

Der grep-Befehl ist ein leistungsstarkes Werkzeug zur Suche nach Mustern in Texten. Er ist auf jeder Linux-Distribution vorinstalliert. Hier ist unser Tutorial zur Einrichtung des LAMP-Stacks – Linux, Apache, MySQL und PHP.
Der Name grep steht für „global regular expression print“. Das Tool sucht nach dem angegebenen Muster in der Eingabe. Im Prinzip klingt das trivial. Seine wahre Stärke liegt jedoch darin, wie Sie das Muster definieren. Diese Anleitung erklärt ausführlich, wie Sie grep mit regulären Ausdrücken verwenden, um komplexe Suchen durchzuführen. Fangen wir an!
So verwenden Sie Grep
Der grep-Befehl an sich ist nicht kompliziert. Er benötigt lediglich das Muster und den Inhalt, in dem gesucht werden soll. So sieht die Grundstruktur des grep-Befehls aus:
|
1 |
grep <regex> <file> |
Text durchsuchen
Holen Sie sich zuerst eine Beispieldatei, um die Aktion auszuführen. Laden Sie die GNU General Public License v3.0 (im Textformat) herunter. Es ist eine ziemlich große Textdatei mit vielen Wörtern und Phrasen. Wenn Sie Ubuntu verwenden, finden Sie sie in der folgenden Datei. Folgen Sie unserem Tutorial für eine schnelle und einfache Ubuntu-Installation.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

Als Nächstes können Sie eine einfache Textsuche mit grep durchführen:
|
1 |
grep <pattern> <text_file> |
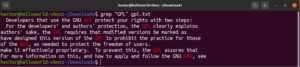
Es ist möglich, die Ausgabe eines Befehls an grep weiterzuleiten (Piping):
|
1 |
cat gpl.txt | grep <pattern> |
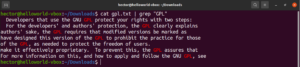
Groß-/Kleinschreibung
Standardmäßig unterscheidet grep zwischen Groß- und Kleinschreibung. In vielen Situationen kann es optimal sein, die Groß-/Kleinschreibung zu ignorieren. Um die case-sensitive Suche zu deaktivieren, verwenden Sie das Flag „-i“ oder „–ignore-case“:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
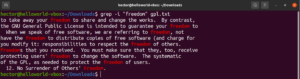
Suche umkehren
Standardmäßig gibt grep die Zeilen aus, in denen das Muster gefunden wurde. Die Umkehrung der Suche (Invert Match) bezieht sich auf das Phänomen, wenn Sie die Zeilen, die mit dem Muster übereinstimmen, nicht sehen möchten. Um die Suche umzukehren, müssen Sie das Flag „-v“ oder „–invert-match“ verwenden:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
Zeilennummer
Wenn Sie grep auf eine sehr große Datei anwenden, ist es schwierig, den Ort des Suchergebnisses im Auge zu behalten. Um die Sache zu vereinfachen, bietet grep die Funktion, die Zeilennummer anzuzeigen. Um die Zeilennummerierung zu aktivieren, verwenden Sie das Flag „-n“ oder „–line-number“:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
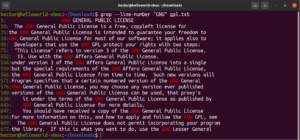
Es ist möglich, mehrere grep-Argumente zu kombinieren. Der folgende grep-Befehl führt eine umgekehrte Suche durch und gibt gleichzeitig die Zeilennummern aus:
|
1 |
grep -nv <pattern> <file> |
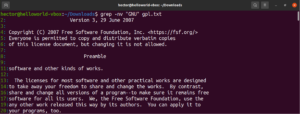
Regulärer Ausdruck
Zu Beginn dieser Anleitung haben wir erwähnt, dass grep für „global regular expression print“ steht. Der Begriff „regulärer Ausdruck“ ist definiert als eine spezielle Zeichenkette, die das Suchmuster beschreibt. Reguläre Ausdrücke haben ihre eigene Struktur und Regeln.
Es gibt zahlreiche Algorithmen und Tools zur String-Suche, die reguläre Ausdrücke (kurz Regex) verwenden, um Such- und Ersetzungsvorgänge durchzuführen. Obwohl sie weit verbreitet sind, implementieren verschiedene Anwendungen und Programmiersprachen Regex leicht unterschiedlich. In diesem Abschnitt werden wir einige Regex-Methoden unter Verwendung von grep vorstellen.
Literale Übereinstimmung
In den vorherigen grep-Beispielen hat grep die Suche nach einer bestimmten Zeichenkette in der angegebenen Textdatei durchgeführt. Grep suchte tatsächlich mit einem sehr einfachen regulären Ausdruck. Die Regex-Muster, die die Suche nach der exakten Übereinstimmung einer bestimmten Zeichenkette definieren, werden als „Literale“ bezeichnet. Der Name rührt von der Tatsache her, dass sie mit dem Muster buchstäblich, Zeichen für Zeichen, übereinstimmen.
Die wörtliche Übereinstimmung funktioniert mit alphabetischen und numerischen Zeichen (sowie einigen Sonderzeichen). Je nach anderen Ausdrucksmechanismen kann sich dieses Verhalten jedoch ändern:
|
1 |
grep "<string>" <file> |
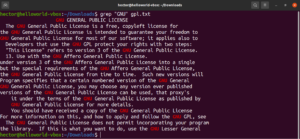
Anker-Übereinstimmung
Anker sind Sonderzeichen, die definieren, wo sich die Position der Übereinstimmung in der Zeile befinden muss, um eine gültige Übereinstimmung zu erzielen. Hier ist ein kurzes Beispiel zur Vereinfachung. Wenn wir nur die Zeilen finden wollen, die mit der Zeichenfolge „GNU“ beginnen, sieht der grep-Befehl mit regulärem Ausdruck wie folgt aus. Hier ist das Zeichen „^“ der Anker, der festlegt, dass nur Übereinstimmungen am Anfang der Zeile gültig sind:
|
1 |
grep -n "^GNU" <file> |

