
ملف CSV هو ملف نصي بسيط يخزن البيانات في تنسيق جدولي. في معظم الحالات، تستخدم ملفات CSV الفواصل (,) كمحدد، ومن هنا جاء الاسم CSV (القيم المفصولة بفواصل). ويُستخدم في الحالات التي يكون فيها توافق البيانات أمرًا مهمًا حيث يمكن فتح ملفات CSV باستخدام أي محرر نصوص، وتطبيقات جداول البيانات، وغيرها من الأدوات المتخصصة. في الواقع، توفر العديد من لغات البرمجة دعمًا مدمجًا لـ CSV.
في هذا الدليل، سنتعلم كيفية استخدام CSV في تطبيق Node.js نموذجي.
CSV في Node.js
إن Node.js هي بيئة تشغيل جافا سكريبت مفتوحة المصدر ومتعددة المنصات. لقد أصبحت واحدة من أكثر الخلفيات البرمجية شيوعًا والتي تشغل العديد من خدمات الويب في جميع أنحاء الإنترنت. حتى الشركات الكبرى مثل Netflix و Uber تستخدم Node.js لتشغيل خدماتها.
تحتوي Node.js أيضًا على العديد من الوحدات البرمجية المتاحة للنشر لإضافة وظائف إضافية إلى المشروع. عندما يتعلق الأمر بـ CSV، هناك العديد من الوحدات المتاحة للاستخدام، على سبيل المثال، node-csv, fast-csv، و papaparse إلخ.
كما يوحي عنوان الدليل، سنقوم باستخدام node-csv لقراءة ملفات CSV باستخدام دفق بيانات Node.js. سنقوم أيضًا بتوضيح كيفية العمل مع البيانات التي تم تحليلها، على سبيل المثال، نقل البيانات إلى قاعدة بيانات SQLite.
المتطلبات الأساسية
-
لتنفيذ الخطوات الموضحة في هذا الدليل، ستحتاج إلى المكونات التالية:
-
نظام Linux مهيأ بشكل صحيح. تعرف على المزيد حول تثبيت وتهيئة خادم Ubuntu سحابي على CloudSigma.
-
الوصول إلى مستخدم غير جذر يمتلك صلاحيات sudo . تحقق من إدارة أذونات sudo باستخدام sudoers.
-
محرر نصوص مناسب، على سبيل المثال، Brackets, VS Code, Sublime Text, Vim/NeoVim، إلخ.
-
برامج أخرى:
-
Node.js LTS
-
SQLite
-
الخطوة 1 – تثبيت البرامج اللازمة
لهذا الدليل، قمت بإنشاء خادم خفيف الوزن يعمل بنظام التشغيل Ubuntu 22.04 LTS (متصل عبر SSH):
الآن، سنقوم بتثبيت Node.js و SQLite عليه.
-
تثبيت Node.js LTS
تتوفر Node.js مباشرة من مستودعات حزم Ubuntu الرسمية. ومع ذلك، فهي ليست النسخة الأحدث. لهذا السبب سنعتمد على مستودع خارجي (Nodesource) للحصول على أحدث حزم Node.js.
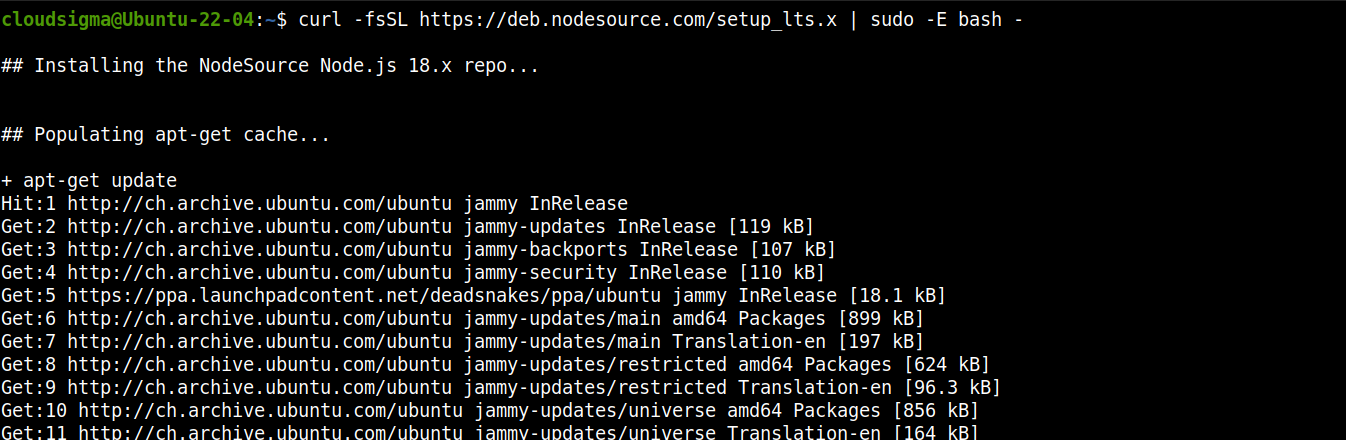
أضف مستودع Node.js LTS:
|
1 |
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - |
الآن، قم بتثبيت Node.js LTS:
|
1 |
sudo apt install nodejs -y |

-
تثبيت SQLite
سنقوم بتثبيت SQLite مباشرة من مستودعات حزم Ubuntu. قم بتشغيل الأوامر التالية:
|
1 |
sudo apt install sqlite3 -y |

الخطوة 2 – إعداد دليل المشروع
في هذا القسم، سنقوم بإعداد دليل مخصص لمشروعنا. سيستضيف جميع ملفات المشروع بالإضافة إلى الوحدات الإضافية.
