

CloudSigma ermöglicht es Kunden, GPUs zu ihren virtuellen Maschinen hinzuzufügen und hochleistungsfähiges, kostengünstiges Computing zu nutzen, das den anspruchsvollsten Workloads gerecht wird. Das Herzstück des GPU-Angebots von CloudSigma ist die NVIDIA A100 Tensor Core GPU, die für HPC, KI und Datenanalyse optimiert ist. Die A100 übertrifft die NVIDIA TESLA V100 und verfügt über neue Funktionen, die sich KI-Anwendungen voll zunutze machen können. Wir ermöglichen es Kunden, auf einfache Weise optimierte NVIDIA A100 VMs im Passthrough-Modus zu erstellen, sodass VM-Instanzen die direkte Kontrolle über die GPU/s und deren integrierten Speicher haben.
Anwendungsfälle
Das Wachstum rechenintensiver Anwendungen in der Cloud hat die jüngste Explosion des GPU-beschleunigten Cloud-Computings vorangetrieben. Zu diesen Anwendungen gehören unter anderem Deep-Learning-Training und -Inferenz für KI, Datenanalyse, wissenschaftliches Rechnen, Genomik, Grafik-Rendering und Gaming. Von der Skalierung von KI-Training und wissenschaftlichem Rechnen über die horizontale Skalierung von Inferenzanwendungen bis hin zur Ermöglichung von Konversations-KI in Echtzeit bieten GPUs die erforderliche Leistung, um zahlreiche komplexe und unvorhersehbare Workloads in der Cloud zu beschleunigen.
Die NVIDIA A100 Tensor Core GPU stellt einen riesigen Sprung nach vorn dar und bietet eine beispiellose Beschleunigung für KI, Datenanalyse und HPC in jedem Maßstab. Angetrieben von der NVIDIA Ampere-Architektur bietet die A100 eine bis zu 20-mal höhere Leistung als die Vorgängergeneration. CloudSigma stellt die Version mit 80 GB Speicher zur Verfügung, die mit über 2 Terabyte pro Sekunde (TB/s) die weltweit schnellste Bandbreite bietet, um die größten Modelle und Datensätze auszuführen.
NVIDIA-GPUs gehören zu den führenden Rechen-Engines für KI, indem sie erhebliche Beschleunigungen für KI-Trainings- und Inferenz-Workloads bieten. Darüber hinaus beschleunigen NVIDIA-GPUs viele Arten von HPC- und Datenanalyseanwendungen und -systemen und verwandeln Daten in Erkenntnisse.
KI und HPC
Trainieren Sie komplexe Modelle für maschinelles Lernen schneller und effizienter mit GPU-Beschleunigung. Bewältigen Sie datenintensive Aufgaben und erzielen Sie Durchbrüche bei KI-gestützten Innovationen.NVIDIA AI Enterprise ist eine durchgängige, Cloud-native Suite von KI- und Datenanalysesoftware, die so optimiert ist, dass jedes Unternehmen KI nutzen kann. Sie ist für den Einsatz in der Public Cloud zertifiziert und umfasst globalen Enterprise-Support, um KI-Projekte auf Kurs zu halten. Die A100 ermöglicht es Forschern, schnell praxisnahe Ergebnisse zu liefern und Lösungen in großem Maßstab in der Produktion bereitzustellen.
DEEP-LEARNING-TRAINING
Das Trainieren von KI-Modellen erfordert enorme Rechenleistung und Skalierbarkeit. NVIDIA A100 Tensor Cores mit Tensor Float (TF32) bieten eine bis zu 20-mal höhere Leistung als die NVIDIA Volta bei null Codeänderungen und einen zusätzlichen 2-fachen Schub mit automatischer gemischter Präzision und FP16.
Ein Trainings-Workload wie BERT kann von 2.048 A100-GPUs in weniger als einer Minute im großen Maßstab gelöst werden – ein Weltrekord für die Zeit bis zur Lösung.
