

Příkaz grep je výkonný nástroj pro vyhledávání vzorů v textu. Je předinstalován v jakékoli distribuci Linuxu. Zde je náš návod, který se zabývá nastavením LAMP Stacku – Linux, Apache, MySQL a PHP.
Název grep znamená „global regular expression print“ (globální tisk regulárních výrazů). Tento nástroj vyhledává v zadaném vstupu specifikovaný vzor. V principu to zní triviálně. Jeho skutečná síla však spočívá v tom, jak definujete vzor. Tento průvodce podrobně popisuje, jak používat grep s regulárními výrazy k provádění složitých vyhledávání. Začněme!
Jak používat grep
Samotný příkaz grep není složitý. Vše, co vyžaduje, je vzor a obsah, ve kterém se má vyhledávat. Základní struktura příkazu grep vypadá takto:
|
1 |
grep <regex> <file> |
Vyhledávání textu
Nejprve si pořiďte ukázkový soubor, na kterém akci provedete. Stáhněte si GNU General Public License v3.0 (v textovém formátu). Je to poměrně velký textový soubor s mnoha slovy a frázemi. Pokud používáte Ubuntu, najdete jej v souboru níže. Postupujte podle našeho návodu pro rychlou a snadnou instalaci Ubuntu.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

Dále můžete provést základní vyhledávání textu pomocí příkazu grep:
|
1 |
grep <pattern> <text_file> |
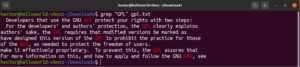
Výstup příkazu je možné přesměrovat (pipe) do příkazu grep:
|
1 |
cat gpl.txt | grep <pattern> |
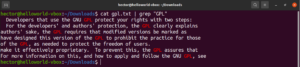
Rozlišování velikosti písmen
Ve výchozím nastavení grep rozlišuje velikost písmen. V mnoha situacích může být optimální velikost písmen ignorovat. Chcete-li zakázat rozlišování velikosti písmen, použijte přepínač „-i“ nebo „–ignore-case“:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
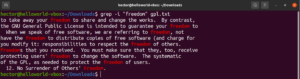
Inverzní vyhledávání
Ve výchozím nastavení grep vypisuje řádky, na kterých byl vzor nalezen. Inverzní shoda (invert match) označuje případ, kdy nechcete zobrazit řádky, které vzoru odpovídají. Chcete-li shodu invertovat, musíte použít přepínač „-v“ nebo „–invert-match“:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
Číslo řádku
Při spuštění příkazu grep na velmi velkém souboru je těžké sledovat umístění výsledku vyhledávání. Pro usnadnění práce má grep funkci zobrazení čísla řádku. Chcete-li povolit číslování řádků, použijte přepínač „-n“ nebo „–line-number“:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
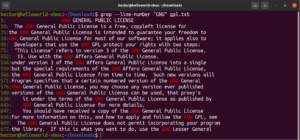
Je možné kombinovat více argumentů příkazu grep. Následující příkaz grep provede inverzní vyhledávání a zároveň vypíše čísla řádků:
|
1 |
grep -nv <pattern> <file> |
Regulární výraz
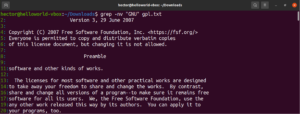
Na začátku této příručky jsme zmínili, že grep znamená „global regular expression print“. Pojem „regulární výraz“ je definován jako speciální řetězec, který popisuje vyhledávací vzor. Regulární výraz má svou vlastní strukturu a pravidla.
Existuje celá řada algoritmů a nástrojů pro vyhledávání řetězců, které k vyhledávání a nahrazování používají regulární výrazy (zkráceně regex). Přestože jsou populární, různé aplikace a programovací jazyky implementují regex mírně odlišně. V této části si ukážeme několik metod regexu pomocí příkazu grep.
Doslovná shoda
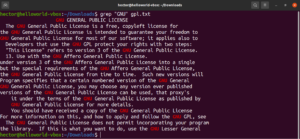
V předchozích příkladech prováděl grep vyhledávání konkrétního řetězce v daném textovém souboru. Grep ve skutečnosti vyhledával pomocí velmi základního regulárního výrazu. Vzory regexu, které definují vyhledávání přesné shody daného řetězce, se nazývají „literály“. Název pochází ze skutečnosti, že odpovídají vzoru doslovně, znak po znaku.
Doslovná shoda funguje s abecedními a číselnými znaky (stejně jako s některými speciálními znaky). V závislosti na jiných mechanismech výrazů se však toto chování může změnit:
|
1 |
grep "<string>" <file> |
Shoda s ukotvením
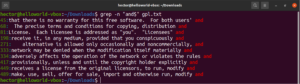
Kotvy jsou speciální znaky, které definují, kde v řádku by se měla nacházet pozice shody, aby byla shoda platná. Zde je rychlý příklad pro zjednodušení. Pokud chceme najít pouze řádky, které začínají řetězcem „GNU“, pak bude grep s regulárním výrazem vypadat takto. Zde je znak „^“ kotvou, která definuje, že jediné platné shody jsou ty na začátku řádku:
|
1 |
grep -n "^GNU" <file> |

