

The Elastic Stack(以前称为 ELK Stack)是一个用于集中式日志记录的强大解决方案。它是开源软件的集合,由 Elastic 开发。它允许管理员搜索、分析和可视化从任何来源以任何格式生成的日志。这是一种被称为集中式日志记录的实践。在尝试定位服务器和应用程序的问题时,集中式日志记录非常方便,因为它允许从一个地方搜索所有日志。它还可以通过关联特定时间的日志来帮助识别跨多个服务器的问题。
在本指南中,了解如何在 Ubuntu 18.04 上安装 Elastic Stack。首先,按照我们的教程轻松地 在 CloudSigma 上安装您的 Ubuntu 服务器.
Ubuntu 上的 The Elastic Stack
The Elastic Stack 由以下组件组成:
- Elasticsearch:一个分布式的 RESTful 搜索引擎。它存储所有收集到的数据。
- Logstash: 是 Elastic Stack 的数据处理部分。它将输入的数据发送到 Elasticsearch。
- Kibana: 一个 Web 界面,提供搜索和日志可视化功能。
- Beats: 一个轻量级、单一用途的数据传输器。它可以将数据从多台机器发送到 Logstash 或 Elasticsearch。
您需要手动安装该技术栈的每个组件。
前提条件
在继续安装 the Elastic Stack 之前,必须满足几个系统要求:
- 硬件要求:
- CPU:2 个 CPU(可由非 root sudo 用户访问)
- RAM:4GB
- OpenJDK 11(最新的 Java LTS 版本)。要安装此软件,请查看我们的 关于如何在 Ubuntu 18.04 上设置 Java 的教程.
- 配置正确的 Nginx。您可以按照我们的 在 Ubuntu 18.04 上安装 Nginx 的指南 来进行设置。
请注意,存储量取决于要收集和存储的日志数量。此外,Elastic Stack 还处理有关服务器的重要信息。为了确保数据传输的安全,我们强烈建议配置 TLS/SSL 证书。按照此 教程在您的 Nginx 服务器上获取免费的 SSL 证书.
除了加密服务器之外,以下步骤也是必需的:
- 一个 FQDN(完全限定域名)。在本指南中,它将是 <domain>。
- 以下两个域名的 DNS 记录都指向该服务器。
- 一条将 <domain> 指向服务器公网 IP 的 A 记录。
- 一条将 www.<domain> 指向服务器公网 IP 的 A 记录。
安装 Elastic Stack
-
配置 Elastic 仓库
Elastic Stack 的组件无法直接从官方 Ubuntu 仓库中获取。幸好,Ubuntu 允许使用第 3方仓库来安装软件包。为此,我们将添加 Elastic 软件包仓库。该仓库提供所有 Elastic 软件包的最新更新。所有 Elastic 软件包都使用 Elasticsearch 签名密钥进行签名,以防止软件包被篡改。首先,将密钥添加到 Ubuntu 密钥环中:
|
1 |
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - |
然后,在 “sources.list.d” 目录下添加 Elastic 源列表。这是 APT 用于搜索新源的专用目录:
|
1 |
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list |
