

Introduction
Database management tools are mostly used by the relational data model. This model organizes data into tables consisting of columns and rows. While this model remains dominant in terms of storing and managing worldwide data, there are other data models such as NoSQL and NewSQL out there.
In this tutorial we will delve into three of the most widely implemented models, all of them open-source RDBMSs. They include SQLite, MySQL, and PostgreSQL. We will explore the data types used by each RDBMS. We will also elaborate on their benefits and shortcomings, as well as how we can optimize them in the best way.
Database Management Systems Overview
Databases are packs of data modeled by logic, while a database management system (DBMS) is a computer program that interacts with these databases. А DBMS permits writing data, running queries, controlling access to, and handling other database management-related tasks. Although the terms databases and database management systems are used interchangeably, they do not actually mean the same thing. A database is a collection of data and can come from multiple sources, not just stored locally on a computer. A DBMS is software that allows interaction with the database.
Every DBMS has a structure model that dictates how to store and access data. An RDBMS (relational database management system) utilizes a relational data model in which data is broken down into tables. In the RDBMS context, they are termed relations. This relation consists of a set of tuples (table rows) with each tuple sharing an attribute set (columns) with other rows in the table.
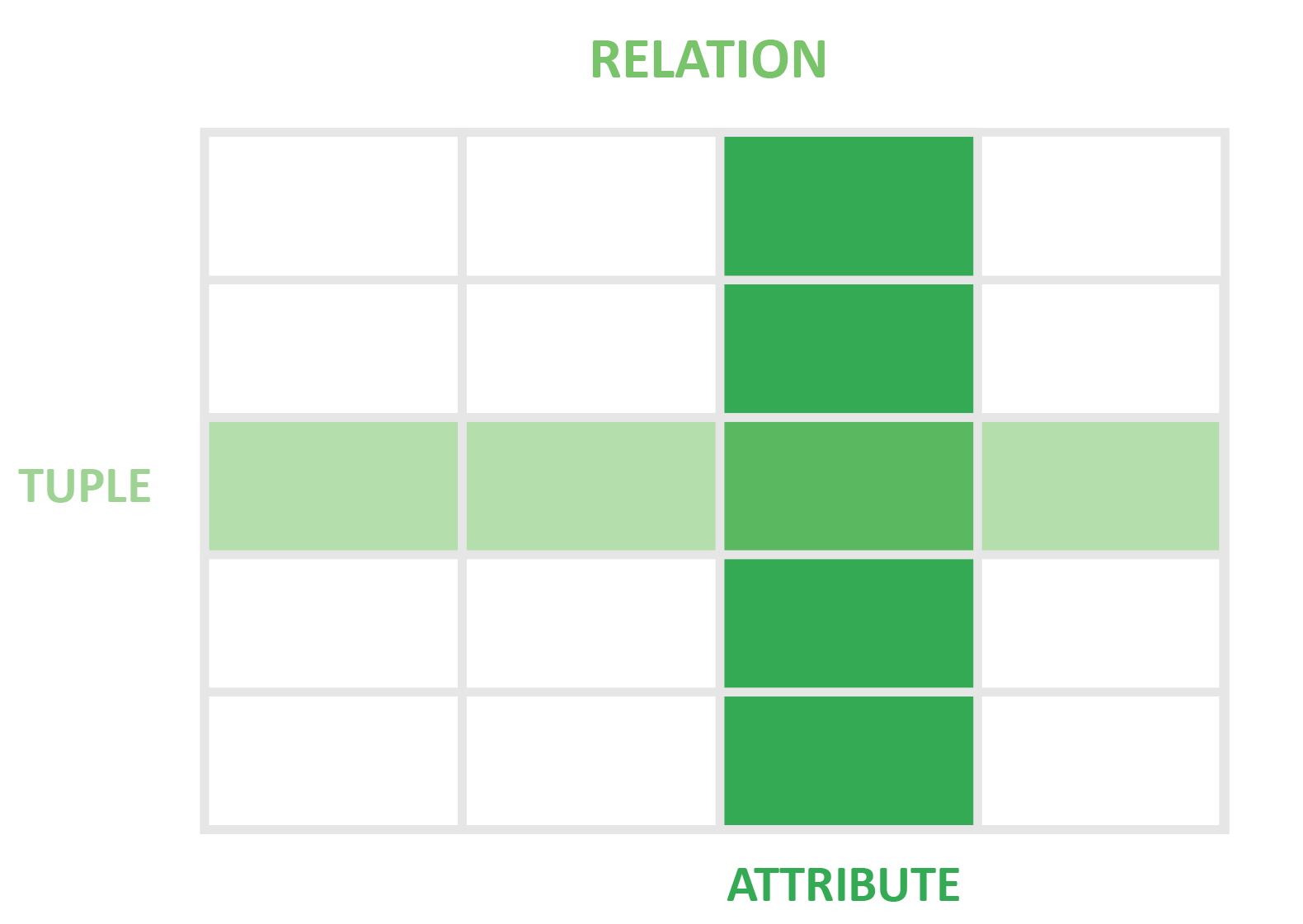
Structured Query Language (SQL) manages and queries data in most relational databases, but each RDBMS uses its own SQL ‘dialect’. These unique ‘versions’ of the same query languages may have a set of their own unique extensions, as well as limitations. The extensions tend to be in the form of additional features that allow for the performance of a more complex operation by users than those that can be accomplished through standard SQL.
