

Ce tutoriel vous guidera dans la configuration d'un Kubernetes cluster à partir de zéro en utilisant Ansible et Kubeadm et en déployant ensuite une application Nginx conteneurisée avec celle-ci.
Introduction
Kubernetes (également connu sous le nom de k8s ou “kube”) est une plateforme d'orchestration de conteneurs open-source qui automatise de nombreux processus manuels impliqués dans le déploiement, la gestion et la mise à l'échelle d'applications conteneurisées. Kubernetes dispose d'une communauté open-source en croissance rapide, qui contribue activement au projet. Jetez un œil à notre article de blog qui vous présentera tout ce que vous devez savoir sur les bases de la plateforme Kubernetes.
Kubeadm est un outil qui configure plusieurs éléments, parties et pièces intégrés tels que le serveur API, le Controller Manager et Kube DNS. Il aide également à automatiser l'installation. Cependant, il ne crée pas d'utilisateurs et ne gère pas l'installation des dépendances au niveau du système d'exploitation et leur configuration, et ne peut pas provisionner votre infrastructure.
Ansible est un outil open-source pour le provisionnement de logiciels et le déploiement d'applications. Saltstack est un logiciel open-source pour l'automatisation des technologies de l'information pilotée par les événements. Ce sont les deux outils qui rendent la création de clusters supplémentaires ou la recréation de clusters existants moins vulnérables aux erreurs et peuvent être utilisés pour ces tâches préliminaires.
Objectifs :
Votre cluster comprendra les ressources physiques suivantes :
1. Un nœud maître :
Un nœud maître est un nœud qui contrôle et gère un ensemble de nœuds de travail (runtime des charges de travail) et ressemble à un cluster dans Kubernetes. Il détient également le plan de ressources du nœud pour déterminer l'action appropriée pour l'événement déclenché. Il exécute etcd, un magasin clé-valeur distribué open-source utilisé pour stocker et gérer les données du cluster parmi les composants qui planifient les charges de travail sur les nœuds de travail.
Par exemple, le planificateur déterminerait quel nœud de travail hébergera un POD nouvellement planifié.
2. Deux nœuds de travail :
Les nœuds de travail sont les nœuds qui poursuivent le travail qui leur est assigné même si le nœud maître tombe en panne une fois la planification terminée. Les nœuds de travail sont les serveurs sur lesquels vos charges de travail (c'est-à-dire les applications et services conteneurisés) s'exécuteront. Vous pouvez également augmenter la capacité du cluster en ajoutant des travailleurs.
Une fois ce tutoriel terminé, vous disposerez d'un cluster entièrement fonctionnel prêt à exécuter des charges de travail (c'est-à-dire des applications et services conteneurisés) en supposant que les serveurs du cluster disposent de ressources CPU et RAM suffisantes pour que vos applications fonctionnent. Après avoir configuré avec succès le cluster, vous pouvez exécuter presque n'importe quelle application UNIX traditionnelle. Elle pourrait être conteneurisée sur votre cluster, y compris des applications web, des bases de données, des démons et des outils en ligne de commande.
Le cluster lui-même consommera environ 300 à 500 Mo de mémoire et 10 % de CPU sur chaque nœud.
Prérequis :
- Vous devez disposer d'une paire de clés SSH sur votre machine Linux locale et savoir comment utiliser les clés SSH. Cependant, si vous n'avez jamais utilisé de clés SSH auparavant, vous pouvez consulter ce tutoriel pour vous aider à configurer des clés SSH sur votre machine locale.
- Trois serveurs exécutant Ubuntu 18.04 avec au moins 4 Go de RAM et 4 vCPUs chacun. Vous devriez pouvoir vous connecter en SSH à chaque serveur en tant qu'utilisateur root avec votre paire de clés SSH. Suivez ce tutoriel pour installer votre serveur Ubuntu.
- Ansible installé sur votre machine locale.
- Vous devez également être familier avec les playbooks Ansible.
- Vous devrez également savoir comment lancer un conteneur à partir d'une image Docker. Reportez-vous à “Étape 5 — Travailler avec des images Docker dans Ubuntu” dans Comment installer et utiliser Docker sur Ubuntu 18.04 si vous avez besoin d'un rappel.
Étape 1 — Configuration du répertoire de l'espace de travail et du fichier d'inventaire Ansible
Vous devez d'abord configurer Ansible sur votre machine locale. Cela vous aidera à exécuter des commandes sur votre serveur distant. Cela facilite également l'effort de déploiement manuel en l'automatisant. Pour cela, vous devrez créer un répertoire sur votre machine locale qui servira de zone de stockage numérique temporaire (Espace de travail).
