
Soubor CSV je soubor s prostým textem, který ukládá data v tabulkovém formátu. Ve většině případů používají soubory CSV jako oddělovač čárky (,), odtud název CSV (Comma Separated Values). Používá se v situacích, kdy je důležitá kompatibilita dat, protože soubory CSV lze otevřít v jakémkoli textovém editoru, tabulkovém procesoru a dalších specializovaných nástrojích. Mnoho programovacích jazyků dokonce nabízí vestavěnou podporu pro CSV.
V této příručce se dozvíme o použití CSV v ukázkové aplikaci Node.js.
CSV v Node.js
Node.js je open-source a multiplatformní běhové prostředí pro JavaScript. Stalo se jedním z nejpopulárnějších backendů, které pohánějí řadu webových služeb po celém internetu. Dokonce i velké společnosti jako Netflix a Uber používají Node.js k pohonu svých služeb.
Node.js má také k dispozici řadu modulů, které lze nasadit pro přidání dalších funkcí do projektu. Pokud jde o CSV, existuje mnoho modulů, které lze použít, například node-csv, fast-csv, a papaparse atd.
Jak napovídá název příručky, budeme používat node-csv ke čtení souborů CSV pomocí streamů Node.js. Ukážeme si také práci s analyzovanými daty, například přenos dat do databáze SQLite.
Požadavky
-
K provedení kroků popsaných v této příručce budete potřebovat následující komponenty:
-
Správně nakonfigurovaný systém Linux. Zjistěte více o instalaci a konfiguraci cloudového serveru Ubuntu na CloudSigma.
-
Přístup k uživateli bez oprávnění root s sudo oprávněním. Podívejte se na správu oprávnění sudo pomocí sudoers.
-
Vhodný textový editor, například Brackets, VS Code, Sublime Text, Vim/NeoVim atd.
-
Další software:
-
Node.js LTS
-
SQLite
-
Step 1 – Installing Necessary Software
Pro účely této příručky jsem vytvořil lehký server se systémem Ubuntu 22.04 LTS (připojený přes SSH):
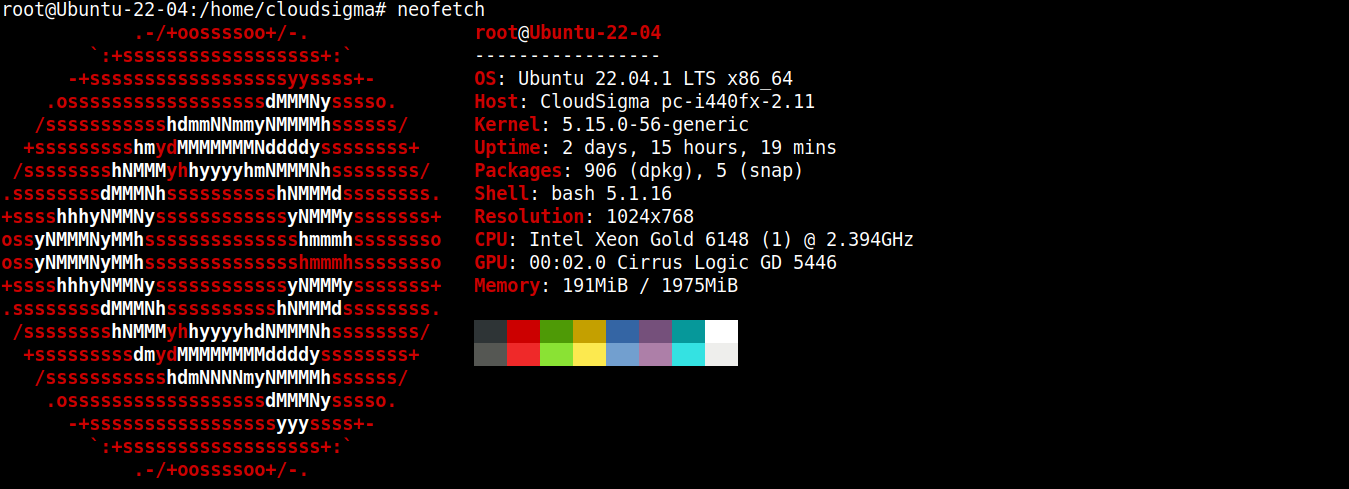
Nyní na něj nainstalujeme Node.js a SQLite.
-
Instalace Node.js LTS
Node.js je přímo k dispozici v oficiálních repozitářích balíčků Ubuntu. Nejedná se však o nejaktuálnější verzi. Proto se spolehneme na repozitář třetí strany (Nodesource) k získání nejnovějších balíčků Node.js.