Keep in mind that the SQL standards are maintained by ANSI (American National Standards Institute), ISO (International Organization for Standardization), and the IEC (International Electrotechnical Commission). These organizations collectively determine what the term “standard SQL” (a term that will appear multiple times in this guide) means. These standards are vast and complex, with the full core SQL:2011 compliance requiring 179 features. For this reason, a large number of RDBMS do not support the entire SQL standard. Some tend to be more compliant with the ‘standard’ than others.
Every column will allow particular types of entries as designated but the columns’ assigned data types, while different types are implemented in different RDBMS. Therefore, they are not typically interchangeable. For instance, some of the more common types of data are strings, integers, dates, and Booleans.
Numeric types can be either signed or unsigned. Signed data types represent both positive and negative numbers. An unsigned data type is limited to just representing positive numbers. For instance, MySQL’s tinyint data type can hold 8 bits of data, which means it can potentially be 256 possible values. In that sense, the signed set ranges from -128 to 127, with the unsigned range supporting 0 to 255.
There are times when the database administrator will constrain a table in order to limit the values that can be entered into it. While this type of constraint is typically involving just one column, the constraints can sometimes be table-wide. A few known constraints on a table used in SQL include:
- UNIQUE: This constraint assures that every entry in the column is unique, with no two entries being identical.
- NOT NULL: This constraint mandates that none of the column entries can have a null value.
- PRIMARY KEY: This is a combination of the UNIQUE and NOT NULL values with this constraint deeming that the column’s entries can neither be NULL nor redundant of any other values in the column.
- FOREIGN KEY: This refers to a column from one table that refers to the PRIMARY KEY from another table. This links two tables, with the condition of the FOREIGN KEY column already being a PRIMARY KEY column that exists in the related table.
- CHECK: This constraint limits the value range that can be entered into the column. If your application is intended to only be used by California residents, a CHECK constraint could check the ZIP code column to only permit entries in the range of those designated just for the zip codes in the California range.
After our overview of the relational database management systems overall, we can move on to a breakdown of the three open-source relational databases: SQLite, MySQL, and PostgreSQL.
SQLite Breakdown
SQLite is an open-source, file-based, RDBMS that is self-contained. It is popular for its adaptability and reliable performance in low-memory environments, as well as its portability. It utilizes transactions that are compliant with ACID standards, even when the system either crashes or experiences a power outage.
SQLite is described as a ‘serverless’ database according to the project’s website. Traditional relational databases have server-based processes that entail a communication of programs with the host server through relayed requests via inter-process communication. However, with SQLite, any process that interacts with the database reads from it or writes directly to the disk file. As this eliminates any need to configure a server process, SQLite’s setup process is much more simple than the traditional relational database model. Programs using SQLite will also not require any additional setup, as they just need to operate its access to the disk.
SQLite requires no special licensing to use as it is open-source and free. The project does offer some paid extensions, with a one-time fee for each. These assist in data encryption and compressions. There are also a set of commercial support packages that you can purchase for an annual fee.
Data Types SQLite Supports
SQLite supports an array of data types. They come into storage classes as follows:

Within the SQLite context, “storage class” and “data type” mean the same thing. Check out SQLite’s official documentation on the subject to learn more about SQLite’s data types and type affinity.
SQLite Advantages
- Small footprint: Because SQLite is self-contained, it does not require any external components that require installation on your system in order to function. The use of space SQLite (as the name would imply) is minimal. While it depends somewhat on the system, it generally takes up less than 600KB of space.
