
Eine CSV -Datei ist eine reine Textdatei, die Daten in tabellarischer Form speichert. In den meisten Fällen verwenden CSV-Dateien Kommas (,) als Trennzeichen, daher der Name CSV (Comma Separated Values). Sie wird in Situationen verwendet, in denen die Datenkompatibilität eine Rolle spielt, da CSVs mit jedem Texteditor, Tabellenkalkulationsprogrammen und anderen spezialisierten Tools geöffnet werden können. Tatsächlich bieten viele Programmiersprachen eine integrierte Unterstützung für CSV.
In dieser Anleitung lernen wir die Verwendung von CSV in einer Beispiel-Node.js -Anwendung.
CSV in Node.js
Node.js ist eine Open-Source- und plattformübergreifende JavaScript-Laufzeitumgebung. Sie hat sich zu einem der beliebtesten Backends entwickelt, das zahlreiche Webdienste im gesamten Internet antreibt. Sogar große Unternehmen wie Netflix und Uber nutzen Node.js, um ihre Dienste zu betreiben.
Node.js verfügt außerdem über zahlreiche Module, die zur Erweiterung eines Projekts um zusätzliche Funktionen bereitgestellt werden können. Wenn es um CSV geht, stehen viele Module zur Verfügung, zum Beispiel node-csv, fast-csv, und papaparse usw.
Wie der Titel der Anleitung vermuten lässt, werden wir node-csv verwenden, um CSV-Dateien mithilfe von Node.js-Streams zu lesen. Wir werden auch die Arbeit mit den analysierten Daten demonstrieren, zum Beispiel die Übertragung der Daten in eine SQLite -Datenbank.
Voraussetzungen
-
Um die in dieser Anleitung gezeigten Schritte auszuführen, benötigen Sie die folgenden Komponenten:
-
Ein ordnungsgemäß konfiguriertes Linux-System. Erfahren Sie mehr über das installing and configuring an Ubuntu cloud server on CloudSigma.
-
Zugriff auf einen Nicht-Root-Benutzer mit sudo -Rechten. Lesen Sie mehr über das managing sudo permission with sudoers.
-
Ein geeigneter Texteditor, zum Beispiel Brackets, VS Code, Sublime Text, Vim/NeoVim, usw.
-
Andere Software:
-
Node.js LTS
-
SQLite
-
Schritt 1 – Installieren der erforderlichen Software
Für diese Anleitung habe ich einen leichtgewichtigen Server mit Ubuntu 22.04 LTS erstellt (verbunden über SSH):
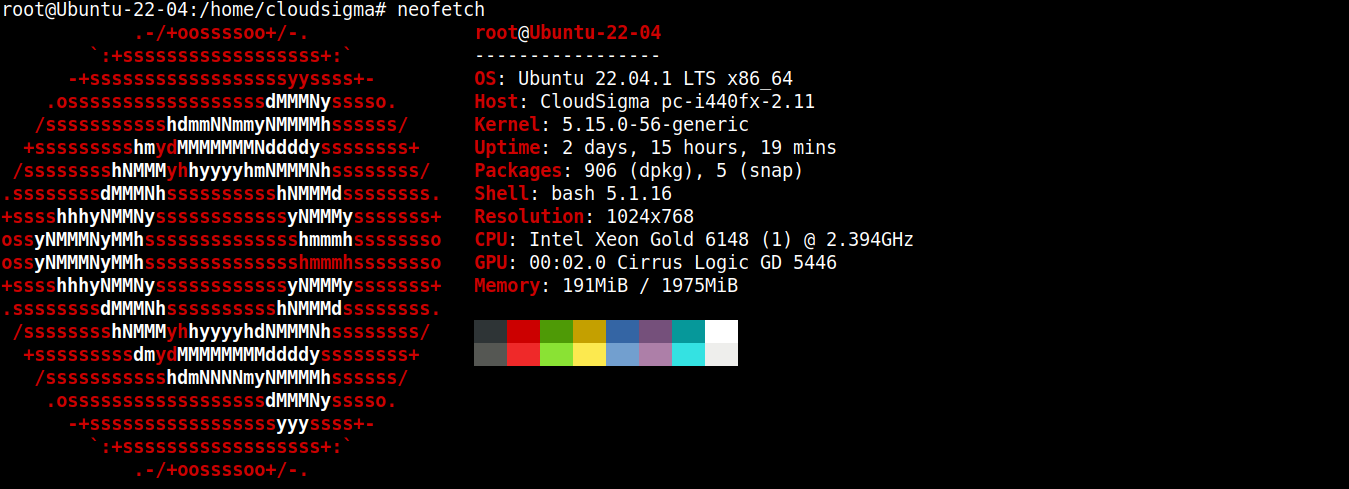
Nun werden wir Node.js und SQLite darauf installieren.
-
Installieren von Node.js LTS
Node.js ist direkt aus den offiziellen Ubuntu-Paket-Repositorys verfügbar. Es ist jedoch nicht die aktuellste Version. Aus diesem Grund werden wir uns auf ein Drittanbieter-Repository (Nodesource) verlassen, um die neuesten Node.js-Pakete zu erhalten.