إنشاء دليل جديد:
|
1 |
mkdir -pv csv_practice |
انتقل إلى الدليل:
|
1 |
cd csv_practice/ |
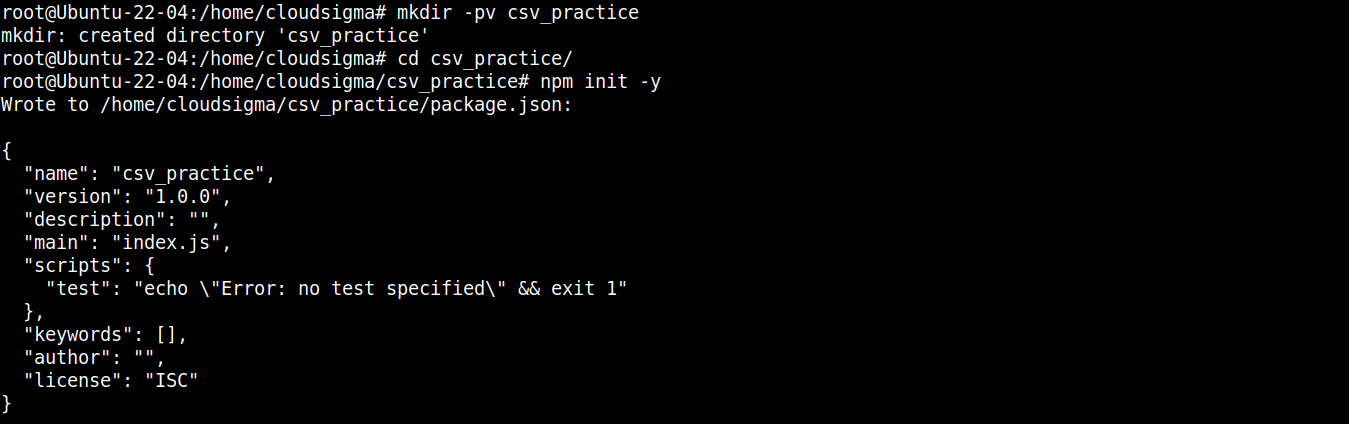
بعد ذلك، قم بتشغيل الأمر التالي للإعلان عن الدليل كـ npm مشروع:
|
1 |
npm init -y |
بمجرد تهيئة مجلد المشروع، يمكننا البدء في تثبيت الحزم والوحدات اللازمة. أولاً، سنقوم بتثبيت node-csv:
|
1 |
npm install csv |

إن وحدة node-csv هي في الواقع مجموعة من عدة وحدات أخرى: csv-generate, csv-parse (لتحليل ملفات CSV)، csv-stringify (لكتابة البيانات إلى CSV)، و stream-transform.