- User-friendly: Sometimes dubbed a “zero-configuration” database, SQLite essentially comes ready to use at install time. Because SQLite does not run on the server-side, it never needs to be started, restarted, or stopped. There are also no configuration files you need to manage it. This makes SQLite easy to install and integrate with an application very quickly.
- Portability: The entire SQLite database is in a single file. By contrast other database management systems typically store data in large batches of separate files. The location of the single SQLite is free to be anywhere in the directory hierarchy and it is shareable through transfer protocol and removable media.
SQLite Disadvantages
- Concurrency limitation: The SQLite database is accessible by multiple processes at once. However, only one edit to the database can happen at a time. While SQLite does support more significant concurrency than other embedded database management systems, it does not have the same versatility as MySQL, PostgreSQL, or other client/server RDBMSs.
- Lack of user management: The only access permissions applicable to SQLite are those typical to underlying operating systems. Therefore, SQLite is not the ideal choice for applications that require a variety of users with their own specific access permissions. This is not the case for many other database systems. Most of them offer particular access privileges to the tables and databases.
- Lower security: Bugs in the applications take much less of a toll on a database engine utilizing a server, as it is harder to corrupt the server side in terms of data integrity concerns. A client-server system has better-governed access, concurrency, and detailed locking than that present (if at all) in a serverless database management system.
SQLite: Suitable for Use
- Dealing with embedded applications: If applications do not need future expansion and benefit from, or demand portability, SQLite is a good choice for a database management system. Some examples of such systems include mobile games and single-user local apps.
- Reading and writing to disk: When an application is heavy on direct reads from and writes to a disk, SQLite could be more beneficial thanks to its simplicity of use and additional functionality.
- Tester friendly: Testing certain applications with a DBMS that requires server processing overhead may be overkill. SQLite’s in-memory model is an ideal choice for testing. That is because there is no need to sling commands back and forth with a server.
SQLite: Not Suitable for Use
- Heavy data: While SQLite can technically support up to a 140TB database (assuming the filesystem and disk drives also support that size), its website recommends that databases sized 1TB and beyond be housed in a central client-server, as databases that large can be very challenging to manage.
- Heavy write volumes: As SQLite is limited to one write operation at a time, the throughput is very limited. If an application requires a lot of disk writing, the process will not be speedy. Therefore, it may not be adequate for application needs.
- Required network access: As a serverless database, SQLite does not provide direct network access to its data. The access is built-in on the application side. That means that if the application and the SQLite database are on separate machines, the engine will need high bandwidth to desk linking across the network. In that case, using SQLite turns out to be an inefficient and costly solution, with DBMS being a better choice.
MySQL Breakdown
Since the DB-Engines Ranking site began tracking database popularity in 2012, MySQL has been the most popular open-source RDBMS thanks to its many features. MySQL powers some of the world’s largest websites including Netflix, Spotify, Twitter, and Facebook. Between the voluminous amount of documentation and the huge developer community, as well as a plethora of MySQL-related online resources, getting started with MySQL is a straightforward process.
Created with reliability and expediency in mind, MySQL is not fully compliant with standard SQL. At the same time, MySQL developers are constantly striving to adhere to them. Nevertheless, the level of adherence tends to lag. It does come with several SQL models and extensions that drive MySQL closer to compliance. Unlike the direct access of applications using SQLite, with MySQL you can obtain database access via a separate daemon process. This promotes better control in terms of database access because there is a server between applications and the database itself.
MySQL has spawned many third-party apps, as well as integrated libraries that help it not only be easier to work with, but also extend its functionality. Some of the more popular third-party tools include HeidiSQL, phpMyAdmin, and DBeaver.
MySQL data types are separated and organized by three different categories including date/time, string, and numeric types.
