

Les entreprises impliquent une grande quantité de données, ce qui rend leur traitement et leur gestion plus difficiles. Traditionnellement, l'industrie utilise des systèmes RDBMS depuis des décennies, mais avec l'avènement du Big Data au XXIe siècle, les bases de données NoSQL (Not only SQL) sont apparues pour gérer les données non structurées et semi-structurées à grande échelle.
Dans cet article, je vais configurer un cluster MongoDB.
MongoDB est une base de données de documents NoSQL gratuite et open-source, qui est largement utilisée en raison du haut niveau d'évolutivité et de flexibilité qu'elle offre.
Pour déployer MongoDB en production, il est conseillé d'utiliser des Replica Sets. Les Replica Sets sont l'équivalent pour MongoDB d'une configuration Maître/Esclave dans le monde relationnel, mais en revanche, ils sont très faciles à configurer, car tout est intégré. Pour en savoir plus sur les Replica Sets, consultez la définition de TutorialsPoint’s sur le processus de réplication.
Planification de votre cluster de serveurs cloud MongoDB
Je vais créer un cluster à 3 nœuds. Il est important de leur attribuer des ressources équivalentes car n'importe lequel d'entre eux peut devenir le serveur primaire (c'est-à-dire maître). Ces nœuds ou machines peuvent fonctionner sur n'importe quel système d'exploitation, mais dans ce tutoriel, je vais utiliser Ubuntu 18.04 LTS. Pour savoir comment attacher et configurer l'image préinstallée de la bibliothèque de CloudSigma’s, vous pouvez vous référer à ce tutoriel.
Puisque tout l'intérêt d'un Replica Set est que le cluster survive à la panne d'un seul nœud, il serait plutôt inutile que tous vos serveurs résident sur le même hôte physique. Heureusement, CloudSigma propose quelque chose appelé groupes de disponibilité. Cela signifie que vous pouvez demander au système de regrouper vos trois serveurs dans des groupes différents. De cette façon, ils ne résideront jamais sur le même hôte physique. Vous trouverez plus d'informations à ce sujet ainsi que sur d'autres fonctionnalités de sécurité et de continuité d'activité ici.
Il est également important d'utiliser une version 64 bits de Linux. La raison en est simplement que MongoDB ne fonctionne pas bien sur les systèmes 32 bits (plus d'informations à ce sujet ici).
Installer MongoDB dans le Cloud
Cette section est assez simple. Utilisez soit l'une des images préconfigurées de Ubuntu 18.04 ou installez-la vous-même.
La configuration du processeur, de la RAM et du disque est vraiment individuelle et dépend de votre charge. Pour une petite installation, un processeur de 4 GHz, 4 Go de RAM et un disque de 10 Go (pour le système) devraient suffire. Lorsque vous attachez vos disques, assurez-vous d'utiliser VirtIO. Si vous utilisez IDE, les performances en souffriront considérablement. De plus, comme vous créez un Replica Set, vous devez vous assurer que tous les nœuds (et serveurs d'applications) se trouvent sur le même VLAN.
Contrairement à de nombreux autres fournisseurs de cloud, il n'est pas nécessaire de configurer votre stockage avec RAID10 ou similaire pour améliorer les performances. Comme le signalent beaucoup de nos clients, vous obtiendrez des performances exceptionnelles dès le départ en utilisant à la fois des disques SSD et magnétiques chez CloudSigma.
Je recommande tout de même de conserver les données MongoDB sur un disque séparé. La raison en est simplement qu'à un moment donné, vous devrez peut-être effectuer des optimisations du système de fichiers que vous ne souhaiteriez pas appliquer à l'ensemble de votre système de fichiers.
Dans cette optique, c’est le plus simple d'ajouter ce disque après la configuration des serveurs. Pour l'instant, concentrons-nous sur l'installation du système. Si vous effectuez l'installation vous-même (au lieu d'utiliser les systèmes préconfigurés), je vous recommande d'appuyer sur F4 dans le menu de démarrage et de sélectionner ‘Installer une machine virtuelle minimale’.
Je crée 3 machines, chacune avec les spécifications suivantes :
- Processeur : 4 GHz
- RAM : 4 Go
- SSD : 10 Go (Ubuntu 18.04 LTS), 20 Go (disque supplémentaire)
Comme indiqué dans la partie SSD, j'attache un disque de 10 Go sur lequel est installé Ubuntu 18.04 LTS.