Ebenso sieht der grep-Befehl mit regulärem Ausdruck wie folgt aus, wenn wir nur die Zeilen finden wollen, die mit der Zeichenfolge „works“ enden. Hier ist das Zeichen „$“ der Anker, der festlegt, dass nur Übereinstimmungen am Ende der Zeile gültig sind:
|
1 |
grep -n "and$" <file> |
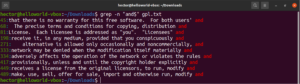
Beliebige Zeichenübereinstimmung
Bei der Durchführung einer Textsuche möchten Sie möglicherweise festlegen, dass an einer bestimmten Stelle ein beliebiges Zeichen stehen kann. In regulären Ausdrücken wird dies durch den Punkt (.) ausgedrückt.
Sehen Sie sich dieses Beispiel an. In der GNU GPL 3-Textdatei haben die Wörter „accept“ und „except“ den Teil „cept“ gemeinsam. Darüber hinaus haben beide Wörter zwei Zeichen vor dem Teil „cept“. Der folgende grep-Befehl findet jedes Wort, das zwei Zeichen vor dem Teil „cept“ hat:
|
1 |
grep -n "..cept" <file> |
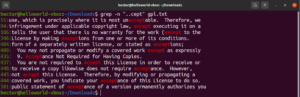
Gemäß diesem regulären Ausdruck sind auch andere Wörter wie suscept, unaccept, unexpected usw. gültige Übereinstimmungen.
Eckige Klammern
In regulären Ausdrücken definieren Klammerausdrücke, dass an der angegebenen Stelle jedes innerhalb der Klammer deklarierte Zeichen stehen kann. Sehen Sie sich die folgende Zeichenfolge für reguläre Ausdrücke an:
|
1 |
t[wo]o |
In der Praxis sind die Wörter too und two die gültigen Übereinstimmungen:
|
1 |
grep -n "t[wo]o" <file> |
Der Klammerausdruck eröffnet einige interessante Möglichkeiten. Es ist möglich, Klammerausdrücke zu verwenden, um anzugeben, dass an der angegebenen Stelle jedes andere Zeichen als die in der Klammer deklarierten stehen kann. Sehen Sie sich die folgende Regex-Zeichenfolge an. Die Übereinstimmung ist nur gültig, wenn vor „ode“ ein anderes Zeichen als „c“ steht:
|
1 |
"[^c]ode" |
Führen Sie es auf der GPL-3-Lizenztextdatei aus:
|
1 |
grep -n "[^c]ode" <file> |

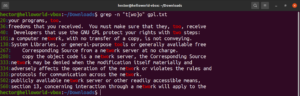
Neben dem Ergebnis aus der Datei wären andere gültige Ergebnisse node, abode, anode usw. Klammerausdrücke können auch einen Bereich von Zeichen beschreiben. Der folgende reguläre Ausdruck besagt, dass die Übereinstimmung gültig ist, wenn der Zeilenanfang ein Großbuchstabe ist:
|
1 |
"^[A-Z]" |
Führen Sie es auf der GPL-3-Lizenztextdatei aus. Es werden alle Zeilen in der Textdatei ausgegeben:
|
1 |
grep -n "^[A-Z]" <file> |
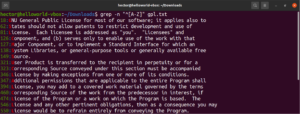
Zur einfacheren Verwendung gibt es bestimmte Zeichenklassen, die über festgelegte Bezeichnungen verfügen. Im vorherigen Beispiel haben wir den Bereich „A-Z“ verwendet, um die Großbuchstaben zu definieren. Stattdessen können wir auch „[:upper:]“ verwenden. Das Ergebnis ist dasselbe:
|
1 |
grep -n "^[[:upper:]]" <file> |
Wiederholen eines Musters
In bestimmten Situationen möchten Sie ein bestimmtes Muster oder einen regulären Ausdruck null oder mehr Mal abgleichen. Das Metazeichen hierfür ist das Sternchen (*). Der folgende reguläre Ausdruck findet alle Klammern, die nur Buchstaben und einzelne Leerzeichen dazwischen enthalten. Beachten Sie, dass die Deklaration der Klein- und Großbuchstabensätze sowie der Leerzeichen ohne Satzzeichen zusammengeschrieben wird:
|
1 |
"([a-zA-Z ]*)" |
Wenden Sie den regulären Ausdruck mit grep an:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