-
Date/Time
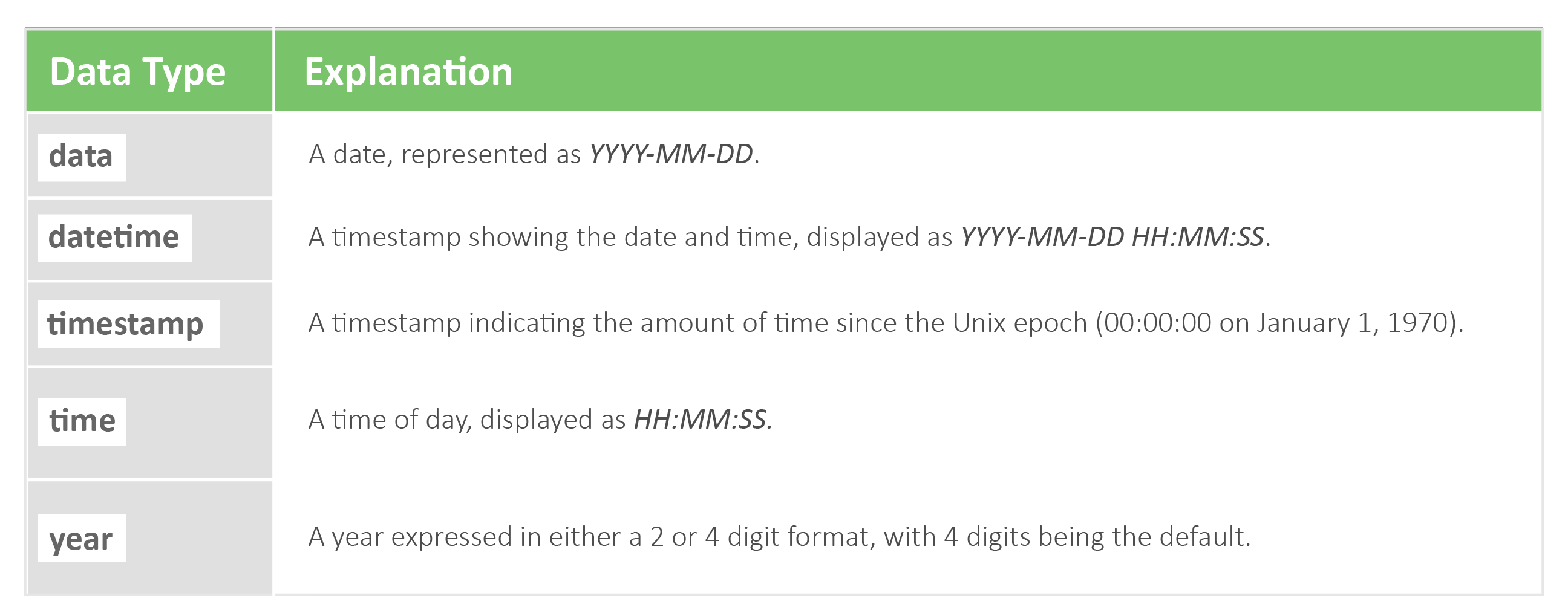
-
String
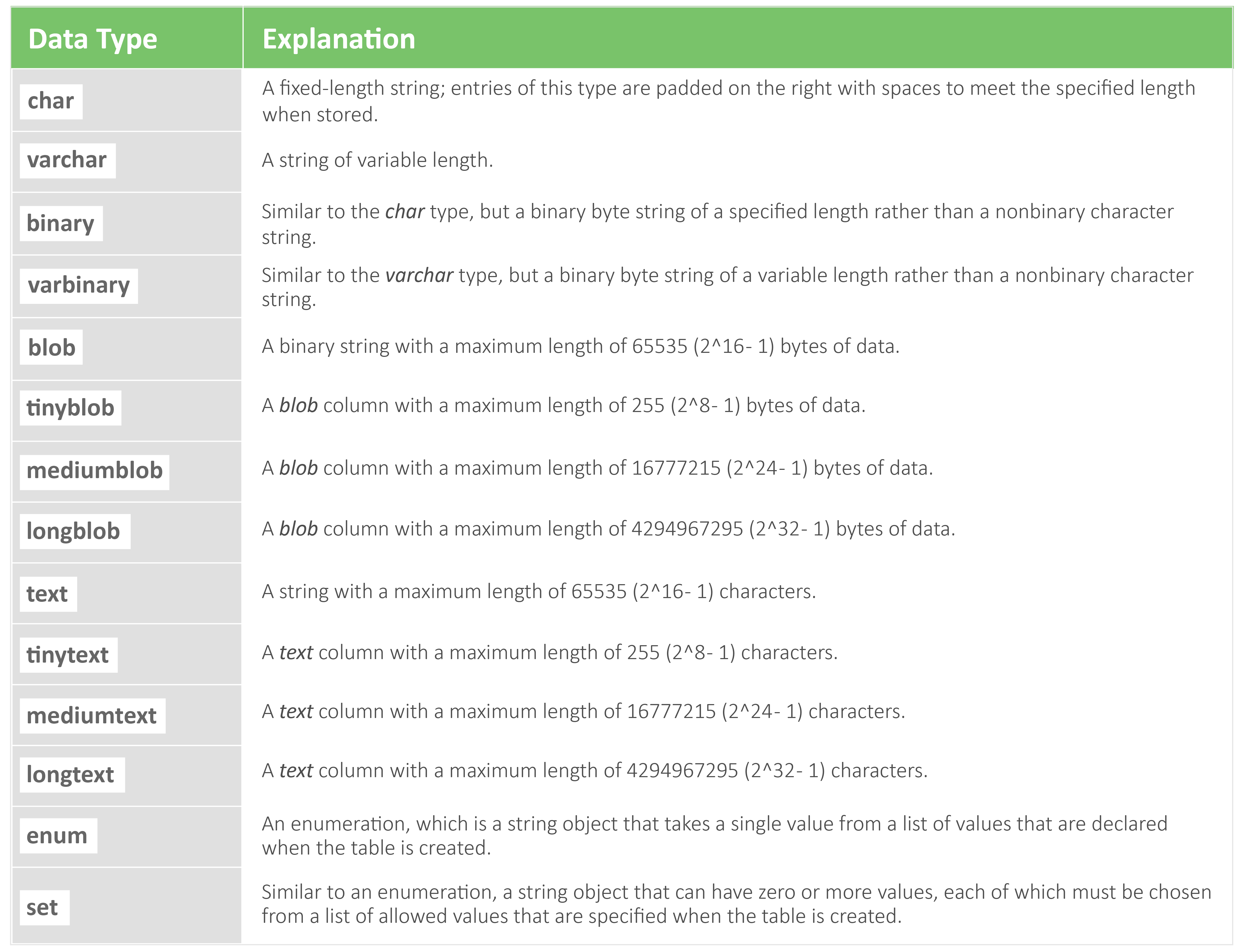
-
Numeric
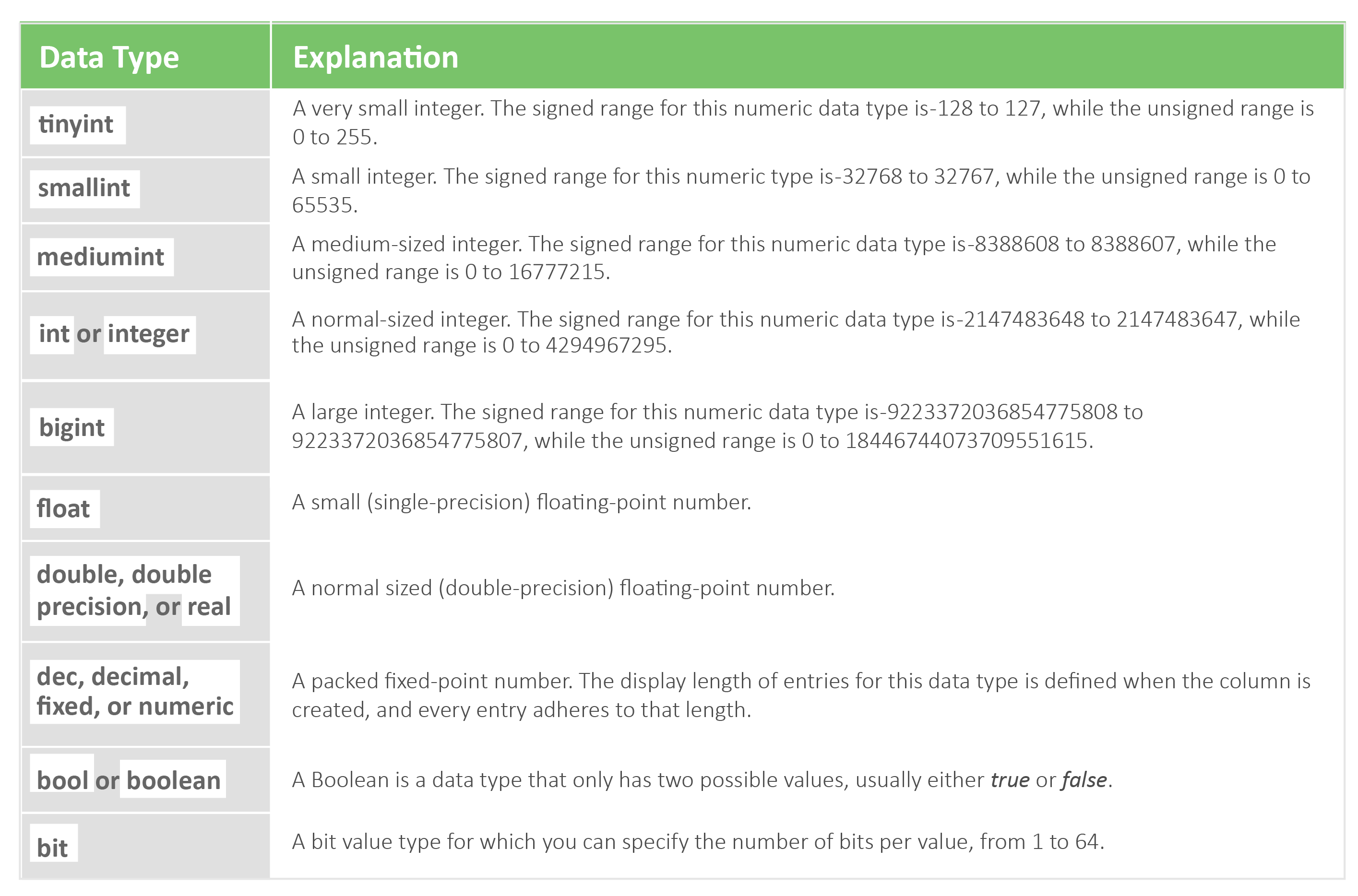
MySQL Advantages
- Ease of use and popularity: Due to its rampant popularity, MySQL not only has an overabundance of online and print documentation, but many experienced database administrators hold a wealth of valuable information. Beyond that, MySQL has several third-part tools like phpMyAdmin, to assist in simplifying the process of getting started. You can follow our tutorial on installing and securing phpMyAdmin on Ubuntu 18.04 to get started.
- Ample security: MySQL includes a script offered upon installation that helps to improve database security by defining the root user password, removing those databases that are available to all users by default, and setting password security levels. Additionally, unlike SQLite, MySQL allows for control of user privilege access settings.
- Operating speed: MySQL developers were able to prioritize speed thanks to their choice to not implement all SQL features. While other database management systems have recently gained on MySQL in terms of operating speed, it still has a reputation for being one of the fastest database solutions.
