

إنّ grep هو أداة قوية للبحث عن الأنماط في النصوص. وهو يأتي مثبتًا مسبقًا في أي توزيعة Linux. إليك البرنامج التعليمي الخاص بنا الذي يشرح إعداد حزمة LAMP Stack - Linux و Apache و MySQL و PHP.
يرمز الاسم grep إلى طباعة التعبيرات النمطية العامة (global regular expression print). تبحث الأداة عن النمط المحدد في المدخلات. من حيث المبدأ، يبدو الأمر بسيطًا. ومع ذلك، تكمن قوتها الحقيقية في كيفية تحديدك للنمط. يوضح هذا الدليل بالتفصيل كيفية استخدام grep مع التعبيرات النمطية لإجراء عمليات بحث معقدة. فلنبدأ!
كيفية استخدام Grep
أمر grep بحد ذاته ليس معقدًا. كل ما يتطلبه هو النمط والمحتوى المراد إجراء البحث فيه. هذا هو الشكل الذي تبدو عليه البنية الأساسية لأمر grep:
|
1 |
grep <regex> <file> |
البحث في النصوص
أولاً، احصل على ملف عينة لتنفيذ الإجراء عليه. قم بتنزيل GNU General Public License v3.0 (بتنسيق نصي). إنه ملف نصي كبير نوعًا ما ويحتوي على الكثير من الكلمات والعبارات. إذا كنت تستخدم Ubuntu فيمكنك العثور عليه في الملف أدناه. اتبع البرنامج التعليمي الخاص بنا لتثبيت Ubuntu سريع وسهل.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

بعد ذلك، يمكنك إجراء بحث نصي أساسي باستخدام grep:
|
1 |
grep <pattern> <text_file> |
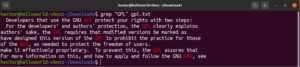
من الممكن تمرير (pipe) مخرجات أمر ما إلى grep:
|
1 |
cat gpl.txt | grep <pattern> |
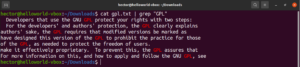
حساسية حالة الأحرف
بشكل افتراضي، يتعامل grep مع حالة الأحرف بحساسية. في العديد من الحالات، قد يكون تجاهل حساسية حالة الأحرف هو الخيار الأمثل. لتعطيل البحث الحساس لحالة الأحرف، استخدم العلامة “-i” أو “–ignore-case”:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
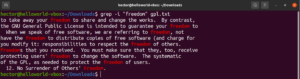
عكس البحث
بشكل افتراضي، يقوم grep بطباعة السطور التي تم العثور فيها على النمط. يشير عكس المطابقة (Invert match) إلى الحالة التي لا تريد فيها رؤية السطور التي تطابق النمط. لعكس المطابقة، تحتاج إلى استخدام العلامة “-v” أو “–invert-match”:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
رقم السطر
عند تشغيل grep على ملف كبير جدًا، يصعب تتبع موقع نتيجة البحث. لتسهيل الأمور، يتميز grep بميزة إظهار رقم السطر. لتمكين ترقيم السطور، استخدم العلامة “-n” أو “–line-number”:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
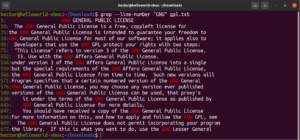
من الممكن دمج وسائط grep متعددة. سيقوم أمر grep التالي بإجراء مطابقة عكسية مع طباعة أرقام السطور:
|
1 |
grep -nv <pattern> <file> |
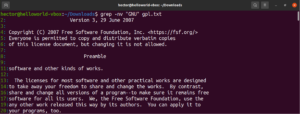
التعبيرات النمطية
في بداية هذا الدليل، ذكرنا أن grep يرمز إلى طباعة التعبيرات النمطية العامة (global regular expression print). يُعرَّف مصطلح “التعبيرات النمطية” بأنه سلسلة نصية خاصة تصف نمط البحث. للتعبيرات النمطية بنيتها وقواعدها الخاصة.
هناك العديد من خوارزميات وأدوات البحث عن النصوص التي تستخدم التعبيرات النمطية (regex باختصار) لإجراء عمليات البحث والاستبدال. على الرغم من شعبيتها، فإن التطبيقات ولغات البرمجة المختلفة تطبق regex بشكل مختلف قليلاً. في هذا القسم، سنعرض مجموعة من طرق regex باستخدام grep.
المطابقة الحرفية
في أمثلة grep السابقة، قام grep بالبحث عن سلسلة نصية محددة في ملف النص المعطى. كان grep يبحث في الواقع باستخدام التعبيرات النمطية الأساسية للغاية. تُسمى أنماط regex التي تحدد البحث عن المطابقة التامة لسلسلة نصية معينة بـ “الحرفية” (literals). ويأتي هذا الاسم من حقيقة أنها تطابق النمط حرفيًا، حرفًا بحرف.
تعمل المطابقة الحرفية مع الأحرف الأبجدية والرقمية (بالإضافة إلى بعض الأحرف الخاصة). ومع ذلك، قد يتغير هذا السلوك اعتمادًا على آليات التعبير الأخرى:
|
1 |
grep "<string>" <file> |
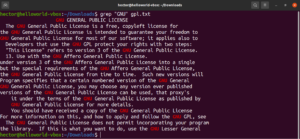
مطابقة المرساة
المراسي (Anchors) هي أحرف خاصة تحدد الموضع الذي يجب أن تكون فيه المطابقة في السطر لتكون مطابقة صالحة. إليك مثال سريع لتبسيط الأمر. إذا كنا نبحث فقط عن الأسطر التي تبدأ بسلسلة النصوص "GNU"، فإن أمر grep مع التعبير النمطي (regex) سيبدو كالتالي. هنا، الرمز "^" هو المرساة، وهو يحدد أن المطابقات في بداية السطر هي الوحيدة الصالحة:
|
1 |
grep -n "^GNU" <file> |