最后,更新 APT 缓存:
|
1 |
sudo apt update |
根据官方文档,建议按照本指南中演示的顺序安装每个组件。这可以确保每个产品所依赖的组件都处于正确的位置。
-
安装和配置 Elasticsearch
配置好 Elastic 仓库后,APT 就可以下载并安装所有 Elastic 软件包了。运行以下命令安装 Elasticsearch:
|
1 |
sudo apt install elasticsearch |
现在您可以配置 Elasticsearch。文件“elasticsearch.yml”提供了有关集群、节点、路径、网络、内存、网关等的配置选项。其中大部分已在文件中预先配置。接下来,使用您选择的文本编辑器打开 Elasticsearch 配置文件:
|
1 |
sudo vim /etc/elasticsearch/elasticsearch.yml |
Elasticsearch 默认在任何地方都监听 9200 端口。我们建议限制对 Elasticsearch 的外部访问,以防止外部人员读取数据或使用其 REST API 关闭 Elasticsearch 集群。要限制对 Elasticsearch 的访问并加强其安全性,请取消注释以下行并替换其值:
|
1 |
network.host: localhost |
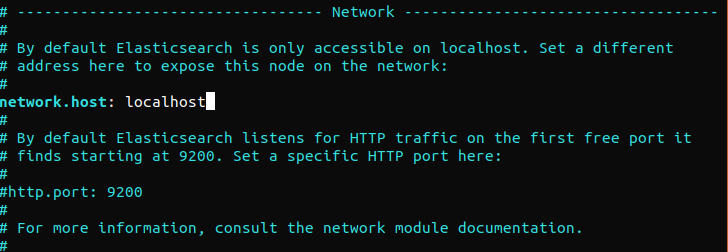
如果 Elasticsearch 要监听特定的 IP 地址,请将“localhost”替换为目标 IP 地址。这是运行 Elasticsearch 之前的最低配置要求。保存并关闭配置文件。接下来,启动 Elasticsearch 服务。启动 Elasticsearch 可能需要片刻时间:
|
1 |
sudo systemctl start elasticsearch |
之后,您需要确保每次服务器启动时 Elasticsearch 都会自动启动:
|
1 |
sudo systemctl enable elasticsearch |
以下命令将验证 Elasticsearch 服务是否正在运行。它只需要发送一个 HTTP 请求:
|
1 |
curl -X GET "localhost:9200" |
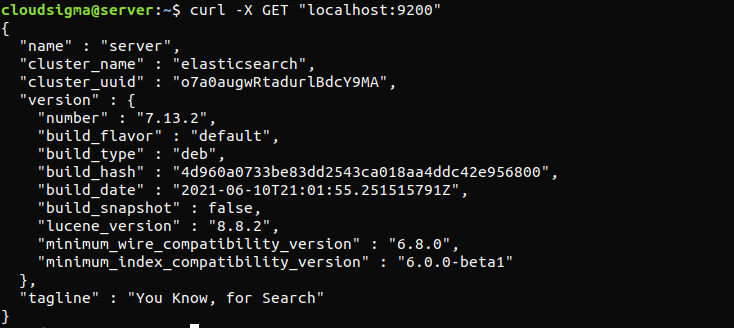
响应看起来会像这样。它将是一个显示有关本地节点的一些基本信息的响应。
安装和配置 Kibana 仪表板
Kibana 可以直接从 Elastic 仓库中获取。请注意,您应该在安装了 Elasticsearch 之后再安装 Kibana。假设仓库已经可用,APT 可以直接获取并安装 Kibana:
|
1 |
sudo apt install kibana |
安装完成后,启用并启动 Kibana 服务:
|
1 2 |
sudo systemctl enable kibana sudo systemctl start kibana |
默认情况下,Kibana 配置为仅监听“localhost”。对于外部访问,它需要配置反向代理。在这里,Nginx 将作为反向代理。使用 openssl 命令创建一个 Kibana 管理员用户。它将是用于访问 Kibana Web 界面的用户帐户。在这里,示例用户名将是“kibana_admin”。为了确保更好的安全性,我们建议使用非标准用户名。以下命令将为 Kibana 创建一个管理员用户。用户名和密码将被生成并存储在“htpasswd.users”文件中。Nginx 必须配置为使用该用户名和密码:
|
1 |
echo "kibana_admin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users |
在提示符下输入并确认密码。此密码对于访问 Kibana 界面非常重要。之后,您需要创建一个 Nginx 服务器块文件。为了演示,它将是 example.com。它也可以是任何其他描述性名称。如果为服务器配置了 FQDN 和 DNS 记录,文件名也可以根据 FQDN 命名:
|
1 |
sudo vim /etc/nginx/sites-available/example.com |
如果存在任何预先存在的内容,请删除这些内容,并将其替换为以下几行代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
server { listen 80; server_name example.com; auth_basic "受限访问"; auth_basic_user_file /etc/nginx/htpasswd.users; location / { proxy_pass http://localhost:5601; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } } |
保存并关闭文件。在“sites-enabled”目录下创建新配置的符号链接。如果已存在同名的链接,则此步骤可能不是必需的:
|
1 |
sudo ln -s /etc/nginx/sites-available/example.com /etc/nginx/sites-enabled/example.com |
以下命令将提示 Nginx 检查是否存在任何语法错误:
|
1 |
sudo nginx -t |
如果存在任何语法问题,请确保文件内容放置正确。接下来,重启 Nginx 服务:
|
1 |
sudo systemctl restart nginx |
告知 UFW 允许连接到 Nginx:
|
1 |
sudo ufw allow 'Nginx Full' |
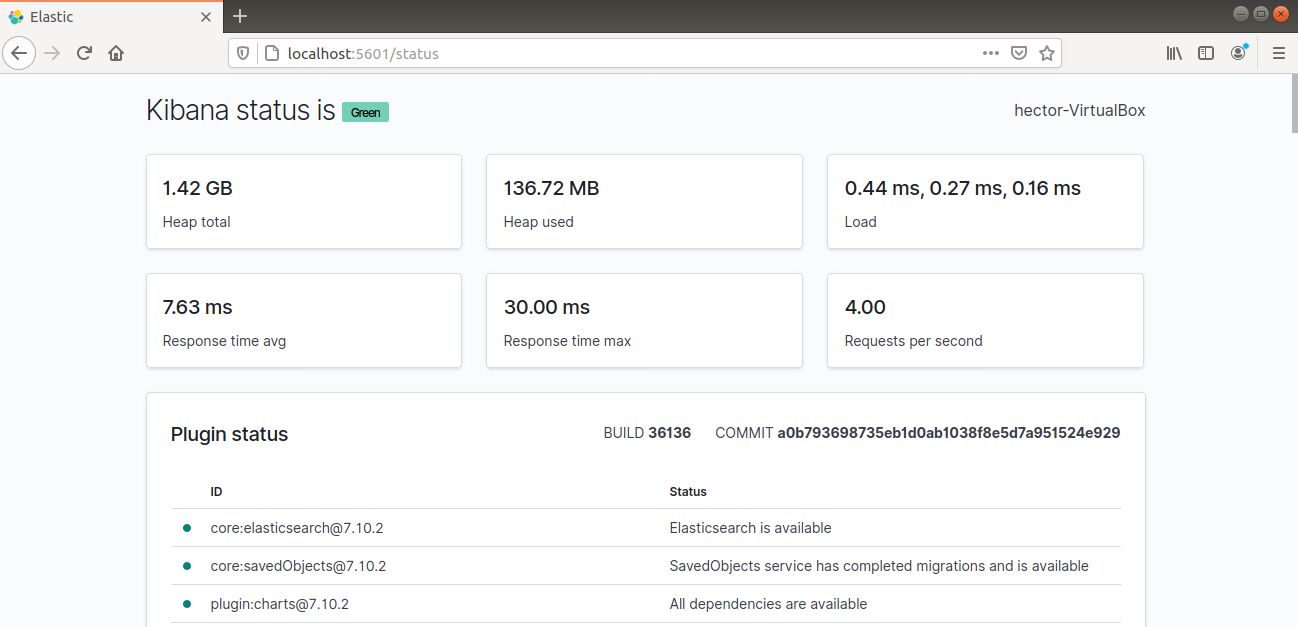
现在应该可以通过 Elastic Stack 服务器的 FQDN 或公网 IP 地址访问 Kibana。检查 Kibana 服务器的状态页面:
|
1 |
http://<server_ip>:5601/status |
安装和配置 Logstash
虽然 Beats 可以直接将数据发送到 Elasticsearch’s 数据库,但建议使用 Logstash 来处理数据。Logstash 可以收集数据并将其转换为通用格式,然后再导出到另一个数据库。运行以下 APT 命令来安装 Logstash:
|
1 |
sudo apt install logstash |