Přidejte repozitář pro Node.js LTS:
|
1 |
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - |
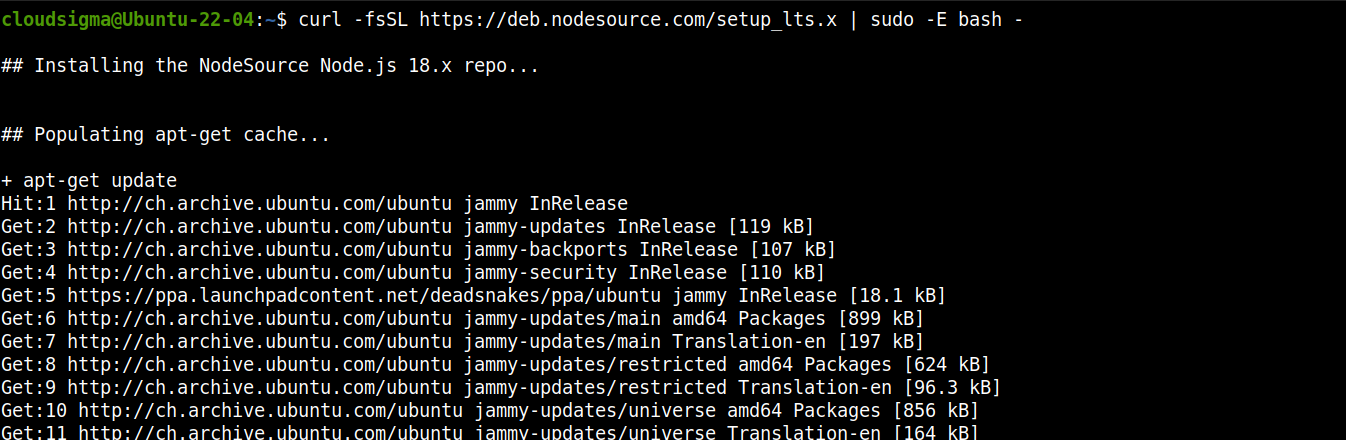
Nyní nainstalujte Node.js LTS:
|
1 |
sudo apt install nodejs -y |

-
Instalace SQLite
SQLite budeme instalovat přímo z repozitářů balíčků Ubuntu. Spusťte následující příkazy:
|
1 |
sudo apt install sqlite3 -y |

Step 2 – Project Directory Setup
V této části připravíme vyhrazený adresář pro náš projekt. Bude obsahovat všechny soubory projektu spolu s dalšími moduly.
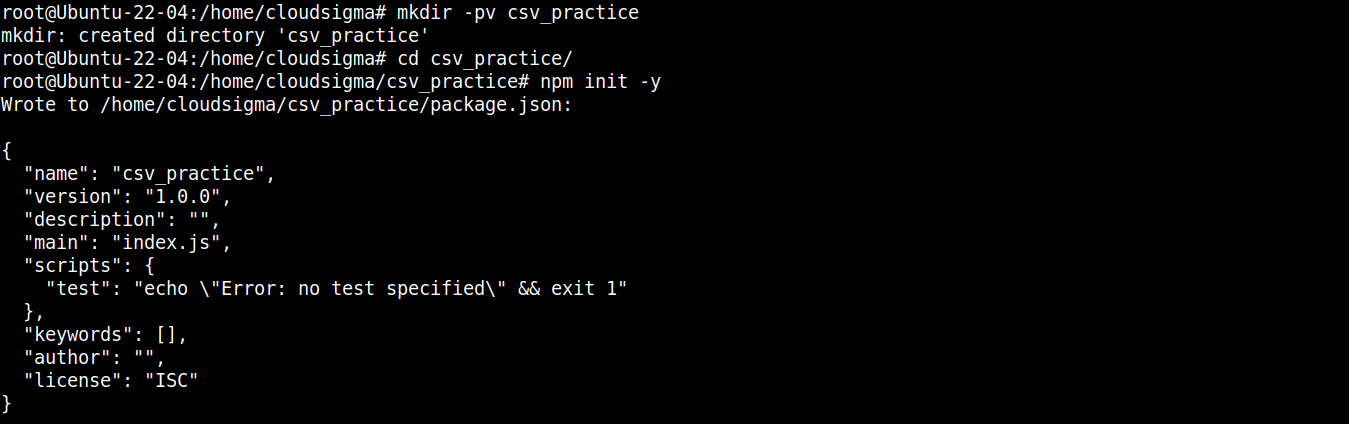
Vytvořte nový adresář:
|
1 |
mkdir -pv csv_practice |
Přejdete do adresáře:
|
1 |
cd csv_practice/ |
Dále spusťte následující příkaz, kterým deklarujete adresář jako npm projekt:
|
1 |
npm init -y |
Jakmile je složka projektu inicializována, můžeme začít instalovat potřebné balíčky a moduly. Nejprve nainstalujeme node-csv:
|
1 |
npm install csv |

Modul node-csv je ve skutečnosti sbírkou několika dalších modulů: csv-generate, csv-parse (analýza souborů CSV), csv-stringify (zápis dat do CSV) a stream-transform.
