

كشط الويب، أو زحف الويب، أو حصاد الويب، أو استخراج بيانات الويب هي مرادفات تشير إلى عملية تنقيب البيانات من صفحات الويب عبر الإنترنت. وتعد أدوات كشط الويب أو زواحف الويب أدوات تتصفح صفحات الويب برمجياً لاستخراج البيانات المطلوبة. ويمكن استخدام هذه البيانات، التي عادة ما تكون مجموعات كبيرة من النصوص، لأغراض تحليلية، أو لفهم المنتجات، أو لإشباع فضول المرء حول صفحة ويب معينة.
إذا كنت تتساءل عن كيفية البدء في زحف الويب، فسنعرض لك أساسيات كشط الويب من خلال مجموعة بيانات بسيطة. يجب أن تكون قادراً على متابعة هذا البرنامج التعليمي بغض النظر عن مستوى خبرتك في البرمجة. بالنسبة للمثال العملي، سنستخدم CloudSigma blog. سنحاول الحصول على معلومات حول البرامج التعليمية على صفحة المدونة الخاصة بنا. وبحلول الوقت الذي تقرأ فيه خاتمة هذا البرنامج التعليمي، سيكون لديك أداة كشط ويب تعمل تم إنشاؤها باستخدام Python 3 تقوم بالزحف إلى عدة صفحات في قسم المدونة لدينا، ثم تعرض البيانات على شاشتك.
باستخدام المعرفة المكتسبة من إنشاء أداة كشط الويب الأساسية هذه، يمكنك التوسع فيها وإنشاء أدوات كشط الويب الخاصة بك. سيكون هذا ممتعاً، فلنبدأ!
المتطلبات الأساسية
هذا برنامج تعليمي عملي، لذا يجب أن يكون لديك بيئة تطوير محلية لـ Python 3 لمتابعته بشكل جيد. أولاً، يمكنك الرجوع إلى برنامجنا التعليمي حول كيفية تثبيت Python 3 وإعداد بيئة برمجة محلية على Ubuntu.
Scrapy
يتضمن كشط الويب خطوتين: الخطوة الأولى هي العثور على صفحات الويب وتنزيلها، والخطوة الثانية هي الزحف عبر تلك الصفحات واستخراج المعلومات منها.
هناك العديد من الطرق والمكتبات التي يمكن استخدامها لإنشاء أداة كشط ويب من الصفر في العديد من لغات البرمجة. ومع ذلك، قد يؤدي هذا إلى حدوث مشكلات في المستقبل عندما تصبح أداة كشط الويب الخاصة بك معقدة، أو عندما تحتاج إلى الزحف إلى صفحات متعددة بإعدادات وأنماط مختلفة في نفس الوقت. قد تكون مهمة شاقة للغاية معرفة كيفية تحويل البيانات التي تم كشطها بين تنسيقات مختلفة مثل CSV أو XML أو JSON.
بينما قد يفضل البعض تحدي بناء أداة كشط الويب الخاصة بهم من الصفر، فمن الأفضل ألا تعيد اختراع العجلة بل تبنيها فوق مكتبة موجودة بالفعل تتعامل مع كل هذه المشكلات. سنستخدم Scrapy، وهي مكتبة Python، جنباً إلى جنب مع Python 3 لتنفيذ أداة كشط الويب في هذا البرنامج التعليمي. Scrapy هي أداة مفتوحة المصدر وواحدة من أشهر وأقوى مكتبات كشط الويب في Python. تم بناء Scrapy للتعامل مع بعض الوظائف الشائعة التي يجب أن تتوفر في جميع أدوات الكشط. بهذه الطريقة لن تضطر إلى إعادة اختراع العجلة في كل مرة تريد فيها تنفيذ زاحف ويب. مع Scrapy، تصبح عملية بناء أداة الكشط سهلة وممتعة.
يتوفر Scrapy من خلال PyPi، المعروف باسم pip – فهرس حزم Python. PyPi هو مستودع مملوك للمجتمع يستضيف معظم حزم Python. عندما تقوم بتثبيت وإعداد Python 3 على بيئة التطوير المحلية الخاصة بك، فإنه يقوم بتثبيت pip أيضاً، والذي يمكنك استخدامه لتثبيت حزم Python.
