

Introduction
Proxy de haute disponibilité (HAProxy), est un proxy open-source populaire et une solution d'équilibrage de charge TCP/HTTP capable de s'exécuter sur Solaris, FreeBSD, et Linux. Il est le plus souvent utilisé pour améliorer la fiabilité et les performances d'un environnement de serveurs en fournissant une distribution équilibrée de la charge de travail sur plusieurs serveurs. Ce type d'outil est utilisé dans de nombreux environnements de premier plan comme Instagram, GitHub, Twitter et Imgur.
Ce guide vous présentera HAProxy, vous familiarisera avec la terminologie de l'équilibrage de charge et fournira des exemples de la manière dont il peut être exploité pour renforcer à la fois les performances et la fiabilité des environnements de serveurs.
Termes essentiels de HAProxy
Avant d'entrer dans les détails de l'équilibrage de charge et du proxying, il y a des termes et concepts importants avec lesquels il faut se familiariser. Nous commencerons par passer en revue ces concepts dans les sections suivantes.
ACL (Access Control List)
En ce qui concerne l'équilibrage de charge, les ACL sont utilisées pour tester une condition particulière et effectuer une action en fonction du résultat. Cela permet de rediriger le trafic de manière optimale en fonction de facteurs tels que les connexions backend et la correspondance de motifs, ainsi que de nombreux autres. Voici un exemple d'utilisation d'une ACL :
|
1 |
acl url_blog path_beg /blog |
Dans ce cas, l'ACL correspond si le chemin demandé par l'utilisateur commence par /blog. Par exemple, cette requête correspondante pointerait vers http://yourdomain.com/blog/blog-entry-1. Le Manuel de configuration de HAProxy contient un guide détaillé sur l'utilisation des ACL.
Le Backend
Les requêtes transférées sont reçues par un ensemble de serveurs appelé backend. Les requêtes sont définies dans la section backend de la configuration HAProxy. En termes simples, un backend peut être défini par les algorithmes d'équilibrage de charge à utiliser et une liste de ports et de serveurs. Un backend peut être constitué d'un seul serveur ou de plusieurs serveurs. À mesure que des serveurs sont ajoutés au backend, la capacité de charge potentielle augmente, le traitement étant réparti sur plusieurs serveurs. Si certains serveurs du backend se déconnectent, les autres serviront de serveurs de secours pour traiter les requêtes.
Voyons un exemple de configuration de deux backends. Dans ce cas, il s'agit d'un blog-backend et d'un web-backend. Chacun dispose de deux serveurs web, écoutant sur le port 80 :
|
1 2 3 4 5 6 7 8 9 10 |
backend web-backend balance roundrobin server web1 web1.yourdomain.com:80 check server web2 web2.yourdomain.com:80 check backend blog-backend balance roundrobin node http server blog1 blog1.yourdomain.com:80 check server blog2 blog2.yourdomain.com:80 check |
La ligne balance roundrobin est destinée à spécifier l'algorithme d'équilibrage de charge. Les détails peuvent être trouvés dans la section suivante Algorithmes d'équilibrage de charge, tandis que mode http configure l'utilisation du proxying de couche 7. Nous expliquerons cela dans la section Types d'équilibrage de charge. De plus, l'option check après la directive des serveurs indique que des contrôles de santé seront déclenchés sur ces serveurs backend particuliers.
Le Frontend
La définition de la manière dont les requêtes sont transférées au backend est appelée le frontend. Les requêtes sont définies dans la section frontend de la configuration HAProxy. Elles sont composées d'ACL, d'un port, d'un ensemble d'adresses IP et d'une règle définissant les backends à utiliser en fonction des conditions ACL remplies, appelée règle use_backend. De plus, une règle default_backend existe également pour gérer tous les autres cas. La section suivante expliquera comment un frontend peut être configuré pour différents types de trafic réseau.
Types d'équilibrage de charge
Une fois établis les composants de base utilisés pour la répartition de charge, nous pouvons maintenant passer aux types de base de répartition de charge.