Fügen Sie das Repository für Node.js LTS hinzu:
|
1 |
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - |
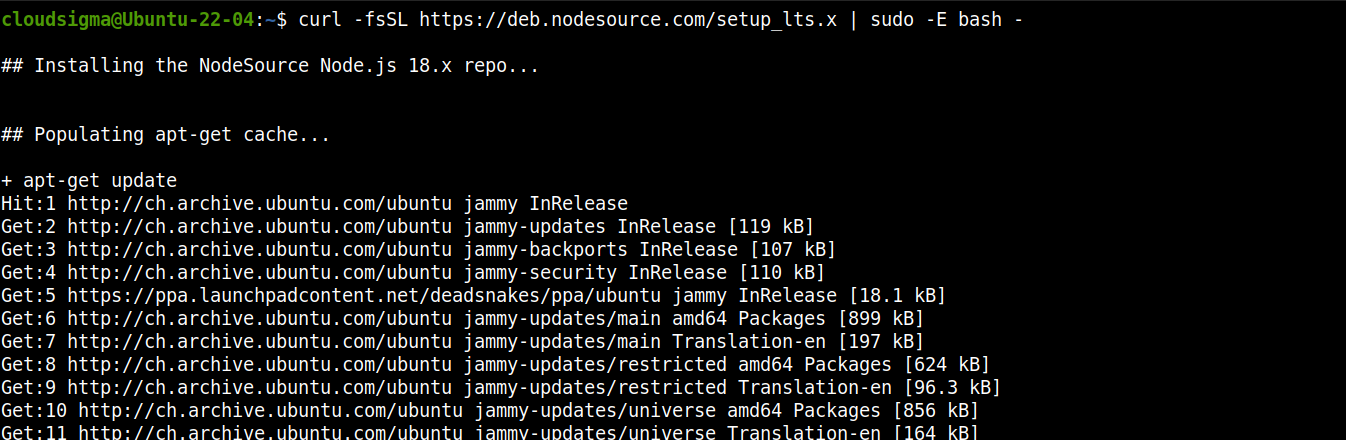
Installieren Sie nun Node.js LTS:
|
1 |
sudo apt install nodejs -y |

-
SQLite installieren
Wir werden SQLite direkt aus den Ubuntu-Paket-Repositorys installieren. Führen Sie die folgenden Befehle aus:
|
1 |
sudo apt install sqlite3 -y |

Schritt 2 – Einrichten des Projektverzeichnisses
In diesem Abschnitt werden wir ein dediziertes Verzeichnis für unser Projekt vorbereiten. Es wird alle Projektdateien zusammen mit zusätzlichen Modulen enthalten.
Erstellen Sie ein neues Verzeichnis:
|
1 |
mkdir -pv csv_practice |
Navigieren Sie in das Verzeichnis:
|
1 |
cd csv_practice/ |
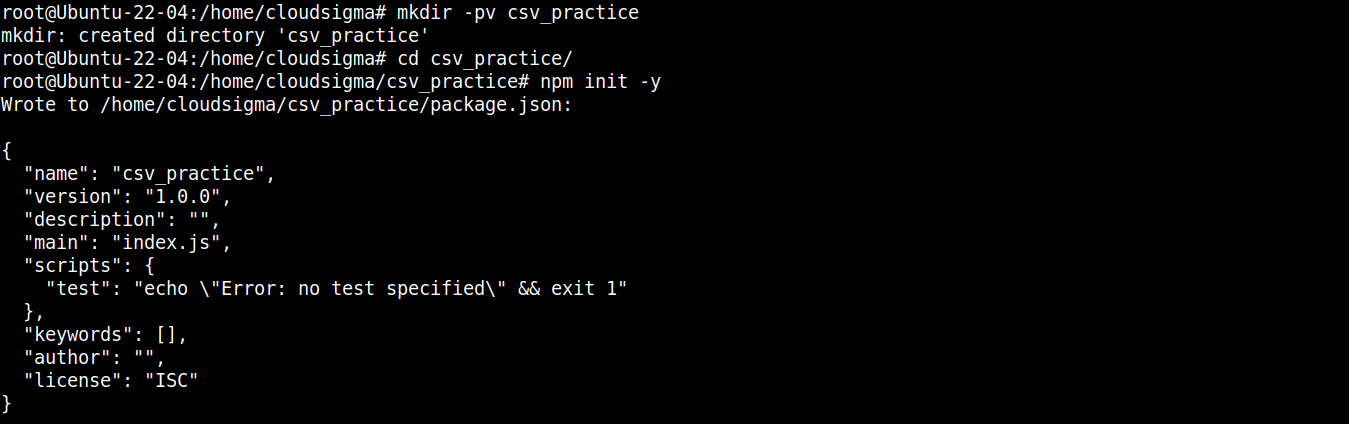
Führen Sie als Nächstes den folgenden Befehl aus, um das Verzeichnis als ein npm -Projekt zu deklarieren:
|
1 |
npm init -y |
Sobald der Projektordner initialisiert ist, können wir mit der Installation der erforderlichen Pakete und Module beginnen. Zuerst werden wir node-csv:
|
1 |
npm install csv |

Das Modul node-csv ist eigentlich eine Sammlung mehrerer anderer Module: csv-generate, csv-parse (Analysieren von CSV-Dateien), csv-stringify (Schreiben von Daten in CSV) und stream-transform.