Une fois que vous aurez créé un répertoire, vous créerez un hosts fichier pour stocker toutes les informations sur les adresses IP et le groupe de chaque serveur. Il vous aidera à stocker les informations d'inventaire à l'intérieur. Comme indiqué précédemment, il y aura trois serveurs, un maître et deux workers. Le serveur maître sera le maître avec une IP affichée comme master_ip. Les deux autres serveurs seront des workers et auront les IP worker_1_ip et worker_2_ip.
Vous devez créer un répertoire nommé ~/kube-cluster dans le répertoire personnel de votre machine locale et entrer dans le répertoire en utilisant la commande cd :
|
1 2 |
mkdir ~/kube-cluster cd ~/kube-cluster |
Le ~/kube-cluster répertoire servira désormais de zone de stockage numérique temporaire (espace de travail) à l'intérieur de laquelle vous exécuterez toutes les commandes locales pour créer un cluster Kubernetes à l'aide de kubeadm. Le répertoire contiendra tous vos playbooks Ansible et sera utilisé pour le reste du tutoriel.
Création du fichier Hosts
Créez un fichier nommé ~/kube-cluster/hosts en utilisant nano ou votre éditeur de texte préféré :
|
1 |
nano ~/kube-cluster/hosts |
Vous devez maintenant ajouter le texte suivant, qui spécifiera les informations sur la structure logique de votre cluster :
|
1 2 3 4 5 6 7 8 9 |
[masters] master ansible_host=master_ip ansible_user=root [workers] worker1 ansible_host=worker_1_ip ansible_user=root worker2 ansible_host=worker_2_ip ansible_user=root [all:vars] ansible_python_interpreter=/usr/bin/python3 |
Comme mentionné, ce fichier d'inventaire vous aidera à stocker toutes les informations sur les adresses IP de vos serveurs et les groupes auxquels chaque serveur appartient. ~/kube-cluster/hosts sera votre fichier d'inventaire et (masters et workers) seront les deux groupes Ansible que vous y avez ajoutés pour spécifier la structure logique de votre cluster.
Le Master est le groupe qui spécifie qu'Ansible doit exécuter des commandes distantes en tant qu'utilisateur root. Il répertorie également l'IP du nœud maître (master_ip) qui peut être répertoriée par l'entrée de serveur nommée “master”. De même, le groupe Workers dispose de deux entrées pour les serveurs workers (worker_1_ip et worker_2_ip) qui spécifient également l' ansible_user en tant que root.
La dernière ligne du fichier indique à Ansible d'utiliser les interpréteurs Python 3 des serveurs distants pour ses opérations de gestion. Enfin, vous devez enregistrer et fermer le fichier après avoir ajouté le texte. Après avoir configuré le répertoire de l'espace de travail et le fichier d'inventaire Ansible, passons à l'étape suivante consistant à installer les dépendances au niveau du système d'exploitation et à créer les paramètres de configuration.
Étape 2 — Création d'un utilisateur non-root sur tous les serveurs distants
Dans cette étape, vous apprendrez à créer un utilisateur non-root avec des privilèges sudo sur tous les serveurs afin de pouvoir vous y connecter en SSH manuellement en tant qu'utilisateur non privilégié.
Cela peut être utile pour les opérations fréquemment effectuées pour la préservation d'un cluster. De plus, cette étape vous aidera à accomplir la tâche de manière plus précise et moins sujette aux erreurs, réduisant ainsi les risques de modification ou de suppression involontaire de fichiers importants. Si vous souhaitez modifier la configuration de fichiers appartenant à root ou voir les informations système avec des commandes telles que top/htop et afficher une liste des conteneurs en cours d'exécution, l'étape suivante vous aidera à effectuer toutes ces tâches.
Création du playbook
Créez un fichier nommé ~/kube-cluster/initial.yml dans l'espace de travail :
|
1 |
nano ~/kube-cluster/initial.yml |
Ensuite, vous devez ajouter le play suivant. Un play dans Ansible est une collection d'étapes à exécuter qui ciblent des serveurs et des groupes spécifiques. Un playbook peut contenir un ou plusieurs plays.
