

企业意味着大量的数据,这使得处理和管理数据的难题变得更加艰巨。传统上,几十年来该行业一直使用 RDBMS 系统,但随着 21 世纪大数据的出现,NoSQL(不仅是 SQL)数据库开始出现,用于处理大规模的非结构化和半结构化数据。
在这篇文章中,我将搭建一个 MongoDB 集群。
MongoDB 是一个免费且开源的 NoSQL 文档数据库,因其提供的高可扩展性和灵活性而被广泛使用。
要在生产环境中部署 MongoDB,建议使用副本集(Replica Sets)。副本集是 MongoDB 在关系型数据库世界中相当于主/从(Master/Slave)架构的实现,但相比之下,它们的搭建非常轻松,因为一切都是内置的。有关副本集的更多信息,请查看 TutorialsPoint’s 关于复制过程的定义.
规划您的 MongoDB 云服务器集群
我将创建一个 3 节点集群。为它们分配相等的资源非常重要,因为其中任何一个都可能成为主(即 master)服务器。这些节点或机器可以运行在任何操作系统上,但在本教程中,我将使用 Ubuntu 18.04 LTS。关于如何挂载和设置来自 CloudSigma’s 库的预装镜像,您可以参考 本教程.
既然副本集(Replica Set)的核心意义在于集群应该在单个节点宕机时存活,那么如果您的所有服务器都位于同一个物理主机上,那就毫无意义了。幸运的是,CloudSigma 确实提供了一种名为 可用性组 的功能。这意味着您可以指示系统将您的所有三台服务器划分到不同的组中。通过这样做,它们将永远不会位于同一个物理主机上。有关此功能以及其他安全和业务连续性功能的更多信息,请参见 此处.
使用 64 位版本的 Linux 也非常重要。原因很简单,MongoDB 在 32 位系统上运行效果不佳(更多相关信息请参见 此处).
在云端安装 MongoDB
这一部分非常简单。要么使用预先配置好的 Ubuntu 18.04 镜像,要么自己安装。
CPU、RAM 和磁盘配置因人而异,取决于您的负载。对于较小的安装,4 GHz CPU、4 GB RAM 和 10 GB 磁盘(用于系统)应该足够了。当您挂载驱动器时,请确保您使用的是 VirtIO。如果使用 IDE,性能将显著下降。此外,由于您正在创建副本集(Replica Set),您需要所有节点(和应用服务器)都处于同一个 VLAN 中。
与许多其他云厂商不同,您无需配置 RAID10 或类似技术来提高存储性能。 正如我们的许多客户所报告的那样,通过在 CloudSigma 同时使用 SSD 和机械硬盘,您将获得令人惊叹的开箱即用性能。
我仍然建议将 MongoDB 数据保存在单独的驱动器上。原因很简单,在某些时候您可能需要进行一些文件系统优化,而您并不想对整个文件系统进行这些优化。
考虑到这一点,在设置好服务器后直接添加该驱动器是最简单的。现在,让我们先专注于系统安装。如果您是自己安装(而不是使用预先配置好的系统),我建议您在启动菜单中按 F4 并选择 ‘安装最小虚拟机’.
