

网页抓取、网页爬取、网页收割或网页数据提取都是同义词,指的是从互联网上的网页中挖掘数据的行为。网页抓取工具或网页爬虫是以编程方式浏览网页并提取所需数据的工具。这些数据通常是大量的文本,可用于分析目的、了解产品或满足对某个网页的好奇心。
如果您想知道如何进行网页爬取,我们将通过一个简单的数据集向您展示网页抓取的基础知识。无论您的编程水平如何,您都应该能够跟着本教程进行操作。在实际示例中,我们将使用我们的 CloudSigma 博客。我们将尝试获取我们博客页面上教程的信息。当您读到本教程的结论时,您将拥有一个使用 Python 3 制作的、可以运行的网页抓取工具,它会爬取我们博客板块的几个页面,然后在您的屏幕上显示数据。
利用创建这个基础网页抓取工具所学到的知识,您可以对其进行扩展并创建自己的网页抓取工具。这应该会很有趣,让我们开始吧!
前提条件
这是一个动手实践教程,因此您应该拥有一个本地的 Python 3 开发环境以便顺利跟进。首先,您可以参考我们的教程,了解如何 在 Ubuntu 上安装 Python 3 并设置本地编程环境.
Scrapy
网页抓取涉及两个步骤:第一步是寻找并下载网页,第二步是爬取这些网页并从中提取信息。
在许多编程语言中,有许多方法和库可以用来从头开始构建网页抓取工具。然而,当您的网页抓取工具变得复杂,或者当您需要同时爬取具有不同设置和模式的多个页面时,这在未来可能会带来问题。弄清楚如何在 CSV、XML 或 JSON 等不同格式之间转换抓取的数据可能是一项相当繁重的任务。
虽然有些人可能会喜欢从头开始构建自己的网页抓取工具的挑战,但最好不要重复造轮子,而是将其构建在处理所有这些问题的现有库之上。我们将使用 Scrapy,一个 Python 库,以及 Python 3 来实现本教程中的网页抓取工具。Scrapy 是一个开源工具,也是最流行、最强大的 Python 网页抓取库之一。Scrapy 旨在处理所有抓取工具都应该具备的一些常用功能。这样,每当您想实现网页爬虫时,就无需重复造轮子。使用 Scrapy,构建抓取工具的过程变得简单而有趣。
Scrapy 可以从 PyPi(通常称为 pip,即 Python 包索引)获取。PyPi 是一个社区拥有的仓库,托管了大多数 Python 包。当您在本地开发环境中安装和设置 Python 3 时,它也会安装 pip,您可以使用它来安装 Python 包。
步骤 1:如何构建一个简单的网页抓取工具
首先,要安装 Scrapy,请运行以下命令:
|
1 |
pip install scrapy |
或者,您可以按照 Scrapy 官方安装说明 进行操作。如果您已成功安装 Scrapy,请使用您选择的名称为项目创建一个文件夹:
|
1 |
mkdir cloudsigma-crawler |
进入该文件夹并为代码创建主文件。该文件将保存本教程的所有代码:
|
1 |
touch main.py |
如果您愿意,可以使用文本编辑器或 IDE 代替上述命令来创建文件。
接下来,打开文件,让我们开始创建一个使用 Scrapy 的基础抓取工具。我们将创建一个继承自 scrapy.Spider(Scrapy 的一个基础爬虫类)的 Python 类。该类将具有如下定义的两个必需属性:
- name — 用于标识爬虫的字符串名称(您可以输入自己选择的名称)。
- start_urls — 包含要爬取的 URL 列表的数组。我们将从一个 URL 开始。
在打开的文件中添加以下代码片段以创建基础爬虫:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
以下是每行代码的解释:
第一行导入了 Scrapy,使我们能够使用该包提供的各种类。
在下一行中,我们继承了 Scrapy 提供的 Spider 类,并创建了一个名为 CloudSigmaCrawler 的子类。通过继承一个类(Spider),我们可以访问该类的属性,并现在可以在我们的代码中使用它们。在这种情况下,Spider 类具有定义如何跟踪 URL 以及如何从网页中提取数据的方法和行为。然而,它不知道要跟踪哪些 URL 或要提取什么数据。通过继承它,我们可以向这些方法提供所需的信息。要了解更多关于子类化和继承的信息,请继续阅读 面向对象编程原则.