Le play suivant créera un utilisateur sudo non-root :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
- hosts: all become: yes tasks: - name: créer l' 'ubuntu' utilisateur user: name=ubuntu append=yes state=present createhome=yes shell=/bin/bash - name: autoriser 'ubuntu' à avoir sans mot de passe sudo lineinfile: dest: /etc/sudoers line: 'ubuntu ALL=(ALL) NOPASSWD: ALL' validate: 'visudo -cf %s' - name: configurer les clés autorisées pour l'ubuntu utilisateur authorized_key: user=ubuntu key="{{item}}" with_file: - ~/.ssh/id_rsa.pub |
Voici une description de ce que fait notre playbook :
- Ce playbook va créer l'utilisateur non-root
ubuntu. - Comme vous devez exécuter des commandes
sudosans invite de mot de passe, ce play va configurer le fichiersudoerspour permettre à l'utilisateurubuntude le faire. - Le but principal de la tâche ci-dessus était de vous permettre de vous connecter en SSH à chaque serveur en tant qu'utilisateur
ubuntu. Ce playbook ajoute la clé publique de votre machine locale (généralement~/.ssh/id_rsa.pub) à l’utilisateur distantubuntudans sa liste de clés autorisées.
Maintenant, après avoir ajouté le texte, vous devez enregistrer et fermer le fichier.
Exécution du playbook
Après cela, nous devons exécuter notre playbook qui va créer l'utilisateur non-root ubuntu en l'exécutant simplement sur les machines locales :
|
1 |
ansible-playbook -i hosts ~/kube-cluster/initial.yml |
L'exécution de cette commande prendra un certain temps, après quoi vous verrez la sortie suivante :
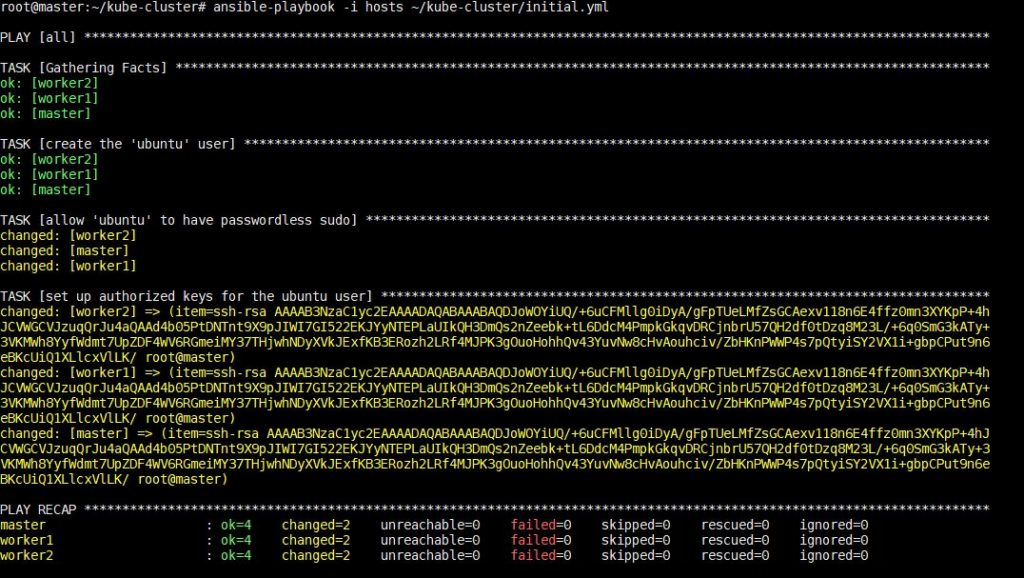
Une fois cette étape terminée, vous pourrez passer à l'installation des dépendances spécifiques à Kubernetes à l'étape suivante.
Étape 3 — Installation des dépendances de Kubernetes
Dans cette étape, vous apprendrez à installer les paquets au niveau du système d'exploitation requis par Kubernetes avec le gestionnaire de paquets d’Ubuntu.
Ces paquets sont :
- Docker : Docker est une plateforme et un outil pour construire, distribuer et exécuter des conteneurs Docker. Vous pouvez facilement configurer Docker en suivant notre tutoriel sur comment installer & utiliser Docker sur Ubuntu dans le cloud public. Cependant, la prise en charge d'autres runtimes tels que rkt est en cours de développement actif dans Kubernetes.
