

The Elastic Stack (auparavant connue sous le nom d'ELK Stack) est une solution puissante pour la journalisation centralisée. Il s'agit d'une collection de logiciels open-source développés par Elastic. Elle permet aux administrateurs de rechercher, d'analyser et de visualiser les journaux générés à partir de n'importe quelle source dans n'importe quel format. C'est une pratique connue sous le nom de journalisation centralisée. La journalisation centralisée peut être très pratique pour identifier les problèmes liés aux serveurs et aux applications, car elle permet de rechercher dans tous les journaux à partir d'un seul endroit. Elle peut également aider à identifier les problèmes sur plusieurs serveurs en corrélant les journaux à un moment précis.
Dans ce guide, découvrez comment installer Elastic Stack sur Ubuntu 18.04. Tout d'abord, suivez notre tutoriel pour facilement installer votre serveur Ubuntu sur CloudSigma.
The Elastic Stack sur Ubuntu
The Elastic Stack se compose des composants suivants :
- Elasticsearch : un moteur de recherche RESTful distribué. Il stocke toutes les données collectées.
- Logstash: La partie traitement des données de The Elastic Stack. Elle envoie les données entrantes à Elasticsearch.
- Kibana: Une interface web, offrant des fonctionnalités de recherche et de visualisation des journaux.
- Beats: Un transmetteur de données léger et à usage unique. Il peut envoyer des données depuis de nombreuses machines vers Logstash ou Elasticsearch.
Vous devrez installer manuellement chaque composant de la suite.
Prérequis
Avant de procéder à l'installation de la suite Elastic, plusieurs exigences système doivent être satisfaites :
- Exigences matérielles :
- Processeur : 2 processeurs (accessibles depuis un utilisateur sudo non-root)
- RAM : 4 Go
- OpenJDK 11 (la dernière version LTS de Java). Pour l'installer, jetez un œil à notre tutoriel sur la configuration de Java sur Ubuntu 18.04.
- Nginx avec les configurations appropriées. Vous pouvez suivre notre guide pour installer Nginx sur Ubuntu 18.04 pour le configurer.
Notez que la quantité de stockage dépend du nombre de journaux à collecter et à stocker. De plus, The Elastic Stack traite également des informations précieuses sur le serveur. Pour sécuriser la transmission des données, nous vous recommandons vivement de configurer un certificat TLS/SSL. Suivez ce tutoriel pour obtenir un certificat SSL gratuit sur votre serveur Nginx.
En plus d'un serveur chiffré, les étapes suivantes vont également être nécessaires :
- Un FQDN (nom de domaine entièrement qualifié). Dans ce guide, ce sera <domain>.
- Les deux enregistrements DNS des domaines suivants pointent vers le serveur.
- Un enregistrement A avec <domain> pointant vers l'adresse IP publique du serveur.
- Un enregistrement A avec www.<domain> pointant vers l'adresse IP publique du serveur.
Installation de The Elastic Stack
-
Configuration du dépôt Elastic
Les composants de The Elastic Stack ne sont pas disponibles directement depuis le dépôt officiel d'Ubuntu. Heureusement, Ubuntu autorise les dépôts de 3ème partie pour installer des paquets. Pour notre objectif, nous allons ajouter le dépôt de paquets Elastic. Le dépôt propose toutes les dernières mises à jour de tous les paquets Elastic. Tous les paquets Elastic sont signés avec la clé de signature Elasticsearch pour éviter l'usurpation de paquets. Tout d'abord, ajoutez la clé au trousseau de clés d'Ubuntu :
|
1 |
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - |
Ensuite, ajoutez la liste des sources Elastic sous le répertoire « sources.list.d ». C'est le répertoire dédié que APT utilise pour rechercher de nouvelles sources :
|
1 |
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list |
Enfin, mettez à jour le cache APT :
|
1 |
sudo apt update |
Selon la documentation officielle, il est recommandé d'installer chacun des composants dans l'ordre présenté dans ce guide. Cela garantit que les composants dont dépend chaque produit sont au bon endroit.
