

Il grep comando è una potente utilità per cercare pattern nel testo. Viene fornito preinstallato in qualsiasi Linux distro. Ecco il nostro tutorial che spiega come configurare il LAMP Stack - Linux, Apache, MySQL e PHP.
Il nome grep sta per global regular expression print. Lo strumento cerca il pattern specificato nell'input. In linea di principio, sembra banale. Tuttavia, il suo vero potere risiede nel modo in cui si definisce il pattern. Questa guida spiega in dettaglio come utilizzare grep con le espressioni regolari per eseguire ricerche complesse. Cominciamo!
Come usare Grep
Il comando grep, di per sé, non è complicato. Tutto ciò che richiede è il pattern e il contenuto su cui eseguire la ricerca. Ecco come si presenta la struttura di base del comando grep:
|
1 |
grep <regex> <file> |
Ricerca di testo
Per prima cosa, prendi un file di esempio su cui eseguire l'azione. Scarica la GNU General Public License v3.0 (in formato testo). È un file di testo piuttosto grande con molte parole e frasi. Se stai usando Ubuntu puoi trovarlo nel file qui sotto. Segui il nostro tutorial per un'installazione di Ubuntu rapida e semplice.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

Successivamente, puoi eseguire una ricerca di testo di base utilizzando grep:
|
1 |
grep <pattern> <text_file> |
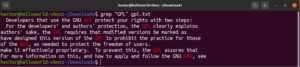
È possibile inviare tramite pipe l'output di un comando a grep:
|
1 |
cat gpl.txt | grep <pattern> |
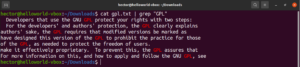
Sensibilità alle maiuscole
Per impostazione predefinita, grep distingue tra maiuscole e minuscole (case-sensitive). In molte situazioni, ignorare questa distinzione può essere ottimale. Per disabilitare la ricerca case-sensitive, usa il flag “-i” o “–ignore-case”:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
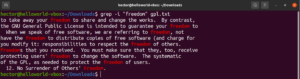
Invertire la ricerca
Per impostazione predefinita, il comportamento di grep è quello di stampare le righe in cui è stato trovato il pattern. L'inversione della corrispondenza (invert match) si riferisce al caso in cui non si desidera vedere le righe che corrispondono al pattern. Per invertire la corrispondenza, è necessario utilizzare il flag “-v” o “–invert-match”:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
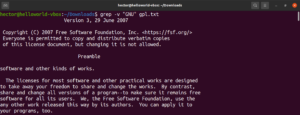
Numero di riga
Quando si esegue grep su un file molto grande, è difficile tenere traccia della posizione del risultato della ricerca. Per semplificare le cose, grep dispone della funzione per mostrare il numero di riga. Per abilitare la numerazione delle righe, usa il flag “-n” o “–line-number”:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
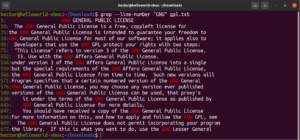
È possibile combinare più argomenti di grep. Il seguente comando grep eseguirà un'inversione della corrispondenza stampando al contempo i numeri di riga:
|
1 |
grep -nv <pattern> <file> |
Espressione regolare
All'inizio di questa guida, abbiamo menzionato che grep sta per global regular expression print. Il termine “espressione regolare” è definito come una stringa speciale che descrive il pattern di ricerca. Le espressioni regolari hanno una propria struttura e regole.
Esistono numerosi algoritmi e strumenti di ricerca di stringhe che utilizzano le espressioni regolari (regex in breve) per eseguire ricerche e azioni di sostituzione. Sebbene sia popolare, diverse applicazioni e linguaggi di programmazione implementano le regex in modo leggermente diverso. In questa sezione, mostreremo una manciata di metodi regex utilizzando grep.
Corrispondenza letterale
Nei precedenti esempi di grep, grep eseguiva la ricerca di una stringa specifica nel file di testo fornito. In realtà, grep stava effettuando la ricerca utilizzando un'espressione regolare di base. I pattern regex che definiscono la ricerca della corrispondenza esatta di una determinata stringa sono chiamati “letterali”. Il nome deriva dal fatto che corrispondono al pattern letteralmente, carattere per carattere.
La corrispondenza letterale funziona con caratteri alfabetici e numerici (oltre ad alcuni caratteri speciali). Tuttavia, a seconda di altri meccanismi di espressione, questo comportamento potrebbe cambiare:
|
1 |
grep "<string>" <file> |
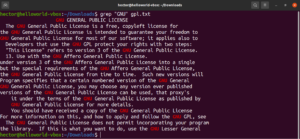
Corrispondenza con ancoraggio
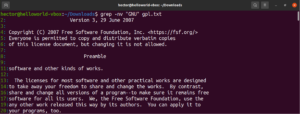
Gli ancoraggi sono caratteri speciali che definiscono dove deve trovarsi la posizione della corrispondenza nella riga affinché sia valida. Ecco un rapido esempio per semplificare. Se vogliamo trovare solo le righe che iniziano con la stringa "GNU", il comando grep con regex si presenterà così. Qui, il carattere "^" è l'ancoraggio, che definisce come uniche corrispondenze valide quelle all'inizio della riga:
|
1 |
grep -n "^GNU" <file> |

