

Web scraping, le web crawling, le web harvesting ou l'extraction de données web sont des synonymes désignant l'action de collecter des données à partir de pages web sur Internet. Les web scrapers ou web crawlers sont des outils qui parcourent les pages web de manière programmatique pour en extraire les données requises. Ces données, qui se présentent généralement sous la forme de grands ensembles de textes, peuvent être utilisées à des fins d'analyse, pour comprendre des produits ou pour satisfaire sa curiosité à l'égard d'une certaine page web.
Si vous vous demandez comment procéder pour le web crawling, nous allons vous montrer les bases du web scraping à travers un ensemble de données simple. Vous devriez être en mesure de suivre ce tutoriel quel que soit votre niveau d'expertise en programmation. Pour l'exemple pratique, nous utiliserons notre blog CloudSigma. Nous essaierons d'obtenir des informations sur les tutoriels de notre page de blog. Au moment où vous lirez la conclusion de ce tutoriel, vous disposerez d'un web scraper fonctionnel conçu avec Python 3 qui parcourt plusieurs pages de notre section blog, puis affiche les données sur votre écran.
En utilisant les connaissances acquises lors de la création de ce web scraper de base, vous pourrez le perfectionner et créer vos propres web scrapers. Cela devrait être amusant, commençons !
Prérequis
Il s'agit d'un tutoriel pratique, vous devez donc disposer d'un environnement de développement local pour Python 3 pour bien le suivre. Tout d'abord, vous pouvez vous référer à notre tutoriel sur la façon d'installer Python 3 et configurer un environnement de programmation local sur Ubuntu.
Scrapy
Le web scraping comporte deux étapes : la première consiste à trouver et à télécharger des pages web, la seconde à les parcourir et à en extraire des informations.
Il existe de nombreuses façons et bibliothèques permettant de créer un web scraper à partir de zéro dans de nombreux langages de programmation. Cependant, cela peut poser des problèmes à l'avenir lorsque votre web scraper deviendra complexe, ou lorsque vous devrez parcourir plusieurs pages avec des paramètres et des modèles différents à la fois. Déterminer comment convertir vos données collectées entre différents formats tels que CSV, XML ou JSON peut s'avérer une tâche assez lourde.
Bien que certains apprécient le défi de créer leur propre web scraper à partir de zéro, il est préférable de ne pas réinventer la roue et de s'appuyer plutôt sur une bibliothèque existante qui gère tous ces problèmes. Nous utiliserons Scrapy, une bibliothèque Python, ainsi que Python 3 pour implémenter le web scraper dans ce tutoriel. Scrapy est un outil open-source et l'une des bibliothèques de web scraping Python les plus populaires et les plus puissantes. Scrapy a été conçu pour gérer certaines des fonctionnalités communes que tous les scrapers devraient avoir. De cette façon, vous n'avez pas à réinventer la roue chaque fois que vous souhaitez implémenter un web crawler. Avec Scrapy, le processus de création d'un scraper devient facile et amusant.
Scrapy est disponible sur PyPi, communément appelé pip – le Python Package Index. PyPi est un dépôt communautaire qui héberge la plupart des packages Python. Lorsque vous installez et configurez Python 3 sur votre environnement de développement local, cela installe également pip, que vous pouvez utiliser pour installer des packages Python.
Étape 1 : Comment créer un web scraper simple
Tout d'abord, pour installer Scrapy, exécutez la commande suivante :
|
1 |
pip install scrapy |
Optionnellement, vous pouvez suivre les instructions d'installation officielles de Scrapy depuis la page de documentation. Si vous avez installé Scrapy avec succès, créez un dossier pour le projet en utilisant le nom de votre choix :
|
1 |
mkdir cloudsigma-crawler |
Naviguez dans le dossier et créez le fichier principal pour le code. Ce fichier contiendra tout le code de ce tutoriel :
|
1 |
touch main.py |
Si vous souhaitez, vous pouvez créer le fichier à l'aide de votre éditeur de texte ou de votre IDE au lieu de la commande ci-dessus.
Ensuite, ouvrez le fichier et commençons par créer un scraper de base qui utilise Scrapy. Nous allons créer une classe Python qui hérite de scrapy.Spider, une classe de spider de base de Scrapy. Cette classe aura deux attributs requis définis ci-dessous :
- name — une chaîne de caractères pour identifier le spider (vous pouvez saisir le nom de votre choix).
- start_urls — un tableau contenant une liste d'URL à partir desquelles effectuer le parcours. Nous commencerons par une seule URL.
Ajoutez l'extrait de code suivant dans le fichier ouvert pour créer le spider de base :
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
Voici une explication de chaque ligne de code :
La première ligne importe Scrapy, ce qui nous permet d'utiliser les différentes classes fournies par le package.