Kubeadm: kubeadm est un outil CLI qui effectue les actions nécessaires pour mettre en place et faire fonctionner un cluster minimal viable. Cela vous aidera à installer et à construire divers composants du cluster de manière standard.kubelet: Le kubelet est l'« agent de nœud » principal qui s'exécute sur chaque nœud et gère les opérations au niveau du nœud.kubectl: kubectl est également un outil CLI qui communique avec votre cluster et émet des commandes via son serveur d'API.
Création du playbook
Créez un fichier nommé ~/kube-cluster/kube-dependencies.yml dans l'espace de travail :
|
1 |
nano ~/kube-cluster/kube-dependencies.yml |
Maintenant, vous devez ajouter les plays suivants au fichier pour installer ces paquets sur vos serveurs :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
- hosts: all become: yes tasks: - name: installer Docker apt: name: docker.io state: present update_cache: true - name: installer APT Transport HTTPS apt: name: apt-transport-https state: present - name: ajouter la clé apt de Kubernetesapt-key apt_key: url: https://packages.cloud.google.com/apt/doc/apt-key.gpg validate_certs: false state: present - name: ajouter le dépôt APT de Kubernetes' APT repository apt_repository: repo: deb http://apt.kubernetes.io/ kubernetes-xenial main state: present filename: 'kubernetes' - name: installer kubelet apt: name: kubelet=1.16.0-00 state: present update_cache: true - name: installer kubeadm apt: name: kubeadm=1.16.0-00 state: present - hosts: master become: yes tasks: - name: installer kubectl apt: name: kubectl=1.16.0-00 state: present force: yes |
Le premier play du playbook fait ce qui suit :
- Ce play vous aidera à installer des paquets au niveau du système d'exploitation, Docker – le moteur d'exécution de conteneurs.
- Il installe
apt-transport-https, ce qui vous permet d'ajouter des sources HTTPS externes à votre liste de sources APT. - Ajoute la clé apt du dépôt APT de Kubernetes pour la vérification des clés.
- Ajoute le dépôt APT de Kubernetes à la liste des sources APT de vos serveurs distants.
- Installe
kubeletetkubeadm.
Le second play effectue une tâche importante et unique qui consiste à installer kubectl sur votre nœud maître. Maintenant, après avoir ajouté le texte, vous devez enregistrer et fermer le fichier.
Exécution du playbook
Après cela, nous devons exécuter notre playbook en le lançant simplement sur les machines locales :
|
1 |
ansible-playbook -i hosts ~/kube-cluster/kube-dependencies.yml |
L'exécution de cette commande prendra un certain temps, après quoi vous verrez la sortie suivante :
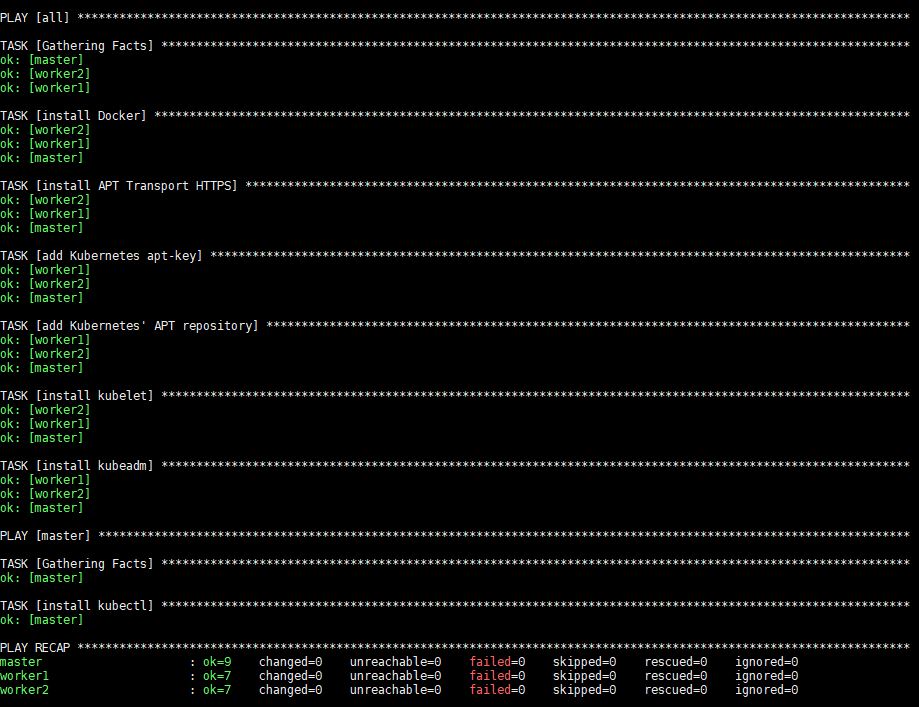
Après l'exécution, Docker, kubeadm et kubelet seront installés sur tous les serveurs distants. Kubectl n'est pas un composant requis et n'est nécessaire que pour exécuter des commandes de cluster. L'installer uniquement sur le nœud maître est logique dans ce contexte puisque vous exécuterez les commandes kubectl uniquement depuis le maître. Notez cependant que kubectl les commandes peuvent être exécutées depuis n'importe quel nœud de travail ou depuis n'importe quelle machine où elles peuvent être installées et configurées pour pointer vers un cluster.