-
Installation et configuration d'Elasticsearch
Une fois le dépôt Elastic configuré, APT is prêt à télécharger et installer tous les paquets Elastic. Exécutez la commande suivante pour installer Elasticsearch :
|
1 |
sudo apt install elasticsearch |
Vous pouvez maintenant configurer Elasticsearch. Le fichier « elasticsearch.yml » fournit des options de configuration concernant les clusters, les nœuds, les chemins, les réseaux, la mémoire, la passerelle, etc. La plupart d'entre elles sont préconfigurées dans le fichier. Ensuite, ouvrez le fichier de configuration d'Elasticsearch avec l'éditeur de texte de votre choix :
|
1 |
sudo vim /etc/elasticsearch/elasticsearch.yml |
Elasticsearch écoute sur le port 9200 depuis n'importe où. Nous vous recommandons de restreindre l'accès externe à Elasticsearch afin d'empêcher des personnes extérieures de lire les données ou d'arrêter les clusters Elasticsearch à l'aide de son API REST. Pour restreindre l'accès à Elasticsearch et renforcer sa sécurité, décommentez la ligne suivante et remplacez sa valeur :
|
1 |
network.host: localhost |
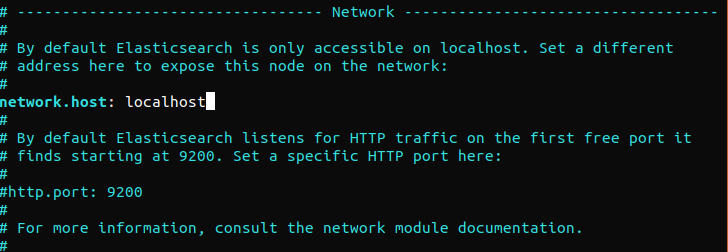
Si Elasticsearch doit écouter une adresse IP spécifique, remplacez « localhost » par l'adresse IP cible. Il s'agit de la configuration minimale requise avant d'exécuter Elasticsearch. Enregistrez et fermez le fichier de configuration. Ensuite, démarrez le service Elasticsearch. Le démarrage d'Elasticsearch peut prendre quelques instants :
|
1 |
sudo systemctl start elasticsearch |
Après cela, vous devez vous assurer qu'Elasticsearch démarre à chaque démarrage du serveur :
|
1 |
sudo systemctl enable elasticsearch |
La commande suivante permettra de vérifier si le service Elasticsearch est en cours d'exécution. Il suffit pour cela d'envoyer une requête HTTP :
|
1 |
curl -X GET "localhost:9200" |
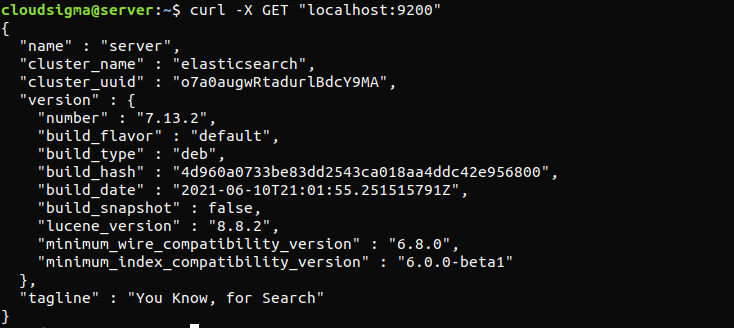
La réponse ressemblera à ceci. Il s'agira d'une réponse affichant quelques informations de base sur le nœud local.
