

该 grep 命令是一个用于在文本中搜索模式的强大工具。它预装在任何 Linux 发行版中。这里是我们的 关于设置 LAMP 栈(Linux、Apache、MySQL 和 PHP)的教程.
grep 这个名字代表全局正则表达式打印。该工具在输入中搜索指定的模式。原则上,这听起来微不足道。然而,它真正的威力在于你如何定义模式。本指南 详细阐述了如何将 grep 与正则表达式结合使用来进行复杂的搜索。 让我们开始吧!
如何使用 Grep
grep 命令本身并不复杂。它只需要模式和要在其中进行搜索的内容。以下是 grep 命令的基本结构:
|
1 |
grep <regex> <file> |
搜索文本
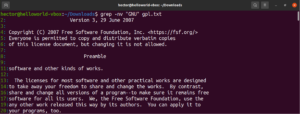
首先,获取一个示例文件来执行操作。下载 GNU General Public License v3.0(文本格式)。这是一个相当大的文本文件,包含许多单词和短语。如果您使用的是 Ubuntu,您可以在下面的文件中找到它。按照我们的 快速轻松安装 Ubuntu 的教程.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

接下来,您可以使用 grep 进行基本的文本搜索:
|
1 |
grep <pattern> <text_file> |
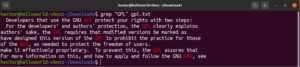
可以将一个命令的输出通过管道传输给 grep:
|
1 |
cat gpl.txt | grep <pattern> |
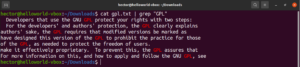
区分大小写
默认情况下,grep 区分大小写。在许多情况下,忽略大小写可能是最佳选择。要禁用区分大小写的搜索,请使用 “-i” 或 “–ignore-case” 标志:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
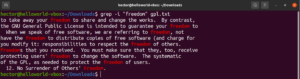
反向查找
默认情况下,grep 的行为是打印找到模式的行。反向匹配是指当您不想看到与模式匹配的行时的现象。为了进行反向匹配,您需要使用 “-v” 或 “–invert-match” 标志:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
行号
在非常大的文件上运行 grep 时,很难跟踪搜索结果的位置。为了让事情变得更容易,grep 具有显示行号的功能。要启用行号,请使用 “-n” 或 “–line-number” 标志:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
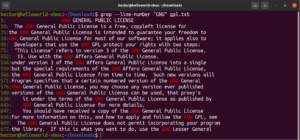
可以组合多个 grep 参数。以下 grep 命令将在打印行号的同时执行反向匹配:
|
1 |
grep -nv <pattern> <file> |
正则表达式
在本指南的开始,我们提到 grep 代表全局正则表达式打印。术语 “正则表达式” 被定义为描述搜索模式的特殊字符串。正则表达式有其自己的结构和规则。
有许多字符串搜索算法和工具使用正则表达式(简称 regex)来执行搜索和替换操作。虽然它很流行,但不同的应用程序和编程语言对正则表达式的实现略有不同。在本节中,我们将展示一些使用 grep 的正则表达式方法。
字面量匹配
在之前的 grep 示例中,grep 在给定的文本文件中搜索了特定的字符串。Grep 实际上是在使用最基本的正则表达式进行搜索。定义搜索给定字符串精确匹配的正则表达式模式被称为“字面量”。这个名字源于它们逐个字符地字面匹配模式这一事实。
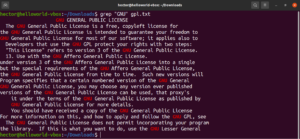
字面匹配适用于字母和数字字符(以及某些特殊字符)。然而,根据其他表达式机制,这种行为可能会发生变化:
|
1 |
grep "<string>" <file> |
锚点匹配
锚点是特殊字符,用于定义匹配在行中应处于的位置,以实现有效匹配。这里有一个简单的例子。如果我们只想找到以字符串“GNU”开头的行,那么带有正则表达式的 grep 将如下所示。在这里,字符“^”是锚点,定义了只有在行首的匹配才是有效的:
|
1 |
grep -n "^GNU" <file> |