الخطوة 1: كيفية بناء أداة كشط ويب بسيطة
أولاً، لتثبيت Scrapy، قم بتشغيل الأمر التالي:
|
1 |
pip install scrapy |
اختيارياً، يمكنك اتباع تعليمات تثبيت Scrapy الرسمية من صفحة التوثيق. إذا قمت بتثبيت Scrapy بنجاح، فقم بإنشاء مجلد للمشروع باستخدام اسم من اختيارك:
|
1 |
mkdir cloudsigma-crawler |
انتقل إلى المجلد وقم بإنشاء الملف الرئيسي للكود. سيحتوي هذا الملف على جميع الأكواد الخاصة بهذا البرنامج التعليمي:
|
1 |
touch main.py |
إذا كنت ترغب في ذلك، يمكنك إنشاء الملف باستخدام محرر النصوص أو بيئة التطوير المتكاملة (IDE) بدلاً من الأمر أعلاه.
بعد ذلك، افتح الملف، ودعنا نبدأ بإنشاء أداة كشط أساسية تستخدم Scrapy. سنقوم بإنشاء فئة (class) في Python ترث من scrapy.Spider، وهي فئة عنكبوت أساسية من Scrapy. ستحتوي هذه الفئة على سمتين مطلوبتين كما هو محدد أدناه:
- name — اسم نصي (string) لتحديد العنكبوت (يمكنك إدخال اسم من اختيارك).
- start_urls — مصفوفة تحتوي على قائمة بعناوين URL للزحف منها. سنبدأ بعنوان URL واحد.
أضف مقتطف الكود التالي في الملف المفتوح لإنشاء العنكبوت (spider) الأساسي:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
فيما يلي شرح لكل سطر من أسطر الكود:
يستورد السطر الأول Scrapy، مما يسمح لنا باستخدام الفئات (classes) المتنوعة التي توفرها الحزمة.
في السطر التالي، نقوم بتوسيع فئة Spider التي يوفرها Scrapy وإنشاء فئة فرعية (subclass) تسمى CloudSigmaCrawler. من خلال توسيع الفئة (Spider)، نحصل على إمكانية الوصول إلى خصائص الفئة التي يمكننا استخدامها الآن في الكود الخاص بنا. في هذه الحالة، تمتلك فئة Spider طرقًا (methods) وسلوكيات تحدد كيفية تتبع عناوين URL واستخراج البيانات من صفحات الويب. ومع ذلك، فهي لا تعرف عناوين URL التي يجب تتبعها أو البيانات التي يجب استخراجها. ومن خلال توسيعها، يمكننا تقديم المعلومات المطلوبة إلى الطرق. لفهم المزيد حول إنشاء الفئات الفرعية والتوسيع، تابع القراءة عن مبادئ البرمجة كائنية التوجه (Object-Oriented programming).
في CloudSigmaCrawler الخاص بنا، نقوم بتعريف السمات المطلوبة. أولاً، نسمي العنكبوت الخاص بنا cloudsigma_crawler. بعد ذلك، نوفر عنوان URL واحدًا للبدء منه: https://blog.cloudsigma.com/blog/. سيؤدي فتح عنوان URL هذا إلى نقلك إلى الصفحة 1 من مدونة CloudSigma التي تحتوي على بعض من البرامج التعليمية العديدة.
حان الوقت لاختبار أداة الكشط (scraper). لديك بعض الخيارات. إذا كنت تستخدم بيئة تطوير متكاملة (IDE)، على سبيل المثال، PyCharm community edition من JetBrains، فمن المحتمل أنها تأتي مع زر يمكنك النقر عليه ببساطة لتشغيل السكربت. هناك خيار آخر وهو اتباع الطريقة المعتادة لتشغيل ملفات Python من سطر الأوامر: python path/to/file.py، أو py path/to/file.py. وخيار آخر هو واجهة سطر أوامر Scrapy. يأتي Scrapy مع واجهة سطر أوامر خاصة به للمساعدة في بدء تشغيل أداة الكشط. أدخل الأمر التالي لبدء تشغيل أداة الكشط:
|
1 |
scrapy runspider main.py |
اعتمادًا على إصدار مكتبة Scrapy الذي قمت بتثبيته، يجب أن ترى مخرجات تشبه ما يلي:
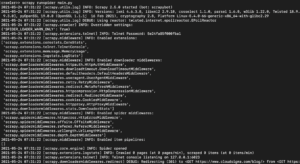
كما ترى، المخرجات طويلة جدًا لذا اخترنا بعض الأجزاء فقط. إليك ما حدث عند تنفيذ الأمر:
- تمت تهيئة أداة الكشط. وبالتالي، قامت بتحميل المكونات والإضافات الإضافية التي تحتاج إلى استخدامها في تتبع وقراءة البيانات من عناوين URL.
- باستخدام عنوان URL المقدم في قائمة start_urls، قامت بجلب كود HTML من الصفحة. هذه عملية مشابهة للعملية التي يتبعها المتصفح عند فتح صفحات الويب.