Pas de répartition de charge
Dans sa forme la plus rudimentaire, l'absence de répartition de charge peut être illustrée comme suit :
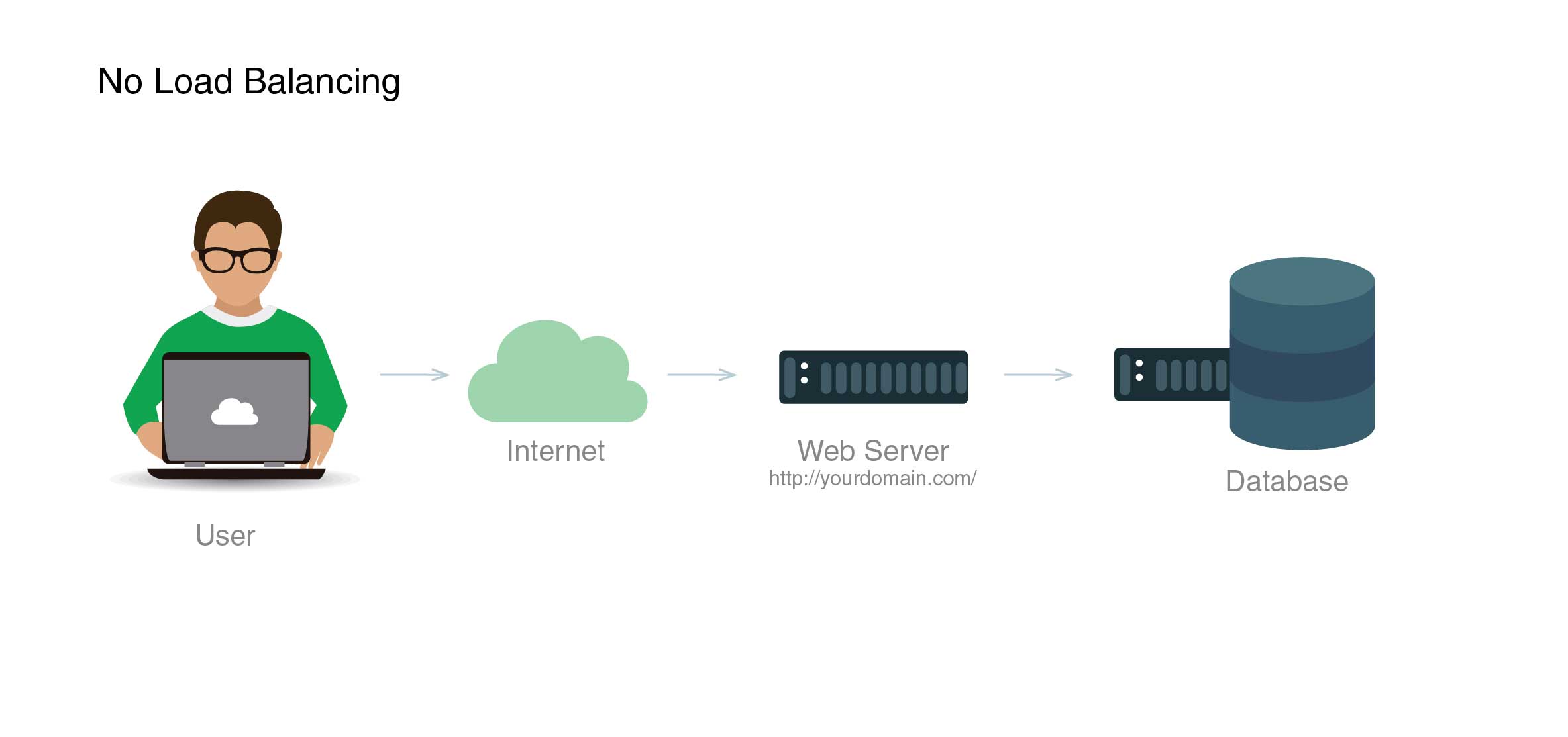
Dans ce scénario, un utilisateur se connecte directement au serveur web, sur yourdomain.com. Il n'y a pas de répartition de charge. Comme il n'y a qu'un seul serveur de base de données, s'il se déconnecte, l'accès aux informations qu'il contient est alors complètement coupé. Si de nombreux utilisateurs tentent de se connecter simultanément à un seul serveur web et que celui-ci n'est pas en mesure de gérer la charge qui s'exerce, toutes les connexions ralentiront ou échoueront complètement.