我正在创建 3 台机器,每台机器的配置如下:
- CPU: 4 GHz
- RAM: 4 GB
- SSD: 10 GB (Ubuntu 18.04 LTS), 20 GB (额外驱动器)
如 SSD 部分所述,我正在挂载一个容量为 10 GB 且安装了 Ubuntu 18.04 LTS 的驱动器。
此外,我还挂载了另一个容量为 20 GB 的空驱动器来存储 MongoDB 数据。其大小很大程度上取决于您的使用情况,但对于一个小型系统, 20GB 应该足够了。然而,由于有时很难预测您将存储多少数据,我们将使用 LVM。这将允许您在以后简单地添加另一个驱动器并扩展卷,而无需重新开始。或者,您可以使用单个驱动器,并在以后使用resize2fs。
要添加磁盘,只需转到 ‘Drives’(驱动器)部分,点击顶部的 ‘Create a new drive’(创建新驱动器)图标,为新磁盘命名并将其大小设置为 20 GB。保存后,转到要挂载该磁盘的个人机器,在该机器详情的驱动器部分下,点击 ‘Attach a drive’(挂载驱动器)并选择该磁盘。
现在您有了三台机器,您可以继续将为 MongoDB 数据存储添加的额外磁盘挂载到每台机器上。我建议将此磁盘添加为分区。使用分区允许操作系统分别管理每个区域中的信息。为了将磁盘添加为分区,我将首先检查连接到我们机器的所有磁盘。为此,我将执行以下命令:
|
1 |
fdisk -l |
当我执行该命令时,我得到了说明我机器上的磁盘和设备的输出。
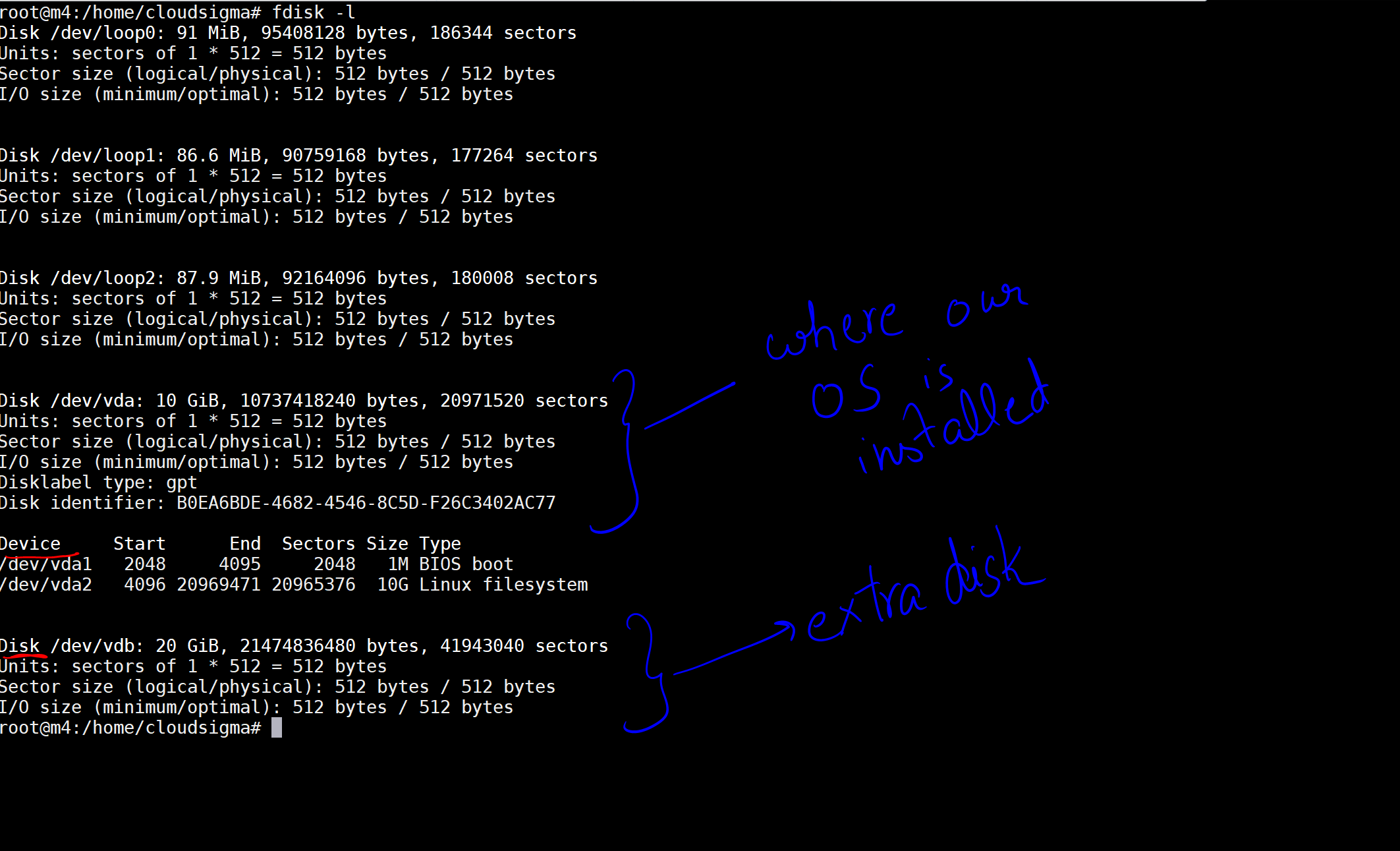
在图中,我已将一个 10 GB 的磁盘标记为安装了操作系统的磁盘。然后是另一个现在已经挂载的 20 GB 磁盘。磁盘位置是 /dev/vdb。您可以使用以下命令在此磁盘上创建分区:
|
1 |
sudo fdisk /dev/vdb |
它将打开 fdisk 工具,这是一个提供磁盘分区功能的命令行工具,您可以在其中在我们的磁盘上创建分区。它会给出提示 “Command (m for help):”,您需要在其中输入 n 以创建一个新分区,然后只需继续按回车键以接受默认值。在创建分区后,输入 w 以写入更改。它看起来像这样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
命令 (m 以获取 帮助): <strong>n</strong> 分区类型 p 主分区 (0 主分区, 0 扩展分区, 4 空闲) e 扩展分区 (容器用于 逻辑分区) 选择 (默认 p): 使用默认 响应 p. 分区编号 (1-4, 默认 1): 第一扇区 (2048-41943039, 默认 2048): 最后扇区, +扇区 或 +大小{K,M,G,T,P} (2048-41943039, 默认 41943039): 已创建 一个 新 分区 1 的类型 'Linux' 和 的大小 20 GiB. 命令 (m 以获取 帮助): <strong>w</strong> 该分区表已被修改. 正在调用ioctl() 以 重新-读取分区表. 正在同步磁盘. |
它已创建了一个类型为 ‘Linux’ 且大小为 20 GiB 的新分区 1。现在分区已创建,让我们创建一个 LVM 池:
|
1 2 3 |
sudo pvcreate /dev/vdb1 sudo vgcreate mongodb /dev/vdb1 sudo lvcreate -n db -L 19.5g mongodb |