Dans la ligne suivante, nous étendons la classe Spider fournie par Scrapy et créons une sous-classe appelée CloudSigmaCrawler. En étendant une classe (Spider), nous accédons aux propriétés de la classe que nous pouvons désormais utiliser dans notre code. Dans ce cas, la classe Spider possède des méthodes et des comportements qui définissent comment suivre les URL et extraire les données des pages web. Cependant, elle ne sait pas quelles URL suivre ni quelles données extraire. En l'étendant, nous pouvons fournir les informations requises aux méthodes. Pour en savoir plus sur le sous-classement et l'extension, lisez la suite les principes de la programmation orientée objet.
Dans notre CloudSigmaCrawler, nous définissons les attributs requis. Tout d'abord, nous nommons notre spider cloudsigma_crawler. Ensuite, nous fournissons une seule URL de départ : https://blog.cloudsigma.com/blog/. L'ouverture de cette URL vous mènera à la page 1 du blog de CloudSigma qui contient certains des nombreux tutoriels.
Il est temps de tester le scraper. Vous avez plusieurs options. Si vous utilisez un IDE, par exemple, la PyCharm community edition de JetBrains, elle est probablement fournie avec un bouton sur lequel vous pouvez simplement cliquer pour exécuter le script. Une autre option consiste à suivre la méthode classique d'exécution des fichiers Python depuis la ligne de commande : python path/to/file.py, ou py path/to/file.py. Une autre option est l'interface en ligne de commande de Scrapy. Scrapy est livré avec sa propre interface en ligne de commande pour aider à démarrer un scraper. Entrez la commande suivante pour démarrer le scraper :
|
1 |
scrapy runspider main.py |
Selon la version de la bibliothèque Scrapy que vous avez installée, vous devriez voir une sortie semblable à la suivante :
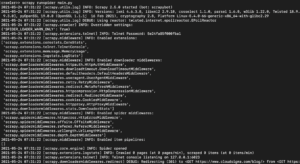
Comme vous pouvez le voir, la sortie est assez longue, nous n'avons donc sélectionné que quelques parties. Voici ce qui s'est passé lorsque vous avez exécuté la commande :
- Le scraper a été initialisé. Par conséquent, il a chargé les composants et extensions supplémentaires dont il a besoin pour suivre et lire les données des URL.
- En utilisant l'URL fournie dans la liste start_urls, il a récupéré le code HTML de la page. C'est un processus similaire à celui que suit le navigateur lors de l'ouverture de pages web.
- Après avoir récupéré le HTML, il est transmis à la méthode parse que nous n'avons pas encore définie. Pour l'instant, elle ne fait rien, le spider s'arrête donc simplement sans effectuer de traitement. Nous définirons le comportement de la méthode parse à l'étape suivante.
Étape 2 : Comment extraire des données d'une page
À l'étape 1, nous n'avons implémenté qu'un scraper de base qui récupère une page HTML mais ne fait rien ensuite. Dans cette section, nous fournirons des instructions pour extraire des données. Sur la page du CloudSigma Blog dont nous voulons extraire des données, vous pouvez remarquer certaines choses telles que :
- L'en-tête, présent sur toutes les pages.
- Le menu de navigation et la boîte de filtre de recherche.
- La liste réelle des tutoriels sous forme de grille.
L'affichage du code source de la page HTML que vous avez l'intention de scraper vous donne une idée générale de la structure de la page. Cela vous aide à écrire un scraper. Vous pouvez afficher le code source en faisant un clic droit sur la page et en sélectionnant Afficher le code source, ou en appuyant sur Ctrl + U. Voici un extrait du code source :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Lien permanent vers : "Sécuriser Apache avec Let’s Encrypt sur Ubuntu 18.04"">Sécuriser Apache avec Let’s Encrypt sur Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>La sécurité des sites web et des données sont des sujets qui ne peuvent pas être pris à la légère. Des informations hautement sensibles qui comprennent des dossiers financiers et des informations privées des clients sont toujours en transit entre l’ordinateur de l’utilisateur et votre site web. Lorsque vous considérez ce fait, il n’est pas difficile de voir pourquoi des sites non sécurisés pourraient entraîner une faille qui pourrait gravement endommager votre entreprise. Il y a … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Lire la suite</a></div> </div> </div> ... </article> </div> </body> |
Comme vous pouvez le voir, chaque tutoriel de blog est inclus dans une balise HTML appelée <article>. Le scraping de la page comportera deux étapes. La première étape consistera à récupérer chaque tutoriel de blog en examinant les parties de la page contenant les données que nous voulons. L'étape suivante consiste à extraire les données que nous voulons de chaque tutoriel identifié par la balise HTML.