De plus, j'y attache un autre disque vide de 20 Go pour stocker les données MongoDB. La taille de celui-ci dépend fortement de votre utilisation, mais pour un petit système, 20 Go devraient probablement suffire. Cependant, comme il est parfois difficile de prédire la quantité de données que vous allez stocker, nous utiliserons LVM. Cela vous permettra d'ajouter simplement un autre disque plus tard et d'étendre le volume sans avoir à tout recommencer. Alternativement, vous pouvez utiliser un seul disque et l'agrandir plus tard avecresize2fs.
Pour ajouter le disque, allez simplement dans la section ‘Drives’, cliquez sur l'icône ‘Create a new drive’ en haut, donnez un nom au nouveau disque et définissez sa taille sur 20 Go. Une fois enregistré, allez sur la machine individuelle à laquelle vous souhaitez l'attacher et, sous la section des disques des détails de cette machine, je peux cliquer sur ‘Attach a drive’ et sélectionner le disque.
Maintenant que vous avez trois machines, vous pouvez procéder au montage du disque supplémentaire que vous avez ajouté pour votre stockage de données MongoDB sur chaque machine. Je recommande d'ajouter ce disque en tant que partition. L'utilisation du partitionnement permet au système d'exploitation de gérer les informations dans chaque région séparément. Pour ajouter le disque en tant que partition, je vais d'abord vérifier tous les disques connectés à notre machine. Pour ce faire, je vais exécuter la commande suivante :
|
1 |
fdisk -l |
Lorsque j'exécute la commande, j'obtiens le résultat indiquant les disques et les périphériques sur ma machine.
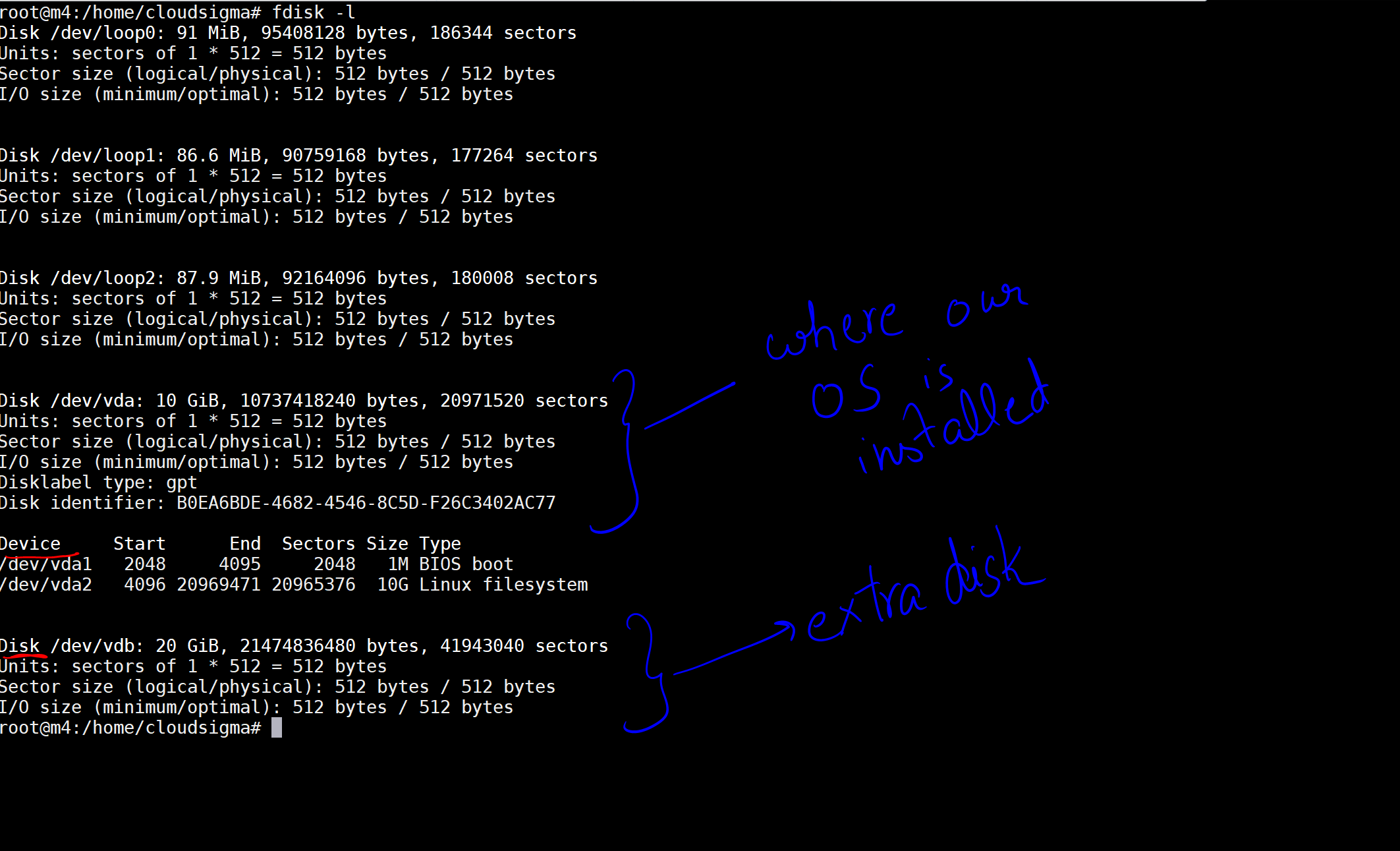
Dans l'image, j'ai marqué un disque de 10 Go comme celui où notre système d'exploitation est installé. Ensuite, il y a un autre disque de 20 Go qui a maintenant été attaché. L'emplacement du disque est /dev/vdb. Vous pouvez créer une partition sur ce disque à l'aide des commandes suivantes :
|
1 |
sudo fdisk /dev/vdb |