Verwendung von Metazeichen als literale Zeichen
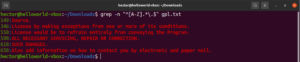
Bisher wurden uns verschiedene Metazeichen wie das Sternchen (*), der Punkt (.), Anker (^ und $) usw. vorgestellt. Jedes von ihnen hat eine einzigartige Funktion im Regex-Kontext. Das Problem entsteht, wenn sie als Literale und nicht als Metazeichen verwendet werden müssen. In solchen Situationen zeigt ein Backslash (\) vor dem Metazeichen an, dass es im wörtlichen Sinne und nicht als Metazeichen verwendet werden soll. Werfen Sie einen Blick auf dieses Regex-Beispiel. Es findet alle Zeilen, die mit einem Großbuchstaben beginnen und mit einem Punkt enden:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
Alternierung
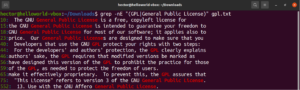
Mithilfe von Klammerausdrücken können wir verschiedene Auswahlmöglichkeiten für die Übereinstimmung eines einzelnen Zeichens angeben. Regex bietet die Möglichkeit, dasselbe mit Wörtern und Phrasen zu tun. Um eine Alternierung anzuzeigen, wird das Pipe-Zeichen (|) verwendet. Die Optionen stehen in Klammern, während das Pipe-Zeichen sie voneinander trennt. Es kann zwei oder mehr mögliche Optionen geben, damit die Übereinstimmung gültig ist. Werfen Sie einen Blick auf das folgende Regex-Beispiel. Es matcht sowohl „GPL“ als auch „General Public License“:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
Quantifizierer
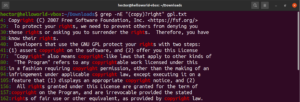
Mit dem Metazeichen Sternchen (*) konnten wir ein Muster wiederholt null- oder mehrmals definieren. Es gibt jedoch noch mehr Möglichkeiten. Es ist einfacher, die Quantifizierer an einem Beispiel zu erklären. Der folgende reguläre Ausdruck beschreibt, dass sowohl „copyright“ als auch „right“ gültige Übereinstimmungen sind. Das Fragezeichen (?) kennzeichnet den „copy“-Teil als optional für die Übereinstimmung:
|
1 |
grep -nE "(copy)?right" <file> |
Der nächste Quantifizierer ist das Pluszeichen (+). Es verhält sich ähnlich wie das Sternchen. Das definierte Muster muss jedoch mindestens einmal übereinstimmen. Im folgenden Beispiel matcht der reguläre Ausdruck „soft“ mit einem oder mehreren Nicht-Leerzeichen:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
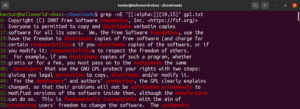
Wiederholung von Übereinstimmungen angeben
Es ist möglich, die Anzahl der Wiederholungen einer Übereinstimmung anzugeben. Verwenden Sie dazu die geschweiften Klammern ({}). Der folgende reguläre Ausdruck matcht jedes Wort, das mindestens drei Vokale enthält:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

Diese Funktion ermöglicht es Ihnen auch, die Unter- und Obergrenze für die Länge der Übereinstimmung festzulegen. Im folgenden Beispiel matcht der Regex jedes Wort, das 10 bis 15 Zeichen lang ist:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
Fazit
Das Durchsuchen von Textdateien mit grep ist äußerst praktisch. Reguläre Ausdrücke machen die Suche mit grep noch interessanter und nützlicher. Sie ermöglichen es Ihnen zudem, das Suchmuster ganz nach Ihren Wünschen anzupassen.
Obwohl wir einige der gängigen regulären Ausdrücke gezeigt haben, ist dies erst der Anfang. Es gibt fortgeschrittenere reguläre Ausdrücke, die eine noch präzisere Kontrolle über das Suchverhalten bieten. Neben grep werden reguläre Ausdrücke auch von vielen anderen Tools und Programmiersprachen verwendet.
Viel Spaß beim Computing!
Kommentare
Noch keine Kommentare. Schreiben Sie den ersten.