Répartition de charge (couche 4)
L'un des moyens les plus simples et les plus pragmatiques de répartir le trafic réseau sur plusieurs serveurs consiste à utiliser des méthodes de répartition de la couche transport ou de la couche 4. Cette manière de répartir la charge dirige tout utilisateur qui se connecte en fonction de la plage IP dans laquelle se trouve son adresse IP et du port. En d'autres termes, si http://yourdomain.com/anything est l'endroit d'où provient la requête, le backend défini pour gérer ces requêtes sera celui qui les traitera en fin de compte. Il transmettra ces requêtes pour yourdomain.com sur le port 80.
La configuration de base de la répartition de charge de couche 4 ressemble à ceci :

Lorsque l'utilisateur accède au répartiteur de charge, ses requêtes sont transmises au groupe de serveurs web-backend. Le serveur backend configuré répondra directement à la requête de l'utilisateur. Pour éviter que l'utilisateur ne rencontre des données incohérentes, tous les serveurs web-backend doivent proposer un contenu identique. Comme le montre le diagramme ci-dessus, les deux serveurs web sont finalement reliés au même serveur de base de données.
Répartition de charge (Couche 7)
Il existe une autre méthode, plus complexe, pour répartir la charge du trafic réseau. Il s'agit d'utiliser la répartition de charge de niveau 7, ou couche application. Cette approche permet de transmettre les requêtes des utilisateurs à différents serveurs backend en fonction du contenu des requêtes des utilisateurs. Cette méthode permet d'effectuer une répartition de charge sur plusieurs serveurs d'applications web via le même port et le même domaine. Pour plus de détails sur cette couche, jetez un œil à la sous-section HTTP de notre The Nitty Gritty of Networking: Learn about Terminology, Interfaces, and Protocols tutoriel.
Le diagramme suivant illustre la répartition de charge de couche 7 :
