

CloudSigma는 고객이 가상 머신에 GPU를 추가하고 가장 까다로운 워크로드를 충족할 수 있는 고성능의 비용 효율적인 컴퓨팅을 사용할 수 있도록 지원합니다. CloudSigma GPU 서비스의 핵심은 HPC, AI 및 데이터 분석에 최적화된 NVIDIA A100 Tensor Core GPU입니다. A100은 NVIDIA TESLA V100보다 뛰어난 성능을 발휘하며 AI 애플리케이션이 최대한 활용할 수 있는 새로운 기능을 갖추고 있습니다. 당사는 고객이 패스스루(passthrough) 모드에서 NVIDIA A100에 쉽게 최적화된 VM을 구축할 수 있도록 지원하여 VM 인스턴스가 GPU 및 내장 메모리를 직접 제어할 수 있도록 합니다.
사용 사례
클라우드에서 실행되는 컴퓨팅 집약적 애플리케이션의 성장은 최근 GPU 가속 클라우드 컴퓨팅의 폭발적인 증가를 이끌었습니다. 이러한 애플리케이션에는 AI 딥러닝 학습 및 추론, 데이터 분석, 과학 컴퓨팅, 유전체학, 그래픽 렌더링, 게임 등이 포함됩니다. AI 학습 및 과학 컴퓨팅의 스케일업부터 추론 애플리케이션의 스케일아웃, 실시간 대화형 AI 구현에 이르기까지, GPU는 클라우드에서 실행되는 수많은 복잡하고 예측 불가능한 워크로드를 가속화하는 데 필요한 강력한 성능을 제공합니다.
NVIDIA A100 Tensor Core GPU는 모든 규모에서 AI, 데이터 분석 및 HPC에 전례 없는 가속을 제공하며 거대한 도약을 나타냅니다. NVIDIA Ampere 아키텍처를 기반으로 하는 A100은 이전 세대보다 최대 20배 더 높은 성능을 제공합니다. CloudSigma는 가장 큰 모델과 데이터 세트를 실행할 수 있도록 초당 2테라바이트(TB/s)가 넘는 세계에서 가장 빠른 대역폭을 제공하는 80GB 메모리 버전을 지원합니다.
NVIDIA GPU는 AI 학습 및 추론 워크로드에 상당한 속도 향상을 제공함으로써 AI를 구동하는 선도적인 컴퓨팅 엔진 중 하나입니다. 또한 NVIDIA GPU는 다양한 유형의 HPC 및 데이터 분석 애플리케이션과 시스템을 가속화하여 데이터를 인사이트로 전환합니다.
AI 및 HPC
GPU 가속을 통해 복잡한 머신러닝 모델을 더 빠르고 효율적으로 학습시키세요. 데이터 집약적인 작업을 해결하고 AI 기반 혁신에서 획기적인 성과를 달성하세요.NVIDIA AI Enterprise는 모든 조직이 AI를 사용할 수 있도록 최적화된 엔드투엔드 클라우드 네이티브 AI 및 데이터 분석 소프트웨어 제품군입니다. 퍼블릭 클라우드 배포 인증을 받았으며, AI 프로젝트가 순조롭게 진행되도록 글로벌 엔터프라이즈 지원을 포함합니다. A100을 통해 연구원들은 실제 결과를 신속하게 도출하고 솔루션을 대규모 프로덕션 환경에 배포할 수 있습니다.
딥러닝 학습
AI 모델을 학습시키려면 대규모 컴퓨팅 성능과 확장성이 필요합니다. Tensor Float(TF32)가 탑재된 NVIDIA A100 Tensor Core는 코드 변경 없이 NVIDIA Volta 대비 최대 20배 더 높은 성능을 제공하며, 자동 혼합 정밀도(automatic mixed precision) 및 FP16을 통해 추가로 2배의 성능 향상을 제공합니다.
BERT와 같은 학습 워크로드는 2,048개의 A100 GPU를 통해 대규모로 1분 미만 만에 해결할 수 있으며, 이는 솔루션 도출 시간 부문에서 세계 기록입니다.
