

The grep command is a powerful utility to search for patterns in text. It comes pre-installed in any Linux distro. Here is our tutorial that goes over setting up the LAMP Stack -Linux, Apache, MySQL, and PHP.
The name grep stands for global regular expression print. The tool searches for the specified pattern in the input. In principle, it sounds trivial. However, its true power lies within how you define the pattern. This guide elaborates on how to use grep with regular expression to perform complex searches. Let’s begin!
How to Use Grep
The grep command, by itself, isn’t complicated. All it requires is the pattern and the content to perform the search on. This is what the base structure of the grep command looks like:
|
1 |
grep <regex> <file> |
Searching text
First, grab a sample file to perform the action on. Download the GNU General Public License v3.0 (in text format). It’s quite a big text file with lots of words and phrases. If you are using Ubuntu you can find it in the file below. Follow our tutorial for a quick and easy Ubuntu installation.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

Next, you can perform a basic text search using grep:
|
1 |
grep <pattern> <text_file> |
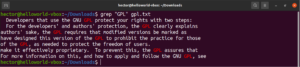
It’s possible to pipe the output of a command to grep:
|
1 |
cat gpl.txt | grep <pattern> |
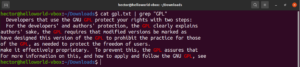
Case sensitivity
By default, grep behaves as case-sensitive. In many situations, ignoring case sensitivity may be optimal. To disable case-sensitive search, use the “-i” or “–ignore-case” flag:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
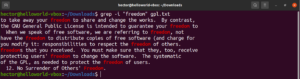
Invert finding
By default, the grep behavior is to print the lines where the pattern was found. Invert match refers to the phenomenon when you don’t want to see the lines that match the pattern. In order to invert match, you need to use the “-v” or “–invert-match” flag:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
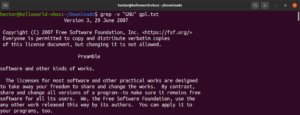
Line number
When running grep on a very large file, it’s hard to keep track of the location of the search result. To make things easier, grep has the feature to show the line number. To enable line numbering, use the “-n” or “–line-number” flag:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
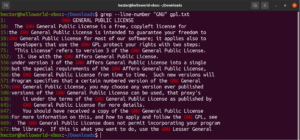
It’s possible to combine multiple grep arguments. The following grep command will perform an invert match while printing the line numbers:
|
1 |
grep -nv <pattern> <file> |
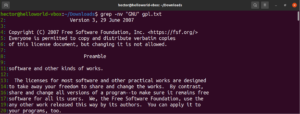
Regular expression
At the start of this guide, we mentioned that grep stands for global regular expression print. The term “regular expression” is defined as a special string that describes the searching pattern. Regular expression has its own structure and rules.
There are numerous string-searching algorithms and tools that use regular expression (regex for short) for performing searches and replacing actions. While it’s popular, different applications and programming languages implement regex slightly differently. In this section, we will showcase a handful of regex methods using grep.
Literal match
In the previous grep examples, grep performed the search for a specific string in the given text file. Grep was actually searching using the very basic regular expression. The regex patterns that define the search for the exact match of a given string are called “literals.” The name comes from the fact that they match the pattern literally, character by character.
The literal match works with alphabetic and numerical characters (as well as some special characters). However, depending on other expression mechanisms, this behavior may change:
|
1 |
grep "<string>" <file> |
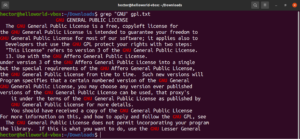
Anchor match
Anchors are special characters that define where the position of the match should be in the line in order to have a valid match. Here’s a quick example to simplify it. If we’re looking to find only the lines that start with the string “GNU,” then the grep with regex will look like this. Here, the character “^” is the anchor, defining that matches at the beginning of the line are the only valid ones:
|
1 |
grep -n "^GNU" <file> |

Similarly, if we’re looking to find only the lines that end with the string “works,” then the grep with regex will look like this. Here, the character “$” is the anchor, defining that only matches at the end of the line are valid:
|
1 |
grep -n "and$" <file> |
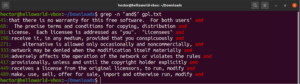
Any character match
When performing a text search, you may want to define that at a specific place, there can be any character. In regex, this is expressed by the period character (.).
Have a look at this example. In the GNU GPL 3 text file, the words “accept” and “except” both have the portion “cept” in common. Moreover, both words have two characters before the “cept” portion. The following grep command will match with any word that has two characters before the “cept” portion:
|
1 |
grep -n "..cept" <file> |
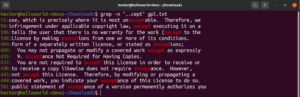
According to this regex, other words like suscept, unaccept, unexpected, etc. are also valid matches.
Brackets
In regex, bracket expressions define that at the specified location, there can be any character declared within the bracket. Have a look at the following regular expression string:
|
1 |
t[wo]o |
When putting it in action, the words too and two will be the valid matches:
|
1 |
grep -n "t[wo]o" <file> |
The bracket expression opens up the possibility for some interesting things. It’s possible to use bracket expressions to tell that at the specified location, there can be any character other than the ones declared within the bracket. Have a look at the following regex string. The match will only be valid if there’s any character other than “c” before “ode”:
|
1 |
"[^c]ode" |
Run it on the GPL-3 license text file:
|
1 |
grep -n "[^c]ode" <file> |