بعد ذلك، نحتاج إلى وحدة للاتصال بـ SQLite. سيقوم الأمر التالي بتثبيت وحدة node-sqlite3 :
|
1 |
npm install sqlite3 |

المكون الذي نحتاجه لمشروعنا هو ملف CSV. لأغراض التوضيح، سنستخدم ملف CSV الخاص بالهجرة في نيوزيلندا:
|
1 |
wget https://www.stats.govt.nz/assets/Uploads/International-migration/International-migration-September-2021-Infoshare-tables/Download-data/international-migration-September-2021-estimated-migration-by-age-and-sex-csv.csv -O migration_data.csv |
دعنا نلقي نظرة سريعة على محتوى الملف:
|
1 |
cat migration_data.csv | less |
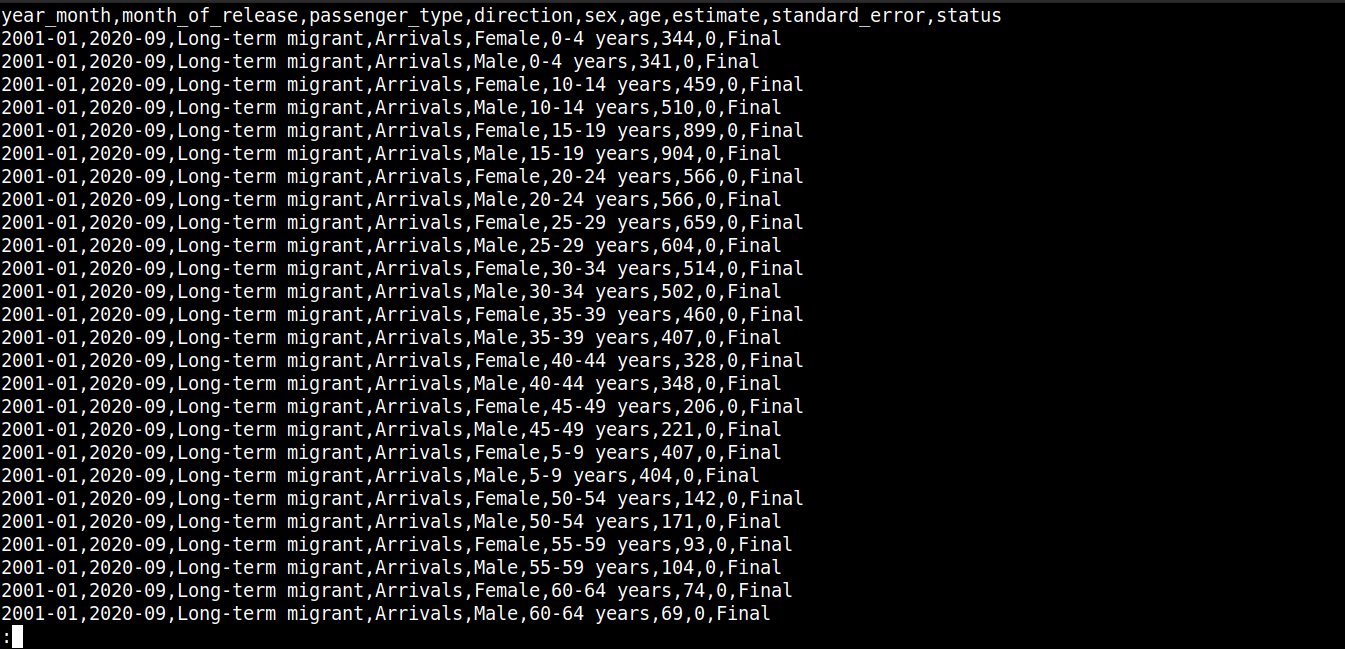
هنا،
-
يصف السطر الأول أسماء الأعمدة.
-
تحتوي السطور التالية على قيم هذه الحقول.
-
يتم فصل كل صف بسطر جديد (\n).
-
يتم فصل كل نقطة بيانات بفاصلة (,).
ومع ذلك، لا يقتصر CSV على استخدام الفواصل كمحدد. تشمل المحددات الشائعة الأخرى النقطتين الرأسيتين (:)، الفاصلة المنقوطة (;)، وعلامات التبويب (\td).
الخطوة 3 – قراءة CSV
في هذا القسم، سنقوم بتوضيح تنفيذ برنامج نموذجي يقرأ البيانات ويحللها من ملف CSV.
أنشئ ملف JavaScript جديدًا:
|
1 |
touch read_csv.js |
افتح الملف في محرر النصوص المفضل لديك:
|
1 |
nano read_csv.js |
أولاً، سنقوم باستيراد وحدات fs و csv-parse :
|
1 2 |
const fs = require("fs"); const { parse } = require("csv-parse"); |
هنا،
-
أولاً، يتم تعيين المتغير fs كائن fs الذي يعيد دالة Node.js require() عند استيراد الوحدة.
-
بعد ذلك، يتم استخراج دالة parse من الكائن الذي تعيده دالة require() إلى متغير parse باستخدام صيغة التفكيك.
بعد ذلك، سنقوم بإضافة أكواد لقراءة ملف CSV:
|
1 2 3 4 5 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) |
هنا،
-
نحن نستدعي createReadStream() من وحدة fs ونمرر ملف CSV الذي نريد قراءته كمعامل. ثم يقوم بإنشاء تدفق قابل للقراءة عن طريق تقسيم الملف الأكبر إلى أجزاء أصغر.
-
بعد إنشاء التدفق، تقوم دالة pipe() بتوجيه أجزاء من بيانات التدفق إلى تدفق آخر. يتم إنشاء هذا التدفق الجديد عند استدعاء دالة parse() من وحدة csv-module.
-
تقوم وحدة csv-module بنشر تدفق تحويل قابل للقراءة/الكتابة يأخذ جزءًا من البيانات ويحوله إلى شكل آخر.
-
تقبل دالة parse() كائنات ذات خصائص. يقوم الكائن بمعالجة البيانات المحللة بشكل أكبر. هنا، يأخذ الكائن الخصائص التالية:
-
delimiter: حرف المحدد لفصل القيم. في حالة ملف CSV المستهدف، فهو الفاصلة (,).
