

Web-Scraping, Web-Crawling, Web-Harvesting oder Web-Datenextraktion sind Synonyme für das Extrahieren von Daten aus Webseiten im Internet. Web-Scraper oder Web-Crawler sind Tools, die Webseiten programmgesteuert durchlaufen und die benötigten Daten extrahieren. Diese Daten, bei denen es sich in der Regel um große Textmengen handelt, können für analytische Zwecke verwendet werden, um Produkte zu verstehen oder um die eigene Neugier auf eine bestimmte Webseite zu befriedigen.
Wenn Sie sich fragen, wie Sie beim Web-Crawling vorgehen können, zeigen wir Ihnen die Grundlagen des Web-Scrapings anhand eines einfachen Datensatzes. Sie sollten dem Tutorial unabhängig von Ihren Programmierkenntnissen folgen können. Für das praktische Beispiel verwenden wir unseren CloudSigma-Blog. Wir werden versuchen, Informationen über die Tutorials auf unserer Blog-Seite zu erhalten. Wenn Sie das Fazit dieses Tutorials lesen, werden Sie einen funktionierenden Web-Scraper haben, der mit Python 3 erstellt wurde, der mehrere Seiten in unserem Blog-Bereich crawlt und die Daten dann auf Ihrem Bildschirm anzeigt.
Mit dem Wissen aus der Erstellung dieses einfachen Web-Scrapers können Sie diesen erweitern und Ihre eigenen Web-Scraper erstellen. Das sollte Spaß machen, fangen wir an!
Voraussetzungen
Dies ist ein praktisches Tutorial, daher sollten Sie über eine lokale Entwicklungsumgebung für Python 3 verfügen, um gut folgen zu können. Zuerst können Sie sich auf unser Tutorial beziehen, wie Sie Python 3 installieren und eine lokale Programmierumgebung auf Ubuntu einrichten.
Scrapy
Web-Scraping umfasst zwei Schritte: Der erste Schritt besteht darin, Webseiten zu finden und herunterzuladen, der zweite Schritt darin, diese Webseiten zu durchsuchen und Informationen daraus zu extrahieren.
Es gibt eine Reihe von Möglichkeiten und Bibliotheken, mit denen ein Web-Scraper in vielen Programmiersprachen von Grund auf neu erstellt werden kann. Dies kann jedoch in Zukunft zu Problemen führen, wenn Ihr Web-Scraper komplex wird oder wenn Sie mehrere Seiten mit unterschiedlichen Einstellungen und Mustern gleichzeitig crawlen müssen. Es kann eine ziemlich mühsame Aufgabe sein, herauszufinden, wie Sie Ihre gescrapten Daten zwischen verschiedenen Formaten wie CSV, XML oder JSON konvertieren.
Während einige die Herausforderung schätzen mögen, ihren eigenen Web-Scraper von Grund auf neu zu bauen, ist es besser, das Rad nicht neu zu erfinden, sondern auf einer bestehenden Bibliothek aufzubauen, die all diese Probleme löst. Wir werden Scrapy, eine Python-Bibliothek, zusammen mit Python 3 verwenden, um den Web-Scraper in diesem Tutorial zu implementieren. Scrapy ist ein Open-Source-Tool und eine der beliebtesten und leistungsstärksten Python-Web-Scraping-Bibliotheken. Scrapy wurde entwickelt, um einige der gängigen Funktionen zu handhaben, die alle Scraper haben sollten. Auf diese Weise müssen Sie das Rad nicht jedes Mal neu erfinden, wenn Sie einen Web-Crawler implementieren möchten. Mit Scrapy wird der Prozess des Erstellens eines Scrapers einfach und macht Spaß.
Scrapy ist verfügbar über PyPi, allgemein bekannt als pip – dem Python Package Index. PyPi ist ein gemeinschaftliches Repository, das die meisten Python-Pakete hostet. Wenn Sie Python 3 in Ihrer lokalen Entwicklungsumgebung installieren und einrichten, wird auch pip installiert, mit dem Sie Python-Pakete installieren können.
