

Unternehmen bringen große Datenmengen mit sich, was die Handhabung und Verwaltung erschwert. Traditionell nutzt die Branche seit Jahrzehnten RDBMS-Systeme, aber mit dem Aufkommen von Big Data im 21. Jahrhundert traten NoSQL-Datenbanken (Not only SQL) für unstrukturierte und semistrukturierte Daten in großem Maßstab auf den Plan.
In diesem Beitrag werde ich einen MongoDB-Cluster einrichten.
MongoDB ist eine kostenlose und quelloffene NoSQL-Dokumentendatenbank, die aufgrund ihrer hohen Skalierbarkeit und Flexibilität weit verbreitet ist.
Um MongoDB in der Produktion einzusetzen, empfiehlt es sich, Replica Sets zu verwenden. Replica Sets sind das MongoDB-Äquivalent zu einem Master/Slave-Setup in der relationalen Welt, aber im Gegensatz dazu sind sie sehr unkompliziert einzurichten, da alles integriert ist. Weitere Informationen zu Replica Sets finden Sie unter TutorialsPoint’s Definition des Replikationsprozesses.
Planung Ihres MongoDB-Cloud-Server-Clusters
Ich werde einen Cluster mit 3 Nodes erstellen. Es ist wichtig, ihnen die gleichen Ressourcen zuzuweisen, da jeder von ihnen zum primären (d. h. Master-) Server werden kann. Diese Nodes oder Maschinen können auf jedem Betriebssystem laufen, aber in diesem Tutorial werde ich Ubuntu 18.04 LTS verwenden. Wie Sie das vorinstallierte Image aus der Bibliothek von CloudSigma’s einbinden und einrichten, erfahren Sie in diesem Tutorial.
Da der Sinn eines Replica Sets darin besteht, dass der Cluster den Ausfall eines einzelnen Nodes übersteht, wäre es ziemlich witzlos, wenn alle Ihre Server auf demselben physischen Host befänden. Glücklicherweise bietet CloudSigma etwas an, das sich Verfügbarkeitsgruppen. Das bedeutet, dass Sie das System anweisen können, alle drei Server in verschiedenen Gruppen zusammenzufassen. Auf diese Weise werden sie sich niemals auf demselben physischen Host befinden. Weitere Informationen hierzu sowie zu anderen Sicherheits- und Business-Continuity-Funktionen finden Sie hier.
Es ist auch wichtig, eine 64-Bit-Version von Linux zu verwenden. Der Grund dafür ist schlichtweg, dass MongoDB auf 32-Bit-Systemen nicht gut läuft (mehr dazu hier).
Installation von MongoDB in der Cloud
Dieser Abschnitt ist ziemlich unkompliziert. Verwenden Sie entweder eines der vorkonfigurierten Ubuntu 18.04 Images oder installieren Sie es selbst.
Die CPU-, RAM- und Festplattenkonfiguration ist sehr individuell und hängt von Ihrer Auslastung ab. Für eine kleinere Installation sollten eine 4-GHz-CPU, 4 GB RAM und eine 10-GB-Festplatte (für das System) ausreichen. Wenn Sie Ihre Laufwerke anschließen, stellen Sie sicher, dass Sie VirtIO verwenden. Wenn Sie IDE verwenden, leidet die Leistung erheblich. Da Sie außerdem ein Replica Set erstellen, müssen sich alle Nodes (und App-Server) im selben VLAN befinden.
Im Gegensatz zu vielen anderen Cloud-Anbietern ist es nicht erforderlich, Ihren Speicher mit RAID10 oder ähnlichem zu konfigurieren, um die Leistung zu verbessern. Wie viele unserer Kunden berichten, erhalten Sie bei CloudSigma durch die Verwendung von sowohl SSDs als auch Magnetspeicherplatten direkt eine hervorragende Leistung.
Ich empfehle dennoch, die MongoDB-Daten auf einem separaten Laufwerk zu speichern. Der Grund dafür ist einfach, dass Sie irgendwann möglicherweise Optimierungen am Dateisystem vornehmen müssen, die Sie nicht auf Ihr gesamtes Dateisystem anwenden möchten.