Scrapy identifie les données à récupérer en fonction des sélecteurs que vous fournissez. Nous pouvons utiliser des sélecteurs pour trouver un ou plusieurs éléments sur une page et obtenir les données contenues dans ces éléments. Scrapy prend en charge les sélecteurs XPath et CSS.
D'après la source que nous avons consultée précédemment, les sélecteurs CSS semblent plus simples. C'est donc l'option que nous allons choisir car elle nous aidera à trouver tous les tutoriels de la page. Dans le code source HTML, chaque tutoriel est spécifié dans la classe CSS appelée post. Les noms de classes CSS sont généralement identifiés par .nom_classe (point nom_classe). Ainsi, nous utiliserons .post pour notre sélecteur CSS. Dans le code source de notre scraper main.py, nous allons passer la classe .post à l'objet response, de sorte que votre fichier ressemblera désormais à ceci :
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
Ce fragment de code récupérera tous les tutoriels sur la page avec les start_urls spécifiés, et bouclera à travers les tutoriels pour extraire les données. Dans l'étape suivante, vous voudrez extraire et afficher ces données. Si vous examinez à nouveau le code source du blog CloudSigma , vous verrez que le titre de chaque tutoriel est stocké dans une balise <a> qui se trouve dans une balise <h2>, par exemple :
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Lien permanent vers : "Sécuriser Apache avec Let’s Encrypt sur Ubuntu 18.04"">Sécuriser Apache avec Let’s Encrypt sur Ubuntu 18.04</a> </h2> |
Chaque objet tutoriel sur lequel nous bouclons contient une méthode CSS à laquelle nous pouvons passer un sélecteur pour localiser et extraire les éléments enfants. Pour cet exemple, nous voulons extraire le titre qui est enfermé dans la balise <a>. Cette balise se trouve à l'intérieur de la balise <h2> à l'intérieur de la classe .entry-header elle-même dans la classe .entry-wrap. Nous pouvons passer ces sélecteurs CSS à la méthode de l'objet pour extraire le titre, modifiez le code pour qu'il ressemble à ceci :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
La virgule finale après extract_first() n'est pas une faute de frappe car nous ajouterons plus de code sous cette section.
Voici quelques points à noter concernant le code source ci-dessus :
- ::text ajouté au sélecteur – il s'agit d'un pseudo-sélecteur CSS qui indique au code de récupérer le texte à l'intérieur de la balise et non la balise elle-même.
- L'appel de la méthode extract_first() au sein de l'objet – indique au code de ne choisir que le premier élément qui correspond au sélecteur. Par conséquent, nous obtenons une chaîne de caractères plutôt qu'une liste d'éléments.
Ensuite, enregistrez le fichier et exécutez le code en saisissant la commande suivante dans votre terminal :
|
1 |
scrapy runspider main.py |
Dans la sortie, vous devriez voir les titres des tutoriels :
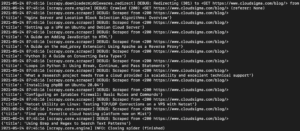
Nous pouvons continuer à développer cela en ajoutant d'autres sélecteurs pour obtenir d'autres détails sur un tutoriel, tels que l'URL du tutoriel, l'image mise en avant et la légende.
Examinons à nouveau le code HTML d'un seul tutoriel :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="Lien permanent vers : "Sécuriser Apache avec Let’s Encrypt sur Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Lien permanent vers : "Sécurisation d'Apache avec Let’s Encrypt sur Ubuntu 18.04"">Sécurisation d' Apache avec Let’s Encrypt sur Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>La sécurité des sites web et des données sont des sujets qui ne doivent pas être pris à la légère. Des informations hautement sensibles qui comprennent des dossiers financiers et des informations privées de clients sont toujours en transit entre l' ordinateur de l'utilisateur et votre site web. Compte tenu de ce fait, il n'est pas difficile de comprendre pourquoi des sites web non sécurisés pourraient entraîner une faille de sécurité susceptible de nuire gravement à votre entreprise. Il y a un … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Lire la suite</a></div> </div> </div> </article> </div> </body> |
Nous voulons essayer d'extraire les éléments mis en évidence, c'est-à-dire l'URL du tutoriel, l'image mise en avant et la légende.
- D'après l'extrait de code ci-dessus, l'image du blog est stockée dans l'attribut data-lazy-src d'une balise img à l'intérieur d'une balise <a> à l'intérieur d'une balise div au début du tutoriel du blog. Nous pouvons utiliser un sélecteur CSS pour récupérer la valeur comme nous l'avons fait avec les titres des tutoriels.