Schritt 1: So erstellen Sie einen einfachen Web-Scraper
Führen Sie zuerst den folgenden Befehl aus, um Scrapy zu installieren:
|
1 |
pip install scrapy |
Optional können Sie den offiziellen Installationsanweisungen für Scrapy auf der Dokumentationsseite folgen. Wenn Sie Scrapy erfolgreich installiert haben, erstellen Sie einen Ordner für das Projekt mit einem Namen Ihrer Wahl:
|
1 |
mkdir cloudsigma-crawler |
Navigieren Sie in den Ordner und erstellen Sie die Hauptdatei für den Code. Diese Datei wird den gesamten Code für dieses Tutorial enthalten:
|
1 |
touch main.py |
Wenn Sie möchten, können Sie die Datei anstelle des obigen Befehls auch mit Ihrem Texteditor oder Ihrer IDE erstellen.
Öffnen Sie als Nächstes die Datei und lassen Sie uns mit der Erstellung eines einfachen Scrapers beginnen, der Scrapy verwendet. Wir werden eine Python-Klasse erstellen, die scrapy.Spider erweitert, eine grundlegende Spider-Klasse von Scrapy. Diese Klasse hat zwei erforderliche Attribute, wie unten definiert:
- name — ein String-Name zur Identifizierung des Spiders (Sie können einen Namen Ihrer Wahl eingeben).
- start_urls — ein Array, das eine Liste von URLs enthält, von denen aus gecrawlt werden soll. Wir beginnen mit einer URL.
Fügen Sie das folgende Code-Snippet in der geöffneten Datei hinzu, um den grundlegenden Spider zu erstellen:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
Nachfolgend finden Sie eine Erklärung für jede Codezeile:
Die erste Zeile importiert Scrapy, sodass wir die verschiedenen Klassen verwenden können, die das Paket bereitstellt.
In der nächsten Zeile erweitern wir die von Scrapy bereitgestellte Spider-Klasse und erstellen eine Unterklasse namens CloudSigmaCrawler. Durch das Erweitern einer Klasse (Spider) erhalten wir Zugriff auf die Eigenschaften der Klasse, die wir nun in unserem Code verwenden können. In diesem Fall verfügt die Spider-Klasse über Methoden und Verhaltensweisen, die definieren, wie URLs gefolgt und Daten von Webseiten extrahiert werden. Sie weiß jedoch nicht, welchen URLs sie folgen oder welche Daten sie extrahieren soll. Durch das Erweitern können wir den Methoden die erforderlichen Informationen bereitstellen. Um mehr über Unterklassenbildung und Erweiterung zu erfahren, lesen Sie weiter unter Prinzipien der objektorientierten Programmierung.
In unserem CloudSigmaCrawler definieren wir die erforderlichen Attribute. Zuerst benennen wir unseren Spider cloudsigma_crawler. Dann geben wir eine einzelne URL an, bei der gestartet werden soll: https://blog.cloudsigma.com/blog/. Das Öffnen dieser URL führt Sie zur CloudSigma-Blogseite 1, die einige der vielen Tutorials enthält.
Zeit, den Scraper zu testen. Sie haben einige Optionen. Wenn Sie beispielsweise eine IDE verwenden, wie die PyCharm Community Edition von JetBrains, verfügt diese wahrscheinlich über eine Schaltfläche, auf die Sie einfach klicken können, um das Skript auszuführen. Eine andere Möglichkeit besteht darin, Python-Dateien auf die typische Weise über die Befehlszeile auszuführen: python path/to/file.py oder py path/to/file.py. Eine weitere Option ist Scrapys Befehlszeilen-schnittstelle. Scrapy verfügt über eine eigene Befehlszeilenschnittstelle, die beim Starten eines Scrapers hilft. Geben Sie den folgenden Befehl ein, um den Scraper zu starten:
|
1 |
scrapy runspider main.py |
Abhängig von der installierten Scrapy-Bibliotheksversion sollten Sie eine Ausgabe sehen, die in etwa wie folgt aussieht:
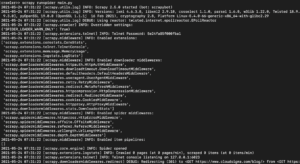
Wie Sie sehen können, ist die Ausgabe recht lang, daher haben wir nur einige Teile ausgewählt. Folgendes ist passiert, als Sie den Befehl ausgeführt haben:
- Der Scraper wurde initialisiert. Daher hat er zusätzliche Komponenten und Erweiterungen geladen, die er benötigt, um URLs zu folgen und Daten daraus zu lesen.
- Unter Verwendung der in der Liste start_urls bereitgestellten URL hat er das HTML von der Seite abgerufen. Dies ist ein ähnlicher Prozess, den auch der Browser beim Öffnen von Webseiten durchläuft.