Als Nächstes benötigen wir das Modul für die Kommunikation mit SQLite. Der folgende Befehl installiert das node-sqlite3 -Modul:
|
1 |
npm install sqlite3 |

Die Komponente, die wir für unser Projekt benötigen, ist eine CSV-Datei. Zu Demonstrationszwecken werden wir die CSV-Datei zur Migration in Neuseeland verwenden:
|
1 |
wget https://www.stats.govt.nz/assets/Uploads/International-migration/International-migration-September-2021-Infoshare-tables/Download-data/international-migration-September-2021-estimated-migration-by-age-and-sex-csv.csv -O migration_data.csv |
Werfen wir einen kurzen Blick auf den Inhalt der Datei:
|
1 |
cat migration_data.csv | less |
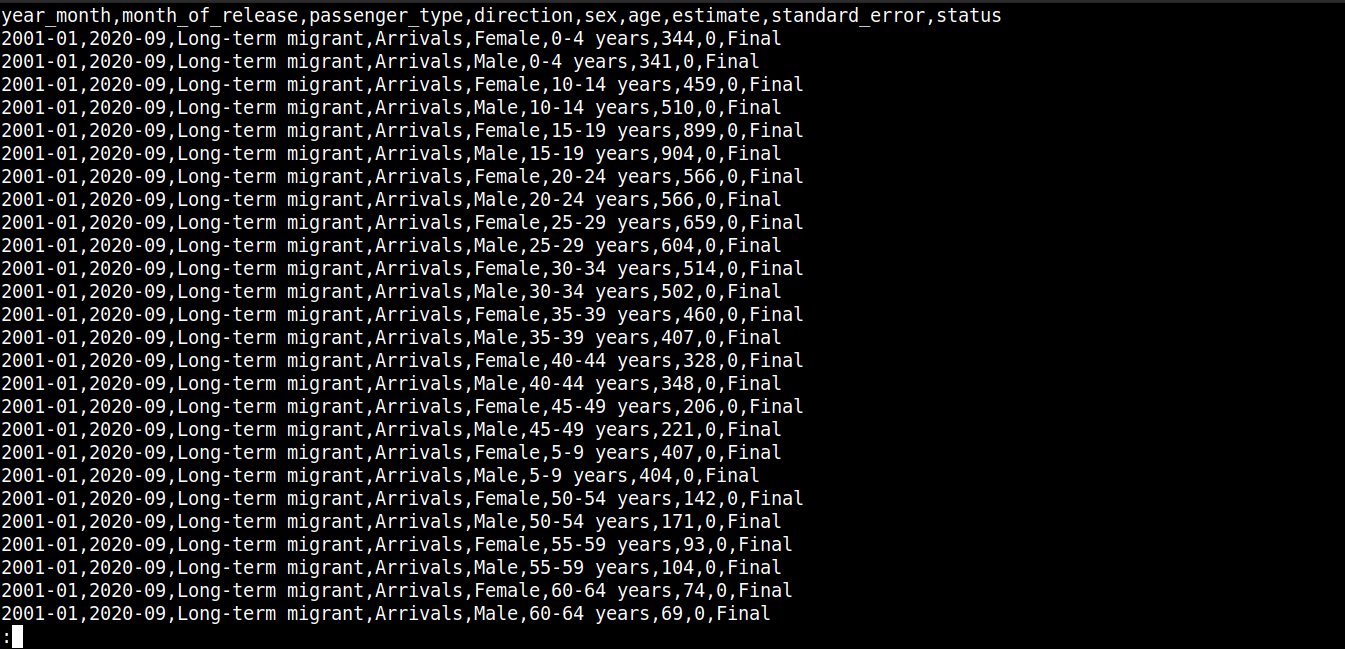
Hier,
-
Die erste Zeile beschreibt die Spaltennamen.
-
Die folgenden Zeilen enthalten die Werte für diese Felder.
-
Jede Zeile ist durch einen Zeilenumbruch (\n) getrennt.
-
Jeder Datenpunkt ist durch ein Komma (,) getrennt.
CSV ist jedoch nicht darauf beschränkt, Kommas als Trennzeichen zu verwenden. Andere gängige Trennzeichen sind Doppelpunkte (:), Semikolons (;) und Tabulatoren (\td).
Schritt 3 – CSV lesen
In diesem Abschnitt zeigen wir die Implementierung eines Beispielprogramms, das Daten aus der CSV-Datei liest und analysiert.
Erstellen Sie eine neue JavaScript-Datei:
|
1 |
touch read_csv.js |
Öffnen Sie die Datei in Ihrem bevorzugten Texteditor:
|
1 |
nano read_csv.js |
Zuerst werden wir die Module fs und csv-parse importieren:
|
1 2 |
const fs = require("fs"); const { parse } = require("csv-parse"); |
Hier,
-
Zuerst wird der Variable fs das fs-Objekt zugewiesen, das die Node.js- require() Methode beim Importieren des Moduls zurückgibt.
-
Als Nächstes wird die parse-Methode aus dem Objekt, das von der require()-Methode zurückgegeben wird, in die parse-Variable extrahiert, unter Verwendung der Destrukturierungssyntax.
Als Nächstes werden wir Code hinzufügen, um die CSV-Datei zu lesen:
|
1 2 3 4 5 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) |
Hier,
-
Wir rufen createReadStream() aus dem fs-Modul auf und übergeben die CSV-Datei, die wir lesen möchten, als Argument. Dadurch wird ein lesbarer Stream erstellt, indem die größere Datei in kleinere Blöcke aufgeteilt wird.
-
Nach dem Erstellen des Streams leitet die pipe()-Methode Blöcke der Stream-Daten an einen anderen Stream weiter. Dieser neue Stream wird beim Aufrufen der parse()-Methode aus dem csv-Modul.
-
Das csv-Modul stellt einen lesbaren/schreibbaren Transformations-Stream bereit, der einen Datenblock entgegennimmt und in eine andere Form umwandelt.
-
Die parse() Methode akzeptiert Objekte mit Eigenschaften. Das Objekt verarbeitet die analysierten Daten weiter. Hier nimmt das Objekt die folgenden Eigenschaften an:
-
delimiter: Das Trennzeichen zum Trennen von Werten. Im Fall unserer Ziel-CSV ist es ein Komma (,).
-
from_line: Die Zeilennummer, ab der der Parser mit dem Parsen beginnt. Bei dem angegebenen Wert 2 überspringt der Parser Zeile 1 und beginnt bei Zeile 2. Mit dieser Anordnung verhindern wir, dass die Spaltennamen in die analysierten Daten integriert werden.