Dále potřebujeme modul pro komunikaci s SQLite. Následující příkaz nainstaluje modul node-sqlite3:
|
1 |
npm install sqlite3 |

Komponenta, kterou pro náš projekt potřebujeme, je soubor CSV. Pro demonstrační účely použijeme soubor CSV o migraci na Novém Zélandu:
|
1 |
wget https://www.stats.govt.nz/assets/Uploads/International-migration/International-migration-September-2021-Infoshare-tables/Download-data/international-migration-September-2021-estimated-migration-by-age-and-sex-csv.csv -O migration_data.csv |
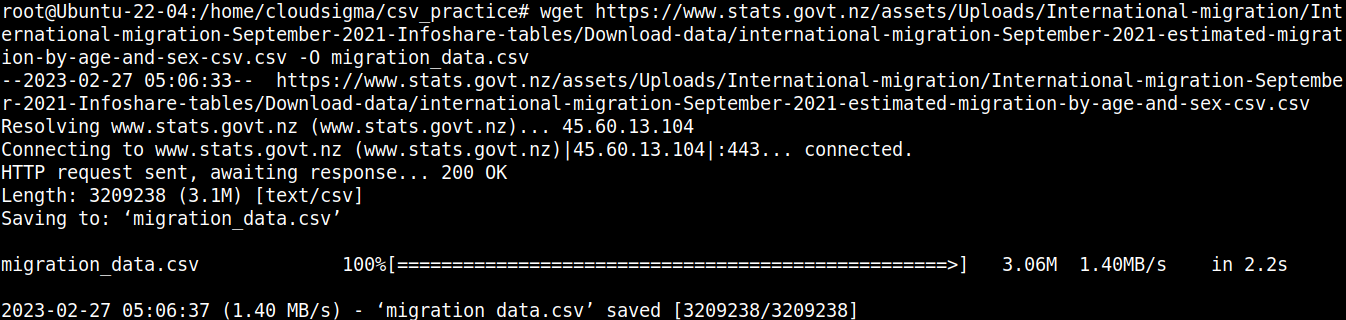
Pojďme se rychle podívat na obsah souboru:
|
1 |
cat migration_data.csv | less |
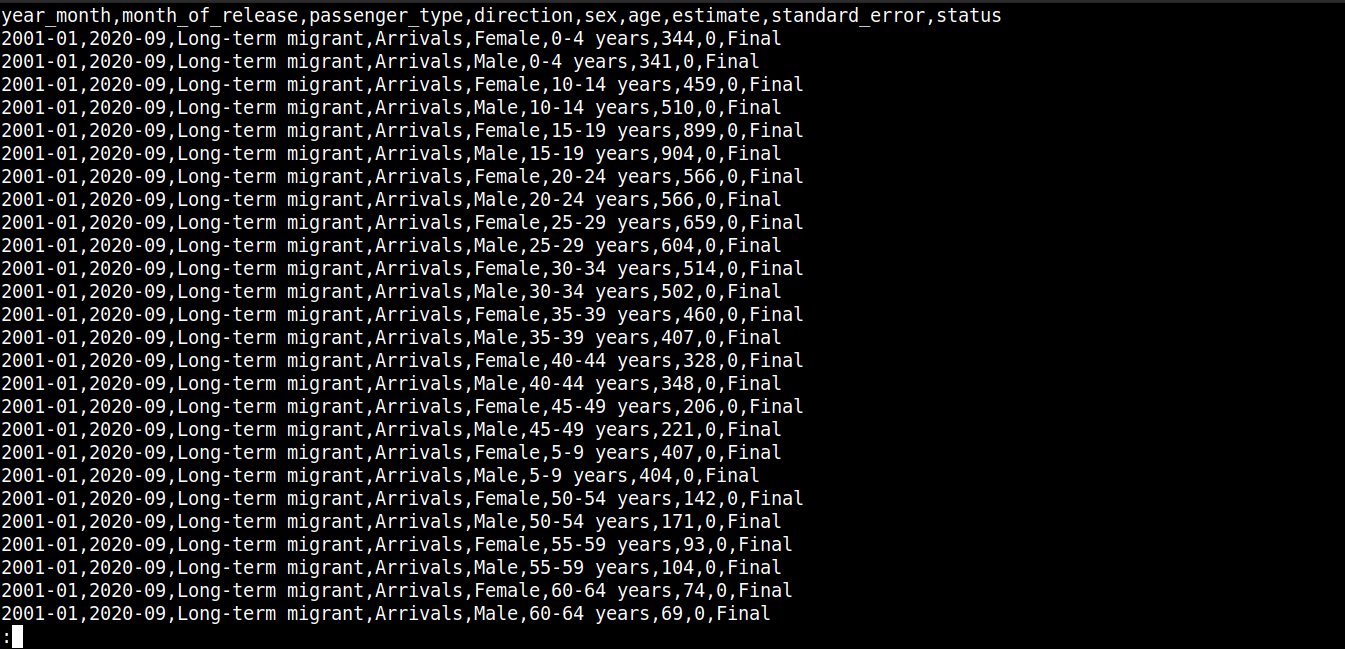
Zde,
-
První řádek popisuje názvy sloupců.