Vor diesem Hintergrund ist es am einfachsten, dieses Laufwerk erst nach der Einrichtung der Server hinzuzufügen. Konzentrieren wir uns für den Moment auf die Systeminstallation. Wenn Sie die Installation selbst vornehmen (anstatt die vorkonfigurierten Systeme zu verwenden), empfehle ich Ihnen, im Boot-Menü F4 zu drücken und ‘Eine minimale virtuelle Maschine installieren’.
Ich erstelle 3 Maschinen mit jeweils folgenden Spezifikationen:
- CPU: 4 GHz
- RAM: 4 GB
- SSD: 10 GB (Ubuntu 18.04 LTS), 20 GB (zusätzliches Laufwerk)
Wie im SSD-Teil aufgeführt, schließe ich ein Laufwerk mit einer Größe von 10 GB an, auf dem Ubuntu 18.04 LTS installiert ist.
Darüber hinaus schließe ich ein weiteres leeres Laufwerk mit einer Größe von 20 GB an, um MongoDB-Daten zu speichern. Die Größe hängt stark von Ihrer Nutzung ab, aber für ein kleines System sollten 20 GB wahrscheinlich ausreichen. Da es jedoch manchmal schwer vorherzusagen ist, wie viele Daten Sie speichern werden, verwenden wir LVM. Dies ermöglicht es Ihnen, später einfach ein weiteres Laufwerk hinzuzufügen und das Volume zu erweitern, ohne von vorne beginnen zu müssen. Alternativ können Sie ein einzelnes Laufwerk verwenden und es später vergrößern mitresize2fs.
Um die Festplatte hinzuzufügen, gehen Sie einfach in den Bereich ‘Drives’, klicken Sie oben auf das Symbol ‘Create a new drive’, geben Sie der neuen Festplatte einen Namen und legen Sie die Größe auf 20 GB fest. Sobald sie gespeichert ist, gehen Sie zu der einzelnen Maschine, an die Sie sie anschließen möchten, und unter dem Bereich „Drives“ der Details dieser Maschine können Sie auf ‘Attach a drive’ klicken und die Festplatte auswählen.
Da Sie nun drei Maschinen haben, können Sie dazu übergehen, die zusätzliche Festplatte, die Sie für Ihren MongoDB-Datenspeicher hinzugefügt haben, an jeder Maschine zu mounten. Ich empfehle, diese Festplatte als Partition hinzuzufügen. Die Verwendung von Partitionierung ermöglicht es dem Betriebssystem, Informationen in jedem Bereich separat zu verwalten. Um die Festplatte als Partition hinzuzufügen, werde ich zuerst alle an unsere Maschine angeschlossenen Festplatten überprüfen. Dazu werde ich den folgenden Befehl ausführen:
|
1 |
fdisk -l |
Wenn ich den Befehl ausführe, erhalte ich die Ausgabe, die die Festplatten und Geräte auf meiner Maschine auflistet.
