
Un CSV file è un file di testo semplice che memorizza i dati in formato tabellare. Nella maggior parte dei casi, i file CSV utilizzano le virgole (,) come delimitatore, da cui il nome CSV (Comma Separated Values). Viene utilizzato in situazioni in cui la compatibilità dei dati è un problema, poiché i CSV possono essere aperti con qualsiasi editor di testo, app per fogli di calcolo e altri strumenti specializzati. In effetti, molti linguaggi di programmazione offrono un supporto integrato per i CSV.
In questa guida, impareremo a usare i CSV in un'applicazione Node.js di esempio.
CSV in Node.js
Node.js è un ambiente di runtime JavaScript open-source e multipiattaforma. È diventato uno dei backend più popolari che alimentano numerosi servizi web in tutto il web. Anche grandi aziende come Netflix e Uber utilizzano Node.js per alimentare i loro servizi.
Node.js ha anche numerosi moduli disponibili per essere distribuiti per aggiungere funzionalità extra a un progetto. Quando si tratta di CSV, ci sono molti moduli disponibili da utilizzare, ad esempio, node-csv, fast-csv, e papaparse ecc.
Come suggerisce il titolo della guida, utilizzeremo node-csv per leggere i file CSV utilizzando gli stream di Node.js. Dimostreremo anche come lavorare con i dati analizzati, ad esempio, trasferendo i dati in un database SQLite.
Prerequisiti
-
Per eseguire i passaggi illustrati in questa guida, avrai bisogno dei seguenti componenti:
-
Un sistema Linux configurato correttamente. Scopri di più su installazione e configurazione di un server cloud Ubuntu su CloudSigma.
-
Accesso a un utente non root con privilegi di sudo. Dai un'occhiata alla gestione dei permessi sudo con sudoers.
-
Un editor di testo adatto, ad esempio, Brackets, VS Code, Sublime Text, Vim/NeoVim, ecc.
-
Altro software:
-
Node.js LTS
-
SQLite
-
Passo 1 – Installazione del software necessario
Per questa guida, ho creato un server leggero con Ubuntu 22.04 LTS (connesso tramite SSH):
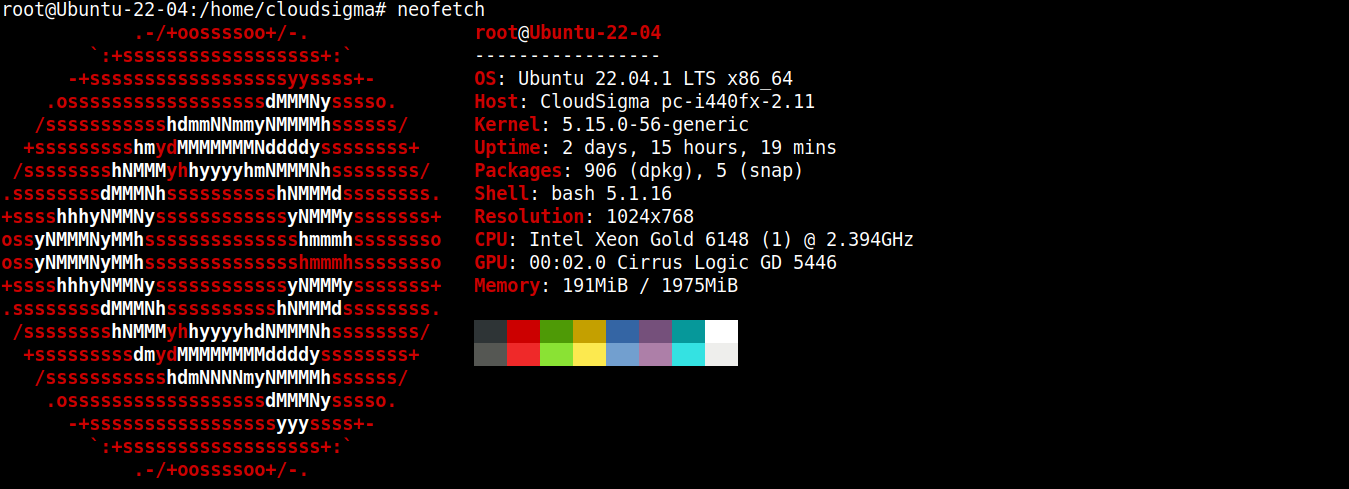
Ora installeremo Node.js e SQLite su di esso.