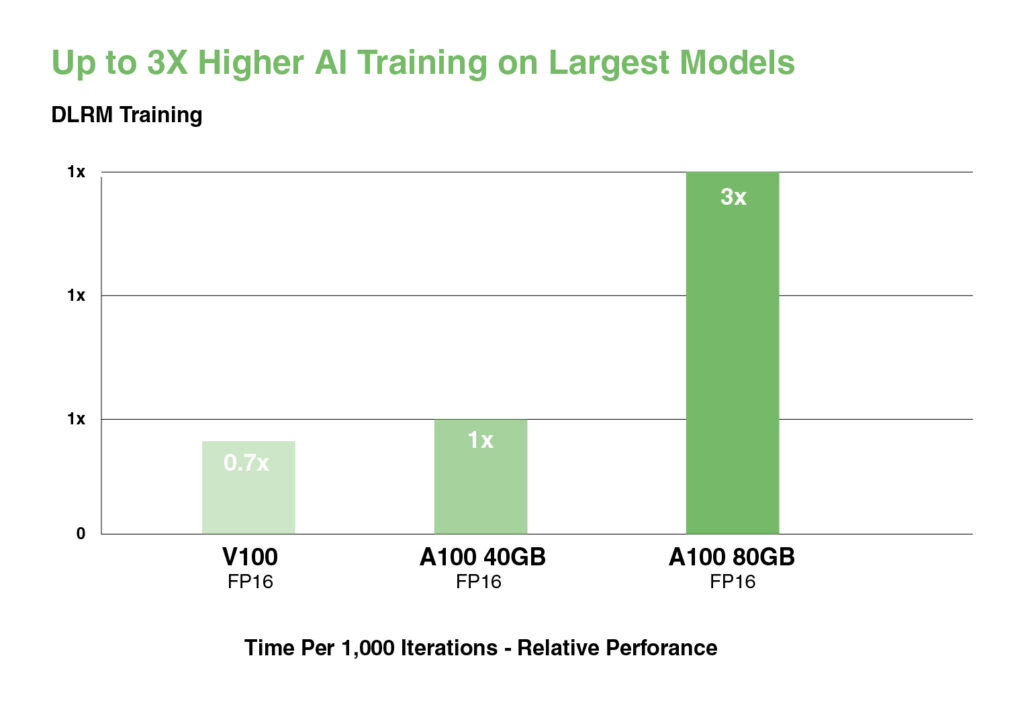
Für die größten Modelle mit massiven Datentabellen wie Deep-Learning-Empfehlungsmodelle (DLRM) erreicht die A100 80GB bis zu 1,3 TB vereinheitlichten Speicher pro Knoten und bietet einen bis zu 3-mal höheren Durchsatz im Vergleich zur A100 40GB.
NVIDIAs führende Rolle bei MLPerf, mit der mehrere Leistungsrekorde im branchenweiten Benchmark für KI-Training aufgestellt wurden.
DEEP-LEARNING-INFERENZ
Die A100 führt bahnbrechende Funktionen zur Optimierung von Inferenz-Workloads ein. Sie beschleunigt ein breites Spektrum an Präzision von FP32 bis INT4. Die Multi-Instance GPU (MIG)-Technologie ermöglicht es mehreren Netzwerken, gleichzeitig auf einer einzigen A100 zu arbeiten, um eine optimale Auslastung der Rechenressourcen zu gewährleisten. Und die Unterstützung struktureller Sparsamkeit liefert eine bis zu 2-mal höhere Leistung zusätzlich zu den anderen Inferenz-Leistungssteigerungen der A100.
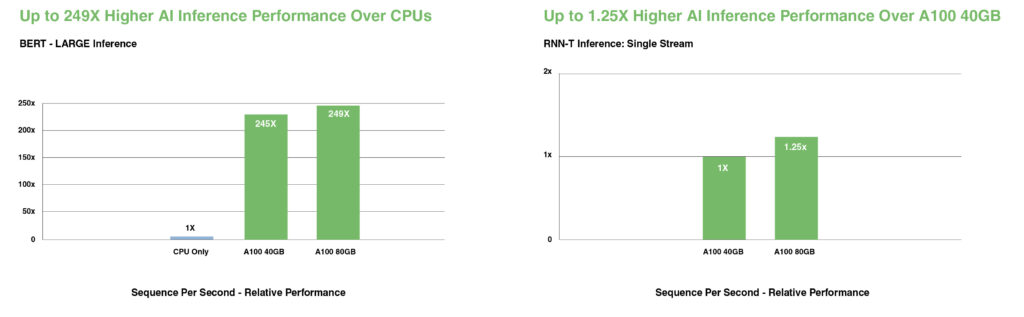
Bei modernsten Konversations-KI-Modellen wie BERT beschleunigt die A100 den Inferenzdurchsatz im Vergleich zu CPUs um das bis zu 249-Fache.
Bei den komplexesten Modellen, die durch die Batch-Größe begrenzt sind, wie RNN-T für die automatische Spracherkennung, verdoppelt die erhöhte Speicherkapazität der A100 80GB die Größe jeder MIG und liefert einen bis zu 1,25-mal höheren Durchsatz im Vergleich zur A100 40GB.
Die marktführende Leistung von NVIDIA wurde bei MLPerf Inference unter Beweis gestellt. Die A100 bringt eine 20-mal höhere Leistung, um diese Führungsposition weiter auszubauen.