وبالمثل، إذا كنا نبحث فقط عن الأسطر التي تنتهي بسلسلة النصوص "works"، فإن أمر grep مع التعبير النمطي سيبدو كالتالي. هنا، الرمز "$" هو المرساة، وهو يحدد أن المطابقات في نهاية السطر فقط هي الصالحة:
|
1 |
grep -n "and$" <file> |
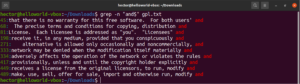
مطابقة أي حرف
عند إجراء بحث في النص، قد ترغب في تحديد أنه يمكن وجود أي حرف في مكان معين. في التعبيرات النمطية (regex)، يتم التعبير عن ذلك برمز النقطة (.).
ألقِ نظرة على هذا المثال. في ملف نص رخصة GNU GPL 3، تشترك الكلمتان "accept" و "except" في الجزء "cept". علاوة على ذلك، تحتوي كلتا الكلمتين على حرفين قبل الجزء "cept". سيطابق أمر grep التالي أي كلمة تحتوي على حرفين قبل الجزء "cept":
|
1 |
grep -n "..cept" <file> |
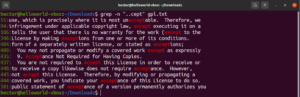
وفقًا لهذا التعبير النمطي، فإن الكلمات الأخرى مثل suscept و unaccept و unexpected وغيرها هي أيضًا مطابقات صالحة.
الأقواس
في التعبيرات النمطية، تحدد تعبيرات الأقواس أنه يمكن وجود أي حرف معلن عنه داخل الأقواس في الموقع المحدد. ألقِ نظرة على سلسلة التعبير النمطي التالية:
|
1 |
t[wo]o |
عند تطبيق ذلك عمليًا، ستكون الكلمتان too و two هما المطابقتان الصالحتان:
|
1 |
grep -n "t[wo]o" <file> |
تفتح تعبيرات الأقواس المجال لبعض الأمور المثيرة للاهتمام. من الممكن استخدام تعبيرات الأقواس لتحديد أنه يمكن وجود أي حرف في الموقع المحدد باستثناء الأحرف المعلن عنها داخل الأقواس. ألقِ نظرة على سلسلة التعبير النمطي التالية. ستكون المطابقة صالحة فقط إذا كان هناك أي حرف غير "c" قبل "ode":
|
1 |
"[^c]ode" |
قم بتشغيله على ملف نص رخصة GPL-3:
|
1 |
grep -n "[^c]ode" <file> |

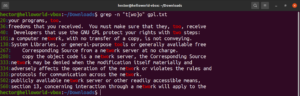
إلى جانب النتيجة من الملف، ستكون النتائج الصالحة الأخرى هي node و abode و anode وغيرها. يمكن لتعبيرات الأقواس أيضًا وصف نطاق من الأحرف. يوضح التعبير النمطي التالي أن المطابقة صالحة إذا كانت بداية السطر حرفًا كبيرًا:
|
1 |
"^[A-Z]" |
قم بتشغيله على ملف نص رخصة GPL-3. ستكون النتيجة جميع الأسطر في الملف النصي:
|
1 |
grep -n "^[A-Z]" <file> |
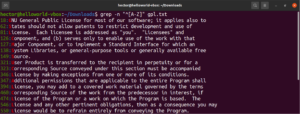
لتسهيل الاستخدام، هناك فئات أحرف معينة لها تسميات محددة. في المثال السابق، استخدمنا النطاق "A-Z" لتحديد الأحرف الكبيرة. بدلاً من ذلك، يمكننا أيضًا استخدام "[:upper:]". ستكون النتيجة هي نفسها:
|
1 |
grep -n "^[[:upper:]]" <file> |
تكرار النمط
في بعض الحالات، قد ترغب في مطابقة نمط معين أو تعبير نمطي صفر أو أكثر من المرات. للقيام بذلك، فإن الحرف التعريفي (meta-character) هو النجمة (*). سيطابق التعبير النمطي التالي جميع الأقواس التي تحتوي فقط على أحرف ومسافات مفردة بينها. لاحظ أن الإعلان عن مجموعات الأحرف الصغيرة والكبيرة والمسافات يأتي معًا دون أي علامات ترقيم:
|
1 |
"([a-zA-Z ]*)" |
قم بتطبيق التعبير النمطي عمليًا باستخدام grep:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