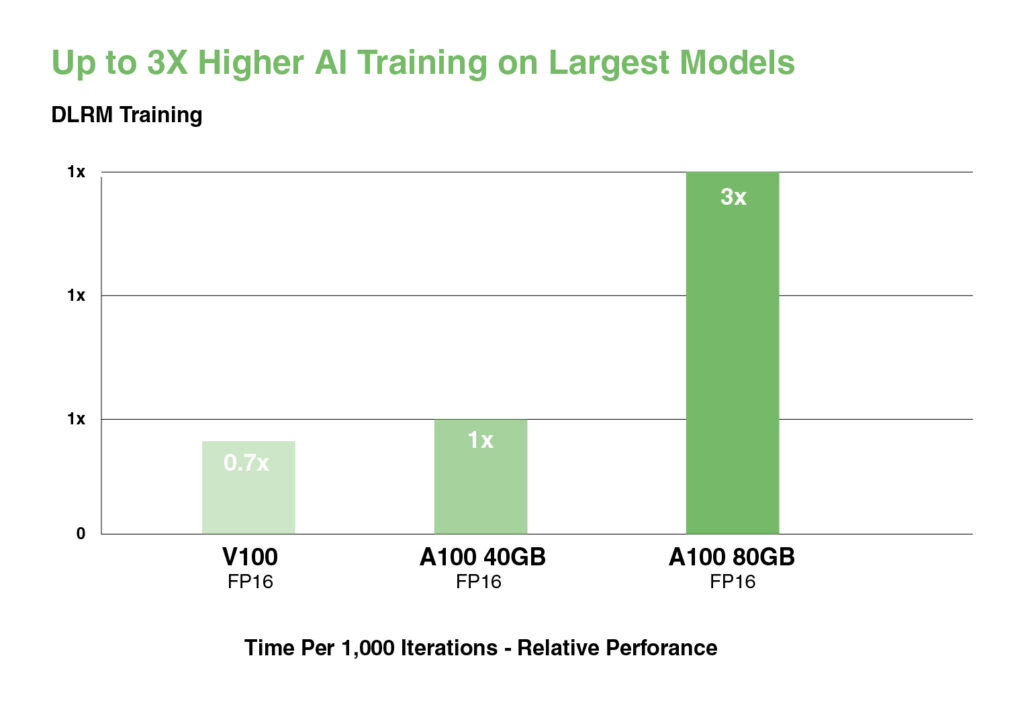
딥러닝 추천 모델(DLRM)과 같이 대규모 데이터 테이블을 가진 가장 큰 모델의 경우, A100 80GB는 노드당 최대 1.3TB의 통합 메모리에 도달하며 A100 40GB 대비 최대 3배의 처리량 향상을 제공합니다.
AI 학습을 위한 업계 전반의 벤치마크인 MLPerf에서 여러 성능 기록을 세우며 NVIDIA의 리더십을 입증했습니다.
딥러닝 추론
A100은 추론 워크로드를 최적화하기 위한 획기적인 기능을 도입했습니다. FP32에서 INT4까지 광범위한 정밀도를 가속화합니다. MIG(Multi-Instance GPU) 기술을 사용하면 단일 A100에서 여러 네트워크가 동시에 작동하여 컴퓨팅 자원 활용을 최적화할 수 있습니다. 또한 구조적 희소성(structural sparsity) 지원은 A100의 다른 추론 성능 향상 외에도 최대 2배 더 높은 성능을 제공합니다.
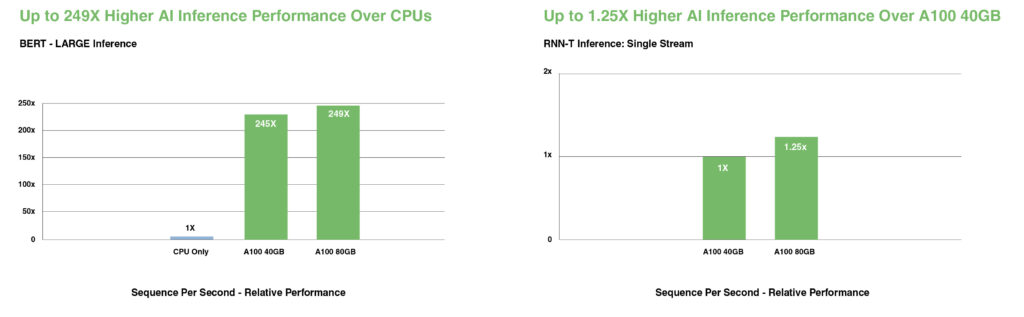
BERT와 같은 최첨단 대화형 AI 모델에서 A100은 CPU 대비 추론 처리량을 최대 249배 가속화합니다.
자동 음성 인식을 위한 RNN-T와 같이 배치 크기가 제한된 가장 복잡한 모델에서, A100 80GB의 늘어난 메모리 용량은 각 MIG의 크기를 두 배로 늘리고 A100 40GB 대비 최대 1.25배 더 높은 처리량을 제공합니다.
NVIDIA의 시장 선도적인 성능은 MLPerf Inference에서 입증되었습니다. A100은 이러한 리더십을 더욱 확장하기 위해 20배 더 높은 성능을 제공합니다.