- Nach dem Abrufen des HTML wird dieses an die parse-Methode übergeben, die wir noch nicht definiert haben. Im Moment tut sie nichts, weshalb der Spider einfach beendet wird, ohne eine Verarbeitung durchzuführen. Wir werden das Verhalten der parse-Methode im nächsten Schritt definieren.
Schritt 2: So extrahieren Sie Daten von einer Seite
In Schritt 1 haben wir nur einen einfachen Scraper implementiert, der eine HTML-Seite abruft, danach aber nichts weiter tut. In diesem Abschnitt geben wir Anweisungen zum Extrahieren von Daten. Auf der CloudSigma Blog-Seite, von der wir Daten extrahieren möchten, fallen Ihnen vielleicht einige Dinge auf, wie zum Beispiel:
- Der Header, der auf allen Seiten vorhanden ist.
- Das Navigationsmenü und das Suchfilterfeld.
- Die eigentliche Liste der Tutorials in einem Rasterformat.
Das Anzeigen des Quellcodes der HTML-Seite, die Sie scrapen möchten, gibt Ihnen eine allgemeine Vorstellung von der Struktur der Seite. Dies hilft Ihnen beim Schreiben eines Scrapers. Sie können den Quellcode anzeigen, indem Sie mit der rechten Maustaste auf die Seite klicken und „Quelltext anzeigen“ auswählen oder Strg + U drücken. Hier ist ein Ausschnitt des Quellcodes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink zu: "Sichern von Apache mit Let’s Encrypt auf Ubuntu 18.04"">Sichern von Apache mit Let’s Encrypt auf Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Website- und Datensicherheit sind Themen, die man nicht auf die leichte Schulter nehmen darf. Hochsensible Informationen, zu denen Finanzdaten und private Informationen von Kunden gehören, werden ständig zwischen dem Computer des Nutzers und Ihrer Website übertragen. Wenn man diese Tatsache bedenkt, ist es unschwer zu erkennen, warum ungesicherte Websites zu einer Sicherheitsverletzung führen können, die Ihrem Unternehmen ernsthaften Schaden zufügen könnte. Es gibt eine … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Weiterlesen</a></div> </div> </div> ... </article> </div> </body> |
Wie Sie sehen können, ist jedes Blog-Tutorial in ein HTML-Tag namens <article> eingeschlossen. Das Scraping der Seite umfasst zwei Schritte. Der erste Schritt besteht darin, jedes Blog-Tutorial zu erfassen, indem wir uns die Teile der Seite ansehen, die die gewünschten Daten enthalten. Der nächste Schritt besteht darin, die gewünschten Daten aus jedem durch das HTML-Tag identifizierten Tutorial zu extrahieren.
Scrapy identifiziert die zu erfassenden Daten basierend auf den von Ihnen bereitgestellten Selektoren. Wir können Selektoren verwenden, um ein oder mehrere Elemente auf einer Seite zu finden und die Daten innerhalb dieser Elemente abzurufen. Scrapy unterstützt XPath und CSS-Selektoren.
Aus dem Quellcode, den wir uns zuvor angesehen haben, scheinen CSS-Selektoren einfacher zu sein. Daher ist dies die Option, für die wir uns entscheiden werden, da sie uns hilft, alle Tutorials auf der Seite zu finden. Im HTML-Quellcode ist jedes Tutorial innerhalb der CSS-Klasse namens post definiert. CSS-Klassennamen werden normalerweise mit .class_name (Punkt class_name) identifiziert. Daher werden wir .post für unseren CSS-Selektor verwenden. In unserem main.py Scraper-Quellcode übergeben wir die .post-Klasse an das Response-Objekt, sodass Ihre Datei nun wie folgt aussieht:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
Dieses Code-Snippet erfasst alle Tutorials auf der Seite mit den angegebenen start_urls und durchläuft die Tutorials in einer Schleife, um Daten zu extrahieren. Im nächsten Schritt möchten Sie diese Daten extrahieren und anzeigen. Wenn Sie den Quellcode des CloudSigma-Blogs erneut untersuchen, werden Sie sehen, dass der Titel jedes Tutorials in einem <a>-Tag gespeichert ist, das sich in einem <h2>-Tag befindet, zum Beispiel:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink zu: "Sichern von Apache mit Let’s Encrypt auf Ubuntu 18.04"">Sichern von Apache mit Let’s Encrypt auf Ubuntu 18.04</a> </h2> |
Jedes Tutorial-Objekt, über das wir iterieren, enthält eine CSS-Methode, an die wir einen Selektor übergeben können, um untergeordnete Elemente zu finden und zu extrahieren. Für dieses Beispiel möchten wir den Titel extrahieren, der im <a>-Tag eingeschlossen ist. Dieses Tag befindet sich im <h2>-Tag innerhalb der Klasse .entry-header innerhalb der Klasse .entry-wrap. Wir können diese CSS-Selektoren an die Objektmethode übergeben, um den Titel zu extrahieren. Ändern Sie den Code so, dass er wie folgt aussieht:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
Das abschließende Komma nach extract_first() ist kein Tippfehler, da wir unter diesem Abschnitt weiteren Code hinzufügen werden.