Installation et configuration du tableau de bord Kibana
Kibana est directement disponible depuis le dépôt Elastic. Notez que vous ne devez installer Kibana qu'après avoir déjà installé Elasticsearch. En supposant que le dépôt soit déjà disponible, APT peut directement récupérer et installer Kibana :
|
1 |
sudo apt install kibana |
Une fois installé, activez et démarrez le service Kibana :
|
1 2 |
sudo systemctl enable kibana sudo systemctl start kibana |
Par défaut, Kibana est configuré pour écouter uniquement « localhost ». Pour un accès externe, il nécessite la configuration d'un proxy inverse. Ici, Nginx sera le proxy inverse. Utilisez la commande openssl pour créer un utilisateur administrateur Kibana. Il s'agira du compte utilisateur permettant d'accéder à l'interface web de Kibana. Ici, l'exemple de nom d'utilisateur sera « kibana_admin ». Pour garantir une meilleure sécurité, nous vous recommandons d'utiliser un nom d'utilisateur non standard. La commande suivante créera un utilisateur administrateur pour Kibana. Le nom d'utilisateur et le mot de passe seront générés et stockés dans le fichier « htpasswd.users ». Nginx devra être configuré pour utiliser ce nom d'utilisateur et ce mot de passe :
|
1 |
echo "kibana_admin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users |
Saisissez et confirmez un mot de passe à l'invite. Ce mot de passe sera important pour accéder à l'interface Kibana. Après cela, vous devez créer un fichier de bloc de serveur Nginx. Pour la démonstration, ce sera example.com. Il peut également s'agir de tout autre nom descriptif. Si des enregistrements FQDN et DNS sont configurés pour le serveur, le nom du fichier peut également correspondre au FQDN :
|
1 |
sudo vim /etc/nginx/sites-available/example.com |
S'il y a du contenu préexistant, supprimez-le et remplacez-le par les lignes de code suivantes :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
server { listen 80; server_name example.com; auth_basic "Accès restreint"; auth_basic_user_file /etc/nginx/htpasswd.users; location / { proxy_pass http://localhost:5601; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } } |
Enregistrez et fermez le fichier. Créez un lien symbolique de la nouvelle configuration sous le répertoire « sites-enabled ». S'il existe déjà un lien avec le même nom de fichier, cette étape n'est peut-être pas nécessaire :
|
1 |
sudo ln -s /etc/nginx/sites-available/example.com /etc/nginx/sites-enabled/example.com |
La commande suivante invitera Nginx à vérifier s'il y a des erreurs de syntaxe :
|
1 |
sudo nginx -t |
S'il y a un problème de syntaxe, assurez-vous que le contenu du fichier a été correctement placé. Ensuite, redémarrez le service Nginx :
|
1 |
sudo systemctl restart nginx |
Indiquez à UFW d'autoriser la connexion à Nginx :
|
1 |
sudo ufw allow 'Nginx Full' |
Kibana devrait maintenant être accessible via le FQDN ou l'adresse IP publique du serveur Elastic Stack. Vérifiez la page d'état du serveur Kibana :
|
1 |
http://<server_ip>:5601/status |
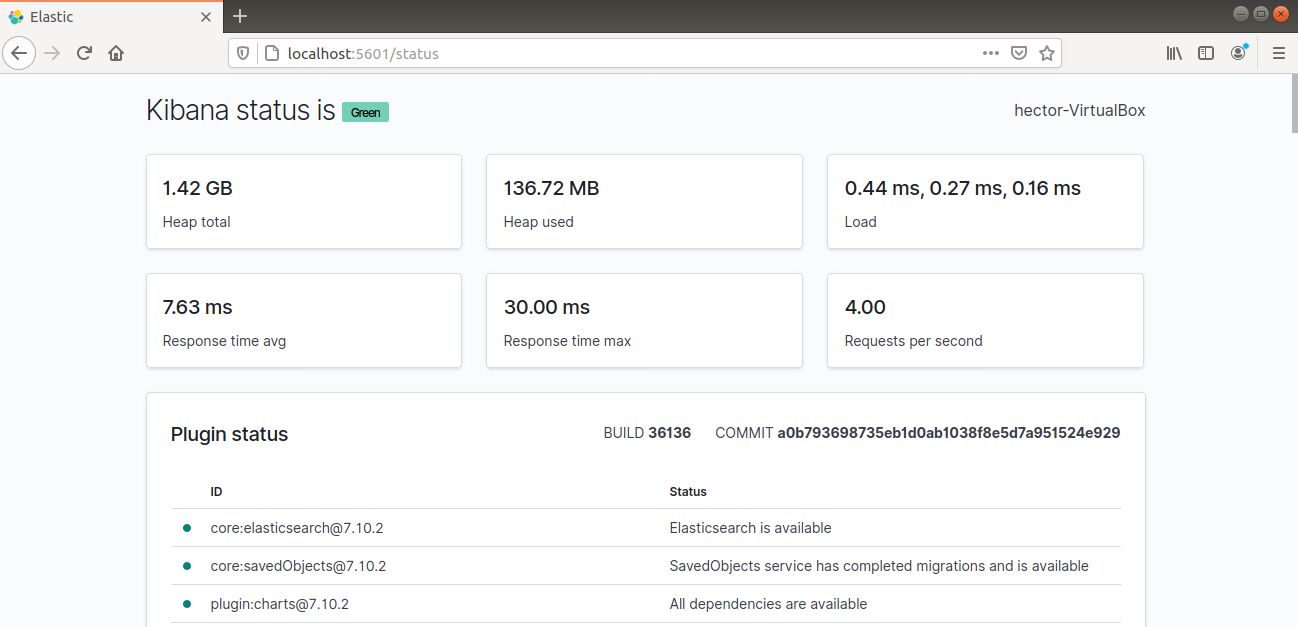
Installation et configuration de Logstash
Bien que Beats puisse envoyer directement des données à la base de données d'Elasticsearch’s, il est recommandé d'utiliser Logstash pour traiter les données. Logstash peut collecter les données et les convertir dans un format commun avant de les exporter vers une autre base de données. Exécutez la commande APT suivante pour installer Logstash :