-
Následující řádky obsahují hodnoty pro tato pole.
-
Každý řádek je oddělen novým řádkem (\n).
-
Každý datový bod je oddělen čárkou (,).
Nicméně CSV se neomezuje pouze na použití čárek jako oddělovače. Mezi další běžné oddělovače patří dvojtečky (:), středníky (;) a tabulátory (\td).
Krok 3 – Čtení CSV
V této části si ukážeme implementaci ukázkového programu, který čte a parsuje data ze souboru CSV.
Vytvořte nový JavaScriptový soubor:
|
1 |
touch read_csv.js |
Otevřete soubor ve svém oblíbeném textovém editoru:
|
1 |
nano read_csv.js |
Nejprve naimportujeme fs a csv-parse moduly:
|
1 2 |
const fs = require("fs"); const { parse } = require("csv-parse"); |
Zde,
-
Nejprve je proměnné fs přiřazen objekt fs, který vrací metoda Node.js require() při importu modulu.
-
Dále je metoda parse extrahována z objektu vráceného metodou require() do proměnné parse pomocí destrukturalizační syntaxe.
Dále přidáme kód pro čtení CSV souboru:
|
1 2 3 4 5 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) |
Zde,
-
Voláme metodu createReadStream() z modulu fs a jako argument jí předáváme CSV soubor, který chceme číst. Ta pak vytvoří čitelný stream rozdělením většího souboru na menší části.
-
Po vytvoření streamu metoda pipe() předává části dat streamu do jiného streamu. Tento nový stream se vytvoří při volání metody parse() z csv- modulu.
-
Modul csv-module využívá transformační stream pro čtení i zápis, který přijímá část dat a transformuje ji do jiné podoby.
-
Metoda parse() přijímá objekty s vlastnostmi. Objekt dále zpracovává parsovaná data. V tomto případě objekt přijímá následující vlastnosti:
-
delimiter: Znak oddělovače pro oddělení hodnot. V případě našeho cílového CSV je to čárka (,).
-
from_line: Číslo řádku, od kterého parser začne parsovat. S nastavenou hodnotou 2 parser přeskočí 1. řádek a začne na 2. řádku. Tímto uspořádáním zabráníme tomu, aby se názvy sloupců začlenily do parsovaných dat.
-
Dále připojíme událost streamu pomocí metody on() z Node.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Zde,
-
Při vyvolání určité události umožňuje událost streamu metodě zpracovat část dat.
-
Jakmile jsou data parsovaná metodou parse() připravena ke zpracování, spustí se událost data event.
-
Pro přístup k datům předáváme metodě on() zpětné volání, které přijímá parametr row.
-
Parametr row je část dat ve formě pole (výsledek parsování).
-
Nakonec jsou data vypsána do konzole pomocí console.log().
Pro dokončení programu přidáme další události streamu pro zpracování chyb a vypsání zprávy o úspěchu, jakmile budou zpracována všechna data v souboru CSV. Aktualizujte kód následovně:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Zde,
-
Událost end se vyvolá, jakmile jsou zpracována všechna data v souboru CSV. Výsledkem je volání metody console.log() , která vypíše zprávu o úspěchu.
-
Událost error se vyvolá, pokud při parsování dat CSV dojde k chybě. Výsledkem je volání metody console.log() , která vypíše chybovou zprávu.
Finální kód by měl vypadat takto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const fs = require("fs"); const { parse } = require("csv-parse"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Uložte soubor a zavřete editor. Nyní jsme připraveni program spustit. Spusťte jej pomocí Node.js:
|
1 |
node read_csv.js |
Výstup by měl vypadat přibližně takto:

Všimněte si, že data jsou zpracovávána, transformována a vypisována do konzole. Jelikož se jedná o nepřetržitý proces, bude to vypadat, jako by se data stahovala, namísto toho, aby se celý výstup vypsal najednou.
Step 4 – Přenos dat z CSV do databáze
Zatím jsme se naučili, jak parsovat CSV soubor pomocí node-csv. Tato část ukáže přenos naparsovaných dat do databáze (SQLite).
Vytvořte nový JavaScriptový soubor pro interakci s databází:
|
1 |
touch csv-to-sqlite3.js |
Nyní otevřete soubor v textovém editoru:
|
1 |
nano csv-to-sqlite3.js |
![]()
Náš program začneme následujícím kódem:
|
1 2 3 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; |

Zde,
-
Na prvním řádku importujeme fs modul.
-
Na třetím řádku obsahuje proměnná filepath cestu k databázi SQLite.
-
V tomto okamžiku databáze ještě neexistuje. Bude však nezbytná při práci s node-sqlite3.
Dále přidejte následující řádky pro navázání připojení k databázi SQLite:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } console.log("Úspěšně připojeno k databázi"); }); return db; } } |
Zde,
-
Metoda connectoToDatabase() navazuje spojení s databází.
