

Der Elastic Stack (früher bekannt als ELK-Stack) ist eine leistungsstarke Lösung für zentralisiertes Logging. Es handelt sich um eine Sammlung von Open-Source-Software, die von Elastic entwickelt wurde. Es ermöglicht Administratoren das Suchen, Analysieren und Visualisieren von Protokollen, die aus beliebigen Quellen in beliebigen Formaten generiert wurden. Dies ist eine Praxis, die als zentralisiertes Logging bekannt ist. Zentralisiertes Logging kann sehr praktisch sein, wenn es darum geht, Probleme mit Servern und Anwendungen genau zu lokalisieren, da es die Suche in allen Protokollen von einem einzigen Ort aus ermöglicht. Es kann auch helfen, Probleme über mehrere Server hinweg zu identifizieren, indem die Protokolle zu einem bestimmten Zeitpunkt korreliert werden.
In dieser Anleitung erfahren Sie, wie Sie den Elastic Stack auf Ubuntu 18.04 installieren. Folgen Sie zuerst unserem Tutorial, um ganz einfach Ihren Ubuntu-Server auf CloudSigma zu installieren.
Der Elastic Stack auf Ubuntu
Der Elastic Stack besteht aus den folgenden Komponenten:
- Elasticsearch: Eine verteilte RESTful-Suchmaschine. Sie speichert alle gesammelten Daten.
- Logstash: Die Datenverarbeitungskomponente des Elastic Stack. Sie sendet eingehende Daten an Elasticsearch.
- Kibana: Eine Weboberfläche, die Such- und Protokollvisualisierungsfunktionen bietet.
- Beats: Ein leichtgewichtiger Datenüberträger für einen bestimmten Zweck. Er kann Daten von zahlreichen Maschinen an Logstash oder Elasticsearch senden.
Sie müssen jede Komponente des Stacks manuell installieren.
Voraussetzungen
Bevor Sie mit der Installation des Elastic Stack fortfahren, müssen mehrere Systemanforderungen erfüllt sein:
- Hardwareanforderungen:
- CPU: 2 CPUs (zugänglich für einen Nicht-Root-Sudo-Benutzer)
- RAM: 4GB
- OpenJDK 11 (das neueste Java-LTS-Release). Um dies zu installieren, werfen Sie einen Blick auf unser Tutorial zur Einrichtung von Java auf Ubuntu 18.04.
- Nginx mit den entsprechenden Konfigurationen. Sie können unserer Anleitung zur Installation von Nginx auf Ubuntu 18.04 folgen, um es einzurichten.
Beachten Sie, dass die Speichermenge von der Anzahl der zu erfassenden und zu speichernden Protokolle abhängt. Zudem verarbeitet der Elastic Stack auch wertvolle Informationen über den Server. Um die Datenübertragung sicher zu halten, empfehlen wir dringend die Konfiguration eines TLS/SSL-Zertifikats. Folgen Sie diesem Tutorial, um ein kostenloses SSL-Zertifikat auf Ihrem Nginx-Server zu erhalten.
Zusätzlich zu einem verschlüsselten Server sind auch die folgenden Schritte erforderlich:
- Ein FQDN (vollständig qualifizierter Domänenname). In dieser Anleitung wird dies <domain> sein.
- Beide DNS-Einträge der folgenden Domänen verweisen auf den Server.
- Ein A-Record mit <domain>, der auf die öffentliche IP des Servers verweist.
- Ein A-Record mit www.<domain>, der auf die öffentliche IP des Servers verweist.