استخدام الأحرف التعريفية كأحرف حرفية
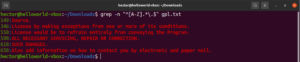
حتى الآن، تعرفنا على العديد من المحارف الوصفية (meta-characters) مثل النجمة (*)، والنقطة (.)، والمثبتات (^ و $)، وما إلى ذلك. كل منها يشير إلى وظيفة فريدة في سياق التعبير النمطي (regex). تظهر المشكلة عندما نحتاج إلى استخدامها كمحارف حرفية، وليس كمحارف وصفية. في مثل هذه الحالات، فإن الشرطة المائلة الخلفية (\) أمام المحرف الوصفي ستشير إلى أنه سيتم استخدامه بالمعنى الحرفي، وليس كمحرف وصفي. ألقِ نظرة على مثال التعبير النمطي هذا. سيطابق جميع السطور التي تبدأ بحرف كبير وتنتهي بنقطة:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
التناوب
باستخدام تعبيرات الأقواس، يمكننا تحديد خيارات مختلفة ممكنة لمطابقة محرف واحد. يحتوي التعبير النمطي (Regex) على ميزة للقيام بالشيء نفسه مع الكلمات والعبارات. للإشارة إلى التناوب، يتم استخدام رمز الأنبوب (|). تظل الخيارات داخل أقواس بينما يفصل رمز الأنبوب بينها. يمكن أن يكون هناك خياران محتملان أو أكثر لتكون المطابقة صالحة. ألقِ نظرة على مثال التعبير النمطي التالي. سيطابق كلاً من “GPL” و “General Public License”:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
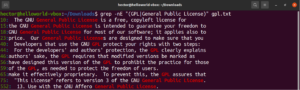
محددات الكمية
باستخدام المحرف الوصفي النجمة (*)، تمكنا من تحديد نمط يتكرر صفرًا أو أكثر من المرات. ومع ذلك، هناك المزيد للعمل معه. من الأسهل شرح محددات الكمية بمثال. يوضح التعبير النمطي التالي أن كلاً من “copyright” و “right” هما مطابقتان صالحتان. تشير علامة الاستفهام (?) إلى أن جزء “copy” اختياري للمطابقة:
|
1 |
grep -nE "(copy)?right" <file> |
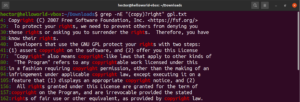
محدد الكمية التالي هو رمز الجمع (+). وهو يتصرف بشكل مشابه للنجمة. ومع ذلك، يجب أن يتطابق النمط المحدد مرة واحدة على الأقل. في المثال التالي، سيطابق التعبير النمطي كلمة “soft” متبوعة بمحرف واحد أو أكثر من المحارف غير الفارغة:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
تحديد تكرار المطابقة
من الممكن تحديد عدد مرات تكرار المطابقة. للقيام بذلك، استخدم الأقواس المتعرجة ({}). سيطابق التعبير النمطي التالي أي كلمة تحتوي على ثلاثة أحرف متحركة كحد أدنى:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

تتيح لك هذه الميزة أيضًا تحديد الحد الأدنى والحد الأقصى لطول المطابقة. في المثال التالي، سيتطابق التعبير النمطي مع أي كلمة يتراوح طولها بين 10 إلى 15 محرفًا:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
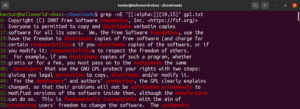
الخاتمة
إن البحث في ملفات النصوص باستخدام grep أمر مفيد للغاية. تجعل التعبيرات النمطية البحث باستخدام grep أكثر إثارة للاهتمام وفائدة. كما أنها تضبط نمط البحث بدقة وفقًا لرغبتك.
على الرغم من أننا استعرضنا بعض التعبيرات النمطية الشائعة، إلا أن هذه مجرد البداية. هناك تعبيرات نمطية أكثر تقدمًا توفر تحكمًا دقيقًا للغاية في سلوك البحث. إلى جانب grep، تُستخدم التعبيرات النمطية أيضًا على نطاق واسع بواسطة أدوات ولغات برمجة أخرى.
حوسبة سعيدة!
التعليقات
لا توجد تعليقات بعد. كن أول من يعلق.