-
Als Nächstes werden wir ein Streaming-Ereignis mithilfe der on() Methode von Node.js anhängen:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Hier,
-
Beim Auslösen eines bestimmten Ereignisses ermöglicht ein Streaming-Ereignis einer Methode, einen Datenblock zu konsumieren.
-
Wenn die von der parse()-Methode analysierten Daten bereit zur Verarbeitung sind, wird das data-Ereignis ausgelöst.
-
Um auf die Daten zuzugreifen, übergeben wir einen Callback an die on()-Methode, die einen Parameter row entgegennimmt.
-
Der Parameter row ist ein Datenblock in Form eines Arrays (Ergebnis des Parsens).
-
Schließlich werden die Daten in der Konsole ausgegeben mittels console.log().
Um das Programm fertigzustellen, werden wir zusätzliche Stream-Ereignisse hinzufügen, um Fehler zu behandeln und eine Erfolgsmeldung auszugeben, wenn alle Daten in der CSV-Datei verarbeitet wurden. Aktualisieren Sie den Code wie folgt:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Hier,
-
Das end-Ereignis wird ausgelöst, wenn alle Daten in der CSV-Datei verarbeitet wurden. Es führt zum Aufruf der console.log()-Methode, die eine Erfolgsmeldung ausgibt.
-
Das error-Ereignis wird ausgelöst, wenn beim Parsen der CSV-Daten ein Fehler auftritt. Es führt zum Aufruf der console.log() Methode, die eine Fehlermeldung ausgibt.
Der endgültige Code sollte wie folgt aussehen:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const fs = require("fs"); const { parse } = require("csv-parse"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
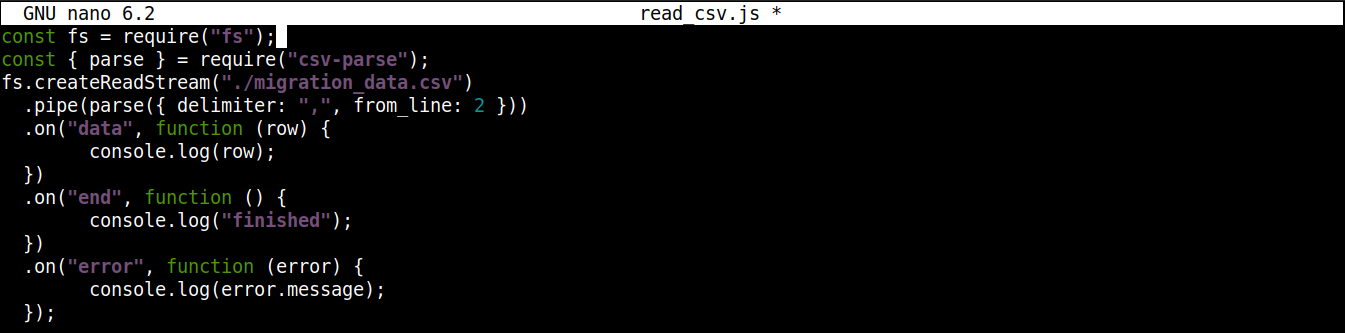
Speichern Sie die Datei und schließen Sie den Editor. Wir sind nun bereit, das Programm auszuführen. Führen Sie es mit Node.js aus:
|
1 |
node read_csv.js |
Die Ausgabe sollte in etwa so aussehen:

Beachten Sie, dass die Daten verarbeitet, transformiert und auf der Konsole ausgegeben werden. Da es sich um einen kontinuierlichen Prozess handelt, wird es so aussehen, als ob Daten heruntergeladen werden, anstatt die Ausgabe auf einmal auszugeben.
Schritt 4 – Übertragen von CSV-Daten in eine Datenbank
Bisher haben wir gelernt, wie man eine CSV-Datei mit node-csv parst. In diesem Abschnitt wird gezeigt, wie die geparsten Daten in eine Datenbank (SQLite) übertragen werden.
Erstellen Sie eine neue JavaScript-Datei für die Interaktion mit der Datenbank:
|
1 |
touch csv-to-sqlite3.js |
Öffnen Sie nun die Datei in einem Texteditor:
|
1 |
nano csv-to-sqlite3.js |
![]()
Wir werden unser Programm mit folgendem Code starten:
|
1 2 3 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; |

Hier,
-
In der ersten Zeile importieren wir das fs-Modul.
-
In der dritten Zeile enthält die Variable filepath den Pfad der SQLite-Datenbank.
-
Zu diesem Zeitpunkt existiert die Datenbank noch nicht. Sie wird jedoch benötigt, wenn wir mit node-sqlite3.