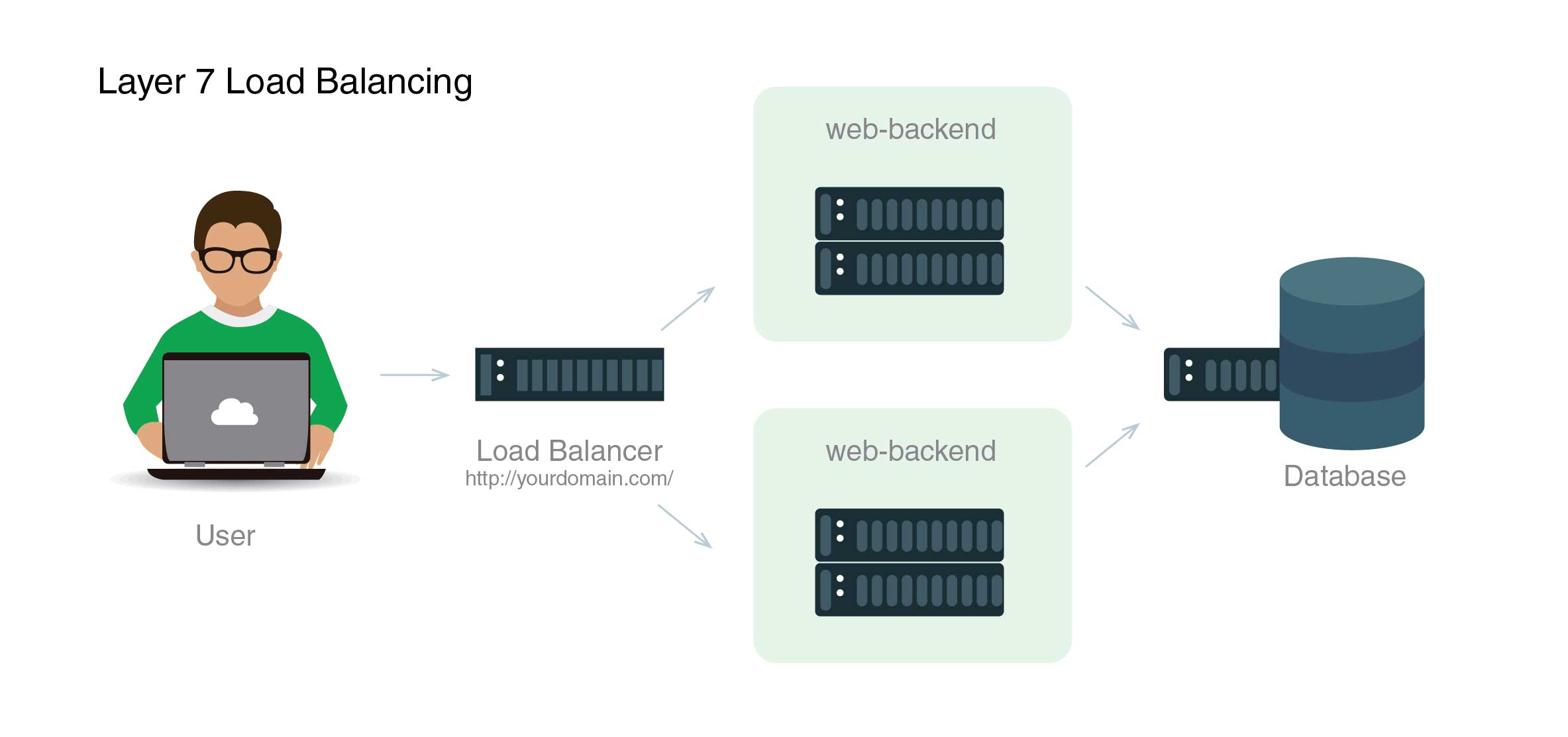
Dans ce cas, un utilisateur demande yourdomain.com/blog, et sa requête est transmise au backend blog. Il s'agit d'un ensemble de serveurs backend spécifiquement alloués à l'exécution de l'application de blog. Pendant ce temps, les autres requêtes seront transmises au web-backend. Cependant, les deux backends finissent par accéder au même serveur de base de données.
Un exemple d'une petite partie de configuration frontend pour la répartition de charge de couche 7 ressemblerait aux commandes suivantes. Elles configurent le frontend http pour gérer le trafic entrant via le port 80 :
|
1 2 3 4 5 6 7 8 |
frontend http bind *:80 node http acl url_blog path_beg /blog use_backend blog.backend if url_blog default_backend web.backend |
Si le chemin de la requête de l'utilisateur commence par /blog, l'acl url_blog path_beg /blog correspondra à la requête.
use_backend blog backend if url_blog redirige le trafic vers blog-backend en utilisant l'ACL.
defaut_backen web_backend dirige toutes les autres transmissions de trafic vers web-backend.
Algorithmes de répartition de charge
Lors de la répartition de charge, c'est l'algorithme de répartition de charge qui définit quel serveur backend sera sélectionné à cette fin. Plusieurs options d'algorithmes sont proposées par HAProxy. Il est également possible d'attribuer un paramètre de poids (weight) aux serveurs afin d'influencer la fréquence à laquelle un serveur est sélectionné par rapport aux autres. Il y a tout simplement trop d'algorithmes disponibles pour tous les décrire. Par conséquent, ce guide se concentrera uniquement sur les plus courants. Vous pouvez vous référer au HAProxy Documentation Converter pour voir la liste complète. Les plus couramment utilisés incluent :
- roundrobin : l'algorithme par défaut qui sélectionne les serveurs à tour de rôle.