-
V rámci connectToDatabase(), voláme metodu existsSync() z modulu fs uvnitř podmínky if. Podmínka if kontroluje existenci databáze v určeném umístění.
-
Pokud je vyhodnocení podmínky true, pak se Database() třída z modulu node-sqlite3 použije. Jakmile je připojení navázáno, funkce vrátí objekt a ukončí se.
-
Pokud je vyhodnocení podmínky false (databáze neexistuje), pak provádění přejde do bloku else. Tam se Database() třída inicializuje se dvěma argumenty: cestou k souboru databáze a callbackem.
-
V zásadě platí, že pokud databáze neexistuje, bude vytvořena. Pokud však během procesu vytváření dojde k jakékoli chybě, nastaví se objekt error a vypíše se chybová zpráva.
Dále si představíme kód pro vytvoření tabulky, pokud databáze neexistuje:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } createTable(db); console.log("Úspěšně připojeno k databázi"); }); return db; } } function createTable(db) { db.exec(` CREATE TABLE migration ( year_month VARCHAR(10), month_of_release VARCHAR(10), passenger_type VARCHAR(50), direction VARCHAR(20), sex VARCHAR(10), age VARCHAR(50), estimate INT ) `); } module.exports = connectToDatabase(); |
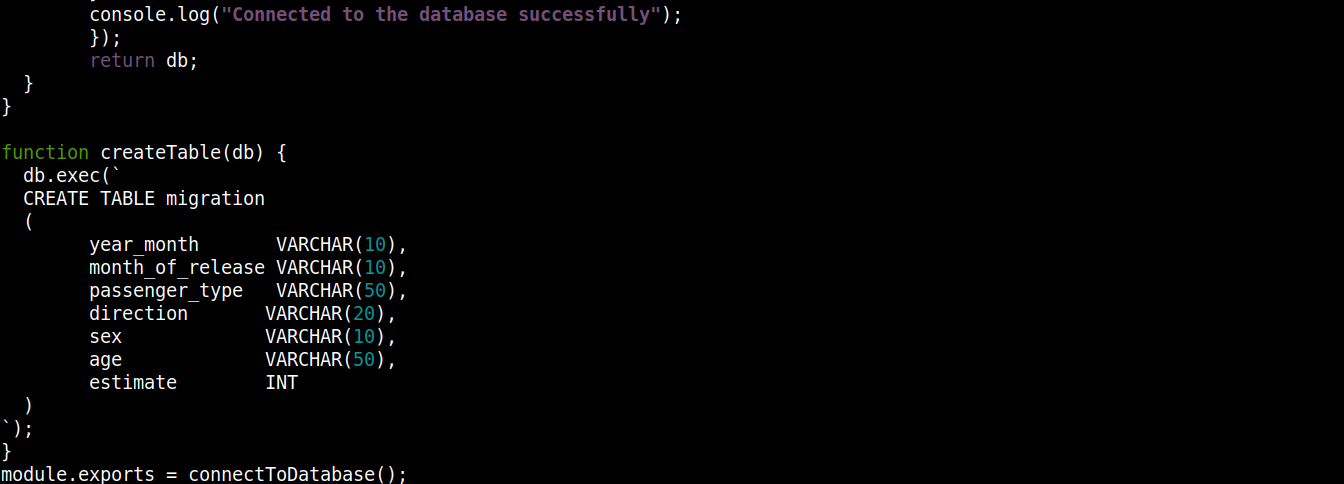
Zde,
-
Funkce connectToDatabase() volá funkci createTable() , která jako argument přijímá objekt uložený v db jako argument.
-
Mimo connectToDatabase(), jsme definovali metodu createTable() , která jako parametr přijímá objekt připojení db jako parametr.
-
Metoda exec() na objektu db přijímá jako argument SQL příkaz. V rámci tohoto SQL příkazu jsme definovali vytvoření tabulky migration se 7 sloupci, přičemž každý sloupec odpovídá záhlaví sloupců v migration_data.csv souboru.
-
Nakonec voláme connectToDatabase() metodu a exportování objektu připojení, který vrací, abychom jej mohli použít v jiných souborech.
Uložte soubor a zavřete editor.