-
Installazione di Node.js LTS
Node.js è direttamente disponibile dai repository ufficiali dei pacchetti Ubuntu. Tuttavia, non è la versione aggiornata. Ecco perché faremo affidamento su un repository di terze parti (Nodesource) per ottenere gli ultimi pacchetti Node.js.
Aggiungi il repository per Node.js LTS:
|
1 |
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash - |
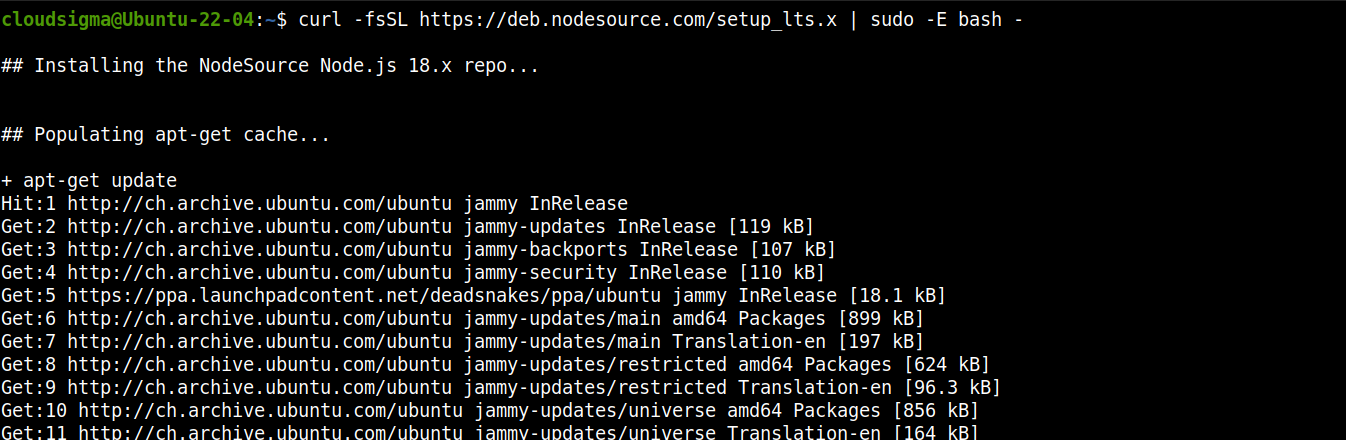
Ora installa Node.js LTS:
|
1 |
sudo apt install nodejs -y |

-
Installa SQLite
Installeremo SQLite direttamente dai repository dei pacchetti Ubuntu. Esegui i seguenti comandi:
|
1 |
sudo apt install sqlite3 -y |

Passo 2 – Configurazione della directory del progetto
In questa sezione, prepareremo una directory dedicata per il nostro progetto. Ospiterà tutti i file del progetto insieme ai moduli aggiuntivi.