|
1 |
sudo apt install logstash |
Une fois l'installation terminée, il est temps de configurer Logstash. Les fichiers de configuration de Logstash sont au format JSON. Vous pouvez tous les trouver dans le répertoire « /etc/logstash/conf.d ». Il est utile de voir Logstash comme un pipeline, recevant des données à une extrémité, les traitant et les envoyant vers la destination. Un pipeline Logstash nécessite deux éléments obligatoires – input et output avec un élément facultatif – filter. Le plugin input reçoit les données, le filter plugin traite les données, et le output plugin écrit les données vers la destination. La commande suivante créera un fichier de configuration qui configurera Logstash pour l'entrée Filebeat :
|
1 |
sudo vim /etc/logstash/conf.d/02-beats-input.conf |
Saisissez la configuration input suivante. Elle décrit une entrée beats qui écoutera sur le port 5044 en TCP :
|
1 2 3 4 5 |
input { beats { port => 5044 } } |
L'étape suivante consiste à créer un fichier de configuration nommé « 10-syslog-filter.conf ». Nous l'utiliserons pour définir un filtre pour les syslogs (journaux système) :
|
1 |
sudo vim /etc/logstash/conf.d/10-syslog-filter.conf |
Saisissez le code de configuration syslog suivant. Ce code est disponible directement depuis le guide Elastic. Ce code explique la configuration input de Logstash :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
input{ beats{ port => 5044 host => "0.0.0.0" } } filter { if [fileset][module] == "system" { if [fileset][name] == "auth" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} pour (utilisateur invalide )?%{DATA:[system][auth][user]} de %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} utilisateur %{DATA:[system][auth][user]} de %{IPORHOST:[system][auth][ssh][ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: N'a pas reçu de chaîne d'identification de %{IPORHOST:[system][auth][ssh][dropped_ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] } pattern_definitions => { "GREEDYMULTILINE"=> "(.|\n)*" } remove_field => "message" } date { match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } geoip { source => "[system][auth][ssh][ip]" target => "[system][auth][ssh][geoip]" } } else if [fileset][name] == "syslog" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] } pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" } remove_field => "message" } date { match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } } } } |
Le fichier de configuration suivant va traiter de la sortie. Ouvrez un nouveau fichier nommé « 30-elasticsearch-output.conf » :
|
1 |
sudo vim /etc/logstash/conf.d/30-elasticsearch-output.conf |
Saisissez le code suivant. Ce code explique la configuration de sortie pour Logstash :
|
1 2 3 4 5 6 7 |
output { elasticsearch { hosts => ["localhost:9200"] manage_template => false index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" } } |
Testez la configuration de Logstash. Ensuite, exécutez la commande suivante :
|
1 |
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t |
S'il n'y a pas d'erreur, Logstash affichera le message de réussite suivant. Si cela n'a pas fonctionné, assurez-vous que tous les fichiers de configuration contiennent les codes appropriés. Enfin, démarrez et activez le service Logstash :
|
1 2 |
sudo systemctl start logstash sudo systemctl enable logstash |
Maintenant que Logstash fonctionne correctement et est entièrement configuré, installons Filebeat.