在我们的 CloudSigmaCrawler 中,我们定义了所需的属性。首先,我们将爬虫命名为 cloudsigma_crawler。然后,我们提供一个起始 URL:https://blog.cloudsigma.com/blog/。打开此 URL 将带您进入 CloudSigma 博客的第 1 页,其中包含许多教程中的一部分。
是时候测试爬虫了。您有几种选择。例如,如果您使用的是 IDE,比如 PyCharm 社区版 来自 JetBrains,它可能带有一个只需点击即可运行脚本的按钮。另一个选择是按照从命令行运行 Python 文件的典型方式:python path/to/file.py,或 py path/to/file.py。另一个选择是 Scrapy 的命令行 接口。Scrapy 自带命令行接口,以帮助启动爬虫。输入以下命令启动爬虫:
|
1 |
scrapy runspider main.py |
根据您安装的 Scrapy 库版本,您应该会看到类似以下的输出:
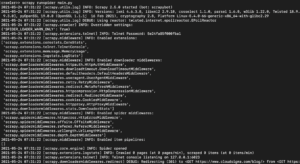
如您所见,输出非常长,因此我们只挑选了部分内容。以下是您执行该命令时发生的情况:
- 爬虫已初始化。因此,它加载了在跟踪和读取 URL 数据时需要使用的其他组件和扩展。
- 通过使用 start_urls 列表中提供的 URL,它抓取了页面中的 HTML。这与浏览器在打开网页时遵循的过程类似。
- 抓取 HTML 后,它会被传递给 parse 方法,但我们尚未定义该方法。目前它什么也不做,因此爬虫直接退出而不进行任何处理。我们将在下一步中定义 parse 方法的行为。
步骤 2:如何从页面中提取数据
在步骤 1 中,我们仅实现了一个基础爬虫,它抓取 HTML 页面但之后什么也不做。在本节中,我们将提供提取数据的说明。在我们要从中提取数据的 CloudSigma 博客 页面上,您可以注意到一些事项,例如:
- 存在于所有页面上的页眉。
- 导航菜单和搜索过滤框。
- 网格格式的实际教程列表。
查看您打算抓取的 HTML 页面的源代码可以让您对页面的结构有一个大致的了解。这有助于您编写爬虫。您可以通过右键单击页面并选择“查看源代码”,或按 Ctrl + U 来查看源代码。以下是源代码的一个片段:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="指向以下内容的永久链接:"在 Ubuntu 18.04 上使用 Let’s Encrypt 保护 Apache 安全"">保护 Ubuntu 18.04 上使用 Let’s Encrypt 的 Apache</a> </h2> </header> <div class="entry-content excerpt"> <p>网站和数据安全是不能轻视的话题。高度敏感的信息(包括 财务记录和客户的私人信息)始终在 用户计算机和您的网站之间传输。考虑到这一事实,不难看出为什么未受保护的 网站可能会导致安全漏洞,从而严重损害您的业务。有许多 … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">阅读更多</a></div> </div> </div> ... </article> </div> </body> |
如您所见,每个博客教程都包含在名为 <article> 的 HTML 标签中。抓取该页面将涉及两个步骤。第一步是通过查看包含我们所需数据的页面部分来获取每个博客教程。下一步是从 HTML 标签识别的每个教程中提取我们所需的数据。
Scrapy 根据您提供的选择器来识别要抓取的数据。我们可以使用选择器来查找页面上的一个或多个元素,并获取这些元素中的数据。Scrapy 支持 XPath 和 CSS 选择器。
从我们之前查看的源代码来看,CSS 选择器似乎更容易。因此,我们将选择这个选项,因为它将帮助我们找到页面上的所有教程。在 HTML 源代码中,每个教程都在名为 post 的 CSS 类中指定。CSS 类名通常用 .class_name(点 类名)来标识。因此,我们将使用 .post 作为我们的 CSS 选择器。在我们的 main.py 爬虫源代码中,我们将把 .post 类传递给 response 对象,这样您的文件现在看起来就像这样:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
此代码片段将抓取具有指定 start_urls 的页面上的所有教程,并循环遍历这些教程以提取数据。在下一步中,您将需要提取并显示这些数据。如果您再次查看 CloudSigma 博客 的源代码,您会发现每个教程的标题都存储在 <h2> 标签内的 <a> 标签中,例如:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
我们正在循环遍历的每个教程对象都包含一个 CSS 方法,我们可以传入一个选择器来定位和提取子元素。在此示例中,我们想要提取包含在 <a> 标签内的标题。该标签位于 .entry-wrap 类内部的 .entry-header 类内部的 <h2> 标签内。我们可以将这些 CSS 选择器传递给对象方法以提取标题,将代码修改为如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
extract_first() 后面的逗号并不是拼写错误,因为我们稍后会在该部分下方添加更多代码。
上述源代码中需要注意的一些要点包括:
- 附加到选择器的 ::text – 这是一个 CSS 伪选择器,它指示代码获取标签内的文本,而不是标签本身。
- 对象中的 extract_first() 方法调用 – 指示代码仅选择与选择器匹配的第一个元素。因此,我们得到的是一个字符串,而不是元素列表。
接下来,保存文件并通过在终端中输入以下命令来运行代码:
|
1 |
scrapy runspider main.py |
在输出中,您应该会看到教程的标题:
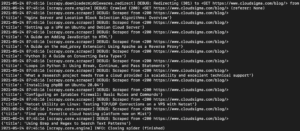
我们可以通过添加更多选择器来继续扩展此内容,以获取有关教程的其他详细信息,例如教程的 URL、特色图片和说明。