Toutes les dépendances système sont maintenant installées. Configurons le nœud maître et initialisons le cluster.
Étape 4 — Configuration du nœud maître
Dans cette étape, vous découvrirez quelques concepts tels que les Pods et les plug-ins de réseau de Pods puisque votre cluster inclura les deux une fois que vous aurez configuré votre nœud maître.
Les Pods sont les objets déployables les plus petits et les plus basiques de Kubernetes. Les Pods contiennent un ou plusieurs conteneurs, tels que des conteneurs Docker. Lorsqu'un Pod exécute plusieurs conteneurs, les conteneurs sont gérés comme une seule entité et partagent les ressources du Pod’.
Chaque pod possède sa propre adresse IP, et un pod sur un nœud doit pouvoir accéder à un pod sur un autre nœud en utilisant l'adresse IP du pod’. Cependant, la communication entre les pods est plus complexe. Elle nécessite un composant distinct capable d'acheminer de manière transparente le trafic d'un pod sur un nœud vers un pod sur un autre. Les plug-ins de réseau de pods sont utilisés pour cette fonctionnalité. De nombreux plug-ins de réseau de pods sont disponibles, mais nous utiliserons Flannel car c'est une option stable et efficace.
Création du Playbook
Créez un playbook Ansible nommé master.yml sur votre machine locale :
|
1 |
nano ~/kube-cluster/master.yml |
De plus, vous devez ajouter le play suivant au fichier pour initialiser le cluster et installer Flannel :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
- hosts: master become: yes tasks: - name: initialiser le cluster shell: kubeadm init --pod-network-cidr=10.244.0.0/16 >> cluster_initialized.txt args: chdir: $HOME creates: cluster_initialized.txt become: yes become_user: root - name: créer le .répertoire kubedirectory become: yes become_user: ubuntu file: path: $HOME/.kube state: directory mode: 0755 - name: copier admin.conf vers la configuration 'kube de l'utilisateur copy: src: /etc/kubernetes/admin.conf dest: /home/ubuntu/.kube/config remote_src: yes owner: ubuntu - name: installer le réseau de Pods become: yes become_user: ubuntu shell: kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/2140ac876ef134e0ed5af15c65e414cf26827915/Documentation/kube-flannel.yml >> pod_network_setup.txt args: chdir: $HOME creates: pod_network_setup.txt |
Voici le détail de ce play :
- La première tâche de ce play configurera le cluster en exécutant
kubeadm init. Pour spécifier le sous-réseau privé auquel les adresses IP des pods seront attribuées, nous passons l'argument--pod-network-cidr=10.244.0.0/16. Flannel utilise le sous-réseau ci-dessus par défaut. Nous l'utilisons pour indiquer àkubeadmd'utiliser le même sous-réseau. - La deuxième tâche sert à créer un répertoire
.kubedans/home/ubuntuLes informations de configuration telles que les fichiers de clés d'administration, nécessaires pour se connecter au cluster et l’adresse de l’API du cluster, seront conservées dans ce répertoire. - La troisième tâche sert à copier le fichier
/etc/kubernetes/admin.confgénéré parkubeadm initvers le répertoire personnel de votre utilisateur non-root. Cela vous permettra d'utiliserkubectlpour accéder au cluster nouvellement créé. - La dernière tâche exécute
kubectl applypour installerFlannel.kubectl apply -f descriptor.[yml|json]est la syntaxe pour indiquer àkubectlde créer les objets décrits dans le fichierdescriptor.[yml|json]. Le fichierkube-flannel.ymlcontient les descriptions des objets requis pour configurerFlanneldans le cluster.
Maintenant, après avoir ajouté le texte, vous devez enregistrer et fermer le fichier.