- Obtenir l'URL du tutoriel est simple, car nous avons la balise <a> à l'intérieur de l'élément <div>.
- La légende est enfermée dans la balise <p> qui se trouve à l'intérieur de la balise <div>.
Nous utiliserons les classes CSS pour obtenir ce que nous voulons. Modifions le code pour qu'il ressemble à ceci :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
Enregistrez les modifications et exécutez le code avec la commande suivante :
|
1 |
scrapy runspider main.py |
Vous verrez plus de données dans la sortie, comme l'URL, l'image et la légende que nous avons ajoutées :

C'est tout pour le crawling d'une seule page. Ensuite, voyons comment nous pouvons créer un scraper qui suit les liens.
Étape 3 : Comment crawler plusieurs pages
Jusqu'à présent, nous avons créé un scraper capable de récupérer des données à partir d'une seule page. Cependant, nous voulons plus que cela. Vous voulez un spider capable de suivre les liens et d'extraire des données de plusieurs pages d'un site web de manière programmatique.
Si vous allez au bas de la page du blog de CloudSigma, vous remarquerez les liens de pagination, et une petite flèche pointant vers la droite indiquant la page suivante. Voici l'extrait de code HTML :
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Page 1 sur 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Dernière page">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
L'extrait montre plusieurs liens de navigation de page dans des balises <li>, sous la balise <div> avec la classe CSS .x-pagination. Notre attention se porte sur le lien pointant vers la page suivante. Il se trouve dans la balise <a> du dernier <li> de la balise <ul>.
Le lien pointant vers la page suivante a la classe .prev-next dans la balise <a> comme on peut le voir dans l'extrait ci-dessus. Cependant, si vous passez à la page suivante, vous remarquerez également que les liens vers la page précédente et suivante ont cette classe CSS. Considérez cet extrait pour la page 2 :
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Page 2 sur 45</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Dernière page">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Si nous utilisons la méthode extract_first() de Scrapy, cela fonctionnera sur la première page. Lorsqu'elle atteindra la page suivante, elle choisira le premier lien avec la classe .prev-next, qui, dans l'extrait ci-dessus, pointe vers la première page. Cela entraînera une boucle. Par conséquent, nous utiliserons la méthode extract() de Scrapy. Cette méthode extrait tous les éléments correspondant à un cas d'utilisation et les place dans un tableau. À partir de ce tableau, nous pouvons choisir le dernier élément qui contiendra le lien réel pointant vers la page suivante. Modifiez votre code pour qu'il ressemble à ceci :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Parcourons le code pour la sélection de next_page.
Nous définissons d'abord un sélecteur pour les liens de page suivante et précédente. Nous utilisons ensuite la méthode extract() pour extraire les URL et les placer dans un tableau. La variable next_page sera un tableau contenant deux éléments comme :
|
1 |
next_page = [prev_page_url, next_page_url] |
Puisque nous naviguons vers la page suivante, nous allons choisir le dernier élément du tableau. Next_page[-1] sélectionne le dernier élément du tableau.
Le bloc if vérifie si la variable next_page contient quelque chose, puis il appelle la méthode scrapy.Request(). Dans notre code, nous demandons à cette méthode de parcourir la page avec l'URL fournie et de la renvoyer à la méthode parse() afin que nous puissions l'analyser pour extraire les données et répéter le processus pour la page suivante. Ce processus est répété jusqu'à ce qu'il ne trouve plus de lien vers la page suivante, ou plutôt si le bloc échoue, il s'arrête.
Enregistrez votre code et exécutez-le. Vous remarquerez que l'itération continue de boucler à travers les pages à mesure qu'elle trouve d'autres pages à scraper. C'est ainsi que vous définiriez un scraper qui suit les liens sur un site web. Notre exemple est assez simple. Nous allons simplement sur une page, trouvons le lien vers la page suivante et répétons le processus. Dans d'autres cas d'utilisation, vous pourriez vouloir suivre des balises ou des liens pointant vers des sources externes et plus encore. Voici le code source complet pour le scraper web de base en Python 3 :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Conclusion
Dans ce tutoriel, nous avons construit un scraper web de base capable de parcourir le blog de CloudSigma et d'afficher des informations sur les tutoriels du blog en environ 27 lignes de code seulement.
Bien sûr, cela est possible parce que nous l'avons construit sur la base de la bibliothèque Python Scrapy. Ce n'est qu'une base qui devrait vous aider à construire des scrapers plus complexes qui suivent plus de balises, des résultats de recherche de sites web, et plus encore. Vous pouvez consulter la documentation officielle de Scrapy pour plus d'informations sur l'utilisation de Scrapy.
Bonne informatique !
Commentaires
Aucun commentaire pour l'instant. Soyez le premier.