Installation des Elastic Stack
-
Konfiguration des Elastic-Repositorys
Die Komponenten des Elastic Stack sind nicht direkt aus dem offiziellen Ubuntu-Repository verfügbar. Glücklicherweise erlaubt Ubuntu 3.-Anbieter-Repositorys zur Installation von Paketen. Für unseren Zweck werden wir das Elastic-Paket-Repository hinzufügen. Das Repository bietet die neuesten Paket-Updates für alle Elastic-Pakete. Alle Elastic-Pakete sind mit dem Elasticsearch-Signierschlüssel signiert, um Paket-Spoofing zu verhindern. Fügen Sie zuerst den Schlüssel zum Ubuntu-Schlüsselbund hinzu:
|
1 |
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - |
Fügen Sie dann die Elastic-Quellenliste unter dem Verzeichnis „sources.list.d“ hinzu. Dies ist das dedizierte Verzeichnis, das APT zur Suche nach neuen Quellen verwendet:
|
1 |
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list |
Aktualisieren Sie abschließend den APT-Cache:
|
1 |
sudo apt update |
Gemäß der offiziellen Dokumentation wird empfohlen, jede der Komponenten in der in dieser Anleitung gezeigten Reihenfolge zu installieren. Dies stellt sicher, dass sich die Komponenten, von denen jedes Produkt abhängt, an der richtigen Stelle befinden.
-
Installation und Konfiguration von Elasticsearch
Sobald das Elastic-Repository konfiguriert ist, ist APT bereit, alle Elastic-Pakete herunterzuladen und zu installieren. Führen Sie den folgenden Befehl aus, um Elasticsearch zu installieren:
|
1 |
sudo apt install elasticsearch |
Jetzt können Sie Elasticsearch konfigurieren. Die Datei „elasticsearch.yml“ bietet Konfigurationsoptionen für Cluster, Nodes, Pfade, Netzwerke, Speicher, Gateway und andere. Die meisten davon sind in der Datei bereits vorkonfiguriert. Öffnen Sie als Nächstes die Elasticsearch-Konfigurationsdatei mit einem Texteditor Ihrer Wahl:
|
1 |
sudo vim /etc/elasticsearch/elasticsearch.yml |
Elasticsearch lauscht standardmäßig auf Port 9200 von überall her. Wir empfehlen, den externen Zugriff auf Elasticsearch einzuschränken, um zu verhindern, dass Außenstehende Daten lesen oder die Elasticsearch-Cluster über die REST-API herunterfahren. Um den Zugriff auf Elasticsearch einzuschränken und die Sicherheit zu erhöhen, entfernen Sie das Kommentarzeichen vor der folgenden Zeile und ersetzen Sie deren Wert:
|
1 |
network.host: localhost |
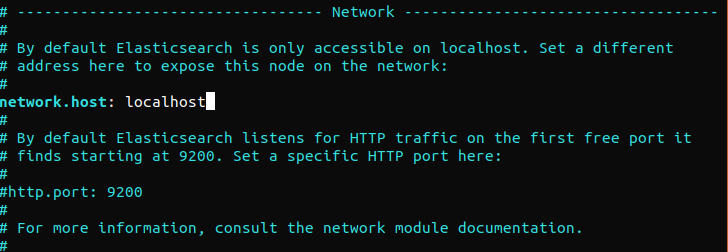
Wenn Elasticsearch auf eine bestimmte IP-Adresse lauschen soll, ersetzen Sie „localhost“ durch die Ziel-IP-Adresse. Dies ist die Mindestanforderung an die Konfiguration, bevor Sie Elasticsearch ausführen. Speichern und schließen Sie die Konfigurationsdatei. Starten Sie als Nächstes den Elasticsearch-Dienst. Es kann einen Moment dauern, bis Elasticsearch startet:
|
1 |
sudo systemctl start elasticsearch |
Danach müssen Sie sicherstellen, dass Elasticsearch bei jedem Systemstart des Servers automatisch gestartet wird:
|
1 |
sudo systemctl enable elasticsearch |
Der folgende Befehl überprüft, ob der Elasticsearch-Dienst ausgeführt wird. Dazu muss lediglich eine HTTP-Anfrage gesendet werden:
|
1 |
curl -X GET "localhost:9200" |
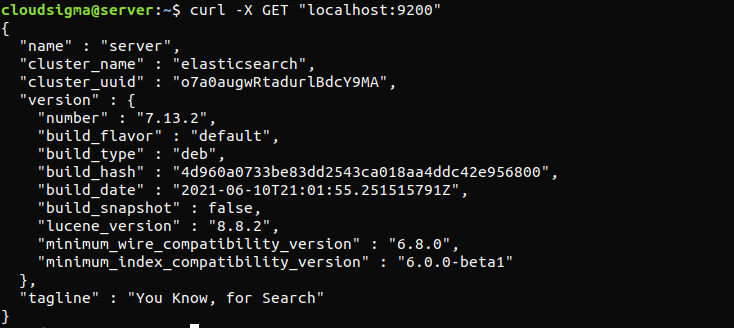
Die Antwort wird in etwa so aussehen. Es handelt sich um eine Antwort, die einige grundlegende Informationen über den lokalen Node anzeigt.