Exécution du Playbook
Après cela, vous devez exécuter notre playbook en le lançant simplement sur les machines locales :
|
1 |
ansible-playbook -i hosts ~/kube-cluster/master.yml |
L’exécution de cette commande prendra un certain temps, après quoi vous verrez la sortie suivante :
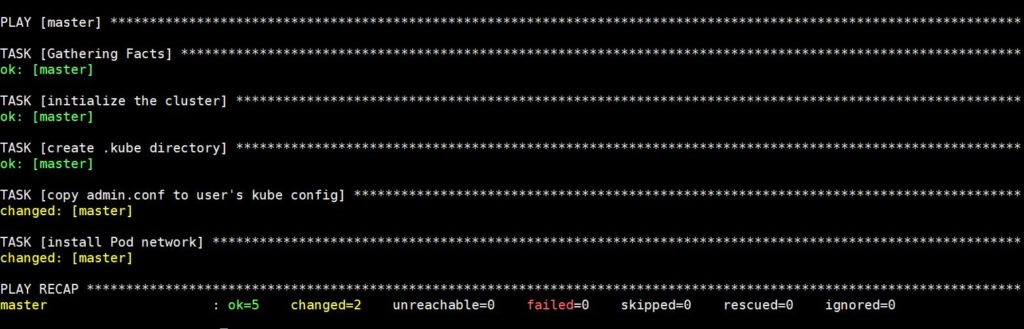
Connectez-vous maintenant en SSH avec la commande suivante pour vérifier l'état du nœud maître :
|
1 |
ssh ubuntu@master_ip |
Une fois à l'intérieur du nœud maître, exécutez :
|
1 |
kubectl get nodes |
Vous verrez maintenant la sortie suivante :

En obtenant la sortie ci-dessus, vous pouvez affirmer que toutes les tâches de configuration ont été accomplies par le nœud maître et qu'il peut commencer à accepter des nœuds de travail (workers) et à exécuter des tâches lorsqu'il passe à l'état Ready. Vous pouvez maintenant ajouter les workers depuis votre machine locale.
Étape 5 — Configuration des nœuds de travail (Worker Nodes)
Après avoir configuré le nœud maître, nous pouvons passer à l'étape suivante de configuration des nœuds de travail. L'ajout de nœuds de travail au cluster peut se faire simplement en exécutant une seule commande sur chaque serveur de travail. Les informations importantes telles que l'adresse IP, le port du serveur API du maître et un jeton sécurisé sont incluses dans cette commande. Notez toutefois que tous les nœuds ne pourront pas rejoindre le cluster, seuls les nœuds qui transmettent le jeton sécurisé pourront le faire.
Création du playbook
Cette commande vous aidera à revenir à votre espace de travail et à créer un playbook nommé workers.yml:
|
1 |
nano ~/kube-cluster/workers.yml |
Ajoutez le texte suivant au fichier pour ajouter les workers au cluster :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
- hosts: master become: yes gather_facts: false tasks: - name: obtenir la commande de jonction shell: kubeadm token create --print-join-command register: join_command_raw - name: définir la commande de jonction set_fact: join_command: "{{ join_command_raw.stdout_lines[0] }}" - hosts: workers become: yes tasks: - name: rejoindre le cluster shell: "{{ hostvars['master'].join_command }} >> node_joined.txt" args: chdir: $HOME creates: node_joined.txt |
Voici ce que fait le playbook. Il y a deux plays dans le code ci-dessus :
- Le premier play sert à obtenir la commande de jonction qui doit être exécutée sur les nœuds workers. Le format de la commande sera :
kubeadm join --token sha256:<hash><token><master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>;. La tâche doit obtenir les valeurs correctes de jeton (token) et de hachage (hash). Une fois qu'elle a obtenu les bonnes informations, la tâche les définit comme un fait (fact) afin que le second play puisse y accéder. - Le second play est écrit uniquement pour effectuer une tâche unique – intégrer les deux nœuds workers au cluster en exécutant simplement la commande de jonction sur tous les nœuds workers.
Après avoir ajouté le texte, vous devez enregistrer et fermer le fichier.