-
from_line: عدد الأسطر التي سيبدأ المحلل في التحليل منها. مع القيمة المحددة 2، سيتخطى المحلل السطر 1 ويبدأ عند السطر 2. وبهذا الترتيب، نتجنب دمج أسماء الأعمدة في البيانات المحللة.
-
بعد ذلك، سنقوم بإرفاق حدث تدفق باستخدام دالة on() من Node.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
هنا،
-
عند إطلاق حدث معين، يسمح حدث التدفق للدالة باستهلاك جزء من البيانات.
-
عندما تكون البيانات المحللة بواسطة دالة parse() جاهزة للاستهلاك، فإنها تطلق حدث data .
-
للوصول إلى البيانات، نقوم بتمرير دالة استدعاء (callback) إلى دالة on() التي تأخذ المعامل row.
-
المعامل row هو جزء من البيانات في شكل مصفوفة (نتيجة التحليل).
-
أخيرًا، يتم تسجيل البيانات في وحدة التحكم (console) باستخدام console.log().
لإنهاء البرنامج، سنقوم بإضافة أحداث تدفق إضافية لمعالجة الأخطاء وطباعة رسالة نجاح عند استهلاك جميع البيانات في ملف CSV. قم بتحديث الكود على النحو التالي:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
هنا،
-
يتم إطلاق الحدث end عندما يتم استهلاك جميع البيانات الموجودة في ملف CSV. وينتج عن ذلك استدعاء console.log() التي تطبع رسالة نجاح.
-
يتم إطلاق الحدث error عند مواجهة خطأ أثناء تحليل بيانات CSV. وينتج عن ذلك استدعاء console.log() التي تطبع رسالة خطأ.
يجب أن يبدو الكود النهائي كما يلي:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const fs = require("fs"); const { parse } = require("csv-parse"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
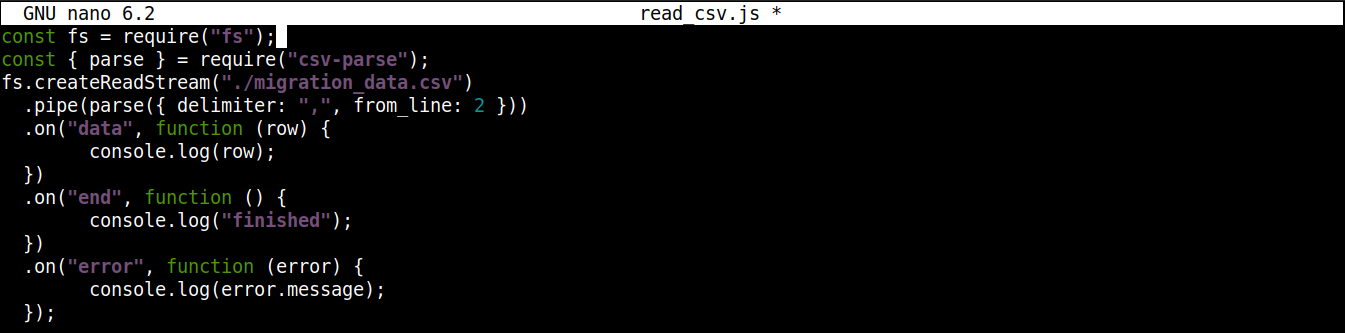
احفظ الملف وأغلق المحرر. نحن الآن جاهزون لتشغيل البرنامج. قم بتشغيله باستخدام Node.js:
|
1 |
node read_csv.js |
يجب أن تبدو المخرجات كالتالي:

لاحظ أنه يتم استهلاك البيانات وتحويلها وطباعتها على وحدة التحكم. وبما أنها عملية مستمرة، فستظهر كما لو أنه يتم تنزيل البيانات بدلاً من طباعة المخرجات دفعة واحدة.
الخطوة 4 – نقل بيانات CSV إلى قاعدة بيانات
حتى الآن، تعلمنا كيفية تحليل ملف CSV باستخدام node-csv. سيوضح هذا القسم كيفية نقل البيانات التي تم تحليلها إلى قاعدة بيانات (SQLite).
أنشئ ملف JavaScript جديدًا للتفاعل مع قاعدة البيانات:
|
1 |
touch csv-to-sqlite3.js |
الآن، افتح الملف في محرر نصوص:
|
1 |
nano csv-to-sqlite3.js |
![]()
سنبدأ برنامجنا بالأكواد التالية:
|
1 2 3 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; |

هنا،
-
في السطر الأول، نقوم باستيراد وحدة fs .
-
في السطر الثالث، يحتوي المتغير filepath على مسار قاعدة بيانات SQLite.
-
في هذه المرحلة، قاعدة البيانات ليست موجودة بعد. ومع ذلك، ستكون ضرورية عند العمل مع node-sqlite3.