- Database replication: MySQL supports multiple replication Replication promotes database availability, reliability, and fault tolerance by sharing information across multiple hosts. This is extremely helpful when setting up a backup solution for your database or horizontally scaling it.
MySQL Disadvantages
- Clear limitations: Because MySQL was designed for ease of use and expediency, there are going to be some functional limitations due to a lack of adherence to SQL compliance. An example is the support of FULL JOIN clauses.
- Proprietary features and licensing: There is a dual-license to MySQL software. One is that it is an open-source community, no-cost edition, licensed under GPLv2. There are also commercial versions with proprietary licenses, with certain features only available in the later versions.
- Development happens slowly: Since the 2008 acquisition of MySQL by Sun Microsystems, and a subsequent 2009 one by the Oracle Corporation, users have noted a more sluggish development process as the open-source community no longer quickly reacts to fixing problems and developing enhancing changes due to lack of agency.
MySQL: Suitable for Use
- Distributed operations: The replication support offered by MySQL makes it a preferable choice for architecture setups such as primary-secondary and primary-primary.
- Web apps and websites: Due in large part to ease of its installation and setup, as well as speed and long run scalability, MySQL currently powers a vast number of apps and websites on the internet.
- Future growth expectation: The replication support can not only facilitate horizontal scaling, but it can get an upgrade to a commercial MySQL product (MySQL Cluster) easily. Thus, it can also support another form of horizontal scaling named automatic sharding.
MySQL: Not Suitable for Use
- A requirement of SQL compliance: With the aforementioned lack of full SQL compliance, it is not entirely suitable for cases where full SQL compliance is a must.
- Large data volumes and concurrency: While MySQL performs well with read-heavy operations, it does run into issues with concurrent read-write actions. If the application is heavy in terms of users writing data to it at once, another RDBMS such as PostgreSQL might be a better database fit.
We have a number of tutorials to help you take a deeper dive into MySQL:
- Follow our tutorial to learn about the main features of MySQL and set up MySQL on a server.
- In this tutorial, you will learn how to create a MySQL user, grant various permissions and privileges, and delete it.
- These tutorials will guide you through installing the LAMP Stack – Linux, Apache, MySQL, PHP on CentOS 7, LAMP Stack – Linux Apache, MySQL, and PHP on Ubuntu, and LEMP Stack -Linux, Nginx, MySQL, and PHP on Ubuntu.