- leastconn : le serveur ayant le moins de connexions actives est automatiquement sélectionné. Cependant, ces serveurs au sein du même backend doivent alterner selon une méthode round-robin.
- source : l'algorithme choisit le serveur en fonction de l'adresse IP source de la requête de l'utilisateur. C'est une méthode permettant de s'assurer que l'utilisateur se connectera toujours au même serveur.
Sessions persistantes
Pour certaines applications, il est nécessaire que les utilisateurs qui se connectent le fassent en étant toujours redirigés vers le même serveur. Grâce aux « sessions persistantes » et en utilisant le paramètre appsession dans le backend qui le requiert, une telle persistance peut être obtenue.
Traitement des contrôles de santé
HAProxy a besoin d'une méthode lui permettant de déterminer la capacité d'un serveur backend à traiter les requêtes. Cela évite d'avoir à retirer un serveur du backend s'il se déconnecte. Un « contrôle de santé » (health check) par défaut est exécuté pour tenter d'établir une connexion TCP. Il le fait en écoutant sur l'adresse IP et le port configurés.
Si le contrôle de santé du serveur échoue, le serveur est incapable de traiter les requêtes envoyées. À ce stade, le serveur est automatiquement désactivé dans le backend, et le trafic ne lui est plus acheminé jusqu'à ce qu'il soit à nouveau opérationnel (sain). Cependant, dans certains cas, déterminer la santé du serveur via le contrôle de santé par défaut s'avère insuffisant.
Solutions alternatives
HAProxy pourrait s'avérer trop complexe pour vos besoins spécifiques. Dans ce cas, il existe d'excellentes alternatives qui pourraient s'avérer plus efficaces :
- Nginx : il s'agit d'un serveur web fiable et rapide qui peut être exploité pour la répartition de charge et le proxying. En fait, Nginx est couramment utilisé en tandem avec HAProxy, qui tire parti de ses capacités de compression et de mise en cache.
- Linux Virtual Servers (LVS) : il s'agit d'un répartiteur de charge simple de couche 4 qui est inclus dans de nombreux systèmes Linux.
Haute disponibilité
Jusqu'à présent, nous avons parlé de la répartition de charge de couche 4 et de couche 7. Toutes deux utilisent un répartiteur de charge pour déterminer lequel des nombreux serveurs backend sera chargé de répondre à la requête de l'utilisateur. Mais il est important de garder à l'esprit les limites d'un répartiteur de charge. À savoir, qu'il s’agit d'un point de défaillance unique. Cela signifie que s'il venait à tomber en panne, ou s'il était surchargé de requêtes d'utilisateurs, cela entraînerait respectivement une interruption de service ou une latence dans le traitement des requêtes. Cependant, une configuration HA (haute disponibilité) présente une infrastructure exempte de tout point de défaillance unique. Cela évite les interruptions de service dues à la panne d'un serveur en introduisant de la redondance à chaque niveau de l'architecture du système. Bien que le répartiteur de charge aide à faciliter la redondance du backend, les répartiteurs de charge doivent également faire preuve de redondance.