بعد ذلك، أضف الأسطر التالية لإنشاء اتصال بقاعدة بيانات SQLite:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } console.log("تم الاتصال بقاعدة البيانات بنجاح"); }); return db; } } |
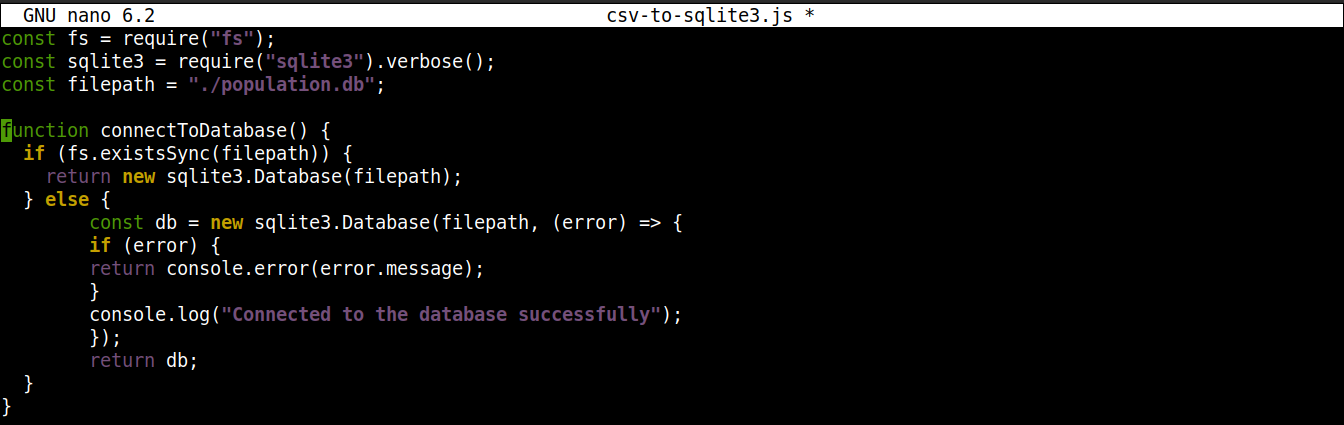
هنا،
-
الدالة connectoToDatabase() تُنشئ اتصالاً بقاعدة البيانات.
-
داخل connectToDatabase()، نقوم باستدعاء existsSync() من وحدة fs داخل عبارة if. تتحقق عبارة if من وجود قاعدة البيانات في الموقع المحدد.
-
إذا كان تقييم الشرط هو true، فإن Database() فئة الخاصة بـ node-sqlite3 . بمجرد إنشاء الاتصال، ترجع الدالة كائناً وتخرج.
-
إذا كان تقييم الشرط هو false (قاعدة البيانات غير موجودة)، فسينتقل التنفيذ إلى كتلة else. هناك، Database() ستبدأ بوجود وسيطتين: مسار إلى ملف قاعدة البيانات ودالة استدعاء (callback).
-
بشكل أساسي، سيتم إنشاء قاعدة البيانات إذا لم تكن موجودة. ومع ذلك، في حال حدوث أي خطأ أثناء عملية الإنشاء، فسيتم تعيين كائن error وطباعة رسالة الخطأ.
بعد ذلك، سنقوم بتقديم الأكواد لإنشاء جدول إذا لم تكن قاعدة البيانات موجودة:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } createTable(db); console.log("Connected to the database successfully"); }); return db; } } function createTable(db) { db.exec(` CREATE TABLE migration ( year_month VARCHAR(10), month_of_release VARCHAR(10), passenger_type VARCHAR(50), direction VARCHAR(20), sex VARCHAR(10), age VARCHAR(50), estimate INT ) `); } module.exports = connectToDatabase(); |
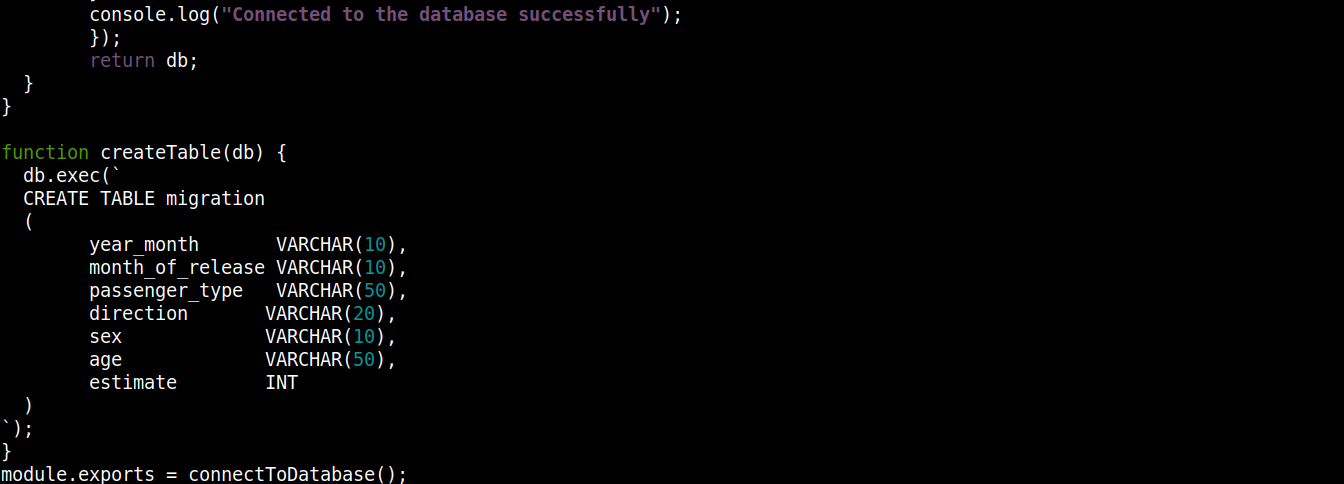
هنا،
-
تقوم connectToDatabase() باستدعاء دالة createTable() التي تقبل الكائنات المخزنة في db كوسيط.