安装完成后,就可以配置 Logstash 了。Logstash 的配置文件为 JSON 格式。您可以在“/etc/logstash/conf.d”目录中找到所有这些文件。将 Logstash 视为一个管道会很有帮助,它在一段接收数据,进行处理,然后发送到目的地。Logstash 管道需要两个必需元素 – input 和 output与一个可选元素 – filter。input 插件接收数据,filter 插件处理数据,而 output 插件将数据写入目的地。以下命令将创建一个配置文件,用于为 Filebeat 输入设置 Logstash:
|
1 |
sudo vim /etc/logstash/conf.d/02-beats-input.conf |
输入以下 input 配置。它描述了一个 beats 输入,它将监听 TCP 端口 5044:
|
1 2 3 4 5 |
input { beats { port => 5044 } } |
下一步是创建一个名为“10-syslog-filter.conf”的配置文件。我们将使用它来为 syslogs (系统日志)设置过滤器:
|
1 |
sudo vim /etc/logstash/conf.d/10-syslog-filter.conf |
输入以下 syslog 配置代码。此代码可直接从 Elastic guide 获取。此代码解释了 Logstash 的 input 配置:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
输入{ beats{ 端口 => 5044 主机 => "0.0.0.0" } } 过滤器 { 如果 [文件集][模块] == "系统" { 如果 [文件集][名称] == "认证" { grok { 匹配 => { "消息" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] } pattern_definitions => { "GREEDYMULTILINE"=> "(.|\n)*" } remove_field => "message" } date { match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } geoip { source => "[system][auth][ssh][ip]" target => "[system][auth][ssh][geoip]" } } else if [fileset][name] == "syslog" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] } pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" } remove_field => "message" } date { match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } } } } |
下一个配置文件将处理输出。打开一个名为“30-elasticsearch-output.conf”的新文件:
|
1 |
sudo vim /etc/logstash/conf.d/30-elasticsearch-output.conf |
输入以下代码。此代码向 Logstash 说明了输出配置:
|
1 2 3 4 5 6 7 |
output { elasticsearch { hosts => ["localhost:9200"] manage_template => false index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" } } |