Installation und Konfiguration des Kibana-Dashboards
Kibana ist direkt über das Elastic-Repository verfügbar. Beachten Sie, dass Sie Kibana erst installieren sollten, nachdem Sie bereits Elasticsearch installiert haben. Vorausgesetzt, das Repository ist bereits verfügbar, kann APT Kibana direkt herunterladen und installieren:
|
1 |
sudo apt install kibana |
Nach der Installation aktivieren und starten Sie den Kibana-Dienst:
|
1 2 |
sudo systemctl enable kibana sudo systemctl start kibana |
Standardmäßig ist Kibana so konfiguriert, dass es nur auf „localhost“ lauscht. Für den externen Zugriff ist die Konfiguration eines Reverse-Proxys erforderlich. Hier wird Nginx als Reverse-Proxy fungieren. Verwenden Sie den Befehl openssl, um einen Kibana-Admin-Benutzer zu erstellen. Dies ist das Benutzerkonto für den Zugriff auf die Kibana-Weboberfläche. In diesem Beispiel lautet der Benutzername „kibana_admin“. Um eine bessere Sicherheit zu gewährleisten, empfehlen wir die Verwendung eines unüblichen Benutzernamens. Der folgende Befehl erstellt einen Admin-Benutzer für Kibana. Der Benutzername und das Passwort werden generiert und in der Datei „htpasswd.users“ gespeichert. Nginx muss so konfiguriert werden, dass es diesen Benutzernamen und dieses Passwort verwendet:
|
1 |
echo "kibana_admin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users |
Geben Sie bei der Aufforderung ein Passwort ein und bestätigen Sie es. Dieses Passwort wird für den Zugriff auf die Kibana-Benutzeroberfläche wichtig sein. Danach müssen Sie eine Nginx-Server-Block-Datei erstellen. Zur Veranschaulichung wird diese example.com heißen. Es kann auch jeder andere beschreibende Name sein. Wenn FQDN- und DNS-Einträge für den Server konfiguriert sind, kann der Dateiname auch nach dem FQDN benannt werden:
|
1 |
sudo vim /etc/nginx/sites-available/example.com |
Falls bereits Inhalte vorhanden sind, entfernen Sie diese und ersetzen Sie sie durch die folgenden Codezeilen:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
server { listen 80; server_name example.com; auth_basic "Restricted Access"; auth_basic_user_file /etc/nginx/htpasswd.users; location / { proxy_pass http://localhost:5601; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } } |
Speichern und schließen Sie die Datei. Erstellen Sie einen symbolischen Link der neuen Konfiguration im Verzeichnis „sites-enabled“. Wenn bereits ein Link mit demselben Dateinamen existiert, ist dieser Schritt möglicherweise nicht erforderlich:
|
1 |
sudo ln -s /etc/nginx/sites-available/example.com /etc/nginx/sites-enabled/example.com |
Der folgende Befehl veranlasst Nginx zu prüfen, ob ein Syntaxfehler vorliegt:
|
1 |
sudo nginx -t |
Wenn ein Syntaxproblem vorliegt, stellen Sie sicher, dass der Inhalt der Datei richtig platziert wurde. Starten Sie als Nächstes den Nginx-Dienst neu:
|
1 |
sudo systemctl restart nginx |
Weisen Sie UFW an, Verbindungen zu Nginx zuzulassen:
|
1 |
sudo ufw allow 'Nginx Full' |
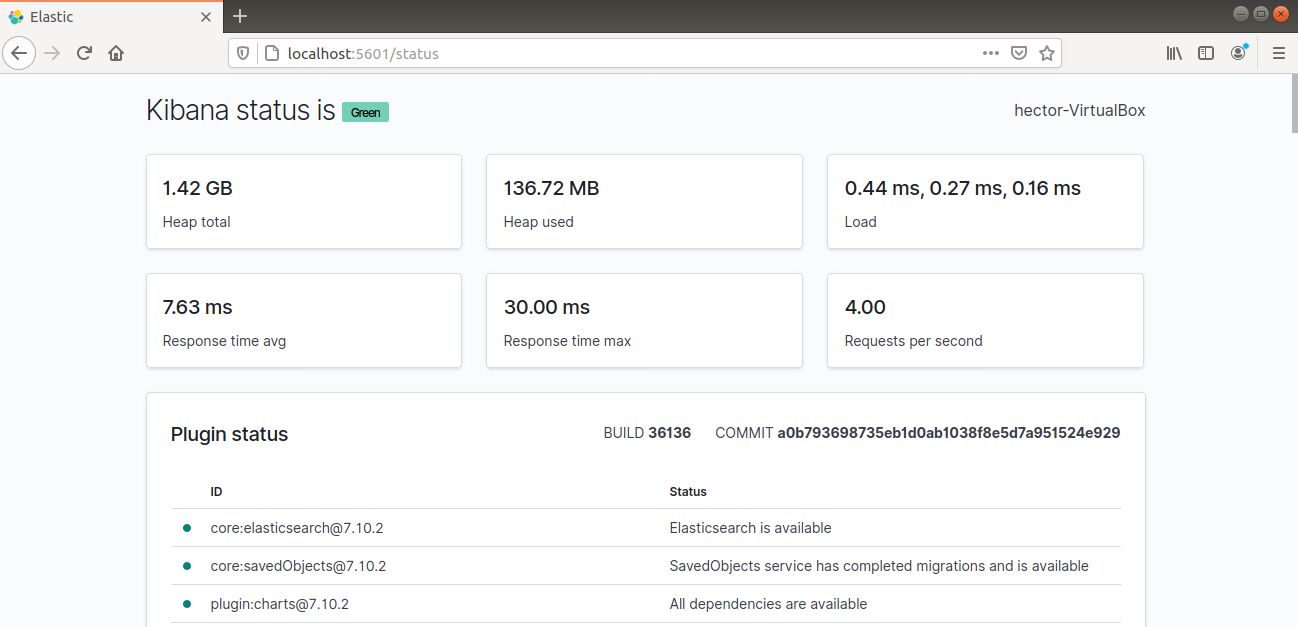
Kibana sollte nun über den FQDN oder die öffentliche IP-Adresse des Elastic Stack-Servers erreichbar sein. Überprüfen Sie die Statusseite des Kibana-Servers:
|
1 |
http://<server_ip>:5601/status |
Installieren und Konfigurieren von Logstash
Während Beats Daten direkt an die Datenbank von Elasticsearch’s senden kann, wird empfohlen, Logstash für die Verarbeitung der Daten zu verwenden. Logstash kann die Daten sammeln und in ein gemeinsames Format konvertieren, bevor sie in eine andere Datenbank exportiert werden. Führen Sie den folgenden APT-Befehl aus, um Logstash zu installieren:
|
1 |
sudo apt install logstash |
Sobald die Installation abgeschlossen ist, ist es an der Zeit, Logstash zu konfigurieren. Die Konfigurationsdateien von Logstash liegen im JSON-Format vor. Sie finden sie alle im Verzeichnis „/etc/logstash/conf.d“. Es ist hilfreich, sich Logstash als eine Pipeline vorzustellen, die an einem Ende Daten aufnimmt, diese verarbeitet und an das Ziel weiterleitet. Eine Logstash-Pipeline erfordert zwei obligatorische Elemente – input und output mit einem optionalen Element – filter. Das input-Plugin nimmt die Daten auf, das filter-Plugin verarbeitet die Daten und das output-Plugin schreibt die Daten an das Ziel. Der folgende Befehl erstellt eine Konfigurationsdatei, die Logstash für die Filebeat-Eingabe einrichtet:
|
1 |
sudo vim /etc/logstash/conf.d/02-beats-input.conf |
Geben Sie die folgende input-Konfiguration ein. Sie beschreibt eine beats-Eingabe, die auf Port 5044 über TCP lauscht:
|
1 2 3 4 5 |
input { beats { port => 5044 } } |
Der nächste Schritt besteht darin, eine Konfigurationsdatei namens „10-syslog-filter.conf“ zu erstellen. Wir werden sie verwenden, um einen Filter für syslogs (Systemprotokolle) einzurichten:
|
1 |
sudo vim /etc/logstash/conf.d/10-syslog-filter.conf |