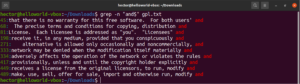
类似地,如果我们只想找到以字符串“works”结尾的行,那么带有正则表达式的 grep 将如下所示。在这里,字符“$”是锚点,定义了只有在行尾的匹配才是有效的:
|
1 |
grep -n "and$" <file> |
任意字符匹配
在进行文本搜索时,您可能希望定义在特定位置可以出现任何字符。在正则表达式中,这由句点字符(.)表示。
看看这个例子。在 GNU GPL 3 文本文件中,单词“accept”和“except”都含有共同的部分“cept”。此外,这两个单词在“cept”部分之前都有两个字符。以下 grep 命令将匹配在“cept”部分之前有两个字符的任何单词:
|
1 |
grep -n "..cept" <file> |
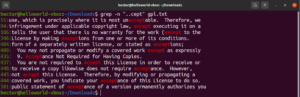
根据这个正则表达式,其他单词如 suscept、unaccept、unexpected 等也是有效的匹配。
括号
在正则表达式中,括号表达式定义了在指定位置可以出现括号内声明的任何字符。看看以下正则表达式字符串:
|
1 |
t[wo]o |
在实际应用中,单词 too 和 two 将是有效的匹配:
|
1 |
grep -n "t[wo]o" <file> |
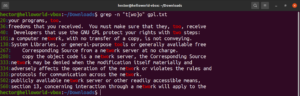
括号表达式为一些有趣的事情提供了可能。可以使用括号表达式来表示在指定位置可以出现除括号内声明的字符之外的任何字符。看看以下正则表达式字符串。只有在“ode”之前出现除“c”之外的任何字符时,匹配才有效:
|
1 |
"[^c]ode" |
在 GPL-3 许可证文本文件上运行它:
|
1 |
grep -n "[^c]ode" <file> |

除了文件中的结果外,其他有效结果还包括 node、abode、anode 等。括号表达式还可以描述字符范围。以下正则表达式表示如果行首是大写字符,则匹配有效:
|
1 |
"^[A-Z]" |
在 GPL-3 许可证文本文件上运行它。结果将是文本文件中的所有行:
|
1 |
grep -n "^[A-Z]" <file> |
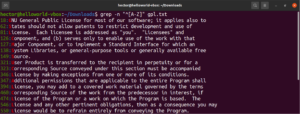
为了便于使用,某些字符类具有指定的标签。在前面的示例中,我们使用范围“A-Z”来定义大写字符。相反,我们也可以使用“[:upper:]”。结果将是相同的:
|
1 |
grep -n "^[[:upper:]]" <file> |
重复模式
在某些情况下,您可能希望匹配特定模式或正则表达式零次或多次。为此,元字符是星号(*)。以下正则表达式将匹配所有仅包含字母和单个空格的括号。请注意,小写、大写字符集和空格的声明是连在一起的,没有任何标点符号:
|
1 |
"([a-zA-Z ]*)" |
使用 grep 实际运行该正则表达式:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

将元字符用作字面字符
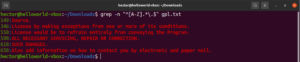
到目前为止,我们已经接触了各种元字符,如星号 (*)、英文句点 (.)、锚点 (^ 和 $) 等。它们在正则表达式上下文中各自代表一个独特的功能。当需要将它们用作字面量而不是元字符时,问题就出现了。在这种情况下,在元字符前面加上反斜杠 (\) 将表示它将以字面量意义使用,而不是作为元字符。看看这个正则表达式示例。它将匹配所有以大写字母开头并以英文句点结尾的行:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
分支
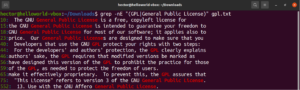
使用括号表达式,我们可以为单个字符匹配指定不同的可能选择。正则表达式也具有对单词和短语执行相同操作的功能。为了表示分支选择,可以使用管道字符 (|)。这些选项保留在圆括号内,而管道字符将它们彼此分隔开。要使匹配有效,可以有两个或多个可能的选项。看看下面的正则表达式示例。它将同时匹配 “GPL” 和 “General Public License”:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
量词
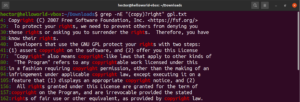
使用星号 (*) 元字符,我们能够重复定义一个模式零次或多次。然而,还有更多可以使用的内容。用一个例子来解释量词会更容易。以下正则表达式说明了 “copyright” 和 “right” 都是有效的匹配。问号 (?) 表示 “copy” 部分是可选匹配的:
|
1 |
grep -nE "(copy)?right" <file> |
下一个量词是加号 (+)。它的行为与星号类似。但是,定义的模式必须至少匹配一次。在以下示例中,正则表达式将匹配 “soft” 以及一个或多个非空白字符:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
指定匹配重复次数
可以指定匹配重复的次数。为此,请使用花括号 ({})。以下正则表达式将匹配包含至少三个元音字母的任何单词:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

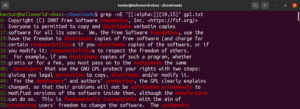
此功能还允许您定义匹配长度的下限和上限。在以下示例中,正则表达式将匹配长度为 10-15 个字符的任何单词:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
总结
使用 grep 搜索文本文件非常方便。正则表达式使使用 grep 进行搜索变得更加有趣和有用。它们还可以根据您的心愿微调搜索模式。
虽然我们已经演示了一些常用的正则表达式,但这只是一个开始。还有更高级的正则表达式,可以对搜索行为提供最精细的控制。除了 grep 之外,正则表达式还被其他工具和编程语言广泛使用。
祝您计算愉快!
评论
暂无评论。发表第一条评论吧。