Cela ouvrirait l'utilitaire fdisk, un utilitaire en ligne de commande qui fournit des fonctions de partitionnement de disque, dans lequel vous pouvez créer des partitions sur notre disque. Il affichera une invite “Command (m for help):” où vous devez saisir n pour créer une nouvelle partition, puis continuer à appuyer sur Entrée pour accepter les valeurs par défaut. Et après avoir créé la partition, saisissez w pour écrire les modifications. Cela ressemblerait à ceci :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Commande (m pour aide): <strong>n</strong> Partition type p primaire (0 primaire, 0 étendue, 4 libre) e étendue (conteneur pour logiques partitions) Sélectionner (défaut p): Utilisation de défaut réponse p. Partition numéro (1-4, défaut 1): Premier secteur (2048-41943039, défaut 2048): Dernier secteur, +secteurs ou +taille{K,M,G,T,P} (2048-41943039, défaut 41943039): Créé une nouvelle partition 1 de type 'Linux' et de taille 20 GiB. Commande (m pour aide): <strong>w</strong> La partition table a été modifiée. Appel de ioctl() pour re-lire partition table. Synchronisation des disques. |
Cela a créé une nouvelle partition 1 de type ‘Linux’ et de taille 20 GiB. Maintenant que la partition est créée, créons un pool LVM :
|
1 2 3 |
sudo pvcreate /dev/vdb1 sudo vgcreate mongodb /dev/vdb1 sudo lvcreate -n db -L 19.5g mongodb |
J'ai saisi ‘19.5g’ car la taille de ma partition est de 20g. Ensuite, exécutez la commande suivante pour trouver le nom du disque :
|
1 |
fdisk -l | grep mongo | awk '{print $2'} |
Après cela, formatez le disque en utilisant la méthode ext4 avec la commande suivante :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
sudo mkfs.ext4 /dev/mapper/mongodb-db Sortie: root@m4:/home/cloudsigma# sudo mkfs.ext4 /dev/mapper/mongodb-db mke2fs 1.44.1 (24-Mar-2018) Création de système de fichiers avec 5217280 4k blocs et 1305600 inodes Système de fichiers UUID: 695a62e6-021d-4fc0-945c-cc51a92d86da Superbloc sauvegardes stockées sur blocs: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 Allocation des tables de groupes: fait Écriture des tables d'inodes: fait Création du journal (32768 blocs): fait Écriture des superblocs et de l'information de comptabilité du système de fichiers: fait |
Ensuite, créons un emplacement pour monter le disque et un dossier dans lequel conserver vos données MongoDB.