고성능 컴퓨팅
차세대 발견을 실현하기 위해 과학자들은 우리 주변의 세계를 더 잘 이해하기 위한 시뮬레이션에 주목합니다.
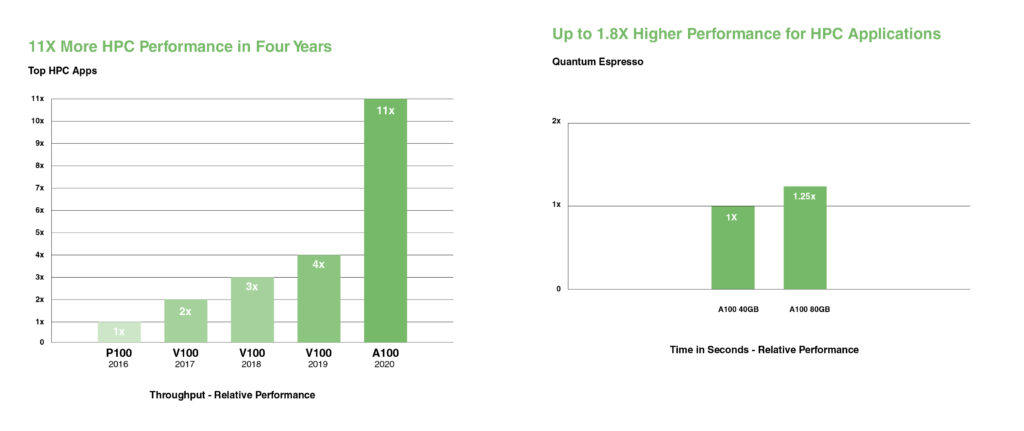
NVIDIA A100은 배정밀도 Tensor Cores를 도입하여 GPU 도입 이래 HPC 성능에서 가장 큰 도약을 이뤄냈습니다. 80GB의 가장 빠른 GPU 메모리를 통해 연구원들은 A100에서 10시간이 걸리던 배정밀도 시뮬레이션을 4시간 미만으로 단축할 수 있습니다. HPC 애플리케이션은 TF32를 활용하여 단정밀도, 조밀 행렬 곱셈 연산에서 최대 11X 더 높은 처리량을 달성할 수 있습니다.
가장 큰 데이터 세트를 사용하는 HPC 애플리케이션의 경우, A100 80GB의 추가 메모리는 재료 시뮬레이션인 Quantum Espresso에서 최대 2X의 처리량 증가를 제공합니다. 이러한 방대한 메모리와 전례 없는 메모리 대역폭 덕분에 A100 80GB는 차세대 워크로드를 위한 이상적인 플랫폼이 되었습니다.
고성능 데이터 분석
데이터 과학자는 방대한 데이터 세트를 분석, 시각화하고 인사이트로 전환할 수 있어야 합니다. 하지만 스케일아웃 솔루션은 여러 서버에 분산된 데이터 세트로 인해 지연되는 경우가 많습니다.
A100이 탑재된 가속 서버는 이러한 워크로드를 해결하는 데 필요한 컴퓨팅 성능(방대한 메모리, 2 TB/sec 이상의 메모리 대역폭, NVIDIA® NVLink® 및 NVSwitch™를 통한 확장성)을 제공합니다. InfiniBand, NVIDIA Magnum IO™ 및 GPU 가속 데이터 분석을 위한 RAPIDS Accelerator for Apache Spark를 포함한 RAPIDS™ 오픈 소스 라이브러리 제품군과 결합된 NVIDIA 데이터 센터 플랫폼은 전례 없는 수준의 성능과 효율성으로 이러한 거대한 워크로드를 가속화합니다.
빅데이터 분석 벤치마크에서 A100 80GB는 A100 40GB 대비 2X 증가한 인사이트를 제공하여 데이터 세트 크기가 폭발적으로 증가하는 새로운 워크로드에 이상적으로 부합합니다.
과학적 시뮬레이션: 과학 연구 및 시뮬레이션을 가속화하여 물리학, 화학, 환경 과학 분야에서 더 빠른 인사이트와 발견을 가능하게 합니다.
미디어 및 엔터테인먼트: 고해상도 그래픽, 비디오, 애니메이션을 번개처럼 빠른 속도로 렌더링합니다. 품질을 타협하지 않으면서 관객에게 뛰어난 시각적 경험을 선사합니다.
금융 모델링: 방대한 데이터 세트를 분석하고 비교할 수 없는 속도로 복잡한 금융 모델링을 수행하여 현명한 의사 결정을 위한 중요한 인사이트를 제공합니다.
댓글
아직 댓글이 없습니다. 첫 번째로 작성해 보세요.