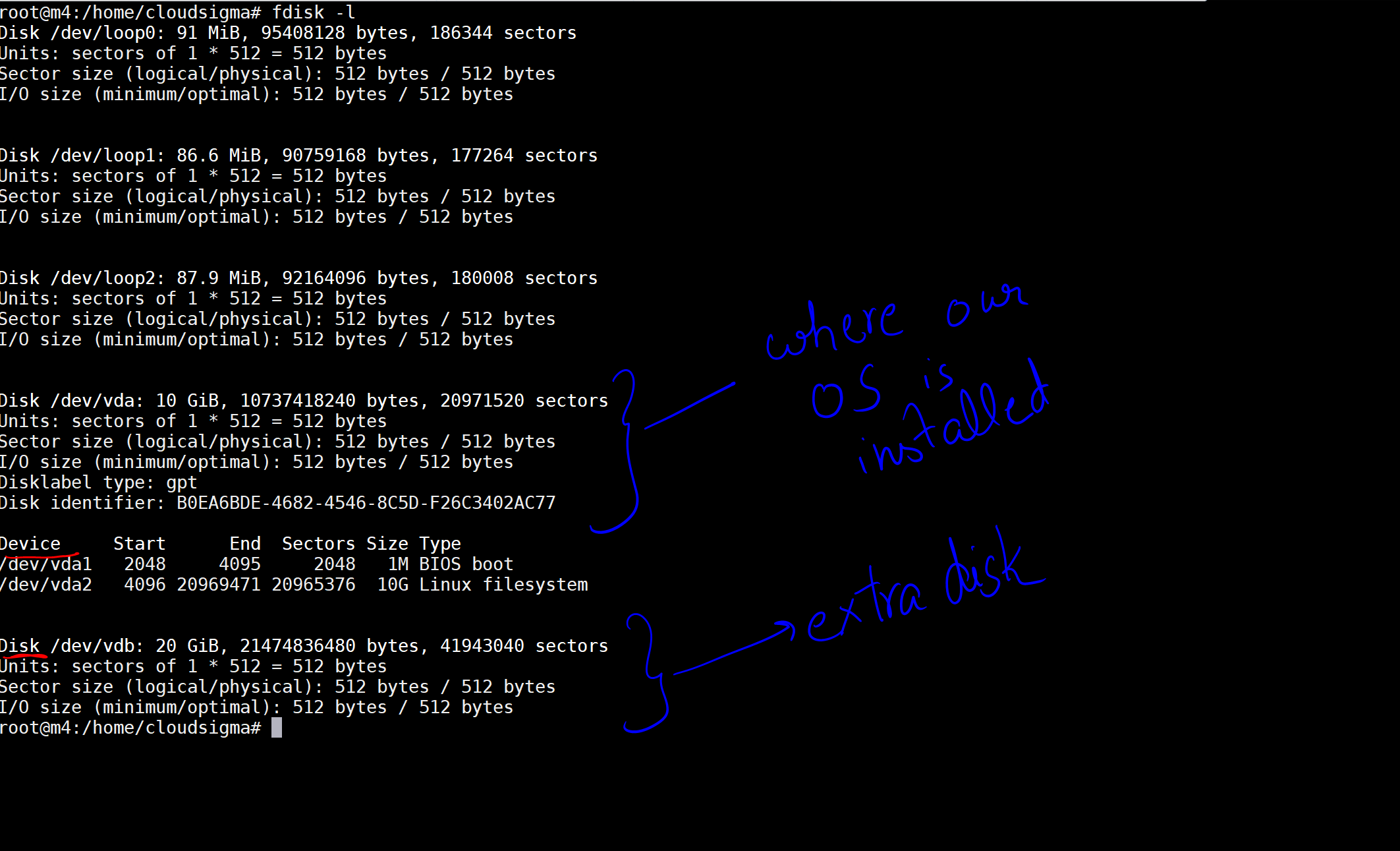
In dem Bild habe ich eine 10-GB-Festplatte als diejenige markiert, auf der unser Betriebssystem installiert ist. Dann gibt es eine weitere Festplatte mit 20 GB, die nun angeschlossen wurde. Der Speicherort der Festplatte ist /dev/vdb. Sie können auf dieser Festplatte mit den folgenden Befehlen eine Partition erstellen:
|
1 |
sudo fdisk /dev/vdb |
Es öffnet das fdisk-Dienstprogramm, ein Befehlszeilen-Dienstprogramm, das Festplattenpartitionierungsfunktionen bereitstellt, mit denen Sie Partitionen auf unserer Festplatte erstellen können. Es erscheint die Eingabeaufforderung “Command (m for help):”, in der Sie n eingeben müssen, um eine neue Partition zu erstellen, und dann einfach die Eingabetaste drücken, um die Standardwerte zu akzeptieren. Und nachdem die Partition erstellt wurde, geben Sie w ein, um die Änderungen zu schreiben. Es würde so aussehen:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Befehl (m für Hilfe): <strong>n</strong> Partitionstyp p primär (0 primär, 0 erweitert, 4 frei) e erweitert (Container für logische Partitionen) Auswählen (Standard p): Verwende Standard Antwort p. Partitionsnummer (1-4, Standard 1): Erster Sektor (2048-41943039, Standard 2048): Letzter Sektor, +Sektoren oder +Größe{K,M,G,T,P} (2048-41943039, Standard 41943039): Erstellt eine neue Partition 1 vom Typ 'Linux' und mit der Größe 20 GiB. Befehl (m für Hilfe): <strong>w</strong> Die Partitionstabelle wurde geändertbeen altered. Rufe ioctl() auf, um -die Partitionstabelle neu einzulesen. Synchronisiere Festplatten. |
Es wurde eine neue Partition 1 vom Typ ‘Linux’ und der Größe 20 GiB erstellt. Da die Partition nun erstellt ist, erstellen wir einen LVM-Pool:
|
1 2 3 |
sudo pvcreate /dev/vdb1 sudo vgcreate mongodb /dev/vdb1 sudo lvcreate -n db -L 19.5g mongodb |
Ich habe ‘19.5g’ eingegeben, da meine Partitionsgröße 20g beträgt. Führen Sie als Nächstes den folgenden Befehl aus, um den Namen der Festplatte herauszufinden:
|
1 |
fdisk -l | grep mongo | awk '{print $2'} |
Formatieren Sie danach die Festplatte mit dem folgenden Befehl im ext4-Format:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