Dále vytvoříme další program pro vložení analyzovaných dat do databáze:
|
1 |
nano insert_data.js |
Zadejte následující kód do insert_data.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const fs = require("fs"); const { parse } = require("csv-parse"); const db = require("./csv-to-sqlite3"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { db.serialize(function () { db.run( `INSERT INTO migration VALUES (?, ?, ? , ?, ?, ?, ?)`, [row[0], row[1], row[2], row[3], row[4], row[5], row[6]], function (error) { if (error) { return console.log(error.message); } console.log(`Řádek vložen, ID: ${this.lastID}`); } ); }); }); |
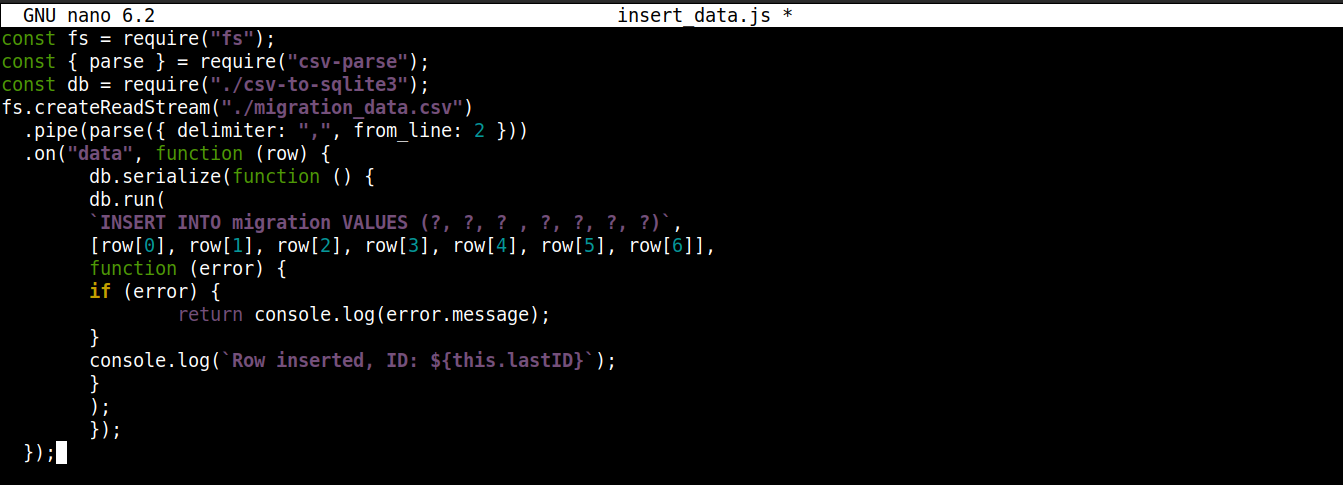
Zde,
-
Ukládáme objekt připojení získaný z csv-to-sqlite3.js do proměnné db.
-
Uvnitř zpětného volání události data (připojeného ke streamu modulu fs) voláme serialize() metodu na objektu připojení. Zajišťuje, že se jeden SQL příkaz dokončí před spuštěním dalšího, což zabraňuje souběhům v databázi (stav, kdy systém provádí konkurenční operace současně).
-
Metoda serialize() přijímá tři argumenty:
-
Prvním argumentem je SQL příkaz.
-
Druhým argumentem je pole.
-
Třetím argumentem je zpětné volání (callback), které se spustí při úspěšném nebo neúspěšném vložení dat do databáze.
-
Jsme připraveni program spustit. Spusťte insert_data.js pomocí Node.js:
|
1 |
node insert_data.js |
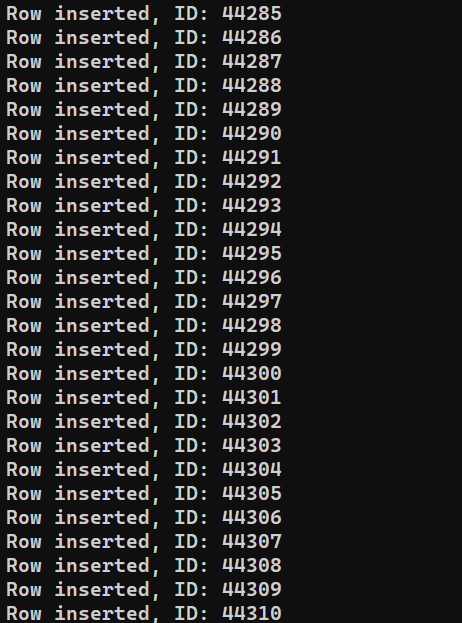
V závislosti na výkonu systému může dokončení procesu nějakou dobu trvat. Po dokončení by však výstup měl vypadat přibližně takto:
Krok 5 – Zápis dat do CSV
Po předchozí části máme databázi obsahující všechny záznamy, které jsme analyzovali z migration_data.csv. V této části budeme číst data z databáze a zapisovat je do samostatného souboru CSV.