PostgreSQL Breakdown
Also known as Postgres, PostgreSQL deems itself as the most advanced among relational databases in existence. Generated with the aim of being standard-compliant and highly extendable, PostgreSQL, an object-relational database, presents features such as table inheritance and function overloading. These features are most commonly associated with object databases.
PostgreSQL possesses the highly coveted function of concurrency (effectively handling multiple tasks simultaneously). This is achieved through the implementation of Multiversion Concurrency Control (MVCC) that ensures ACID compliance (atomicity, consistency, isolation, and durability) of transactions.
While PostgreSQL is not as popular as MySQL, there are still a lot of third-party tools available to ease working with it. Some examples of such tools are Postbird and pgAdmin.
Data Types Supported by PostgreSQL
Much like MySQL, PostgreSQL supports numeric, date/time, and string data types. However, it also supports other data types including network addresses, geometric shapes, bit strings, JSON entries, text searches, and other idiosyncratic data types.
-
Numeric

-
Date & Time

-
Character

-
Geometric Shapes
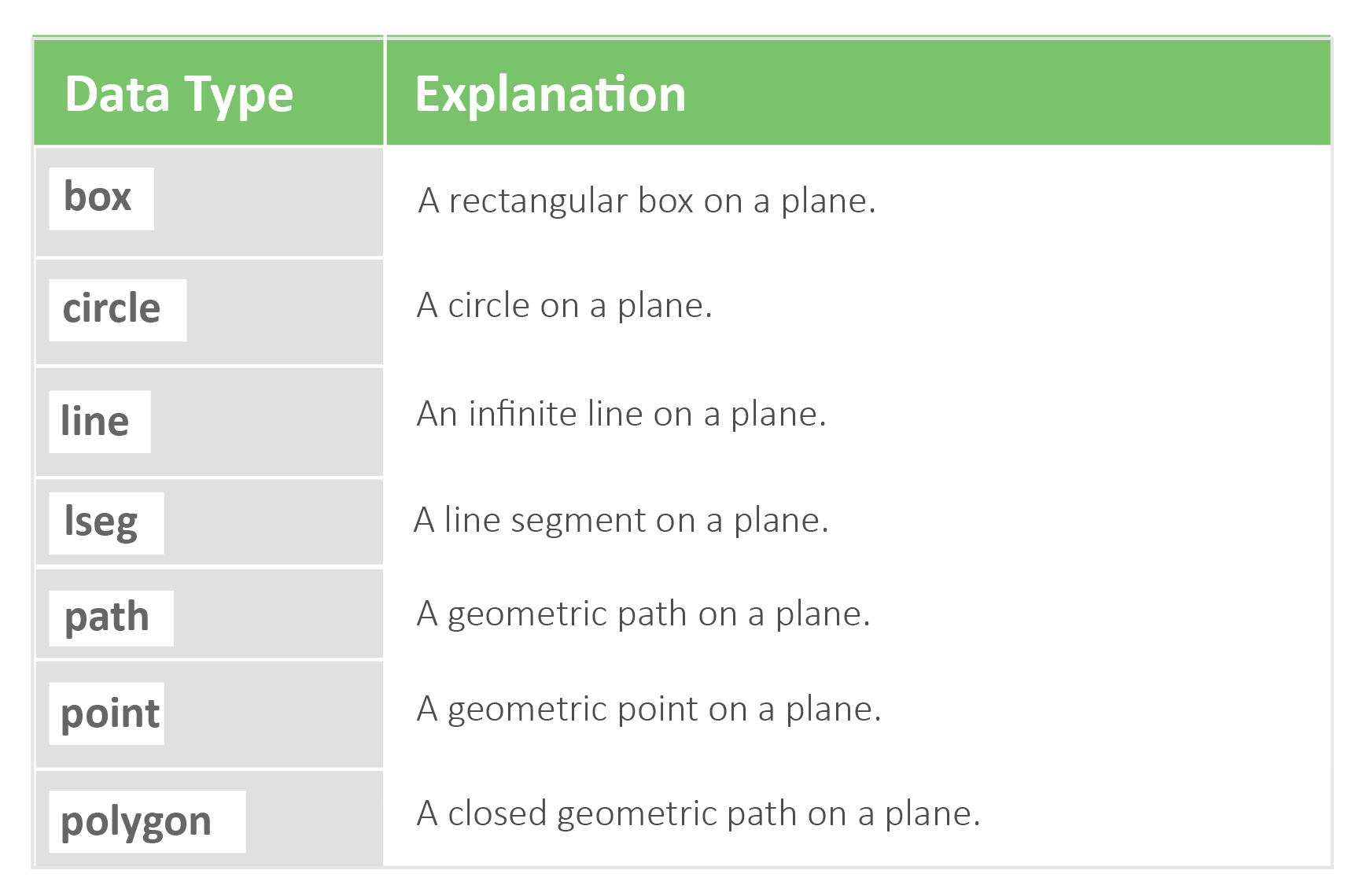
-
Network Address

-
Bit Strings

-
Text Search

-
JSON

-
Other Types

PostgreSQL Advantages
- SQL compliance: PostgreSQL aims to meet SQL compliance far more than MySQL or SQLite. It supports 160 out of the 179 required features to fulfill the core SQL:2011 compliance. It also contains many optional features according to the official documentation.