arbeiten. Fügen Sie als Nächstes die folgenden Zeilen hinzu, um eine Verbindung zur SQLite-Datenbank herzustellen:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } console.log("Connected to the database successfully"); }); return db; } } |
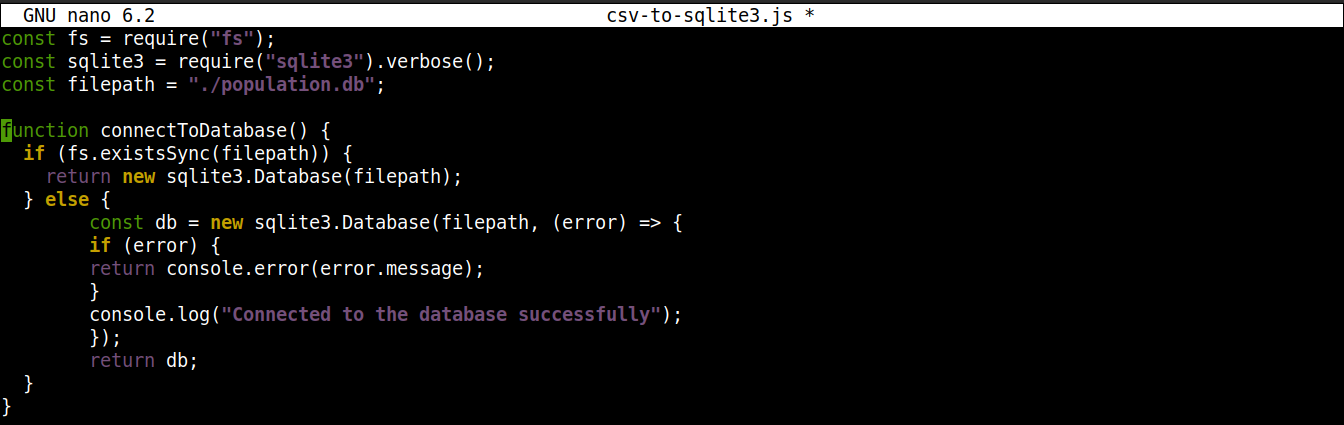
Hier,
-
Die Methode connectoToDatabase() stellt eine Verbindung zur Datenbank her.
-
Innerhalb von connectToDatabase(), rufen wir die existsSync() -Methode aus dem fs-Modul innerhalb einer if-Anweisung auf. Die if-Anweisung prüft die Existenz der Datenbank am angegebenen Speicherort.
-
Wenn die Auswertung der Bedingung true ist, dann wird die Database()-Klasse des node-sqlite3 -Moduls instanziiert. Sobald die Verbindung hergestellt ist, gibt die Funktion ein Objekt zurück und wird beendet.
-
Wenn die Auswertung der Bedingung false ist (die Datenbank existiert nicht), springt die Ausführung in den else-Block. Dort wird die Database()-Klasse mit zwei Argumenten initialisiert: einem Pfad zur Datenbankdatei und einem Callback.
-
Im Grunde wird die Datenbank erstellt, wenn sie nicht existiert. Wenn jedoch während des Erstellungsprozesses ein Fehler auftritt, wird das error-Objekt gesetzt und die Fehlermeldung ausgegeben.
Als Nächstes werden wir Code einführen, um eine Tabelle zu erstellen, falls keine Datenbank existiert:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } createTable(db); console.log("Connected to the database successfully"); }); return db; } } function createTable(db) { db.exec(` CREATE TABLE migration ( year_month VARCHAR(10), month_of_release VARCHAR(10), passenger_type VARCHAR(50), direction VARCHAR(20), sex VARCHAR(10), age VARCHAR(50), estimate INT ) `); } module.exports = connectToDatabase(); |
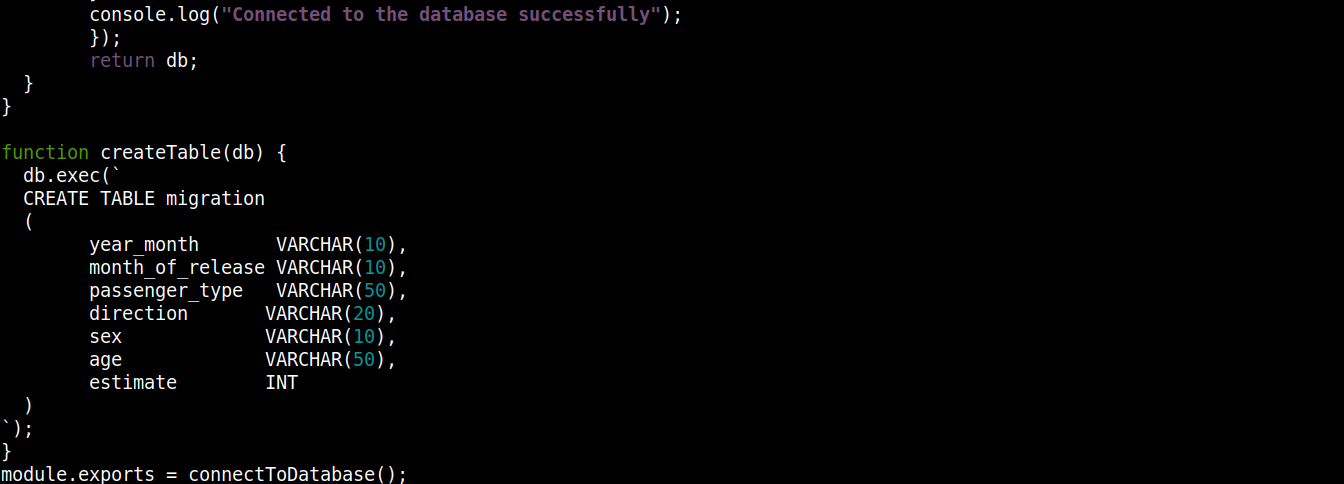
Hier,
-
Die Funktion connectToDatabase() ruft die createTable()-Funktion auf, die das in db gespeicherte Objekt als Argument entgegennimmt.
-
Außerhalb von connectToDatabase() haben wir die createTable()-Methode definiert, die das Verbindungsobjekt db als Parameter akzeptiert.
-
Die exec()-Methode auf db nimmt eine SQL-Anweisung als Argument entgegen. Innerhalb dieser SQL-Anweisung haben wir die Erstellung einer Tabelle migration mit 7 Spalten definiert, wobei jede Spalte den Spaltenüberschriften in der migration_data.csv -Datei entspricht.
-
Schließlich rufen wir die connectToDatabase()-Methode und exportieren das zurückgegebene Verbindungsobjekt, damit wir es in anderen Dateien verwenden können.