Geben Sie den folgenden syslog-Konfigurationscode ein. Dieser Code ist direkt aus dem Elastic-Leitfaden verfügbar. Dieser Code erklärt die input-Konfiguration für Logstash:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
input{ beats{ port => 5044 host => "0.0.0.0" } } filter { if [fileset][module] == "system" { if [fileset][name] == "auth" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] } pattern_definitions => { "GREEDYMULTILINE"=> "(.|\n)*" } remove_field => "message" } date { match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } geoip { source => "[system][auth][ssh][ip]" target => "[system][auth][ssh][geoip]" } } else if [fileset][name] == "syslog" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] } pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" } remove_field => "message" } date { match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } } } } |
Die nächste Konfigurationsdatei befasst sich mit der Ausgabe. Öffnen Sie eine neue Datei namens „30-elasticsearch-output.conf“:
|
1 |
sudo vim /etc/logstash/conf.d/30-elasticsearch-output.conf |
Geben Sie den folgenden Code ein. Dieser Code erklärt Logstash die Ausgabekonfiguration:
|
1 2 3 4 5 6 7 |
output { elasticsearch { hosts => ["localhost:9200"] manage_template => false index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" } } |
Testen Sie die Logstash-Konfiguration. Führen Sie dann den folgenden Befehl aus:
|
1 |
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t |
Wenn kein Fehler auftritt, gibt Logstash die folgende Erfolgsmeldung aus. Wenn es nicht erfolgreich war, stellen Sie sicher, dass alle Konfigurationsdateien die richtigen Codes enthalten. Starten und aktivieren Sie schließlich den Logstash-Dienst:
|
1 2 |
sudo systemctl start logstash sudo systemctl enable logstash |
Da Logstash nun erfolgreich läuft und vollständig konfiguriert ist, installieren wir Filebeat.
Installieren und Konfigurieren von Filebeat
Der Elastic Stack verwendet Data Shipper, bekannt als „Beats“, um Daten aus verschiedenen Quellen zu sammeln und diese an Logstash/Elasticsearch zu übertragen. Hier ist eine kurze Liste der verfügbaren Beats von Elastic:
- Filebeat: Sammeln/Übertragen von Logdateien.
- Metricbeat: Sammeln/Übertragen von Metriken aus Systemen und Diensten.
- Packetbeat: Sammeln/Analysieren von Netzwerkdaten.
- Winlogbeat: Sammeln von Windows-Ereignisprotokollen.
- Auditbeat: Sammeln von Linux-Audit-Framework-Daten und Überwachen der Dateiintegrität.
- Heartbeat: Überwachen von Diensten auf ihre Verfügbarkeit.