Einige wichtige Punkte aus dem obigen Quellcode sind:
- ::text an den Selektor angehängt – dies ist ein CSS-Pseudoselektor , der den Code anweist, den Text innerhalb des Tags und nicht das Tag selbst abzurufen.
- Aufruf der Methode extract_first() innerhalb des Objekts – weist den Code an, nur das erste Element auszuwählen, das mit dem Selektor übereinstimmt. Daher erhalten wir eine Zeichenkette anstelle einer Liste von Elementen.
Speichern Sie als Nächstes die Datei und führen Sie den Code aus, indem Sie den folgenden Befehl in Ihrem Terminal eingeben:
|
1 |
scrapy runspider main.py |
In der Ausgabe sollten Sie die Titel der Tutorials sehen:
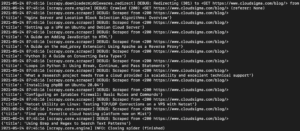
Wir können dies weiter ausbauen, indem wir weitere Selektoren hinzufügen, um andere Details über ein Tutorial zu erhalten, wie z. B. die URL des Tutorials, das Beitragsbild und die Bildunterschrift.
Lassen Sie uns den HTML-Code für ein einzelnes Tutorial noch einmal ansehen:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="Permalink zu: "Sichern von Apache mit Let’s Encrypt auf Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink zu: "Absicherung von Apache mit Let’s Encrypt auf Ubuntu 18.04"">Absicherung von Apache mit Let’s Encrypt auf Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>Website- und Datensicherheit sind Themen, die nicht auf die leichte Schulter genommen werden dürfen. Hochsensible Informationen, die Finanzdaten und private Informationen von Kunden umfassen, werden ständig zwischen dem Computer des Nutzers und Ihrer Website übertragen. Wenn man diese Tatsache bedenkt, ist es unschwer zu erkennen, warum ungesicherte Websites zu einer Sicherheitsverletzung führen können, die Ihrem Unternehmen ernsthaften Schaden zufügen könnte. Es gibt eine … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Mehr lesen</a></div> </div> </div> </article> </div> </body> |
Wir wollen versuchen, die hervorgehobenen Teile zu extrahieren, d. h. die URL des Tutorials, das Beitragsbild und die Bildunterschrift.
- Aus dem obigen Code-Snippet geht hervor, dass das Bild für das Blog im data-lazy-src-Attribut eines img-Tags innerhalb eines <a>-Tags innerhalb eines div-Tags am Anfang des Blog-Tutorials gespeichert ist. Wir können einen CSS-Selektor verwenden, um den Wert abzurufen, so wie wir es bei den Tutorial-Titeln getan haben.
- Das Abrufen der URL des Tutorials ist unkompliziert, da wir das <a>-Tag innerhalb des <div>-Elements haben.
- Die Bildunterschrift befindet sich innerhalb des <p>-Tags, das sich wiederum im <div>-Tag befindet.
Wir werden die CSS-Klassen verwenden, um das Gewünschte zu erhalten. Lassen Sie uns den Code so ändern, dass er wie folgt aussieht:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
Speichern Sie die Änderungen und führen Sie den Code mit dem folgenden Befehl aus:
|
1 |
scrapy runspider main.py |
Sie werden mehr Daten in der Ausgabe sehen, wie die URL, das Bild und die Bildunterschrift, die wir hinzugefügt haben:

Das ist alles für das Crawlen einer einzelnen Seite. Als Nächstes sehen wir uns an, wie wir einen Scraper erstellen können, der Links folgt.
Schritt 3: Wie man mehrere Seiten crawlt
Bis zu diesem Punkt haben wir einen Scraper erstellt, der Daten von einer einzelnen Seite abrufen kann. Wir wollen jedoch mehr als das. Sie möchten einen Spider, der programmgesteuert Links folgen und Daten von mehreren Seiten einer Website extrahieren kann.