让我们再次检查单个教程的 HTML 代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="永久链接至:"Securing Apache with Let’s Encrypt on Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">保护 Ubuntu 18.04 上使用 Let’s Encrypt 的 Apache</a> </h2> </header> <div class="entry-content excerpt"> <p>网站和数据安全是不能轻视的话题。高度敏感的信息,包括 财务记录和客户的隐私信息,一直在 用户的计算机和您的网站之间传输。考虑到这一事实,不难看出为什么未受保护的 网站可能会导致安全漏洞,从而严重损害您的业务。有许多 … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">阅读更多</a></div> </div> </div> </article> </div> </body> |
我们想要尝试提取突出显示的部分,即教程的 URL、特色图片和说明文字。
- 从上面的代码片段中,博客的图片存储在博客教程开头的 div 标签内的 <a> 标签内的 img 标签的 data-lazy-src 属性中。我们可以像处理教程标题那样,使用 CSS 选择器来获取该值。
- 获取教程的 URL 非常简单,因为我们在 <div> 元素内有 <a> 标签。
- 说明文字包含在 <div> 标签内的 <p> 标签中。
我们将使用 CSS 类来获取我们想要的内容。让我们修改代码,使其看起来像这样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
保存更改并使用以下命令运行代码:
|
1 |
scrapy runspider main.py |
您将在输出中看到更多数据,例如我们添加的 URL、图像和说明文字:

抓取单个页面的内容就这些了。接下来,让我们看看如何创建一个能够跟踪链接的爬虫。
步骤 3:如何抓取多个页面
到目前为止,我们已经创建了一个可以从单个页面获取数据的爬虫。然而,我们的目标不止于此。您需要一个能够自动跟踪链接并从网站的多个页面中提取数据的爬虫。
如果您转到 CloudSigma 博客页面的底部,您会注意到分页链接,以及一个指向右侧表示下一页的小箭头。以下是 HTML 代码片段:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">第 1 页,共 45 页</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="最后一页">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
该片段显示了在具有 .x-pagination CSS 类的 <div> 标签下,<li> 标签内的几个页面导航链接。我们的重点是指向下一页的链接。它位于 <ul> 标签中最后一个 <li> 的 <a> 标签中。
如上面的片段所示,指向下一页的链接在 <a> 标签内具有 .prev-next 类。但是,如果您转到下一页,您还会注意到指向上一页和下一页的链接都具有此 CSS 类。请看第 2 页的这个片段:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">第 2 页,共 45 页</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="最后一页">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
如果我们使用 Scrapy 的 extract_first() 方法,它将在第一页上起作用。当它到达下一页时,它将选择带有 .prev-next 类的第一个链接,在上面的代码片段中,该链接指向第一页。这将导致循环。因此,我们将使用 Scrapy 的 extract() 方法。此方法提取与用例匹配的所有元素并将其放入数组中。从该数组中,我们可以选择最后一个元素,该元素将包含指向下一页的实际链接。修改您的代码,如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
让我们逐步分析 next_page 选择的代码。
我们首先为下一页和上一页的链接定义一个选择器。然后,我们使用 extract() 方法提取 URL 并将它们放入一个数组中。next_page 变量将是一个包含两个元素的数组,如下所示:
|
1 |
next_page = [prev_page_url, next_page_url] |
由于我们要导航到下一页,我们将选择数组中的最后一个元素。Next_page[-1] 会选择数组中的最后一个元素。
if 块会检查 next_page 变量是否包含内容,然后调用 scrapy.Request() 方法。在我们的代码中,我们指示该方法抓取提供 URL 的页面,并将其传回 parse() 方法,以便我们可以对其进行解析以提取数据,并对下一页重复该过程。重复此过程,直到找不到下一页的链接,或者如果该块失败,它就会停止。
保存代码并运行它。你会注意到,随着找到更多要抓取的页面,迭代会继续循环遍历这些页面。这就是你定义一个跟踪网站链接的爬虫的方法。我们的示例非常简单。我们只是访问一个页面,找到下一页的链接,然后重复该过程。在其他使用场景中,你可能希望跟踪指向外部源等的标签或链接。以下是 Python 3 基础网页爬虫的完整源代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
结论
在本教程中,我们构建了一个基础的网络爬虫,可以爬取 CloudSigma 博客 目录,并仅用大约 27 行代码展示有关博客教程的一些信息。
当然,这之所以能够实现,是因为我们是基于 Scrapy Python 库构建的。这只是一个基础,可以帮助您构建更复杂的爬虫,以跟踪更多标签、网站搜索结果等。您可以查看 Scrapy 官方文档 以获取有关使用 Scrapy 的更多信息。
祝您计算愉快!
评论
暂无评论。发表第一条评论吧。