HIGH-PERFORMANCE COMPUTING
Um Entdeckungen der nächsten Generation freizusetzen, setzen Wissenschaftler auf Simulationen, um die Welt um uns herum besser zu verstehen.
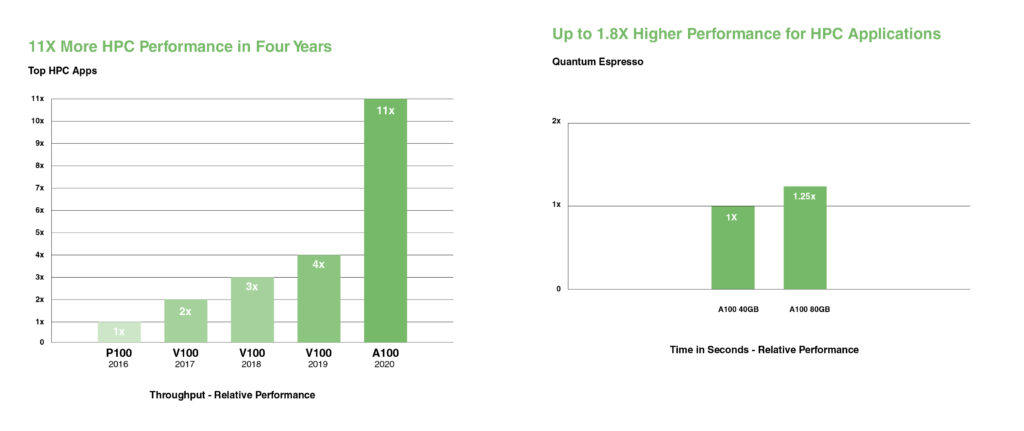
NVIDIA A100 führt Tensor Cores mit doppelter Genauigkeit ein, um den größten Sprung in der HPC-Leistung seit der Einführung von GPUs zu liefern. Mit 80GB des schnellsten GPU-Speichers können Forscher eine 10-stündige Simulation mit doppelter Genauigkeit auf der A100 auf unter vier Stunden verkürzen. HPC-Anwendungen können TF32 nutzen, um einen bis zu 11X höheren Durchsatz bei dichten Matrixmultiplikationsoperationen mit einfacher Genauigkeit zu erzielen.
Für HPC-Anwendungen mit den größten Datensätzen bietet der zusätzliche Speicher der A100 80GB eine bis zu 2X höhere Durchsatzsteigerung bei Quantum Espresso, einer Materialsimulation. Dieser enorme Speicher und die beispiellose Speicherbandbreite machen die A100 80GB zur idealen Plattform für Workloads der nächsten Generation.
HIGH-PERFORMANCE-DATENANALYSE
Data Scientists müssen in der Lage sein, riesige Datensätze zu analysieren, zu visualisieren und in Erkenntnisse umzuwandeln. Aber Scale-out-Lösungen werden oft durch Datensätze ausgebremst, die über mehrere Server verteilt sind.
Beschleunigte Server mit A100 bieten die erforderliche Rechenleistung – enormen Speicher, über 2 TB/sec Speicherbandbreite und Skalierbarkeit mit NVIDIA® NVLink® und NVSwitch™ –, um diese Workloads zu bewältigen. In Kombination mit InfiniBand, NVIDIA Magnum IO™ und der RAPIDS™-Suite von Open-Source-Bibliotheken, einschließlich des RAPIDS Accelerators für Apache Spark für GPU-beschleunigte Datenanalyse, beschleunigt die NVIDIA-Rechenzentrumsplattform diese riesigen Workloads mit einer beispiellosen Leistung und Effizienz.
In einem Big-Data-Analyse-Benchmark lieferte die A100 80GB Erkenntnisse mit einer 2X-Steigerung gegenüber der A100 40GB, wodurch sie sich ideal für neue Workloads mit explosionsartig wachsenden Datensatzgrößen eignet.
WISSENSCHAFTLICHE SIMULATIONEN: Beschleunigen Sie wissenschaftliche Forschung und Simulationen und ermöglichen Sie schnellere Erkenntnisse und Entdeckungen in Physik, Chemie und Umweltwissenschaften.
MEDIEN UND UNTERHALTUNG: Rendern Sie hochauflösende Grafiken, Videos und Animationen in Blitzschnelle. Bieten Sie Ihrem Publikum außergewöhnliche visuelle Erlebnisse, ohne Kompromisse bei der Qualität einzugehen.
FINANZMODELLIERUNG: Analysieren Sie riesige Datensätze und führen Sie komplexe Finanzmodellierungen mit unübertroffener Geschwindigkeit durch, um entscheidende Erkenntnisse für eine fundierte Entscheidungsfindung zu gewinnen.
Kommentare
Noch keine Kommentare. Schreiben Sie den ersten.