Vytvořte nový JavaScriptový soubor pro uložení programu:
|
1 |
nano write_csv.js |
Nejprve přidejte následující řádky pro import fs a csv-stringify společně s objektem připojení k databázi z csv-to-sqlite3.js:
|
1 2 3 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); |
Dále přidáme proměnnou, která obsahuje název CSV souboru, do kterého se má zapisovat, společně se zapisovatelným proudem:
|
1 2 3 4 5 6 7 8 9 10 11 |
const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; |
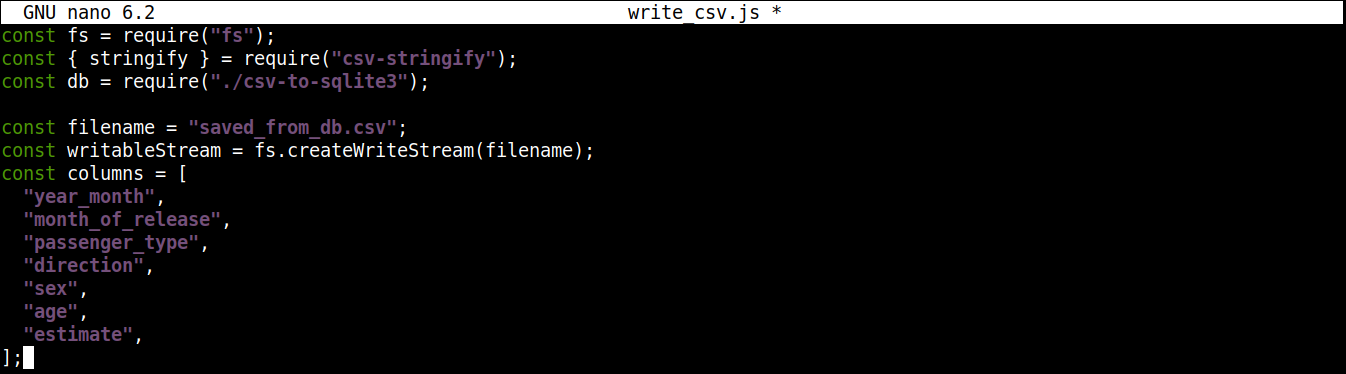
Zde,
-
Metoda createWriteStream() přijímá jako argument název souboru, do kterého se má zapisovat. Soubor pojmenujeme saved_from_db.csv.
-
Proměnná column ukládá pole, které obsahuje všechny názvy hlaviček pro data CSV.
Dále přidejte následující řádky kódu pro čtení dat z databáze a jejich zápis do saved_from_db.csv:
|
1 2 3 4 5 6 7 8 9 10 11 |
const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
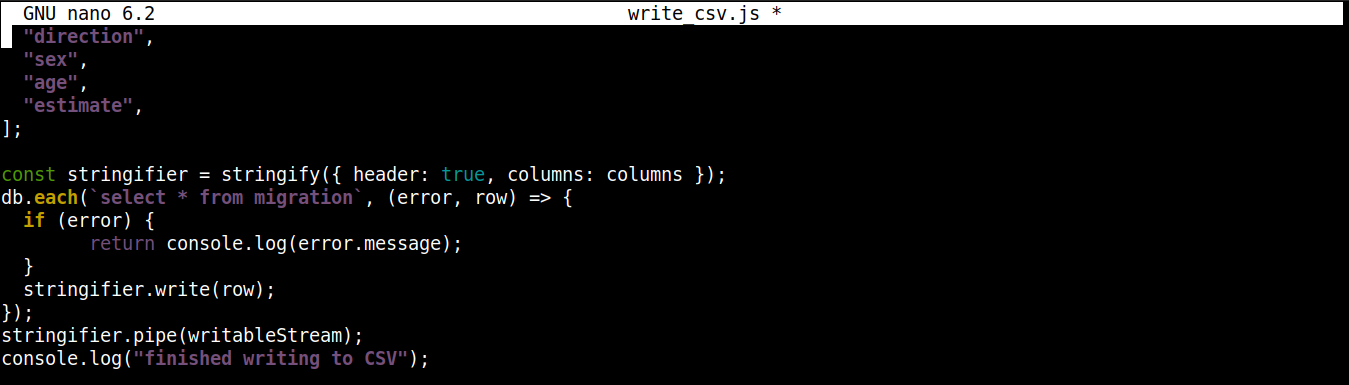
Zde,
-
Voláme metodu stringify() s objektem jako argumentem. Výsledkem je transformační proud (transform stream), který převádí data z objektu do formátu CSV. Objekt předaný metodě stringify() má dvě vlastnosti:
-
header: Přijímá booleovskou hodnotu. Pokud je hodnota true, vygeneruje se hlavička.
-
columns: Přijímá pole obsahující názvy sloupců, které se mají zapsat na první řádek CSV souboru, pokud je header is true.
-
-
Metoda each() z csv-to-sqlite3 objektu připojení je volána se dvěma argumenty: SQL příkazem (čtení dat z databáze) a zpětným voláním (pro zpracování úspěchu/chyby).
-
Při každé iteraci metody each(), pipe() (z proudu stringifier) začne posílat data po částech do zapisovatelného proudu writableStream. Každá část dat je pak zapsána do saved_from_db.csv.
-
Jakmile jsou všechna data zapsána do CSV souboru, na obrazovku konzole se vypíše zpráva o úspěchu.