Le schéma suivant présente une forme de base d'une configuration en haute disponibilité :
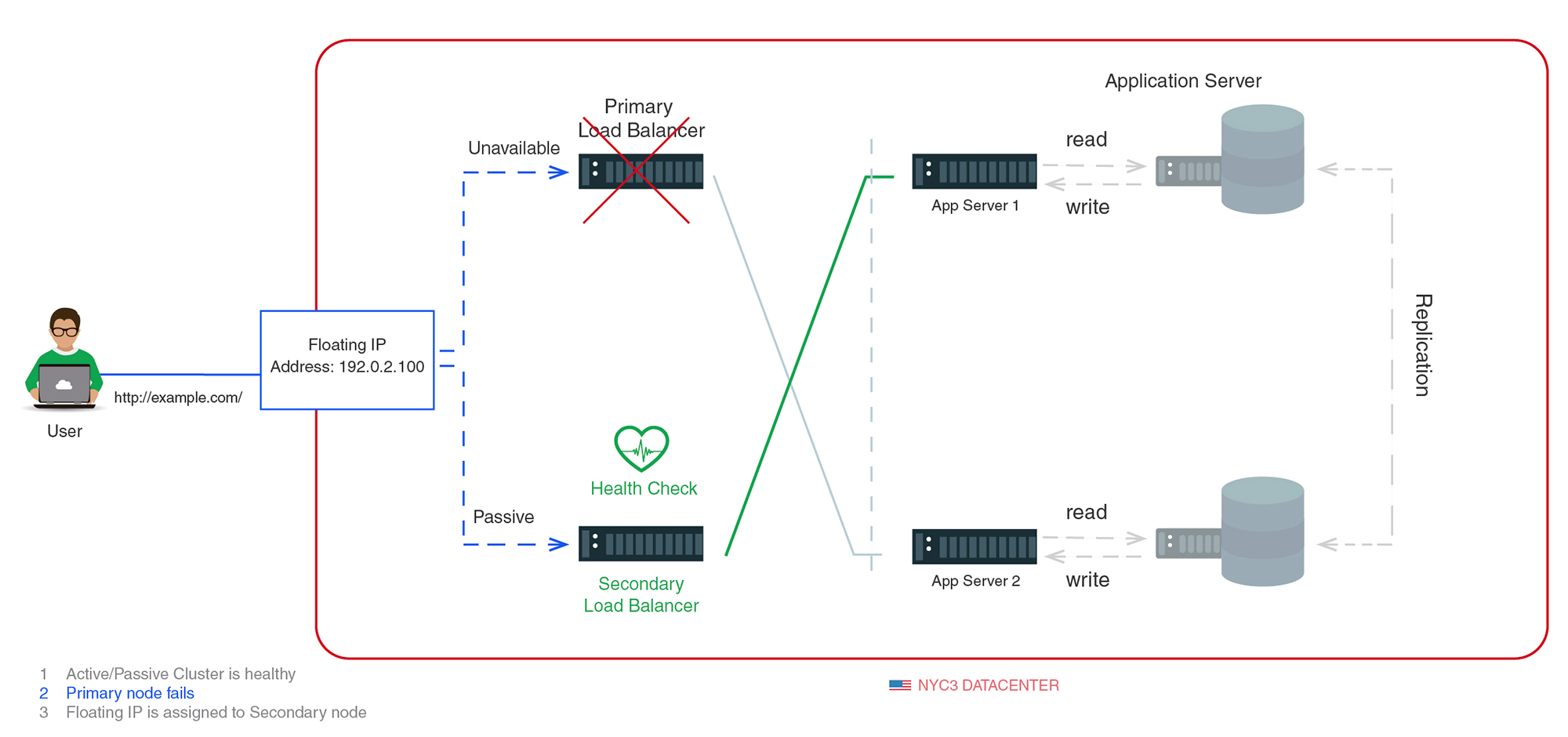
Cette infrastructure comporte plusieurs répartiteurs de charge (un actif, les autres passifs) liés à une adresse IP statique. Cette adresse IP peut être réattribuée à un autre serveur si la situation l'exige. La requête de l'utilisateur passe par l'adresse IP externe pour atteindre le répartiteur de charge actuellement actif. Si le répartiteur de charge est hors ligne à ce moment-là, le mécanisme de sécurité détectera son état et réattribuera l'adresse IP au(x) serveur(s) passif(s).
Conclusion
La compréhension fondamentale de la répartition de charge et la connaissance de certaines des manières dont HAProxy peut répondre aux besoins de répartition de charge de votre système devraient vous donner une base solide pour commencer à optimiser la fiabilité et les performances de vos environnements de serveurs actuels. Vous pouvez également consulter notre tutoriel Proxying HTTP Nginx, répartition de charge, mise en mémoire tampon et mise en cache : un aperçu pour en savoir plus sur les propriétés de répartition de charge de Nginx.
Bonne informatique !
Commentaires
Aucun commentaire pour l'instant. Soyez le premier.