Speichern Sie die Datei und schließen Sie den Editor.
Als Nächstes werden wir ein weiteres Programm erstellen, um die analysierten Daten in die Datenbank einzufügen:
|
1 |
nano insert_data.js |
Geben Sie in den folgenden Code ein:insert_data.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const fs = require("fs"); const { parse } = require("csv-parse"); const db = require("./csv-to-sqlite3"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { db.serialize(function () { db.run( `INSERT INTO migration VALUES (?, ?, ? , ?, ?, ?, ?)`, [row[0], row[1], row[2], row[3], row[4], row[5], row[6]], function (error) { if (error) { return console.log(error.message); } console.log(`Zeile eingefügt, ID: ${this.lastID}`); } ); }); }); |
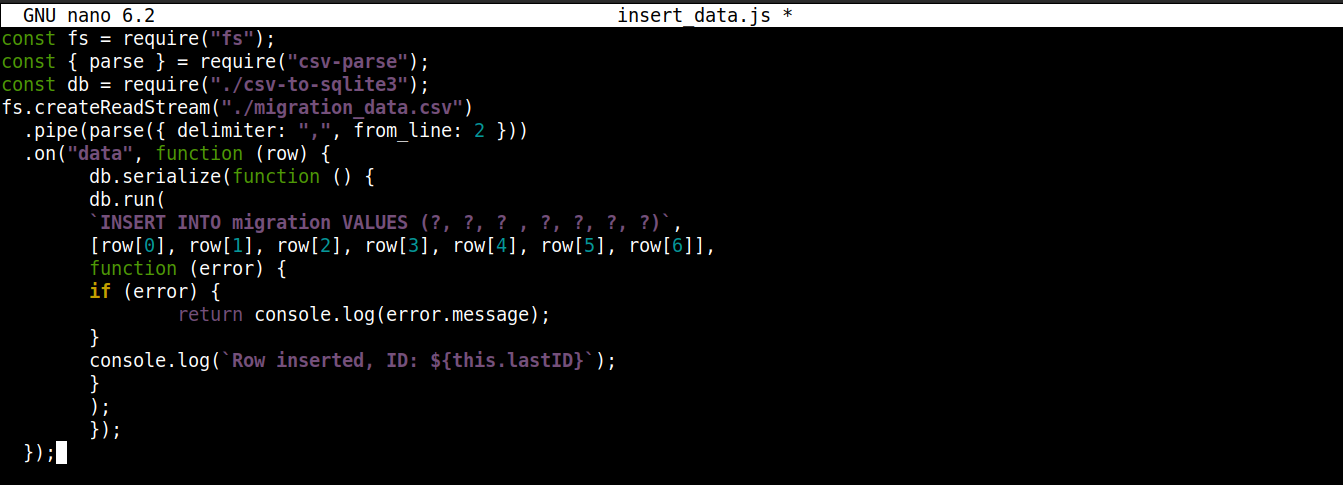
Hier
-
speichern wir das von csv-to-sqlite3.js erhaltene Verbindungsobjekt in der Variablen db.
-
Innerhalb des data-Event-Callbacks (der an den Stream des fs-Moduls angehängt ist) rufen wir die serialize()-Methode für das Verbindungsobjekt auf. Sie stellt sicher, dass die Ausführung einer SQL-Anweisung abgeschlossen ist, bevor die nächste beginnt, wodurch Race Conditions in der Datenbank (gleichzeitige Ausführung konkurrierender Operationen durch das System) verhindert werden.
-
Die serialize() akzeptiert drei Argumente:
-
Das erste Argument ist die SQL-Anweisung.
-
Das zweite Argument ist ein Array.
-
Das dritte Argument ist ein Callback, der ausgeführt wird, wenn Daten erfolgreich oder nicht erfolgreich in die Datenbank eingefügt wurden.
-
Wir sind bereit, das Programm auszuführen. Führen Sie insert_data.js mit Node.js aus:
|
1 |
node insert_data.js |
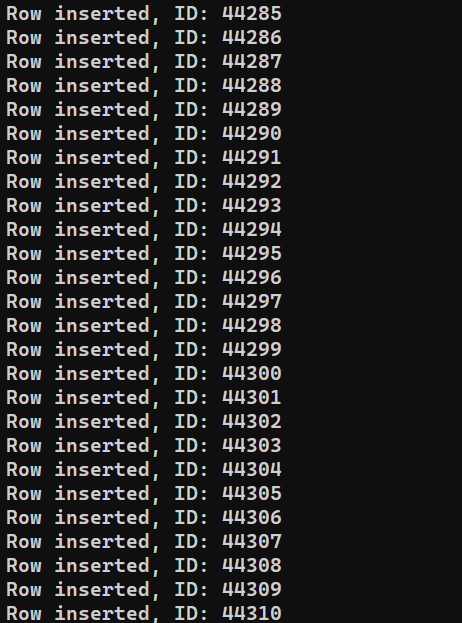
Je nach Systemleistung kann der Vorgang einige Zeit in Anspruch nehmen. Nach Abschluss sollte die Ausgabe jedoch in etwa so aussehen:
Schritt 5 – Schreiben von Daten in eine CSV-Datei
Nach dem letzten Abschnitt haben wir eine database, die alle Datensätze enthält, die wir aus migration_data.csv analysiert haben. In diesem Abschnitt werden wir die Daten aus der Datenbank lesen und in eine separate CSV-Datei schreiben.