-
خارج connectToDatabase()، قمنا بتعريف دالة createTable() التي تقبل كائن الاتصال db كمعلمة.
-
تأخذ طريقة exec() على db عبارة SQL كوسيط. وداخل عبارة SQL هذه، قمنا بتعريف إنشاء جدول migration بـ 7 أعمدة، حيث يتوافق كل عمود مع عناوين الأعمدة في ملف migration_data.csv .
-
أخيراً، نقوم باستدعاء connectToDatabase() وطريقة وتصدير كائن الاتصال الذي ترجعه حتى نتمكن من استخدامه في ملفات أخرى.
احفظ الملف وأغلق المحرر.
بعد ذلك، سنقوم بإنشاء برنامج آخر لإدراج البيانات التي تم تحليلها في قاعدة البيانات:
|
1 |
nano insert_data.js |
أدخل الكود التالي في insert_data.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const fs = require("fs"); const { parse } = require("csv-parse"); const db = require("./csv-to-sqlite3"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { db.serialize(function () { db.run( `INSERT INTO migration VALUES (?, ?, ? , ?, ?, ?, ?)`, [row[0], row[1], row[2], row[3], row[4], row[5], row[6]], function (error) { if (error) { return console.log(error.message); } console.log(`Row inserted, ID: ${this.lastID}`); } ); }); }); |
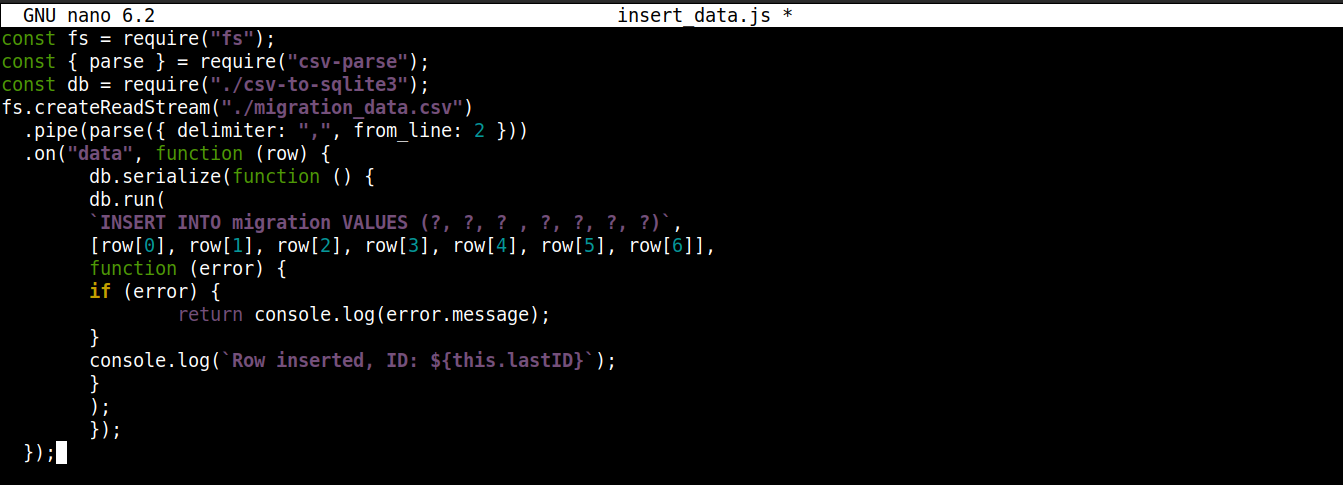
هنا،
-
نقوم بتخزين كائن الاتصال الذي تم الحصول عليه من csv-to-sqlite3.js في المتغير db.
