1 |
$ sudo mysql -u root -p newdatabase < newdatabase.sql |
![]()
-
Ajustement de la configuration de MySQL
Il y a quelques éléments à déclarer dans le fichier de configuration de MySQL. Ouvrez le fichier de configuration dans un éditeur de texte :
|
1 |
$ sudo nano /etc/mysql/my.cnf |
Les entrées suivantes iront sous la section mysqld. Sinon, cela ne fonctionnera pas. Le premier est l'ID du serveur. Comme mentionné précédemment, il doit être unique pour tous les serveurs de la configuration de réplication source-réplica. Pour la démonstration, il est défini sur 2:
|
1 |
$ server-id = 2 |
Ensuite, ajoutez les lignes suivantes :
|
1 2 3 |
$ relay-log = /var/log/mysql/mysql-relay-bin.log $ log_bin = /var/log/mysql/mysql-bin.log $ binlog_do_db = newdatabase |

Ici, seul relay-log est une nouvelle entrée. C'est le journal que le serveur réplica crée pendant la réplication. Le format du journal est le même que celui du journal binaire. Enregistrez le fichier de configuration et redémarrez MySQL :
|
1 |
$ sudo service mysql restart |
-
Activation de la réplication
Enfin, nous sommes prêts à activer la réplication depuis MySQL. Lancez le shell MySQL :
|
1 |
$ sudo mysql -u root -p |
Exécutez la commande suivante. Tout d'abord, modifiez l'adresse IP, le nom d'utilisateur et les mots de passe en conséquence :
|
1 |
$ CHANGE MASTER TO MASTER_HOST='31.171.240.179',MASTER_USER='cloudsigma_master', MASTER_PASSWORD='password_123', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS= 107; |

La commande accomplit ce qui suit :
- Le serveur actuel est marqué comme le réplica du serveur source.
- Le serveur réplica dispose des identifiants de connexion appropriés.
- Le serveur réplica sait d'où commencer la réplication. Vous vous souvenez du statut de la base de données que nous avons vérifié sur le serveur source ? Le fichier journal source et la position du journal proviennent de là.
Enfin, activez le serveur réplica :
|
1 |
$ START REPLICA; |

-
Divers
Besoin de vérifier les détails de l'état actuel du réplica ? Exécutez la commande suivante dans le shell MySQL. Le \G à la fin sert à réorganiser les textes pour les rendre plus lisibles :
|
1 |
$ SHOW REPLICA STATUS\G |
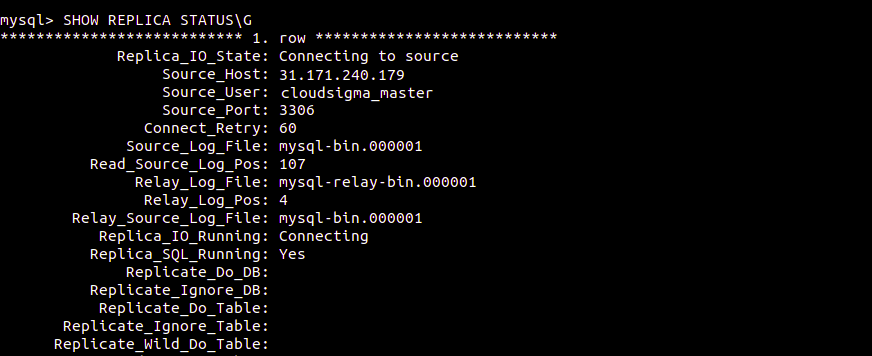
S'il y a un problème de connexion, essayez de démarrer le serveur réplica pour le contourner :
|
1 |
$ SET GLOBAL SQL_REPLICA_SKIP_COUNTER = 1; REPLICA START; |
Conclusion
La réplication MySQL a de nombreuses implications. Il ne s'agit que d'une brève démonstration de sa forme de base. Cependant, elle peut facilement s'étendre à des configurations à sources et réplicas multiples. Les mêmes étapes s'appliqueront également à toutes les configurations complexes de niveau supérieur. C'est toujours une bonne idée de tester toute configuration par la suite. Essayez d'exécuter des commandes insert, delete ou update sur la base de données source. Si la configuration fonctionne, la base de données réplica devrait tout récupérer correctement.
De plus, vous pouvez consulter d'autres ressources de notre blog couvrant ce que vous pouvez faire avec MySQL :
- SQLite vs MySQL vs PostgreSQL : comparaison des systèmes de gestion de bases de données relationnelles
- Comment réinitialiser le mot de passe root de MariaDB ou MySQL
- Comment installer la pile LEMP (Linux, Nginx, MySQL PHP) sur Ubuntu 20.04
Bonne informatique !
Commentaires
Aucun commentaire pour l'instant. Soyez le premier.