Allo stesso modo, se vogliamo trovare solo le righe che terminano con la stringa "works", il comando grep con regex si presenterà così. Qui, il carattere "$" è l'ancoraggio, che definisce come valide solo le corrispondenze alla fine della riga:
|
1 |
grep -n "and$" <file> |
Corrispondenza con qualsiasi carattere
Quando si esegue una ricerca di testo, si potrebbe voler definire che in una posizione specifica può esserci un carattere qualsiasi. Nelle regex, questo è espresso dal carattere punto (.).
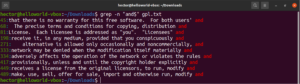
Diamo un'occhiata a questo esempio. Nel file di testo della GNU GPL 3, le parole "accept" ed "except" hanno entrambe in comune la parte "cept". Inoltre, entrambe le parole hanno due caratteri prima della parte "cept". Il seguente comando grep troverà corrispondenza con qualsiasi parola che abbia due caratteri prima della parte "cept":
|
1 |
grep -n "..cept" <file> |
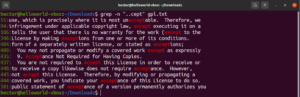
In base a questa regex, anche altre parole come suscept, unaccept, unexpected, ecc. sono corrispondenze valide.
Parentesi quadre
Nelle regex, le espressioni tra parentesi quadre definiscono che, nella posizione specificata, può esserci qualsiasi carattere dichiarato all'interno delle parentesi. Diamo un'occhiata alla seguente stringa di espressione regolare:
|
1 |
t[wo]o |
All'atto pratico, le parole too e two saranno le corrispondenze valide:
|
1 |
grep -n "t[wo]o" <file> |
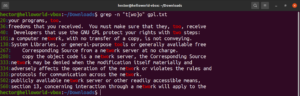
L'espressione tra parentesi quadre apre la strada ad alcune possibilità interessanti. È possibile utilizzare le espressioni tra parentesi quadre per indicare che, nella posizione specificata, può esserci qualsiasi carattere diverso da quelli dichiarati all'interno delle parentesi. Diamo un'occhiata alla seguente stringa regex. La corrispondenza sarà valida solo se c'è un carattere qualsiasi diverso da "c" prima di "ode":
|
1 |
"[^c]ode" |
Eseguilo sul file di testo della licenza GPL-3:
|
1 |
grep -n "[^c]ode" <file> |

Oltre al risultato del file, altri risultati validi sarebbero node, abode, anode, ecc. Le espressioni tra parentesi quadre possono anche descrivere un intervallo di caratteri. La seguente regex indica che la corrispondenza è valida se l'inizio della riga è un carattere maiuscolo:
|
1 |
"^[A-Z]" |
Eseguilo sul file di testo della licenza GPL-3. Verranno mostrate tutte le righe del file di testo:
|
1 |
grep -n "^[A-Z]" <file> |
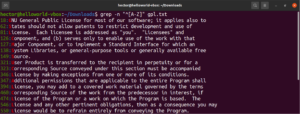
Per facilità d'uso, esistono alcune classi di caratteri che hanno etichette specifiche. Nell'esempio precedente, abbiamo utilizzato l'intervallo "A-Z" per definire i caratteri maiuscoli. In alternativa, possiamo utilizzare anche "[:upper:]". Il risultato sarà lo stesso:
|
1 |
grep -n "^[[:upper:]]" <file> |
Ripetizione di un pattern
In determinate situazioni, potresti voler trovare la corrispondenza di un pattern specifico o di una regex zero o più volte. Per farlo, il metacarattere è l'asterisco (*). La seguente espressione regolare troverà corrispondenza con tutte le parentesi contenenti solo lettere dell'alfabeto e spazi singoli tra di esse. Nota che la dichiarazione dei set di caratteri minuscoli, maiuscoli e degli spazi è unita senza alcuna punteggiatura:
|
1 |
"([a-zA-Z ]*)" |
Metti in azione la regex con grep:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