sudo mkfs.ext4 /dev/mapper/mongodb-db Ausgabe: root@m4:/home/cloudsigma# sudo mkfs.ext4 /dev/mapper/mongodb-db mke2fs 1.44.1 (24-Mär-2018) Erzeugen des Dateisystems mit 5217280 4k Blöcken und 1305600 Inodes Dateisystem-UUID: 695a62e6-021d-4fc0-945c-cc51a92d86da Superblock-Backups gespeichert auf Blöcken: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 Zuweisen der Gruppen-Tabellen: erledigt Schreiben der Inode-Tabellen: erledigt Erstellen des Journals (32768 Blöcke): erledigt Schreiben der Superblöcke und Dateisystem-Accounting-Informationen: erledigt |
Als Nächstes erstellen wir einen Ort zum Einhängen der Festplatte und einen Ordner, in dem Ihre MongoDB-Daten gespeichert werden.
|
1 |
sudo mkdir -p /mongodb/data |
Um einen Eintrag in der fstab für Ihre neu einzuhängende Festplatte hinzuzufügen, können Sie direkt den folgenden Befehl verwenden:
|
1 |
echo -e "` blkid | grep mongodb | awk {'print $2'}`\t/mongodb\text4 auto,noexec,rw,sync,nouser\t0\t0" >> /etc/fstab |
In dem Befehl liefert blkid Ihnen eine UUID – Universally Unique Identifier (universell eindeutige Identifikationsnummer) für jede Festplatte. Hier filtere ich diejenige für die MongoDB-Festplatte heraus und kombiniere diese UUID jeweils mit dem Speicherort des Einhängeordners, dem Dateisystemtyp und anderen Optionen für die Festplatte. Ich füge diese Zeile zu /etc/fstab hinzu. Wenn Sie das nicht tun, erhalten Sie beim Einhängen der Festplatte eine Fehlermeldung. Der Eintrag sieht wie folgt aus:
UUID=”695a62e6-021d-4fc0-945c-cc51a92d86da” /mongodb ext4 auto,noexec,rw,sync,nouser 0 0
Jetzt können Sie die Festplatte am Speicherort /mongodb einhängen:
|
1 |
sudo mount /mongodb |
MongoDB installieren
Nachdem das System vorbereitet ist, fahren wir mit der Installation von MongoDB fort. Obwohl Ubuntu eine Version von MongoDB in seinem eigenen Repository anbietet, empfehle ich Ihnen, stattdessen die offizielle MongoDB-Version zu verwenden. Der Grund dafür ist, dass das Ubuntu-Repository bei den Veröffentlichungen ziemlich weit hinterherhinkt. Wenn Sie also das Beste aus MongoDB herausholen wollen, müssen Sie auf die offiziellen Releases zurückgreifen.