我输入了 ‘19.5g’,因为我的分区大小是 20g。接下来,执行以下命令以找出磁盘的名称:
|
1 |
fdisk -l | grep mongo | awk '{print $2'} |
之后,使用以下命令通过 ext4 方法格式化磁盘:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
sudo mkfs.ext4 /dev/mapper/mongodb-db 输出: root@m4:/home/cloudsigma# sudo mkfs.ext4 /dev/mapper/mongodb-db mke2fs 1.44.1 (24-3月-2018) 正在创建 文件系统 使用 5217280 4k 块 和 1305600 inodes 文件系统 UUID: 695a62e6-021d-4fc0-945c-cc51a92d86da 超级块 备份 存储在 于 块: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 正在分配 组 表: 完成 正在写入 inode 表: 完成 正在创建 日志 (32768 块): 完成 正在写入 超级块 和 文件系统 记账 信息: 完成 |
接下来,让我们创建一个用于挂载磁盘的位置,以及一个用于存放 MongoDB 数据的文件夹。
|
1 |
sudo mkdir -p /mongodb/data |
为了在 fstab 中添加关于要挂载的新磁盘的条目,您可以直接使用以下命令:
|
1 |
echo -e "` blkid | grep mongodb | awk {'print $2'}`\t/mongodb\text4 auto,noexec,rw,sync,nouser\t0\t0" >> /etc/fstab |
在该命令中,blkid 会为您提供每个磁盘的 UUID – 通用唯一识别码。在这里,我过滤出了 MongoDB 磁盘的 UUID,并将该 UUID 分别与挂载文件夹的位置、文件系统类型以及磁盘的其他选项结合起来。我正在将这一行添加到 /etc/fstab 中。如果不这样做,您在挂载磁盘时会遇到错误。该条目如下所示:
UUID=”695a62e6-021d-4fc0-945c-cc51a92d86da” /mongodb ext4 auto,noexec,rw,sync,nouser 0 0
现在,您可以将磁盘挂载到 /mongodb 位置:
|
1 |
sudo mount /mongodb |
安装 MongoDB
系统准备就绪后,让我们开始安装 MongoDB。虽然 Ubuntu 在其官方软件源中确实提供了 MongoDB 的版本,但我建议您使用官方的 MongoDB 版本。原因在于 Ubuntu 软件源的版本更新相当滞后,因此如果您想充分利用 MongoDB,就必须求助于官方版本。
由于 MongoDB 提供了自己的软件源,您只需将其添加到系统中,然后像往常一样安装 MongoDB 即可。以下是需要遵循的步骤:
首先,导入包管理系统使用的公钥:
|
1 |
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4 |
然后,我创建一个列表文件。其中将包含 MongoDB 所在的软件源,以便您的系统可以从中下载它:
|
1 |