测试 Logstash 配置。然后,运行以下命令:
|
1 |
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t |
如果没有错误,Logstash 将打印以下成功消息。如果不成功,请确保所有配置文件都包含正确的代码。最后,启动并启用 Logstash 服务:
|
1 2 |
sudo systemctl start logstash sudo systemctl enable logstash |
现在 Logstash 已成功运行并配置完毕,让我们来安装 Filebeat。
安装和配置 Filebeat
Elastic Stack 使用被称为 “Beats” 的数据发送器从各种来源收集数据并将其传输到 Logstash/Elasticsearch。以下是 Elastic 提供的可用 Beats 的简短列表:
- Filebeat:收集/发送日志文件。
- Metricbeat:从系统和服务中收集/发送指标。
- Packetbeat:收集/分析网络数据。
- Winlogbeat:收集 Windows 事件日志。
- Auditbeat:收集 Linux 审计框架数据并监控文件完整性。
- Heartbeat:监控服务的可用性。
在本教程中,我们需要使用 Filebeat 将本地日志发送到 Elastic Stack。首先,安装 Filebeat:
|
1 |
sudo apt install filebeat |
现在您可以配置 Filebeat 了。首先,它需要连接到 Logstash。我们将使用 Filebeat 附带的示例配置。在文本编辑器中打开配置文件。请注意,由于该文件是 YAML 格式,因此正确的缩进非常重要:
|
1 |
sudo vim /etc/filebeat/filebeat.yml |
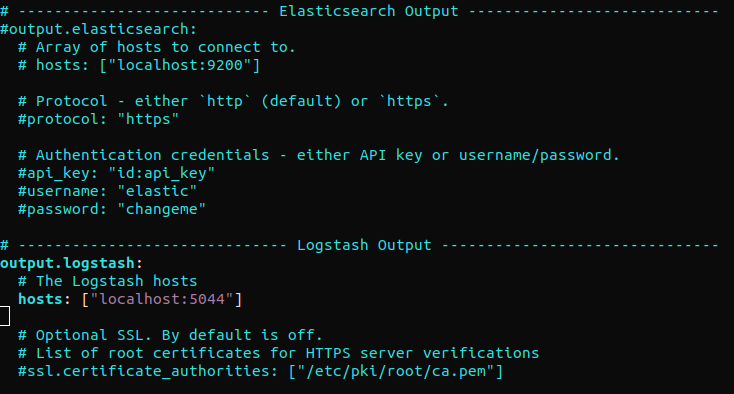
找到 “output.elasticsearch” 部分并注释掉以下行。这将配置 Filebeat 直接将事件发送到 Elasticsearch/Logstash 进行额外处理。接下来,跳转到 “output.logstash” 部分。接下来,取消注释以下行:
|
1 2 3 4 5 6 7 |
#output.elasticsearch: # 要连接的主机数组。 # hosts: ["localhost:9200"] output.logstash: # Logstash 主机 hosts: ["localhost:5044"] |
Filebeat 支持 模块,这些模块可以扩展其功能。在本教程中,我们将使用 系统模块,它收集并解析由常见 Linux 发行版的系统日志服务生成的日志。启用 Filebeat 系统模块:
|
1 |
sudo filebeat modules enable system |
以下 Filebeat 命令将列出所有已启用和已禁用的模块:
|
1 |
sudo filebeat modules list |
默认情况下,Filebeat 设置为遵循 syslog 和授权日志的默认路径。模块的参数可在 “/etc/filebeat/modules.d/system.yml” 配置文件中找到。