Wenn Sie zum Ende der CloudSigma-Blogseite gehen, werden Sie die Links zur Seitennummerierung (Pagination) und einen kleinen Pfeil nach rechts bemerken, der auf die nächste Seite hinweist. Hier ist das HTML-Code-Snippet:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Seite 1 von 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Letzte Seite">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Das Snippet zeigt mehrere Links zur Seitennavigation innerhalb von <li>-Tags unter dem <div>-Tag mit der CSS-Klasse .x-pagination. Unser Fokus liegt auf dem Link, der auf die nächste Seite verweist. Er befindet sich im <a>-Tag des letzten <li> im <ul>-Tag.
Der Link, der auf die nächste Seite verweist, hat die Klasse .prev-next innerhalb des <a>-Tags, wie im obigen Snippet zu sehen ist. Wenn Sie jedoch zur nächsten Seite wechseln, werden Sie auch feststellen, dass die Links zur vorherigen und nächsten Seite diese CSS-Klasse haben. Betrachten Sie dieses Snippet für Seite 2:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Seite 2 von 45</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Letzte Seite">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Wenn wir die Scrapy-Methode extract_first() verwenden, funktioniert sie auf der ersten Seite. Wenn sie die nächste Seite erreicht, wählt sie den ersten Link mit der Klasse .prev-next aus, der im obigen Snippet auf die erste Seite verweist. Dies führt zu einer Endlosschleife. Daher verwenden wir die Scrapy-Methode extract(). Diese Methode extrahiert alle Elemente, die auf einen Anwendungsfall passen, und fügt sie in ein Array ein. Aus diesem Array können wir das letzte Element auswählen, das den tatsächlichen Link zur nächsten Seite enthält. Ändern Sie Ihren Code so ab, dass er wie folgt aussieht:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Gehen wir den Code für die next_page-Auswahl durch.
Wir definieren zuerst einen Selektor für die Links zur nächsten und vorherigen Seite. Anschließend verwenden wir die Methode extract(), um die URLs zu extrahieren und in einem Array zu speichern. Die Variable next_page ist ein Array mit zwei Elementen wie:
|
1 |
next_page = [prev_page_url, next_page_url] |
Da wir zur nächsten Seite navigieren, wählen wir das letzte Element im Array aus. Next_page[-1] wählt das letzte Element im Array aus.
Der if-Block prüft, ob die Variable next_page einen Wert enthält, und ruft dann die Methode scrapy.Request() auf. In unserem Code weisen wir diese Methode an, die Seite mit der bereitgestellten URL zu crawlen und sie an die Methode parse() zurückzugeben, damit wir sie parsen können, um die Daten zu extrahieren und den Vorgang für die nächste Seite zu wiederholen. Dieser Vorgang wird so lange wiederholt, bis kein Link zur nächsten Seite mehr gefunden wird, oder genauer gesagt, wenn der Block fehlschlägt, stoppt er.
Speichern Sie Ihren Code und führen Sie ihn aus. Sie werden feststellen, dass die Iteration die Seiten weiter durchläuft, während sie weitere zu scrapende Seiten findet. So würden Sie einen Scraper definieren, der Links auf einer Website folgt. Unser Beispiel ist recht einfach. Wir gehen nur auf eine Seite, finden den Link zur nächsten Seite und wiederholen den Vorgang. In anderen Anwendungsfällen möchten Sie vielleicht Tags oder Links folgen, die auf externe Quellen verweisen, und mehr. Hier ist der vollständige Quellcode für den einfachen Python 3 Web-Scraper:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Fazit
In diesem Tutorial haben wir einen einfachen Web-Scraper erstellt, der das CloudSigma-Blog-Verzeichnis durchsuchen und einige Informationen über die Blog-Tutorials in nur etwa 27 Codezeilen anzeigen kann.
Das ist natürlich möglich, weil wir es auf der Python-Bibliothek Scrapy aufgebaut haben. Dies ist nur eine Grundlage, die Ihnen helfen soll, komplexere Scraper zu erstellen, die mehr Tags, Suchergebnisse von Websites und mehr verfolgen. Sie können sich die offizielle Dokumentation von Scrapy ansehen, um weitere Informationen zur Arbeit mit Scrapy zu erhalten.
Viel Spaß beim Computing!
Kommentare
Noch keine Kommentare. Schreiben Sie den ersten.