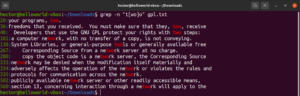
Besides the result from the file, other valid results would be node, abode, anode, etc. Bracket expressions can also describe a range of characters. The following regex tells that the match is valid if the starting of the line is an uppercase character:
|
1 |
"^[A-Z]" |
Run it on the GPL-3 license text file. It will be all the lines in the text file:
|
1 |
grep -n "^[A-Z]" <file> |
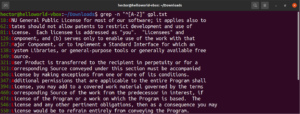
For ease of use, there are certain character classes that have specified labels. In the prior example, we used the range “A-Z” to define the uppercase characters. Instead, we can also use “[:upper:]”. The result will be the same:
|
1 |
grep -n "^[[:upper:]]" <file> |
Repeating a pattern
In certain situations, you may want to match a specific pattern or regex zero or more times. To do so, the meta-character is the asterisk (*). The following regular expression will match all the parentheses with only alphabets and single spaces between them. Note that the declaration of the lowercase, uppercase character sets and spaces are together without any punctuation:
|
1 |
"([a-zA-Z ]*)" |
Put the regex into action with grep:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

Using meta-characters as literal characters
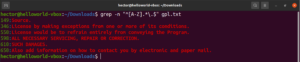
So far, we’ve been introduced to various meta-characters like the asterisk (*), period (.), anchors (^ and $), etc. Each of them denotes a unique function in the regex context. The problem arises when they need to be used as literals, not meta-characters. In such situations, backslash (\) in front of the meta-character will denote that it’s to be used in literal sense, not as a meta-character. Have a look at this regex example. It will match all the lines that start with an uppercase character and end with a period:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
Alternation
Using bracket expressions, we can specify different possible choices for a single character match. Regex has the feature to do the same with words and phrases. To indicate an alternation, the pipe character (|) is used. The options remain within parentheses while the pipe character separates them from one another. There can be two or more possible options for the match to be valid. Take a look at the following regex example. It’ll match both “GPL” and “General Public License”:
|
1 |
grep -nE "(GPL|General Public License)" <file> |

Quantifiers
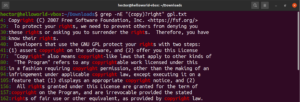
Using the asterisk (*) meta-character, we were able to define a pattern repeatedly zero or more times. However, there is more to work with. It’s easier to explain the quantifiers with an example. The following regular expression describes that both “copyright” and “right” are valid matches. The question mark (?) signifies the “copy” portion optional to match:
|
1 |
grep -nE "(copy)?right" <file> |
The next quantifier is the addition symbol (+). It behaves similarly to the asterisk. However, the defined pattern must match at least once. In the following example, the regular expression will match “soft” with one or more non-white characters:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
Specify match repetition
It’s possible to specify the number of times a match is repeated. To do so, use the curly braces ({}). The following regular expression will match any word that contains a minimum of three vowels:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

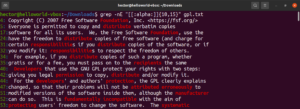
This feature also allows you to define the lower limit and upper limit of the length of the match. In the following example, the regex will match with any word that’s 10-15 characters long:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
Conclusion
Searching text files with grep is quite handy. Regular expressions make searching with grep more interesting and useful. They also fine-tune the searching pattern to your heart’s desire.
While we’ve demonstrated some of the common regular expressions, it’s just the beginning. There are more advanced regular expressions that offer the finest control over the search behavior. Besides grep, regular expressions are also widely used by other tools and programming languages.
Happy computing!
- Removing Spaces in Python - March 24, 2023
- Is Kubernetes Right for Me? Choosing the Best Deployment Platform for your Business - March 10, 2023
- Cloud Provider of tomorrow - March 6, 2023
- SOLID: The First 5 Principles of Object-Oriented Design? - March 3, 2023
- Setting Up CSS and HTML for Your Website: A Tutorial - October 28, 2022