Installation et configuration de Filebeat
La suite Elastic utilise des agents d'expédition de données, appelés « Beats », pour collecter des données à partir de diverses sources et les transporter vers Logstash/Elasticsearch. Voici une liste restreinte des Beats disponibles chez Elastic :
- Filebeat : collecte/expédition de fichiers journaux.
- Metricbeat : collecte/expédition de métriques à partir de systèmes et de services.
- Packetbeat : collecte/analyse de données réseau.
- Winlogbeat : collecte de journaux d'événements Windows.
- Auditbeat : collecte de données du framework d'audit Linux et surveillance de l'intégrité des fichiers.
- Heartbeat : surveillance de la disponibilité des services.
Pour les besoins de ce tutoriel, nous aurons besoin de Filebeat pour envoyer les journaux locaux vers la suite Elastic. Tout d'abord, installez Filebeat :
|
1 |
sudo apt install filebeat |
Vous pouvez maintenant configurer Filebeat. Tout d'abord, il doit se connecter à Logstash. Nous utiliserons l'exemple de configuration fourni avec Filebeat. Ouvrez le fichier de configuration dans un éditeur de texte. Notez que le fichier étant au format YAML, une indentation correcte est importante :
|
1 |
sudo vim /etc/filebeat/filebeat.yml |
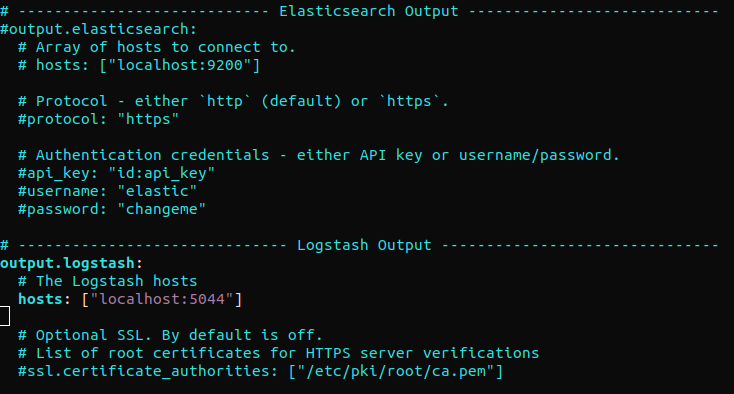
Recherchez la section « output.elasticsearch » et commentez les lignes suivantes. Cela configurera Filebeat pour envoyer directement les événements à Elasticsearch/Logstash pour un traitement supplémentaire. Ensuite, passez à la section « output.logstash ». Puis, décommentez les lignes :
|
1 2 3 4 5 6 7 |
#output.elasticsearch: # Tableau d'hôtes auxquels se connecter. # hosts: ["localhost:9200"] output.logstash: # Les hôtes Logstash hosts: ["localhost:5044"] |
Filebeat prend en charge les modules qui peuvent étendre ses fonctionnalités. Dans ce tutoriel, nous utiliserons le module system qui collecte et analyse les journaux générés par le service de journalisation système des distributions Linux courantes. Activez le module system de Filebeat :
|
1 |
sudo filebeat modules enable system |
La commande Filebeat suivante listera tous les modules activés et désactivés :
|
1 |
sudo filebeat modules list |
Par défaut, Filebeat est configuré pour suivre les chemins par défaut pour les journaux syslog et d'autorisation. Les paramètres des modules sont disponibles dans le fichier de configuration « /etc/filebeat/modules.d/system.yml ».