Erstellen Sie eine neue JavaScript-Datei, um das Programm zu speichern:
|
1 |
nano write_csv.js |
Fügen Sie zuerst die folgenden Zeilen hinzu. Diese importieren fs und csv-stringify sowie das Datenbankverbindungsobjekt aus csv-to-sqlite3.js:
|
1 2 3 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); |
Als Nächstes fügen wir eine Variable hinzu, die den Namen der CSV-Datei enthält, in die geschrieben werden soll, zusammen mit einem beschreibbaren Stream:
|
1 2 3 4 5 6 7 8 9 10 11 |
const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; |
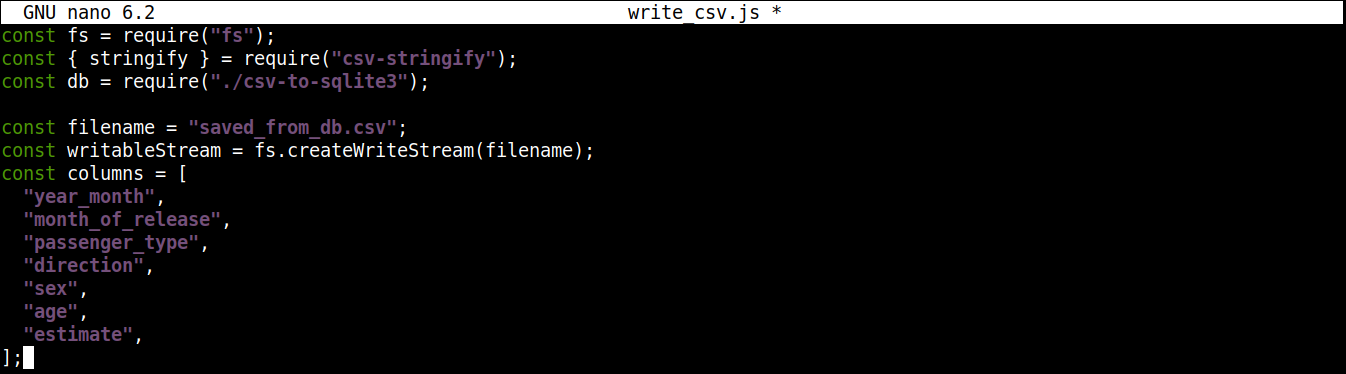
Hier,
-
Die createWriteStream()-Methode nimmt den Dateinamen, in den geschrieben werden soll, als Argument entgegen. Wir nennen die Datei saved_from_db.csv.
-
Die column-Variable speichert ein Array, das alle Namen der Kopfzeile für die CSV-Daten enthält.
Fügen Sie als Nächstes die folgenden Codezeilen hinzu, um Daten aus der Datenbank zu lesen und zu schreiben in saved_from_db.csv:
|
1 2 3 4 5 6 7 8 9 10 11 |
const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
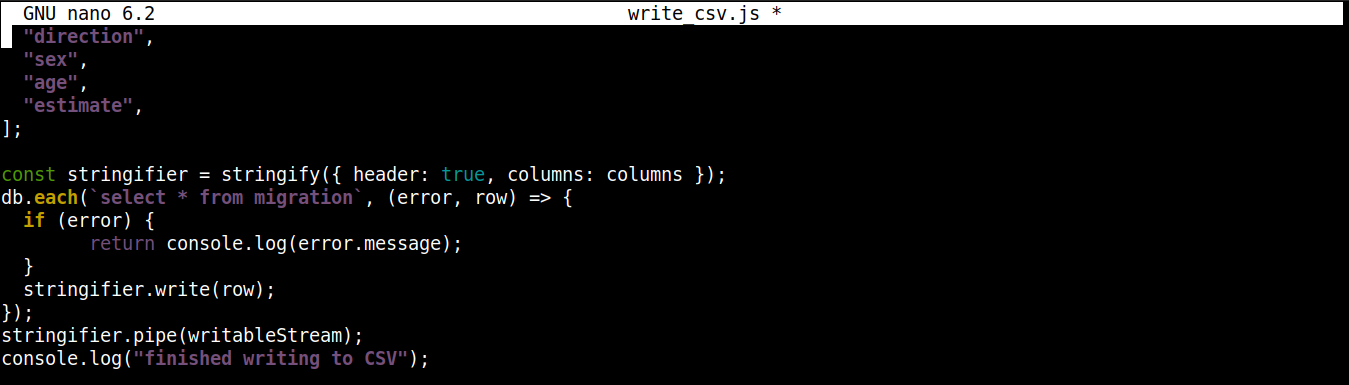
Hier,
-
Wir rufen die stringify()-Methode mit einem Objekt als Argument auf. Dies führt zu einem Transform-Stream, der die Daten von einem Objekt in das CSV-Format konvertiert. Das an stringify() übergebene Objekt hat zwei Eigenschaften:
-
header: Akzeptiert einen booleschen Wert. Wenn der Wert true ist, wird eine Kopfzeile generiert.
-
columns: Akzeptiert ein Array, das die Spaltennamen enthält, die in die erste Zeile der CSV-Datei geschrieben werden sollen, wenn header Folgendes ist: true.
-
-
Die each()-Methode aus dem csv-to-sqlite3-Verbindungsobjekt wird mit zwei Argumenten aufgerufen: der SQL-Anweisung (Lesen von Daten aus der Datenbank) und einem Callback (Behandlung von Erfolg/Fehler).
-
Bei jeder Iteration von each(), pipe() (aus dem stringifier-Stream) beginnt, Daten in Blöcken an den beschreibbaren Stream writableStream zu senden. Jeder Datenblock wird dann geschrieben in saved_from_db.csv.
-
Wenn alle Daten in die CSV-Datei geschrieben wurden, wird eine Erfolgsmeldung auf dem Konsolenbildschirm ausgegeben.