Exécution du playbook
Après cela, nous devons exécuter notre playbook en lançant la commande suivante sur les machines workers :
|
1 |
ansible-playbook -i hosts ~/kube-cluster/workers.yml |
L'exécution de cette commande prendra un certain temps, après quoi vous verrez la sortie suivante :
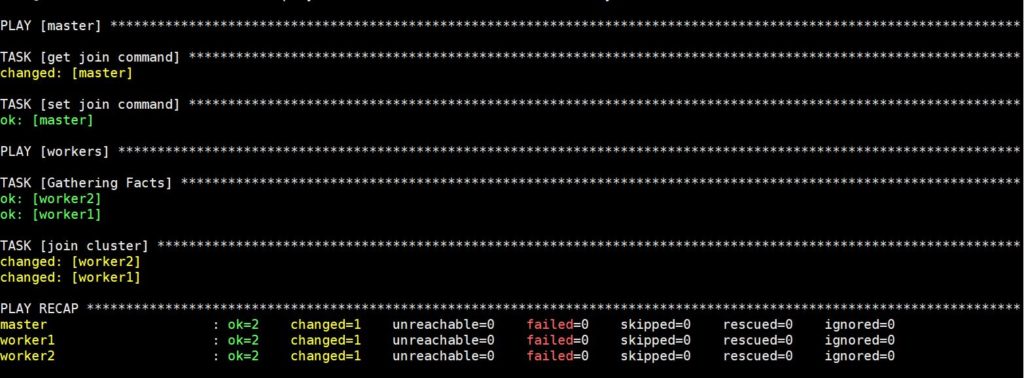
Maintenant, votre cluster Kubernetes est entièrement configuré et fonctionnel, avec les workers prêts à exécuter des charges de travail. Avant de passer à l'étape suivante, vérifions que le cluster fonctionne comme prévu.
Étape 6 — Vérification du cluster
Il peut arriver qu'un cluster échoue lors de la configuration. Cela peut être dû à une erreur réseau entre le master et le worker, ou à un problème de nœud. Nous devons donc vérifier le cluster avant de planifier des applications et nous assurer qu'aucun dysfonctionnement ne se produit. Pour cela, vous devrez vérifier l'état actuel du cluster depuis le nœud master pour vous assurer que les nœuds sont prêts. Vous pouvez rétablir la connexion avec la commande suivante si les nœuds ne sont pas prêts ou si vous êtes déconnecté :
|
1 |
ssh ubuntu@master_ip |
Utilisez les commandes suivantes pour obtenir le statut du cluster :
|
1 |
kubectl get nodes |
L'exécution de cette commande prendra un certain temps, après quoi vous verrez la sortie suivante :

Vous devez vérifier si tous les nœuds qui font partie du cluster sont à l'état prêt. Si quelques nœuds ont Not Ready comme STATUS, cela montre que les nœuds workers n’ont pas encore terminé leur configuration. Cependant, avant de réexécuter kubectl get nodes et de vérifier la sortie mise à jour, vous devriez attendre encore cinq à dix minutes. Si certains nœuds affichent toujours Not Ready comme statut, vous devriez aller vérifier les étapes précédentes et réexécuter les commandes. Ce n'est que si les nœuds ont la valeur Ready pour STATUS qu'ils font partie du cluster et sont prêts à exécuter des charges de travail. Après avoir exécuté avec succès la 6e étape, votre cluster est maintenant vérifié. Planifions maintenant un exemple d'application Nginx sur le cluster.
Étape 7 — Exécution d'une application sur le cluster
Création du déploiement
Après avoir créé le cluster avec succès, vous pouvez déployer n'importe quelle application conteneurisée sur votre cluster. Vous pouvez utiliser les commandes ci-dessous pour d'autres applications conteneurisées si vous vous trouvez dans le nœud master. Ensuite, exécutez la commande suivante pour créer un déploiement nommé nginx :
|
1 |
kubectl create deployment nginx --image=nginx |
Vous devez modifier le nom de l'image Docker et toutes les options pertinentes (telles que les ports et les volumes). Pour rester dans un cadre familier, vous pouvez déployer Nginx à l'aide de déploiements et de services pour voir comment les applications peuvent être déployées sur le cluster.
Un déploiement Kubernetes est un objet de ressource dans Kubernetes qui fournit des mises à jour déclaratives aux applications. Un déploiement permet de décrire le cycle de vie d'une application, comme l'image du conteneur, les réplicas et la stratégie de mise à jour. Un déploiement garantit que le nombre souhaité de pods est en cours d'exécution et disponible à tout moment. Si un pod plante pendant la durée de vie du cluster, il le recrée. Le processus de mise à jour est également entièrement enregistré et versionné avec des options pour mettre en pause, continuer et revenir à des versions antérieures. La commande ci-dessus pour créer un déploiement nommé Nginx vous aidera à déployer un pod avec un conteneur à partir de l'image Docker Nginx du registre Docker.