Für die Zwecke dieses Tutorials benötigen wir Filebeat, um lokale Logs an den Elastic Stack zu übertragen. Installieren Sie zuerst Filebeat:
|
1 |
sudo apt install filebeat |
Sie können nun Filebeat konfigurieren. Zuerst muss es eine Verbindung zu Logstash herstellen. Wir werden die Beispielkonfiguration verwenden, die mit Filebeat geliefert wird. Öffnen Sie die Konfigurationsdatei in einem Texteditor. Beachten Sie, dass die richtige Einrückung wichtig ist, da die Datei im YAML-Format vorliegt:
|
1 |
sudo vim /etc/filebeat/filebeat.yml |
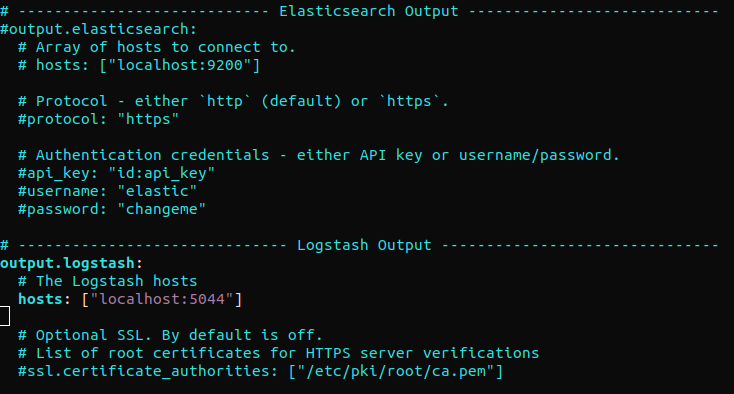
Suchen Sie den Abschnitt „output.elasticsearch“ und kommentieren Sie die folgenden Zeilen aus. Dadurch wird Filebeat so konfiguriert, dass Ereignisse zur weiteren Verarbeitung direkt an Elasticsearch/Logstash gesendet werden. Springen Sie als Nächstes zum Abschnitt „output.logstash“. Heben Sie anschließend die Auskommentierung der folgenden Zeilen auf:
|
1 2 3 4 5 6 7 |
#output.elasticsearch: # Array von Hosts, zu denen eine Verbindung hergestellt werden soll. # hosts: ["localhost:9200"] output.logstash: # Die Logstash-Hosts hosts: ["localhost:5044"] |
Filebeat unterstützt Module, die seine Funktionalität erweitern können. In diesem Tutorial verwenden wir das System-Modul, das vom Systemprotokollierungsdienst gängiger Linux-Distributionen generierte Protokolle sammelt und analysiert. Aktivieren Sie das Filebeat-Systemmodul:
|
1 |
sudo filebeat modules enable system |
Der folgende Filebeat-Befehl listet alle aktivierten und deaktivierten Module auf:
|
1 |
sudo filebeat modules list |
Standardmäßig ist Filebeat so eingestellt, dass es den Standardpfaden für Syslog- und Autorisierungsprotokolle folgt. Die Parameter der Module sind in der Konfigurationsdatei „/etc/filebeat/modules.d/system.yml“ verfügbar.
Der nächste Schritt besteht darin, die Indexvorlage in Elasticsearch zu laden. Ein Elasticsearch-Index bezeichnet eine Sammlung von Dokumenten mit ähnlichen Eigenschaften. Jeder Index hat einen Namen. Der Name ist erforderlich, wenn verschiedene Operationen darin durchgeführt werden. Die Indexvorlage wird automatisch jedes Mal angewendet, wenn ein neuer Index erstellt wird. Laden Sie als Nächstes die Vorlage:
|
1 |
sudo filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]' |
Filebeat enthält standardmäßig ein Beispiel-Dashboard für Kibana. Es hilft, Filebeat-Daten in Kibana zu visualisieren. Vor der Verwendung des Dashboards ist es jedoch erforderlich, das Indexmuster zu erstellen und die Dashboards in Kibana zu laden. Während die Dashboards geladen werden, kontaktiert Filebeat Elasticsearch für Versionsinformationen. Zum Laden von Dashboards bei aktiviertem Logstash muss die Logstash-Ausgabe deaktiviert und die Elasticsearch-Ausgabe aktiviert sein. Der folgende Befehl erledigt dies:
|
1 |
sudo filebeat setup -e -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601 |
Schließlich können Sie Filebeat starten:
|
1 2 |
sudo systemctl start filebeat sudo systemctl enable filebeat |
Jetzt ist es an der Zeit, die Konfiguration des Elastic Stacks zu testen. Wenn er richtig konfiguriert wurde, sieht die Ausgabe in etwa so aus:
|
1 |
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty' |
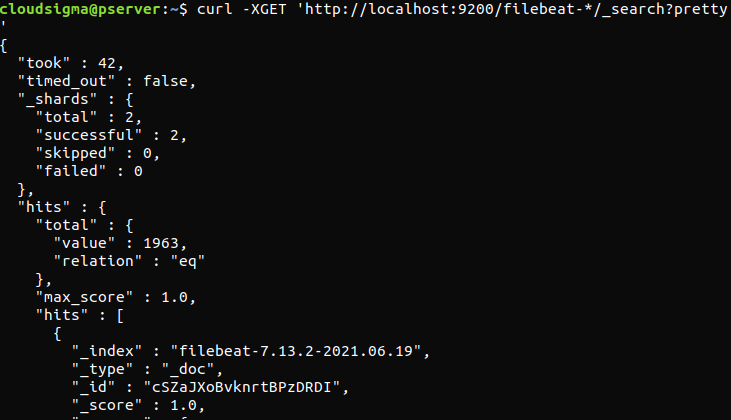
Wenn die Ausgabe insgesamt 0 Treffer meldet, lädt Elasticsearch keine Protokolle unter dem von uns gesuchten Index. Dies weist darauf hin, dass ein Fehler bei der Konfiguration vorlag. Wenn die Ausgabe wie erwartet war, ist der Elastic Stack erfolgreich konfiguriert.
Kibana-Dashboards Übersicht
Jetzt ist es an der Zeit, die bereits installierte Kibana-Weboberfläche zu erkunden. Öffnen Sie zuerst das Kibana-Dashboard. Es sollte sich unter dem FQDN oder der öffentlichen IP-Adresse des Elastic Stack-Servers befinden:
|
1 |
http://<server_ip>:5601 |
Geben Sie die zuvor generierten Anmeldedaten ein. Nach dem Einloggen sieht das Dashboard wie folgt aus:
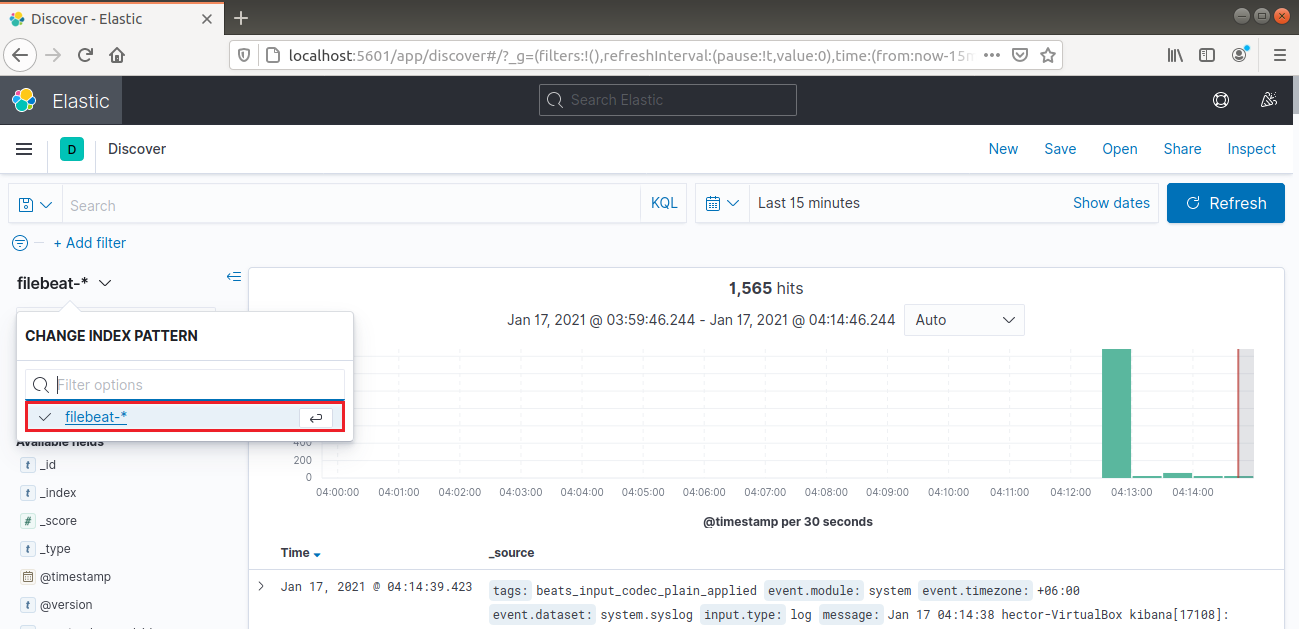
Wählen Sie in der linken Navigationsleiste „Discover“. Wählen Sie dann das Muster „filebeat-*“. Es zeigt alle Protokolle an, die in den letzten 15 Minuten gesammelt wurden. Es ist möglich, Protokolle zu suchen und zu durchsuchen sowie das Dashboard anzupassen:
Gehen Sie in der linken Navigationsleiste auf Dashboard >> Filebeat System. Hier sind alle Beispiel-Dashboards aus dem Systemmodul von Filebeat verfügbar.