|
1 |
sudo mkdir -p /mongodb/data |
Afin d'ajouter une entrée dans le fstab concernant votre nouveau disque à monter, vous pouvez utiliser directement la commande ci-dessous :
|
1 |
echo -e "` blkid | grep mongodb | awk {'print $2'}`\t/mongodb\text4 auto,noexec,rw,sync,nouser\t0\t0" >> /etc/fstab |
Dans la commande, blkid vous donne un UUID – Universally Unique Identifier (identifiant unique universel) de chaque disque. Ici, je filtre celui du disque MongoDB et je combine cet UUID avec l'emplacement du dossier de montage, le type de système de fichiers et d'autres options pour le disque respectivement. J'ajoute cette ligne à /etc/fstab. Si vous ne le faites pas, vous obtiendrez une erreur lors du montage du disque. L'entrée ressemble à ceci :
UUID=”695a62e6-021d-4fc0-945c-cc51a92d86da” /mongodb ext4 auto,noexec,rw,sync,nouser 0 0
Maintenant, vous pouvez monter le disque sur l'emplacement /mongodb :
|
1 |
sudo mount /mongodb |
Installation de MongoDB
Une fois le système préparé, passons à l'installation de MongoDB. Bien qu'Ubuntu propose une version de MongoDB dans son propre dépôt, je vous recommande d'utiliser plutôt la version officielle de MongoDB. La raison en est que le dépôt d'Ubuntu est assez en retard dans les versions, donc si vous voulez tirer le meilleur parti de MongoDB, vous devrez vous tourner vers les versions officielles.
Puisque MongoDB propose son propre dépôt, vous pouvez simplement l'ajouter à votre système puis installer MongoDB normalement. Voici les étapes à suivre :
Tout d'abord, importez la clé publique utilisée par le système de gestion de paquets :
|
1 |
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4 |
Ensuite, je crée un fichier de liste. Celui-ci contiendra le dépôt où se trouve MongoDB, afin que votre système puisse le télécharger à partir de là :
|
1 |
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list |
Maintenant, je mets à jour ma base de données de paquets locale afin de prendre en compte les modifications.
|
1 |
sudo apt-get update |
Maintenant, je peux simplement installer le paquet en utilisant la commande suivante :
|
1 |
sudo apt-get install -y mongodb-org |
J'ai installé MongoDB sur chacune des machines.
|
1 |
sudo service mongod start |
Maintenant, MongoDB est opérationnel, avec les données créées sur le disque. Si une charge lourde et/ou un grand nombre de connexions sont attendus, vous devrez peut-être augmenter les valeurs de ulimit .
Si vous souhaitez obtenir plus d'informations sur vos données, vous pouvez également vous inscrire au MMS, qui est un service de surveillance gratuit basé sur le cloud pour MongoDB.
Création du Replica Set pour votre Cloud MongoDB
Maintenant, créons un replica set. Avant cela, vous devez vous assurer que chacune des machines peut communiquer avec les autres. Pour ce faire, vous devez ajouter ces entrées dans /etc/hosts
|
1 2 3 |
IP-1 m1.mongo.cluster m1 IP-2 m2.mongo.cluster m2 IP-3 m3.mongo.cluster m3 |
Pour vérification, vous pouvez essayer de pinger les machines en utilisant le nom d'hôte. Ainsi, si l’IP de ma machine 1 est IP-1, disons, 213.189.123.12, alors au lieu d'écrire
|
1 |
ping 123.189.123.12 |
j'écrirai,
|
1 2 3 |
ping m1.mongo.cluster ou ping m1. |
Si vous avez activé le pare-feu (ce que vous devriez vraiment faire), assurez-vous que les nœuds peuvent envoyer et recevoir du trafic TCP sur les ports 28017 et 27017 sur l'interface interne.
Maintenant, sur chacune des machines, démarrez le service mongod en utilisant les commandes suivantes.
Sur la machine m1,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m1.mongo.cluster |
Ensuite, sur la machine m2,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m2.mongo.cluster |
Sur la machine m3,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m3.mongo.cluster |
Ici,
mongod est le nom du service
dbpath est l'emplacement de notre répertoire de base de données
replSet est le nom de notre ensemble de réplication. Il doit être le même pour chacune des machines du même ensemble de réplication
bind_ip est le nom d'hôte de la machine sur laquelle vous l'exécutez.
Une fois que vous avez démarré le service mongod, allez sur le serveur primaire (dans mon cas, j'ai choisi m1) et lancez mongo.
|
1 |
mongo |
Cela démarrera le terminal MongoDB. Sur le terminal, initialisez le replicaSet à l'aide de la commande ci-dessous. Cela créera le replicaSet avec les configurations par défaut :
|
1 |
rs.initiate() |
Maintenant, il ne reste plus qu’à ajouter les deux autres machines comme réplicas en utilisant les commandes suivantes :
|
1 2 |
rs.add("m2.mongo.cluster") rs.add("m3.mongo.cluster") |
Vous pouvez surveiller l'état à l'aide de la commande :
|
1 |
rs.status() |
C’est vraiment tout. Vous devriez maintenant être opérationnel avec votre cluster MongoDB sur le cloud ultra-rapide de CloudSigma.
Commentaires
Aucun commentaire pour l'instant. Soyez le premier.