Configuration du Node Port
Ensuite, nous devons créer un NodePort. NodePort est un port ouvert sur chaque nœud de votre cluster. Kubernetes redirige de manière transparente le trafic entrant sur le NodePort vers votre service, même si votre application s'exécute sur un autre nœud. Pour cela, nous pouvons utiliser cette commande pour créer une ressource NodePort nommée Nginx qui exposera l'application publiquement :
|
1 |
kubectl expose deploy nginx --port 80 --target-port 80 --type NodePort |
Un service est un autre objet Kubernetes chargé d'exposer une interface à ces pods, ce qui permet un accès réseau soit depuis l'intérieur du cluster, soit entre des processus externes et le service. Il peut être défini comme une abstraction au-dessus du pod qui fournit une adresse IP et un nom DNS uniques par lesquels les pods peuvent être consultés. Avec un service, il est très facile de gérer la configuration de l'équilibrage de charge.
Exécutez la commande suivante :
|
1 |
kubectl get services |
Cela affichera un texte similaire au suivant :

Après avoir obtenu la sortie, Kubernetes attribuera automatiquement un port aléatoire supérieur à 30000 tout en s'assurant également que le port attribué n'est pas déjà lié par un autre service. La troisième ligne de la sortie ci-dessus vous aidera à récupérer le port sur lequel Nginx s'exécute.
Pour vérifier que cela fonctionne, visitez http://worker_1_ip:nginx_port ou http://worker_2_ip:nginx_port via un navigateur sur votre machine locale. Vous verrez la page d'accueil familière de Nginx.
Suppression du déploiement
Si vous souhaitez supprimer l'application Nginx, vous devez d'abord supprimer le service nginx depuis le nœud maître :
|
1 |
kubectl delete service nginx |
Pour vérifier que l'application est bien supprimée, vous devez exécuter cette commande :
|
1 |
kubectl get services |
Vous obtiendrez la sortie suivante :

Après cela, vous devez supprimer le déploiement à l'aide de la commande suivante :
|
1 |
kubectl delete deployment nginx |
Vous pouvez utiliser cette commande pour vérifier si le déploiement est bien supprimé :
|
1 |
kubectl get deployments |
![]()
Conclusion :
Ce tutoriel vous aidera à configurer correctement un cluster sur Ubuntu 18.04 en utilisant Kubeadm et Ansible. Maintenant que votre cluster est configuré, vous pouvez facilement commencer à déployer vos propres applications et services.
Voici une liste de liens contenant des détails supplémentaires qui vous guideront dans le processus :
- Conteneurisation d'applications avec Docker – Ce lien contient des exemples qui vous guident sur la façon de charger des applications à l'aide de Docker. Comme la conteneurisation de PostgreSQL, d'un service CouchDB, etc.
- Présentation des Pods – Ce lien présente des détails sur l'utilisation d'un pod, le fonctionnement des pods et la relation entre les pods et d'autres objets Kubernetes. Les pods sont une partie importante de Kubernetes, donc les comprendre vous aidera à réussir votre tâche.
- Présentation des déploiements – Cela vous aidera à en savoir plus sur les déploiements. Un déploiement fournit des mises à jour déclaratives pour les Pods et les ReplicaSets. Vous apprendrez à mettre à jour, déployer et annuler un déploiement.
- Présentation des services - Ce lien vous guidera à travers les services, qui sont un autre objet fréquemment utilisé dans les clusters Kubernetes. Un service dans Kubernetes est une abstraction qui définit un ensemble logique de Pods et une politique permettant d'y accéder. Comprendre les types de services et les options dont ils disposent est essentiel pour exécuter des applications avec ou sans état.
De plus, jetez un œil à nos autres tutoriels axés sur Docker et Kubernetes que vous pouvez trouver sur notre blog:
- Découvrir Kubernetes
- Nettoyer les ressources Docker – Images, conteneurs et volumes
- Comment exécuter Docker sur CloudSigma (avec CloudInit) Mis à jour
- Installation et configuration de Docker sur CentOS 7
- Comment installer & exploiter Docker sur Ubuntu dans le cloud public
Il existe également de nombreux autres concepts importants tels que Volumes, Ingresses, et Secrets que vous pouvez utiliser lors du déploiement d'applications en production.
Bonne informatique !
Commentaires
Aucun commentaire pour l'instant. Soyez le premier.