Im folgenden Beispiel werden verschiedene Statistiken basierend auf den Syslog-Meldungen detailliert dargestellt:
Es kann auch berichtet werden, welche Benutzer Befehle mit sudo ausgeführt haben:
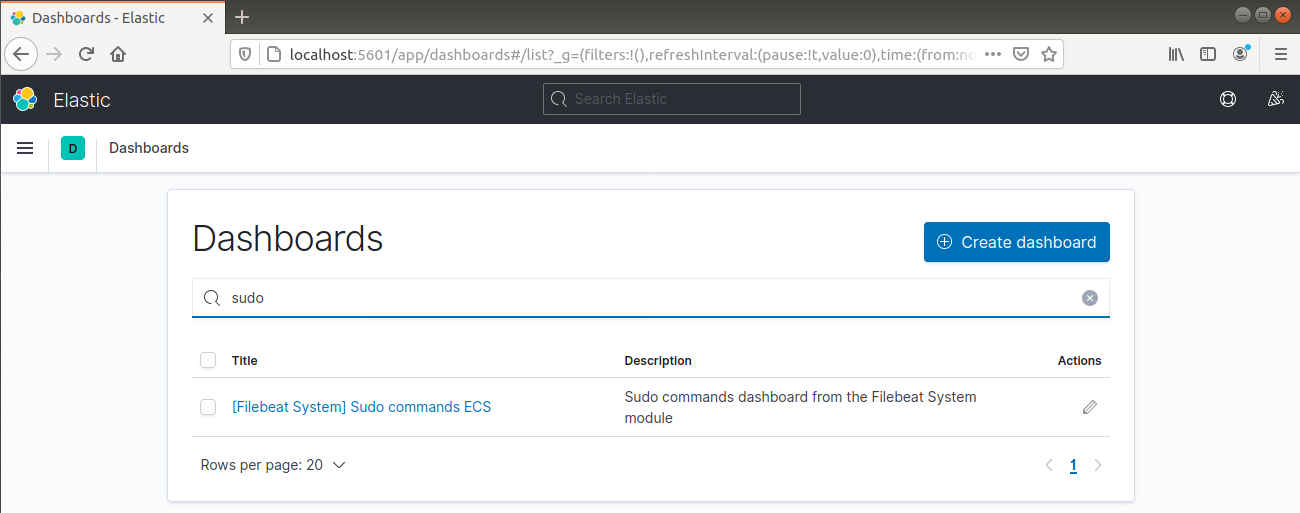
Schließlich bietet Ihnen Kibana die Möglichkeit, viele andere Funktionalitäten wie Grafiken und Filterung zu erkunden, also zögern Sie nicht, auf eigene Faust auf Entdeckungsreise zu gehen.
Schlussgedanken
Der Elastic Stack ist eine leistungsstarke Lösung zur Analyse von Systemprotokollen. Bitte beachten Sie, dass zwar alle Protokolle oder indizierten Daten an Logstash gesendet werden können, unter Verwendung von Beats, diese jedoch nützlicher werden, wenn sie durch Logstash-Filter analysiert und strukturiert werden.
Frohes Schaffen!
Kommentare
Noch keine Kommentare. Schreiben Sie den ersten.