L'étape suivante consiste à charger le modèle d'index dans Elasticsearch. Un index Elasticsearch désigne une collection de documents partageant des caractéristiques similaires. Chaque index possède un nom. Ce nom est nécessaire pour effectuer diverses opérations en son sein. Le modèle d'index est automatiquement appliqué chaque fois qu'un nouvel index est généré. Ensuite, chargez le modèle :
|
1 |
sudo filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]' |
Filebeat contient par défaut un exemple de tableau de bord pour Kibana. Il permet de visualiser les données Filebeat dans Kibana. Cependant, avant d'utiliser le tableau de bord, il est nécessaire de créer le modèle d'index (index pattern) et de charger les tableaux de bord dans Kibana. Pendant le chargement des tableaux de bord, Filebeat contacte Elasticsearch pour obtenir des informations sur la version. Pour charger les tableaux de bord alors que Logstash est activé, il est nécessaire de désactiver la sortie Logstash et d'activer la sortie Elasticsearch. La commande suivante fera l'affaire :
|
1 |
sudo filebeat setup -e -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601 |
Enfin, vous pouvez lancer Filebeat :
|
1 2 |
sudo systemctl start filebeat sudo systemctl enable filebeat |
Il est maintenant temps de tester la configuration de la suite Elastic (Elastic Stack). Si elle a été correctement configurée, le résultat ressemblera à ceci :
|
1 |
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty' |
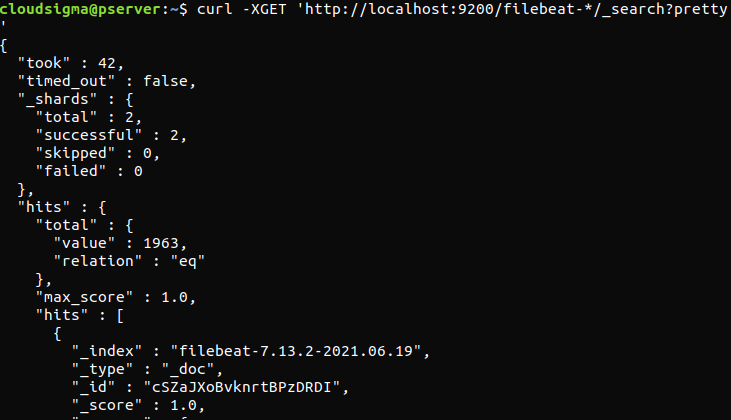
Si le résultat indique 0 résultat au total (total hits), Elasticsearch ne charge aucun journal sous l'index que nous avons recherché. Cela indique qu'il y a eu une erreur dans la configuration. Si le résultat est conforme aux attentes, alors l'Elastic Stack est configurée avec succès.