Utilizzare i metacaratteri come caratteri letterali
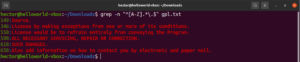
Finora abbiamo conosciuto vari metacaratteri come l'asterisco (*), il punto (.), le ancore (^ e $), ecc. Ognuno di essi denota una funzione unica nel contesto delle regex. Il problema sorge quando devono essere usati come letterali, non come metacaratteri. In tali situazioni, la barra rovesciata (\) davanti al metacarattere indicherà che deve essere usato in senso letterale, non come metacarattere. Dai un'occhiata a questo esempio di regex. Corrisponderà a tutte le righe che iniziano con un carattere maiuscolo e terminano con un punto:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
Alternanza
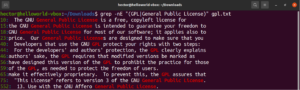
Utilizzando le espressioni tra parentesi quadre, possiamo specificare diverse scelte possibili per la corrispondenza di un singolo carattere. Le regex hanno la funzionalità di fare lo stesso con parole e frasi. Per indicare un'alternanza, si usa il carattere pipe (|). Le opzioni rimangono all'interno delle parentesi tonde mentre il carattere pipe le separa l'una dall'altra. Possono esserci due o più opzioni possibili affinché la corrispondenza sia valida. Dai un'occhiata al seguente esempio di regex. Corrisponderà sia a “GPL” che a “General Public License”:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
Quantificatori
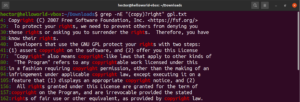
Utilizzando il metacarattere asterisco (*), siamo stati in grado di definire un pattern ripetuto zero o più volte. Tuttavia, c'è dell'altro con cui lavorare. È più facile spiegare i quantificatori con un esempio. La seguente espressione regolare descrive che sia “copyright” che “right” sono corrispondenze valide. Il punto interrogativo (?) rende opzionale la corrispondenza della parte “copy”:
|
1 |
grep -nE "(copy)?right" <file> |
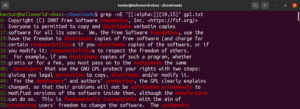
Il quantificatore successivo è il simbolo di addizione (+). Si comporta in modo simile all'asterisco. Tuttavia, il pattern definito deve corrispondere almeno una volta. Nel seguente esempio, l'espressione regolare corrisponderà a “soft” seguito da uno o più caratteri non di spaziatura:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
Specificare la ripetizione della corrispondenza
È possibile specificare il numero di volte in cui una corrispondenza viene ripetuta. Per farlo, usa le parentesi graffe ({}). La seguente espressione regolare corrisponderà a qualsiasi parola che contenga un minimo di tre vocali:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

Questa funzionalità consente anche di definire il limite inferiore e il limite superiore della lunghezza della corrispondenza. Nel seguente esempio, la regex corrisponderà a qualsiasi parola lunga da 10 a 15 caratteri:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
Conclusione
Cercare nei file di testo con grep è piuttosto comodo. Le espressioni regolari rendono la ricerca con grep più interessante e utile. Inoltre, consentono di perfezionare il pattern di ricerca in base ai propri desideri.
Sebbene abbiamo mostrato alcune delle espressioni regolari più comuni, questo è solo l'inizio. Esistono espressioni regolari più avanzate che offrono un controllo estremamente preciso sul comportamento di ricerca. Oltre a grep, le espressioni regolari sono ampiamente utilizzate anche da altri strumenti e linguaggi di programmazione.
Buon computing!
Commenti
Ancora nessun commento. Scrivi il primo.