Finální kód by měl vypadat takto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
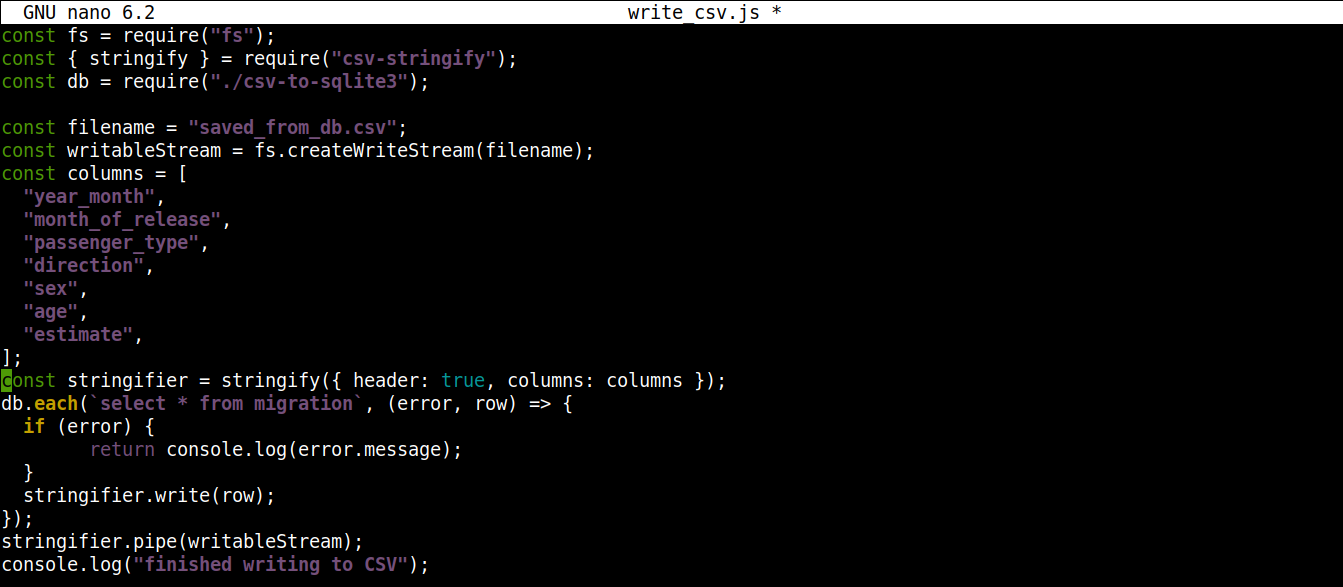
Uložte soubor a zavřete editor. Nyní můžeme program spustit pomocí Node.js:
|
1 |
node write_csv.js |
Chcete-li ověřit, zda byla data úspěšně exportována, zkontrolujte obsah saved_from_db.csv:
|
1 |
cat saved_from_db.csv | less |
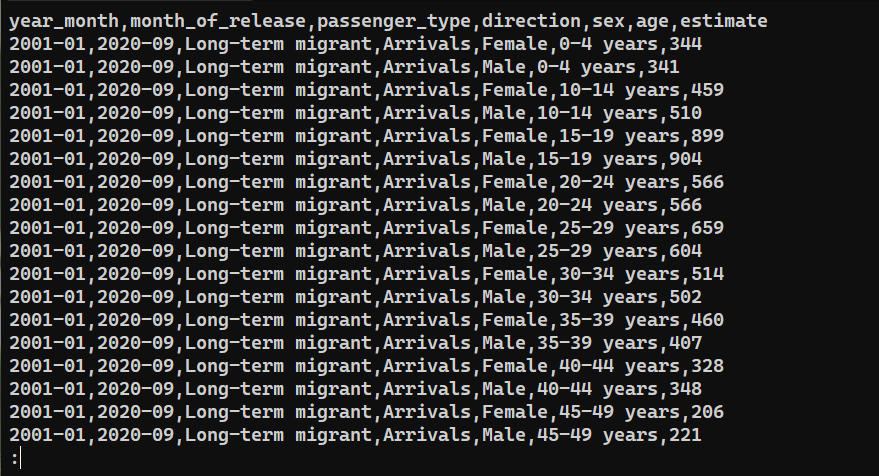
Závěr
V této příručce jsme si ukázali práci se soubory CSV v Node.js pomocí modulů node-csv a node-sqlite3. Vytvořili jsme několik programů pro splnění různých úkolů, například parsování dat z CSV, vkládání dat do databáze SQLite a zápis dat do nového souboru CSV.
Tato příručka ukazuje pouze malou část možností node-csv modulu. Více o všech jeho funkcích se dozvíte na CSV Project. Chcete-li se dozvědět více o node-sqlite3, podívejte se na oficiální dokumentaci na GitHubu. Dalším modulem, který stojí za zmínku, je event-stream pro zjednodušení práce se streamy.
Máte zájem o další rozvoj svého projektu v Node.js? Zde je několik návodů pro Node.js, které byste si měli prohlédnout:
-
Jak nasadit aplikaci Node.js (Express.js) pomocí Dockeru na Ubuntu 20.04
-
Nastavení aplikací v Node.js: Jak provádět produkční úlohy na Ubuntu 20.04 s Node.js
Příjemné programování!
Komentáře
Zatím žádné komentáře. Buďte první.