-
داخل رد النداء لحدث البيانات (المرفق بدفق وحدة fs)، نقوم باستدعاء serialize() على كائن الاتصال. تضمن هذه الطريقة انتهاء تنفيذ عبارة SQL واحدة قبل بدء العبارة التالية، مما يمنع حالات السباق في قاعدة البيانات (تشغيل النظام لعمليات متنافسة في نفس الوقت).
-
تقبل الـ serialize() ثلاثة وسائط:
-
الوسيط الأول هو عبارة SQL.
-
الوسيط الثاني هو مصفوفة.
-
الوسيط الثالث هو رد نداء (callback) يتم تشغيله عند إدراج البيانات بنجاح أو فشل إدراجها في قاعدة البيانات.
-
نحن جاهزون لتنفيذ البرنامج. قم بتشغيل insert_data.js باستخدام Node.js:
|
1 |
node insert_data.js |
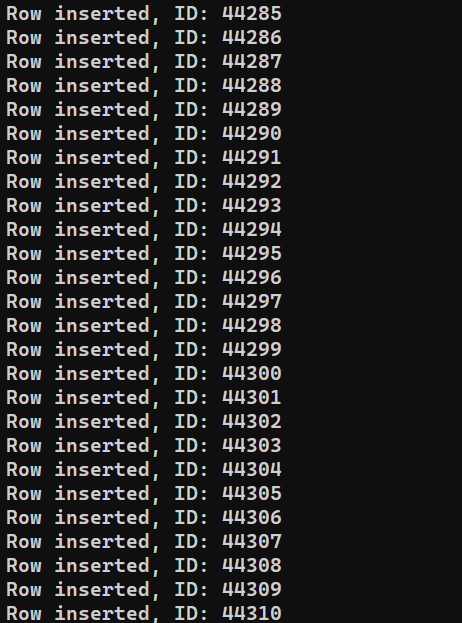
اعتمادًا على أداء النظام، قد تستغرق العملية بعض الوقت لتنتهي. ومع ذلك، عند الاكتمال، يجب أن يبدو المخرج مشابهًا لهذا:
الخطوة 5 – كتابة البيانات إلى CSV
بعد القسم الأخير، أصبح لدينا قاعدة بيانات تحتوي على جميع السجلات التي قمنا بتحليلها من migration_data.csv. في هذا القسم، سنقوم بقراءة البيانات من قاعدة البيانات وكتابتها في ملف CSV منفصل.
أنشئ ملف JavaScript جديدًا لتخزين البرنامج:
|
1 |
nano write_csv.js |
أولاً، أضف السطور التالية لاستيراد fs و csv-stringify جنبًا إلى جنب مع كائن اتصال قاعدة البيانات من csv-to-sqlite3.js:
|
1 2 3 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); |
بعد ذلك، سنقوم بإضافة متغير يحتوي على اسم ملف CSV للكتابة إليه بالإضافة إلى مجرى قابل للكتابة:
|
1 2 3 4 5 6 7 8 9 10 11 |
const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; |
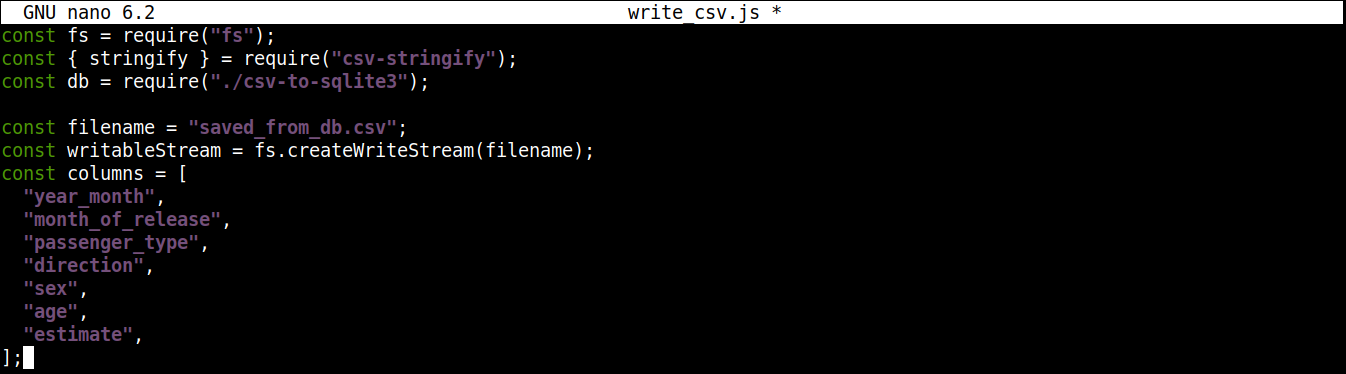
هنا،
-
الـ createWriteStream() تأخذ اسم الملف المراد الكتابة إليه كمعامل. سنقوم بتسمية الملف saved_from_db.csv.