- بعد جلب كود HTML، يتم تمريره إلى طريقة parse التي لم نقم بتعريفها بعد. في الوقت الحالي لا تفعل أي شيء، وبالتالي يخرج العنكبوت ببساطة دون إجراء أي معالجة. سنقوم بتعريف سلوك طريقة parse في الخطوة التالية.
الخطوة 2: كيفية استخراج البيانات من صفحة
في الخطوة 1، قمنا فقط بتنفيذ أداة كشط أساسية تجلب صفحة HTML ولكنها لا تفعل شيئًا بعد ذلك. في هذا القسم، سنقدم تعليمات لاستخراج البيانات. في صفحة CloudSigma Blog التي نريد استخراج البيانات منها، هناك بعض الأشياء التي يمكنك ملاحظتها مثل:
- الترويسة (header)، الموجودة في جميع الصفحات.
- قائمة التنقل وصندوق تصفية البحث.
- القائمة الفعلية للبرامج التعليمية في تنسيق شبكي (grid).
يمنحك عرض الكود المصدري لصفحة HTML التي تنوي كشطها فكرة عامة عن بنية الصفحة. يساعدك هذا في كتابة أداة الكشط. يمكنك عرض الكود المصدري عن طريق النقر بزر الماوس الأيمن على الصفحة واختيار "عرض الكود المصدري" (View Source Code)، أو الضغط على Ctrl + U. إليك مقتطف من الكود المصدري:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="رابط دائم لـ: "تأمين Apache باستخدام Let’s Encrypt على Ubuntu 18.04"">تأمين Apache باستخدام Let’s Encrypt على Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>إن أمن المواقع الإلكترونية والبيانات من المواضيع التي لا يمكن الاستهانة بها. إن المعلومات الحساسة للغاية والتي تشمل السجلات المالية والمعلومات الخاصة بالعملاء تكون دائماً قيد الانتقال بين جهاز الكمبيوتر الخاص بالمستخدم وموقعك الإلكتروني. وعندما تأخذ هذه الحقيقة بعين الاعتبار، فليس من الصعب معرفة سبب أن المواقع غير الآمنة قد تؤدي إلى حدوث خرق يمكن أن يلحق ضرراً جسيماً بأعمالك. هناك … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">اقرأ المزيد</a></div> </div> </div> ... </article> </div> </body> |
كما ترى، فإن كل درس تعليمي في المدونة محاط بعلامة HTML تسمى <article>. ستتضمن عملية كشط الصفحة خطوتين. الخطوة الأولى ستكون جلب كل درس تعليمي في المدونة من خلال النظر إلى أجزاء الصفحة التي تحتوي على البيانات التي نريدها. الخطوة التالية هي سحب البيانات التي نريدها من كل درس تعليمي تم تحديده بواسطة علامة HTML.
يحدد Scrapy البيانات المراد جلبها بناءً على المحددات التي توفرها. يمكننا استخدام المحددات للعثور على عنصر واحد أو أكثر في الصفحة والحصول على البيانات الموجودة داخل هذه العناصر. يدعم Scrapy كلاً من XPath و CSS من المحددات.
من المصدر الذي استعرضناه سابقاً، تبدو محددات CSS أسهل. وبالتالي، سيكون هذا هو الخيار الذي سنعتمده لأنه سيساعدنا في العثور على جميع الدروس التعليمية في الصفحة. من كود مصدر HTML، يتم تحديد كل درس تعليمي داخل فئة CSS تسمى post. عادةً ما يتم تحديد أسماء فئات CSS باستخدام .class_name (نقطة class_name). وبالتالي، سنستخدم .post لمحدد CSS الخاص بنا. داخل كود مصدر أداة الكشط main.py، سنقوم بتمرير فئة .post إلى كائن الاستجابة (response object)، بحيث يبدو ملفك الآن كما يلي:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
ستقوم مقتطفة البرمجية هذه بجلب جميع البرامج التعليمية على الصفحة باستخدام start_urls المحددة، وتكرار الحلقات عبر البرامج التعليمية لاستخراج البيانات. في الخطوة التالية، سترغب في استخراج هذه البيانات وعرضها. إذا قمت بفحص الكود المصدري لـ مدونة CloudSigma مجددًا، سترى أن عنوان كل برنامج تعليمي مخزن داخل علامة <a> الموجودة داخل علامة <h2>، على سبيل المثال:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
يحتوي كل كائن برنامج تعليمي نقوم بالتكرار عليه على طريقة CSS يمكننا تمرير محدد (selector) إليها لتحديد موقع العناصر الفرعية واستخراجها. في هذا المثال، نريد استخراج العنوان الموجود داخل علامة <a>. توجد هذه العلامة داخل علامة <h2> داخل فئة .entry-header داخل فئة .entry-wrap. يمكننا تمرير محددات CSS هذه إلى طريقة الكائن لاستخراج العنوان، وتعديل الكود ليبدو كالتالي:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
الفاصلة اللاحقة بعد extract_first() ليست خطأً مطبعيًا لأننا سنضيف المزيد من الكود أسفل هذا القسم.