Présentation des tableaux de bord Kibana
Il est maintenant temps d'explorer l'interface web de Kibana que nous avons déjà installée. Tout d'abord, ouvrez le tableau de bord Kibana. Il devrait être accessible à l'adresse FQDN ou à l'adresse IP publique du serveur Elastic Stack :
|
1 |
http://<server_ip>:5601 |
Saisissez les identifiants de connexion que nous avons générés précédemment. Une fois connecté, le tableau de bord ressemblera à ceci :
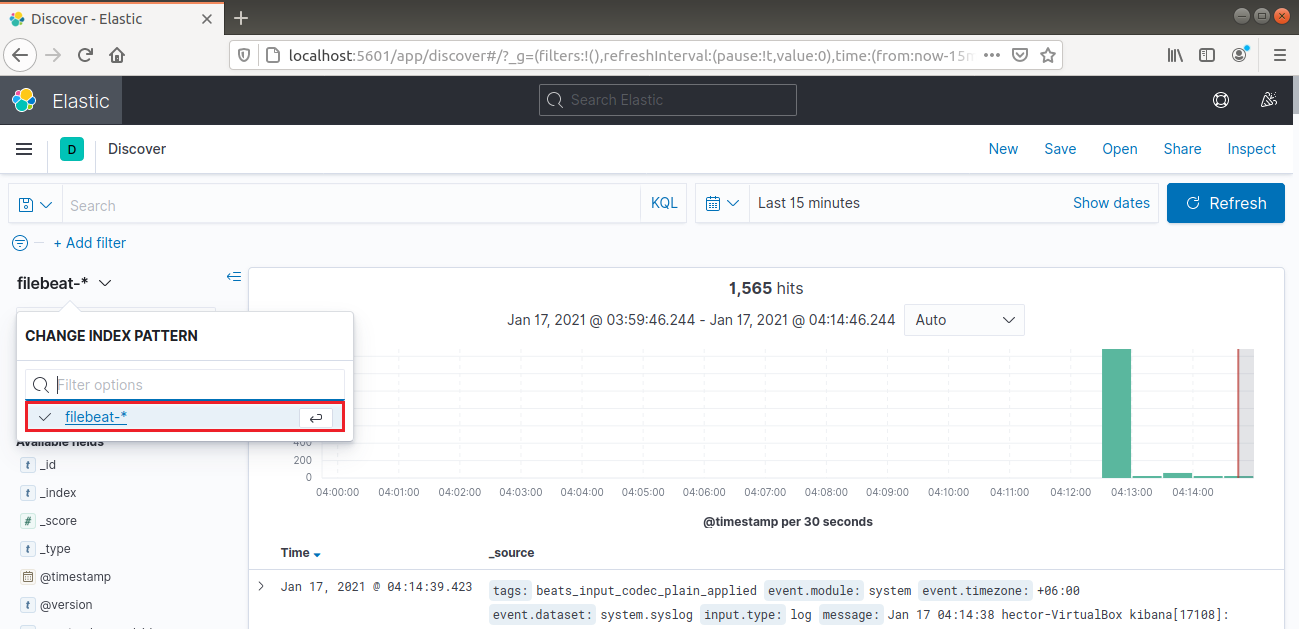
Depuis la barre de navigation de gauche, sélectionnez « Discover ». Ensuite, sélectionnez le motif « filebeat-* ». Il affiche tous les journaux collectés au cours des 15 dernières minutes. Il est possible de rechercher et de parcourir les journaux et de personnaliser le tableau de bord :
Depuis la barre de navigation de gauche, allez dans Dashboard >> Filebeat System. Ici, tous les exemples de tableaux de bord du module système de Filebeat sont disponibles.
Dans l'exemple suivant, il détaille diverses statistiques basées sur les messages syslog :
Il peut également signaler quels utilisateurs ont exécuté des commandes avec sudo :
Enfin, Kibana vous donne l'opportunité d'explorer de nombreuses autres fonctionnalités telles que la création de graphiques et le filtrage, alors n'hésitez pas à explorer par vous-même.
Réflexions finales
L'Elastic Stack est une solution puissante pour analyser les journaux système. Gardez à l'esprit que bien que tout journal ou donnée indexée puisse être envoyé à Logstash en utilisant Beats, cela devient plus utile lorsqu'il est analysé et structuré via les filtres Logstash.
Bonne informatique !
Commentaires
Aucun commentaire pour l'instant. Soyez le premier.