-
الـ column يخزن مصفوفة تحتوي على جميع أسماء الترويسة لبيانات CSV.
بعد ذلك، أضف أسطر البرمجة التالية لقراءة البيانات من قاعدة البيانات وكتابتها في saved_from_db.csv:
|
1 2 3 4 5 6 7 8 9 10 11 |
const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("تم الانتهاء من الكتابة إلى CSV"); |
هنا،
-
نحن نستدعي الـ stringify() مع كائن كمعامل. ينتج عن ذلك مجرى تحويل (transform stream) يقوم بتحويل البيانات من كائن إلى تنسيق CSV. الكائن الممرر إلى stringify() له خاصيتان:
-
header: يقبل قيمة منطقية (Boolean). إذا كانت القيمة هي true، فسيتم إنشاء ترويسة.
-
columns: يقبل مصفوفة تحتوي على أسماء الأعمدة التي سيتم كتابتها في السطر الأول من ملف CSV إذا كان header هو true.
-
-
الـ each() من كائن الاتصال csv-to-sqlite3 يتم استدعاؤه بمعاملين: عبارة SQL (قراءة البيانات من قاعدة البيانات) ودالة استدعاء ذاتي (callback) (لمعالجة النجاح/الخطأ).
-
عند كل تكرار لـ each(), pipe() (من مجرى stringifier) يبدأ في إرسال البيانات على شكل أجزاء (chunks) إلى المجرى القابل للكتابة writableStream. ثم يتم كتابة كل جزء من البيانات في saved_from_db.csv.
-
عند كتابة جميع البيانات في ملف CSV، يتم طباعة رسالة نجاح على شاشة وحدة التحكم (console).
يجب أن يبدو الكود النهائي كما يلي:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("تم الانتهاء من الكتابة إلى CSV"); |
احفظ الملف وأغلق المحرر. يمكننا الآن تشغيل البرنامج باستخدام Node.js:
|
1 |
node write_csv.js |
لتأكيد ما إذا كان قد تم تصدير البيانات بنجاح، تحقق من محتوى saved_from_db.csv:
|
1 |
cat saved_from_db.csv | less |
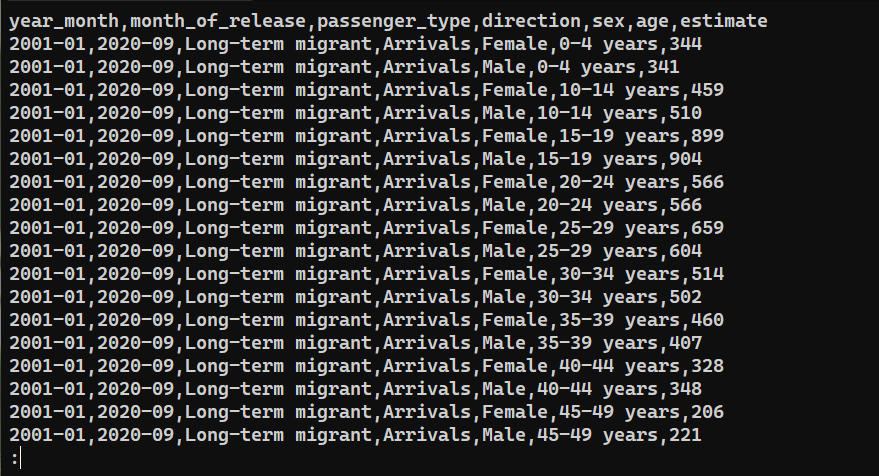
أفكار نهائية
في هذا الدليل، أوضحنا كيفية العمل مع ملفات CSV في Node.js باستخدام وحدات node-csv و node-sqlite3. لقد أنشأنا برامج متعددة لإنجاز مهام مختلفة، على سبيل المثال، تحليل البيانات من CSV، ودفع البيانات إلى قاعدة بيانات SQLite، وكتابة البيانات إلى ملف CSV جديد.
يوضح هذا الدليل جزءًا صغيرًا فقط من إمكانيات node-csv وحدة. تعرف على المزيد حول جميع ميزاتها في مشروع CSV. لمعرفة المزيد حول node-sqlite3، راجع الوثائق الرسمية على GitHub. وهناك وحدة أخرى تستحق الذكر وهي event-stream لتبسيط العمل مع التدفقات.
هل أنت مهتم بتطوير مشروع Node.js الخاص بك بشكل أكبر؟ إليك بعض البرامج التعليمية لـ Node.js التي يجب عليك الاطلاع عليها:
-
كيفية نشر تطبيق Node.js (Express.js) باستخدام Docker على Ubuntu 20.04
-
إعداد تطبيقات Node.js: كيفية أداء مهام الإنتاج على Ubuntu 20.04 باستخدام Node.js
حوسبة سعيدة!
التعليقات
لا توجد تعليقات بعد. كن أول من يعلق.