تتضمن بعض النقاط التي يجب ملاحظتها من الكود المصدري أعلاه ما يلي:
- تم إلحاق ::text بالمحدد – هذا عبارة عن محدد CSS زائف يوجه الكود لجلب النص الموجود داخل العلامة وليس العلامة نفسها.
- استدعاء طريقة extract_first() داخل الكائن – يوجه الكود لاختيار العنصر الأول فقط الذي يطابق المحدد. وبالتالي، نحصل على سلسلة نصية بدلاً من قائمة عناصر.
بعد ذلك، احفظ الملف وقم بتشغيل الكود عن طريق إدخال الأمر التالي في الطرفية:
|
1 |
scrapy runspider main.py |
في المخرجات، يجب أن تشاهد عناوين الدروس التعليمية:
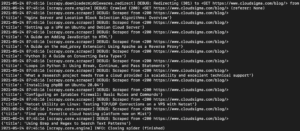
يمكننا الاستمرار في التوسع في هذا عن طريق إضافة المزيد من المحددات للحصول على تفاصيل أخرى حول الدرس التعليمي، مثل عنوان URL الخاص بالدرس، والصورة البارزة، والتعليق التوضيحي.
دعنا نفحص كود HTML لدرس تعليمي واحد مرة أخرى:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="رابط دائم لـ: "تأمين Apache باستخدام Let’s Encrypt على Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="رابط دائم لـ: "تأمين Apache باستخدام Let’s Encrypt على Ubuntu 18.04"">تأمين Apache باستخدام Let’s Encrypt على Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>أمن المواقع الإلكترونية والبيانات من المواضيع التي لا يمكن الاستهانة بها. إن المعلومات الحساسة للغاية والتي تشمل السجلات المالية والمعلومات الخاصة بالعملاء تكون دائمًا قيد النقل بين جهاز كمبيوتر المستخدم وموقعك الإلكتروني. وعندما تفكر في هذه الحقيقة، ليس من الصعب معرفة سبب أن المواقع غير الآمنة قد تؤدي إلى حدوث خرق يمكن أن يلحق ضررًا جسيمًا بأعمالك. هناك … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">اقرأ المزيد</a></div> </div> </div> </article> </div> </body> |
نريد محاولة استخراج الأجزاء المميزة، أي عنوان URL الخاص بالدرس التعليمي، والصورة البارزة، والتعليق التوضيحي.
- من مقتطف الكود أعلاه، يتم تخزين صورة المدونة داخل السمة data-lazy-src لعلامة img داخل علامة <a> داخل علامة div في بداية الدرس التعليمي للمدونة. يمكننا استخدام محدد CSS لجلب القيمة كما فعلنا مع عناوين الدروس التعليمية.
- الحصول على عنوان URL الخاص بالدرس التعليمي أمر بسيط، حيث لدينا علامة <a> داخل عنصر <div>.
- التعليق التوضيحي محاط داخل علامة <p> الموجودة داخل علامة <div>.
سنستخدم فئات CSS للحصول على ما نريد. دعنا نعدل الكود ليصبح كالتالي:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
احفظ التغييرات وقم بتشغيل الكود باستخدام الأمر التالي:
|
1 |
scrapy runspider main.py |
سترى المزيد من البيانات في المخرجات، مثل عنوان URL والصورة والتعليق التوضيحي الذي أضفناه:

هذا كل ما يتعلق بزحف صفحة واحدة. بعد ذلك، دعنا نرى كيف يمكننا إنشاء أداة زحف تتبع الروابط.
الخطوة 3: كيفية زحف صفحات متعددة
حتى هذه النقطة، قمنا بإنشاء أداة زحف يمكنها الحصول على البيانات من صفحة واحدة. ومع ذلك، نريد أكثر من ذلك. أنت تريد عنكبوتًا (spider) يمكنه تتبع الروابط واستخراج البيانات من صفحات متعددة لموقع ويب برمجياً.