Der fertige Code sollte wie folgt aussehen:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("Schreiben in CSV abgeschlossen"); |
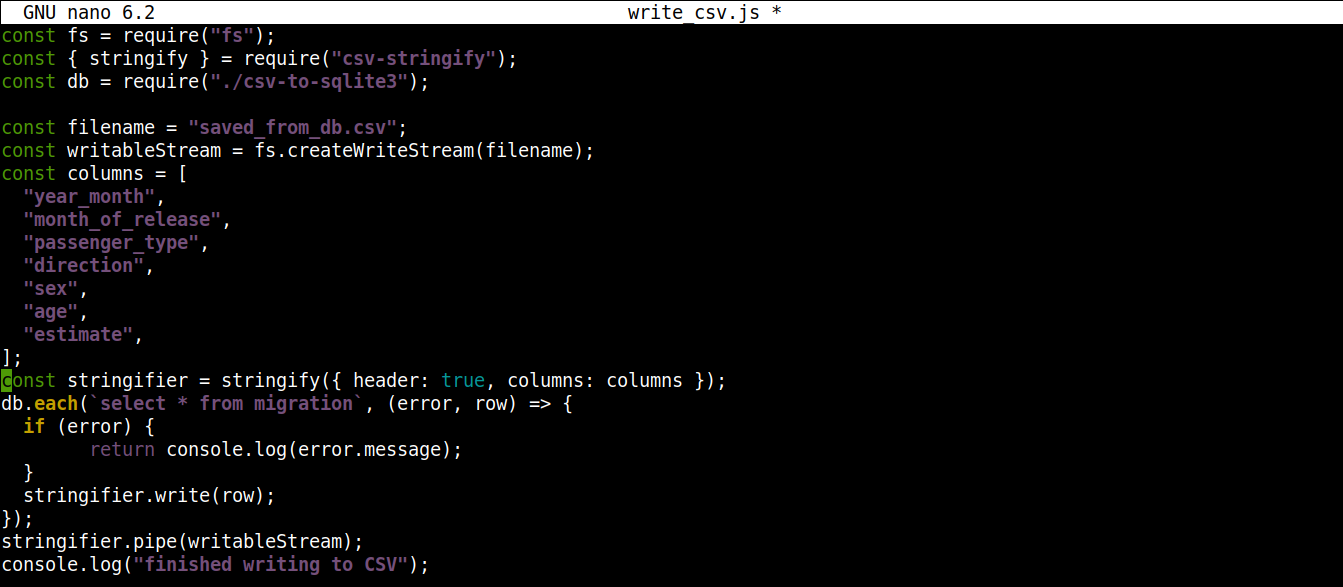
Speichern Sie die Datei und schließen Sie den Editor. Wir können das Programm nun mit Node.js ausführen:
|
1 |
node write_csv.js |
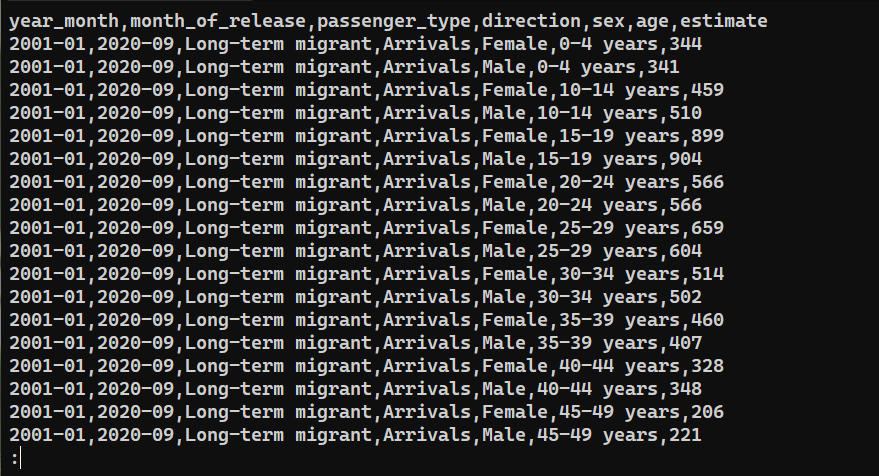
Um zu überprüfen, ob die Daten erfolgreich exportiert wurden, prüfen Sie den Inhalt von saved_from_db.csv:
|
1 |
cat saved_from_db.csv | less |
Fazit
In dieser Anleitung haben wir die Arbeit mit CSV-Dateien in Node.js unter Verwendung der Module node-csv und node-sqlite3 demonstriert. Wir haben mehrere Programme erstellt, um verschiedene Aufgaben zu erfüllen, z. B. das Parsen von Daten aus einer CSV-Datei, das Schreiben der Daten in eine SQLite-Datenbank und das Schreiben von Daten in eine neue CSV-Datei.
Diese Anleitung zeigt nur einen kleinen Teil der Funktionen des node-csv -Moduls. Erfahren Sie mehr über alle seine Funktionen unter CSV-Projekt. Um mehr über node-sqlite3 zu erfahren, lesen Sie die offizielle Dokumentation auf GitHub. Ein weiteres erwähnenswertes Modul ist event-stream, um die Arbeit mit Streams zu vereinfachen.
Möchten Sie Ihr Node.js-Projekt weiter ausbauen? Hier sind einige Node.js-Tutorials, die Sie sich ansehen sollten:
-
Verwendung von Node.js-Modulen mit npm und package.json: Ein Tutorial
-
Wie man eine Node.js (Express.js) App mit Docker auf Ubuntu 20.04 bereitstellt
-
Verbindung von PostgreSQL mit Node.js-Anwendungen: Ein Tutorial
Viel Spaß beim Programmieren!
Kommentare
Noch keine Kommentare. Schreiben Sie den ersten.