Da MongoDB ein eigenes Repository anbietet, können Sie dieses einfach zu Ihrem System hinzufügen und MongoDB dann ganz normal installieren. Hier sind die folgenden Schritte:
Importieren Sie zunächst den öffentlichen Schlüssel, der vom Paketverwaltungssystem verwendet wird:
|
1 |
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4 |
Dann erstelle ich eine Listendatei. Diese enthält das Repository, in dem sich MongoDB befindet, sodass Ihr System es von dort herunterladen kann:
|
1 |
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list |
Jetzt aktualisiere ich meine lokale Paketdatenbank, um die Änderungen zu berücksichtigen.
|
1 |
sudo apt-get update |
Jetzt kann ich das Paket einfach mit dem folgenden Befehl installieren:
|
1 |
sudo apt-get install -y mongodb-org |
Ich habe MongoDB auf jeder der Maschinen installiert.
|
1 |
sudo service mongod start |
Jetzt läuft MongoDB und die Daten auf dem erstellten Laufwerk sind vorhanden. Wenn eine hohe Last und/oder viele Verbindungen erwartet werden, müssen Sie möglicherweise die ulimit-Werte erhöhen.
Wenn Sie mehr Einblick in Ihre Daten erhalten möchten, können Sie sich auch für MongoDBs MMS registrieren, einen kostenlosen cloudbasierten Überwachungsdienst für MongoDB.
Erstellen des Replica Sets für Ihre MongoDB Cloud
Lassen Sie uns nun ein Replica Set erstellen. Zuvor müssen Sie sicherstellen, dass alle Maschinen miteinander kommunizieren können. Fügen Sie dazu diese Einträge in /etc/hosts hinzu
|
1 2 3 |
IP-1 m1.mongo.cluster m1 IP-2 m2.mongo.cluster m2 IP-3 m3.mongo.cluster m3 |
Zur Überprüfung können Sie versuchen, die Maschinen über den Hostnamen anzupingen. Wenn also die IP meiner Maschine 1 IP-1 ist, sagen wir 213.189.123.12, dann schreiben Sie statt
|
1 |
ping 123.189.123.12 |
schreibe ich,
|
1 2 3 |
ping m1.mongo.cluster oder ping m1. |
Wenn Sie die Firewall aktiviert haben (was Sie wirklich tun sollten), stellen Sie sicher, dass die Nodes TCP-Verkehr auf den Ports 28017 und 27017 auf der internen Schnittstelle senden und empfangen können.
Starten Sie nun auf jeder der Maschinen den mongod-Dienst mit den folgenden Befehlen.
Auf Maschine m1,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m1.mongo.cluster |
Als Nächstes auf Maschine m2,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m2.mongo.cluster |
Auf Maschine m3,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m3.mongo.cluster |
Hier
mongod ist der Name des Dienstes
dbpath ist der Speicherort unseres Datenbankverzeichnisses
replSet ist der Name unseres Replikationssets. Er sollte für jede der Maschinen im selben Replica-Set identisch sein
bind_ip ist der Hostname der Maschine, auf der Sie es ausführen.
Sobald Sie den mongod-Dienst gestartet haben, gehen Sie zum primären Server (in meinem Fall habe ich m1 gewählt) und führen Sie mongo aus.
|
1 |
mongo |
Dadurch wird das MongoDB-Terminal gestartet. Initiieren Sie im Terminal das replicaSet mit dem folgenden Befehl. Es erstellt das replicaSet mit Standardkonfigurationen:
|
1 |
rs.initiate() |
Fügen wir nun einfach die anderen beiden Maschinen als Replikate mit den folgenden Befehlen hinzu:
|
1 2 |
rs.add("m2.mongo.cluster") rs.add("m3.mongo.cluster") |
Sie können den Status mit folgendem Befehl überwachen:
|
1 |
rs.status() |
Das ist auch schon alles. Sie sollten nun mit Ihrem MongoDB-Cluster in CloudSigma’s blitzschneller Cloud startklar sein.
Kommentare
Noch keine Kommentare. Schreiben Sie den ersten.