Podobně, pokud chceme najít pouze řádky, které končí řetězcem „works“, bude grep s regulárním výrazem vypadat takto. Zde je znak „$“ kotvou, která definuje, že platné jsou pouze shody na konci řádku:
|
1 |
grep -n "and$" <file> |
Shoda s libovolným znakem
Při vyhledávání textu můžete chtít definovat, že na určitém místě může být libovolný znak. V regulárních výrazech je to vyjádřeno znakem tečky (.).
Podívejte se na tento příklad. V textovém souboru GNU GPL 3 mají slova „accept“ a „except“ společnou část „cept“. Obě slova mají navíc před částí „cept“ dva znaky. Následující příkaz grep najde shodu s jakýmkoli slovem, které má před částí „cept“ dva znaky:
|
1 |
grep -n "..cept" <file> |
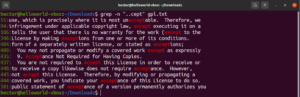
Podle tohoto regulárního výrazu jsou platnými shodami také další slova jako suscept, unaccept, unexpected atd.
Hranaté závorky
V regulárních výrazech definují výrazy v hranatých závorkách, že na zadaném místě může být jakýkoli znak deklarovaný uvnitř závorky. Podívejte se na následující řetězec regulárního výrazu:
|
1 |
t[wo]o |
Při použití v praxi budou platnými shodami slova too a two:
|
1 |
grep -n "t[wo]o" <file> |
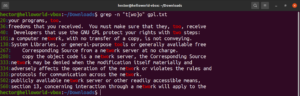
Výraz v hranatých závorkách otevírá možnosti pro zajímavé věci. Pomocí výrazů v hranatých závorkách lze říci, že na zadaném místě může být jakýkoli jiný znak než ty, které jsou deklarovány uvnitř závorky. Podívejte se na následující řetězec regulárního výrazu. Shoda bude platná pouze tehdy, pokud je před „ode“ jakýkoli jiný znak než „c“:
|
1 |
"[^c]ode" |
Spusťte jej na textovém souboru s licencí GPL-3:
|
1 |
grep -n "[^c]ode" <file> |

Kromě výsledku ze souboru by dalšími platnými výsledky byly node, abode, anode atd. Výrazy v hranatých závorkách mohou také popisovat rozsah znaků. Následující regulární výraz říká, že shoda je platná, pokud je na začátku řádku velké písmeno:
|
1 |
"^[A-Z]" |
Spusťte jej na textovém souboru s licencí GPL-3. Budou to všechny řádky v textovém souboru:
|
1 |
grep -n "^[A-Z]" <file> |
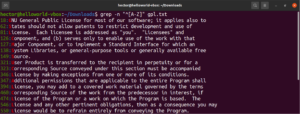
Pro snadnější použití existují určité třídy znaků, které mají specifická označení. V předchozím příkladu jsme k definování velkých písmen použili rozsah „A-Z“. Místo toho můžeme použít také „[:upper:]“. Výsledek bude stejný:
|
1 |
grep -n "^[[:upper:]]" <file> |
Opakování vzoru
V určitých situacích můžete chtít najít shodu pro konkrétní vzor nebo regulární výraz nulakrát nebo vícekrát. K tomu slouží metaznak hvězdička (*). Následující regulární výraz najde shodu se všemi závorkami, které obsahují pouze písmena a jednoduché mezery mezi nimi. Všimněte si, že deklarace sad malých a velkých písmen a mezer jsou společně bez jakékoli interpunkce:
|
1 |
"([a-zA-Z ]*)" |
Uveďte regulární výraz do praxe pomocí grep:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