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list |
现在,我正在更新本地软件包数据库,以便应用这些更改。
|
1 |
sudo apt-get update |
现在,我只需使用以下命令安装该软件包:
|
1 |
sudo apt-get install -y mongodb-org |
我已在每台机器上安装了 MongoDB。
|
1 |
sudo service mongod start |
现在 MongoDB 已经启动并运行,且驱动器上的数据已创建。如果预计会有重负载和/或大量连接,您可能需要提高 ulimit 值。
如果您想更深入地了解您的数据,您可能还想注册 MongoDB 的 MMS,这是一个针对 MongoDB 的免费云端监控服务。
为您的 MongoDB 云创建副本集
现在,让我们创建一个副本集。在此之前,您需要确保每台机器之间可以相互通信。为此,请在 /etc/hosts 中添加这些条目
|
1 2 3 |
IP-1 m1.mongo.cluster m1 IP-2 m2.mongo.cluster m2 IP-3 m3.mongo.cluster m3 |
为了进行验证,您可以尝试使用主机名来 ping 这些机器。因此,如果我的机器 1 的 IP 是 IP-1,例如 213.189.123.12,那么不用写
|
1 |
ping 123.189.123.12 |
我将写成,
|
1 2 3 |
ping m1.mongo.cluster 或 ping m1. |
如果您已启用防火墙(您确实应该这样做),请确保节点可以在内部接口上发送和接收端口 28017 和 27017 的 TCP 流量。
现在,在每台机器上,使用以下命令启动 mongod 服务。
在机器 m1 上,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m1.mongo.cluster |
接下来,在机器 m2 上,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m2.mongo.cluster |
在机器 m3 上,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m3.mongo.cluster |
这里,
mongod 是服务的名称
dbpath 是我们数据库目录的位置
replSet 是我们副本集的名称。对于同一个副本集中的每台机器,它应该都是相同的
bind_ip 是您运行该服务的机器的主机名。
启动 mongod 服务后,转到主服务器(在我的例子中,我选择了 m1),然后运行 mongo。
|
1 |
mongo |
它将启动 MongoDB 终端。在终端上,使用以下命令初始化 replicaSet。它将使用默认配置创建 replicaSet:
|
1 |
rs.initiate() |
现在,让我们使用以下命令将另外两台机器添加为副本:
|
1 2 |
rs.add("m2.mongo.cluster") rs.add("m3.mongo.cluster") |
You can monitor the status using the command:
|
1 |
rs.status() |
就是这样。您现在应该已经在 CloudSigma’s 极速云上启动并运行您的 MongoDB 集群了。
评论
暂无评论。发表第一条评论吧。