下一步是将索引模板加载到 Elasticsearch 中。一个 Elasticsearch 索引 表示具有相似特征的文档集合。每个索引都有一个名称。在其中执行各种操作时,该名称是必需的。每次生成新索引时,都会自动应用索引模板。接下来,加载模板:
|
1 |
sudo filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]' |
默认情况下,Filebeat 包含一个适用于 Kibana 的示例仪表板。它有助于在 Kibana 中可视化 Filebeat 数据。但是,在使用仪表板之前,需要创建索引模式并将仪表板加载到 Kibana 中。在加载仪表板时,Filebeat 会联系 Elasticsearch 以获取版本信息。为了加载仪表板,在启用 Logstash 的同时,需要禁用 Logstash 输出并启用 Elasticsearch 输出。以下命令将完成此操作:
|
1 |
sudo filebeat setup -e -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601 |
最后,您可以启动 Filebeat:
|
1 2 |
sudo systemctl start filebeat sudo systemctl enable filebeat |
现在,是时候测试 Elastic Stack 配置了。如果配置正确,输出将类似于以下内容:
|
1 |
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty' |
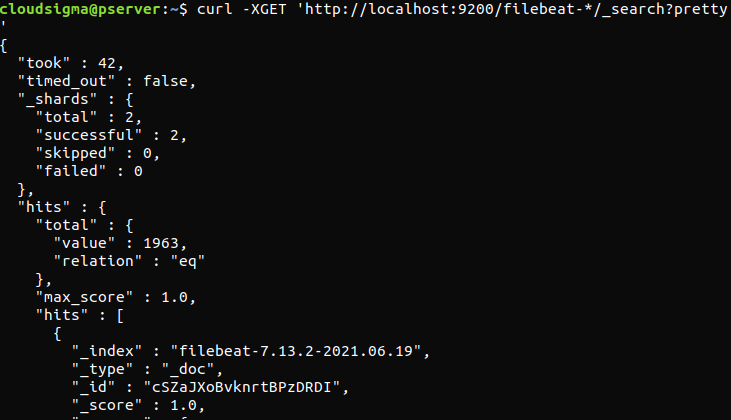
如果输出报告总命中数为 0,则说明 Elasticsearch 没有在我们搜索的索引下加载任何日志。这表明配置存在错误。如果输出符合预期,则说明 Elastic Stack 已成功配置。
Kibana 仪表板概述
现在,是时候探索我们已经安装的 Kibana Web 界面了。首先,打开 Kibana 仪表板。它应该位于 Elastic Stack 服务器的 FQDN 或公网 IP 地址:
|
1 |
http://<server_ip>:5601 |
输入我们之前生成的登录凭据。登录后,仪表板将如下所示:
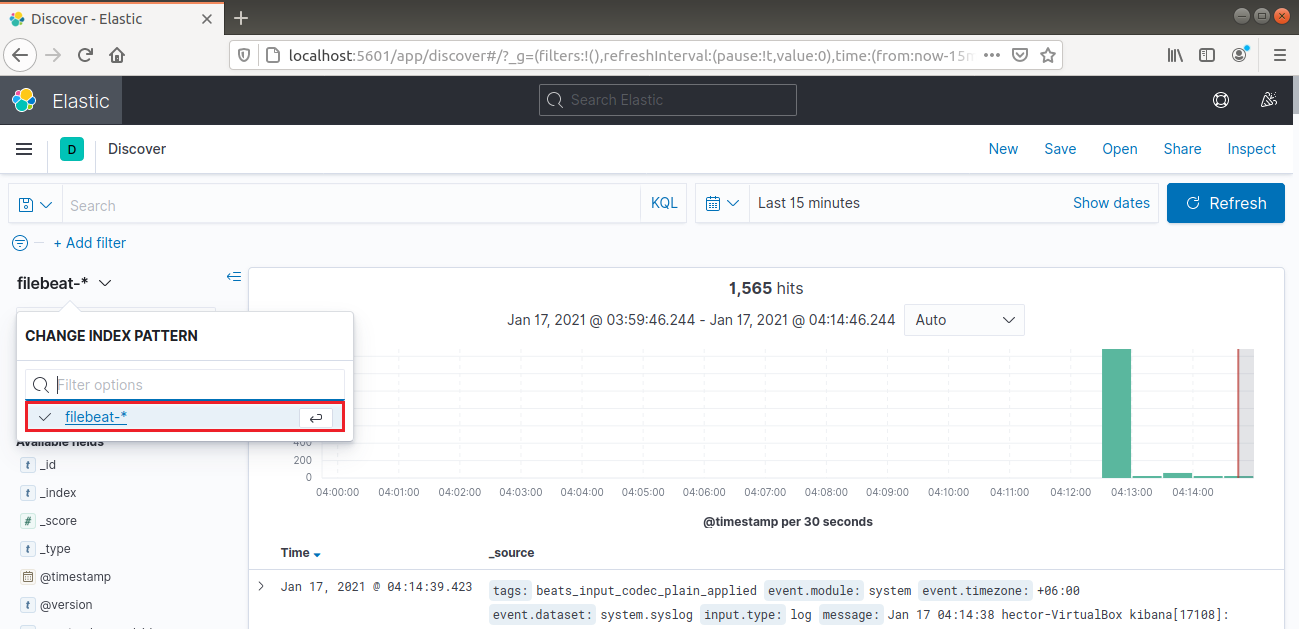
从左侧导航栏中,选择“Discover”。然后,选择“filebeat-*”模式。它会显示过去 15 分钟内收集的所有日志。您可以搜索和浏览日志,并自定义仪表板:
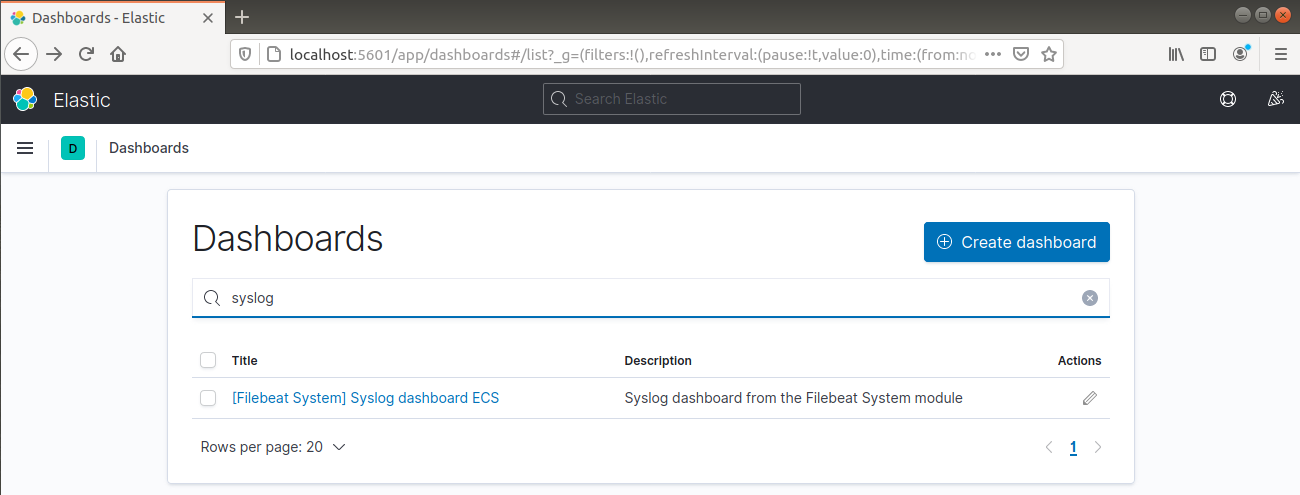
从左侧导航栏中,转到 Dashboard >> Filebeat System。在这里,可以使用来自 Filebeat 系统模块的所有示例仪表板。
在以下示例中,它详细列出了基于 syslog 消息的各种统计信息:
它还可以报告哪些用户使用 sudo 执行了命令:
最后,Kibana 让您有机会探索许多其他功能(例如图表和过滤),请随时自行探索。
结语
Elastic Stack 是用于分析系统日志的强大解决方案。请记住,虽然任何日志或索引数据都可以使用 Beats 发送到 Logstash,但通过 Logstash 过滤器进行解析和结构化后,它会变得更加有用。
祝您使用愉快!
评论
暂无评论。发表第一条评论吧。