Použití metaznaků jako doslovných znaků
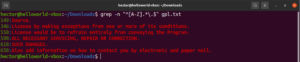
Dosud jsme se seznámili s různými metaznaky, jako je hvězdička (*), tečka (.), ukotvení (^ a $), atd. Každý z nich označuje jedinečnou funkci v kontextu regulárních výrazů. Problém nastává, když je potřeba je použít jako literály, nikoli jako metaznaky. V takových situacích zpětné lomítko (\) před metaznakem označuje, že se má použít v doslovném smyslu, nikoli jako metaznak. Podívejte se na tento příklad regulárního výrazu. Vyhledá všechny řádky, které začínají velkým písmenem a končí tečkou:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
Alternace
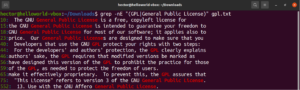
Pomocí závorkových výrazů můžeme specifikovat různé možné volby pro shodu jednoho znaku. Regulární výrazy mají funkci dělat totéž se slovy a frázemi. K označení alternace se používá znak svislé čáry (|). Možnosti zůstávají v závorkách, zatímco svislá čára je od sebe odděluje. Pro platnost shody mohou existovat dvě nebo více možných možností. Podívejte se na následující příklad regulárního výrazu. Bude odpovídat jak „GPL“, tak „General Public License“:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
Kvantifikátory
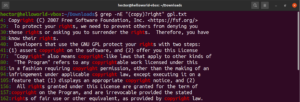
Pomocí metaznaku hvězdičky (*) jsme byli schopni definovat vzor opakovaně nulkrát nebo vícekrát. Je toho však k práci více. Kvantifikátory je snazší vysvětlit na příkladu. Následující regulární výraz popisuje, že jak „copyright“, tak „right“ jsou platné shody. Otazník (?) označuje část „copy“ jako volitelnou pro shodu:
|
1 |
grep -nE "(copy)?right" <file> |
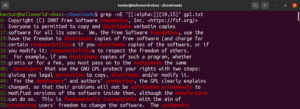
Dalším kvantifikátorem je symbol plus (+). Chová se podobně jako hvězdička. Definovaný vzor se však musí shodovat alespoň jednou. V následujícím příkladu bude regulární výraz odpovídat slovu „soft“ s jedním nebo více nebílými znaky:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
Určení opakování shody
Je možné určit, kolikrát se má shoda opakovat. K tomu použijte složené závorky ({}). Následující regulární výraz vyhledá jakékoli slovo, které obsahuje minimálně tři samohlásky:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

Tato funkce také umožňuje definovat dolní a horní hranici délky shody. V následujícím příkladu bude regulární výraz odpovídat jakémukoli slovu o délce 10–15 znaků:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
Závěr
Vyhledávání v textových souborech pomocí grep je docela praktické. Regulární výrazy dělají vyhledávání pomocí grep zajímavějším a užitečnějším. Také doladí vyhledávací vzor podle vašich představ.
Ačkoli jsme si ukázali některé z běžných regulárních výrazů, je to jen začátek. Existují pokročilejší regulární výrazy, které nabízejí tu nejjemnější kontrolu nad chováním při vyhledávání. Kromě nástroje grep jsou regulární výrazy široce používány také dalšími nástroji a programovacími jazyky.
Příjemnou práci s počítačem!
Komentáře
Zatím žádné komentáře. Buďte první.