إذا ذهبت إلى أسفل صفحة مدونة CloudSigma، فستلاحظ روابط تقسيم الصفحات (pagination)، وسهمًا صغيرًا يشير إلى اليمين يوضح الصفحة التالية. إليك مقتطف كود HTML:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">الصفحة 1 من 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="الصفحة الأخيرة">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
يوضح المقتطف العديد من روابط التنقل بين الصفحات داخل علامات <li>، أسفل علامة <div> مع فئة CSS .x-pagination. ينصب تركيزنا على الرابط الذي يشير إلى الصفحة التالية. إنه موجود في علامة <a> لآخر <li> في علامة <ul>.
يحتوي الرابط الذي يشير إلى الصفحة التالية على فئة .prev-next داخل علامة <a> كما هو موضح في المقتطف أعلاه. ومع ذلك، إذا انتقلت إلى الصفحة التالية، فستلاحظ أيضًا أن روابط الصفحة السابقة والتالية تحتوي على فئة CSS هذه. ضع في اعتبارك هذا المقتطف للصفحة 2:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">الصفحة 2 من 45</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="الصفحة الأخيرة">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
إذا استخدمنا طريقة extract_first() الخاصة بـ Scrapy، فستعمل على الصفحة الأولى. وعندما تصل إلى الصفحة التالية، ستختار الرابط الأول الذي يحتوي على الفئة .prev-next، والذي يشير في المقتطف أعلاه إلى الصفحة الأولى. سيؤدي هذا إلى حدوث حلقة تكرارية. لذلك، سنستخدم طريقة extract() الخاصة بـ Scrapy. تستخرج هذه الطريقة جميع العناصر التي تطابق حالة الاستخدام وتضعها في مصفوفة. ومن هذه المصفوفة، يمكننا اختيار العنصر الأخير الذي سيحتوي على الرابط الفعلي الذي يشير إلى الصفحة التالية. قم بتعديل الكود الخاص بك ليبدو كالتالي:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
دعنا نستعرض الكود الخاص بتحديد next_page.
نقوم أولاً بتعريف محدد لروابط الصفحة التالية والسابقة. ثم نستخدم الدالة extract() لاستخراج عناوين URL ووضعها في مصفوفة. سيكون متغير next_page عبارة عن مصفوفة تحتوي على عنصرين مثل:
|
1 |
next_page = [prev_page_url, next_page_url] |
بما أننا ننتقل إلى الصفحة التالية، فسنختار العنصر الأخير في المصفوفة. يختار next_page[-1] العنصر الأخير في المصفوفة.
تحقق كتلة if ما إذا كان متغير next_page يحتوي على قيمة ما، ثم تستدعي الدالة scrapy.Request(). في الكود الخاص بنا، نوجه هذه الدالة لزحف الصفحة باستخدام عنوان URL المقدم وتمريره مجددًا إلى الدالة parse() حتى نتمكن من تحليلها لاستخراج البيانات وتكرار العملية للصفحة التالية. تتكرر هذه العملية حتى لا تجد رابطًا للصفحة التالية، أو بالأحرى إذا فشلت الكتلة، فإنها تتوقف.
احفظ الكود الخاص بك وقم بتشغيله. ستلاحظ أن التكرار يستمر في التنقل عبر الصفحات كلما وجد المزيد من الصفحات لكشطها. هذه هي الطريقة التي تحدد بها أداة كشط تتبع الروابط على موقع ويب. مثالنا مباشر للغاية. نحن نذهب فقط إلى صفحة، ونجد رابط الصفحة التالية، ونكرر العملية. في حالات الاستخدام الأخرى، قد ترغب في تتبع العلامات أو الروابط التي تشير إلى مصادر خارجية والمزيد. إليك الكود المصدري الكامل لأداة كشط الويب الأساسية باستخدام Python 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
الخاتمة
في هذا البرنامج التعليمي، قمنا ببناء أداة كشط ويب أساسية يمكنها الزحف إلى مدونة CloudSigma ودليلها وعرض بعض المعلومات حول البرامج التعليمية للمدونة في حوالي 27 سطرًا برمجياً فقط.
بالطبع، هذا ممكن لأننا قمنا ببنائه فوق مكتبة Scrapy Python. هذا مجرد أساس من شأنه مساعدتك في بناء أدوات كشط أكثر تعقيدًا تتبع المزيد من العلامات، ونتائج البحث للمواقع الإلكترونية، والمزيد. يمكنك الاطلاع على وثائق Scrapy الرسمية لمزيد من المعلومات حول العمل مع Scrapy.
حوسبة سعيدة!
التعليقات
لا توجد تعليقات بعد. كن أول من يعلق.