- Community-driven and open source: PostgreSQL has a massive and very devoted developer community that maintains and provides many online resources that describe how to utilize it best. This includes various online forums, official documentation, and even a PostgreSQL Wiki.
- Extensible: Using dynamic loading and catalog-driven operation users can programmatically extend PostgreSQL on the fly. An object code file can be designated (such as a shared library) to be loaded, if needed, by PostgreSQL.
PostgreSQL Disadvantages
- Memory performance concerns: Every new client connection splinters a new process in PostgreSQL. Each process has roughly 10MB of memory allocated to it. This can add up very quickly as lots of user connections. This means that PostgreSQL does not perform as well with read-heavy environments as other RDBMSs do.
- Popularity: Though recent years have shown an uptick in use, in terms of popularity, PostgreSQL has largely lagged behind MySQL. One of the reasons is that Postgre has fewer third-party tools available. Beyond that, there are simply fewer database administrators with Postgre database experience in comparison to MySQL.
PostgreSQL: Suitable for Use
- Preservation of data integrity is vital: Data integrity preservation is one of the primary factors that make PostgreSQL appealing. It has been fully ACID-compliant since 2001. It perpetually implements multi-version control to ensure this continues to be the case.
- Integration: PostgreSQL is widely compatible with many platforms and a variety of programming languages. As a result, migrating a database to another OS or integrating it with another tool is likely to be far easier with this database type.
- Complex operations: Multiple CPUs using query plans can be used to get answers faster. Additionally, the support of multiple concurrent writer actions helps this be more conducive to online transaction processing and complex operations like data warehousing.
PostgreSQL: Not Suitable for Use
- When speed matters: Designed with the primary goals of compatibility and extendability, Postgre sacrifices speed. If a project requires fast read operations, this is not the ideal DBMS to leverage.
- Simple setup: Simple database setups that do not require strict adherence to SQL standards and do not require large feature sets may not have use for Postgre. Its vast array of inclusions might not be necessary. MySQL tends to be a more practical choice for these scenarios.
- Complex replication: While the replication support from Postgre is strong, the feature is still relatively new and includes some configurations which are possible only with extensions. Many users find MySQL’s replication to be easier as it is a more mature process. This is especially true for those who do not possess vast system administration experience or are lacking a requisite database.
Following our PostgreSQL tutorials will help you get more familiar with the management system and use its advantages:
- Follow this tutorial to easily set up PostgreSQL on an Ubuntu server.
- With this guide, you will learn how to use roles and manage permissions in PostgreSQL.
Conclusion
SQLite, MySQL, and PostgreSQL are the most popular contemporary DBMS out there. Each of them comes with its own set of unique features, as well as limitations. Each excels against the others in its own way. The choice is not usually a simple one when you weigh in the pros and cons. It is not enough to just pick the fastest or the most feature-heavy one. It is prudent to research each of these tools in-depth before making your selection.
Happy Computing!
- How To Create a Kubernetes Cluster Using Kubeadm on Ubuntu 18.04 - June 24, 2021
- Nginx Server and Location Block Selection Algorithms: Overview - May 14, 2021
- Configuring an Iptables Firewall: Basic Rules and Commands - April 5, 2021
- How to Configure a Linux Service to Auto-Start After a Reboot or System Crash: Part 2 (Theoretical Explanations) - March 25, 2021
- How to Configure a Linux Service to Auto-Start After a Reboot or System Crash: Part 1 (Practical Examples) - March 24, 2021