Crea una nuova directory:
|
1 |
mkdir -pv csv_practice |
Entra nella directory:
|
1 |
cd csv_practice/ |
Successivamente, esegui il seguente comando per dichiarare la directory come un progetto npm :
|
1 |
npm init -y |
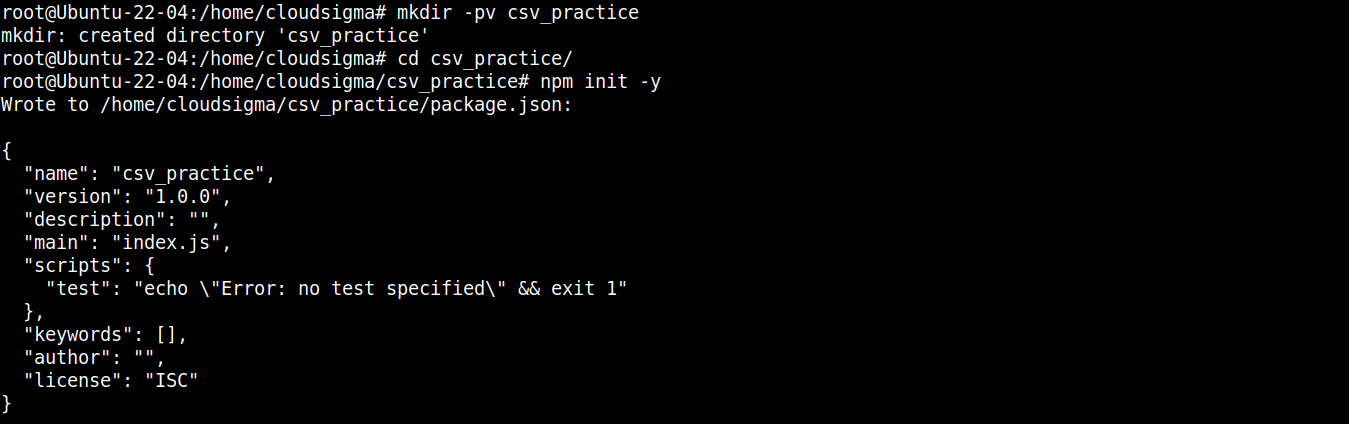
Una volta inizializzata la cartella del progetto, possiamo iniziare a installare i pacchetti e i moduli necessari. Per prima cosa, installeremo node-csv:
|
1 |
npm install csv |

Il modulo node-csv è in realtà una raccolta di diversi altri moduli: csv-generate, csv-parse (analisi dei file CSV), csv-stringify (scrittura di dati in CSV) e stream-transform.
Successivamente, abbiamo bisogno del modulo per comunicare con SQLite. Il seguente comando installerà il modulo node-sqlite3:
|
1 |
npm install sqlite3 |

Il componente di cui abbiamo bisogno per il nostro progetto è un file CSV. A scopo dimostrativo, utilizzeremo il file CSV sulla migrazione in Nuova Zelanda:
|
1 |
wget https://www.stats.govt.nz/assets/Uploads/International-migration/International-migration-September-2021-Infoshare-tables/Download-data/international-migration-September-2021-estimated-migration-by-age-and-sex-csv.csv -O migration_data.csv |
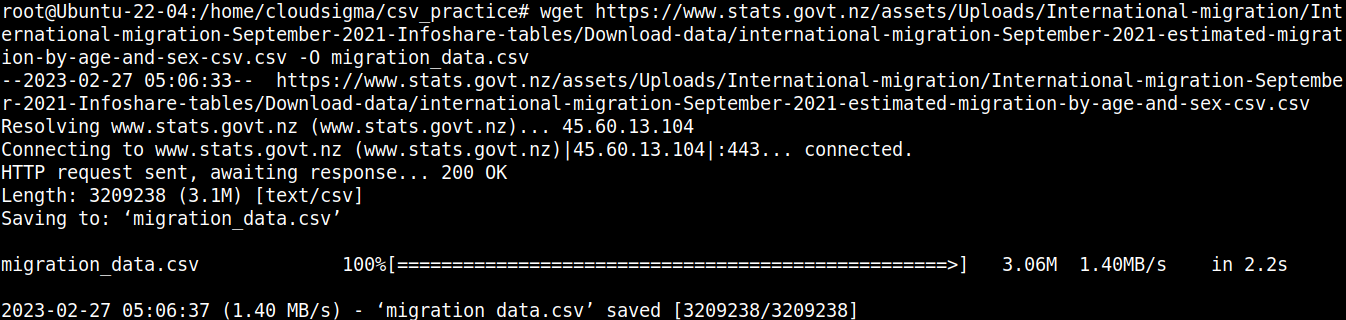
Diamo un’occhiata rapida al contenuto del file:
|
1 |
cat migration_data.csv | less |
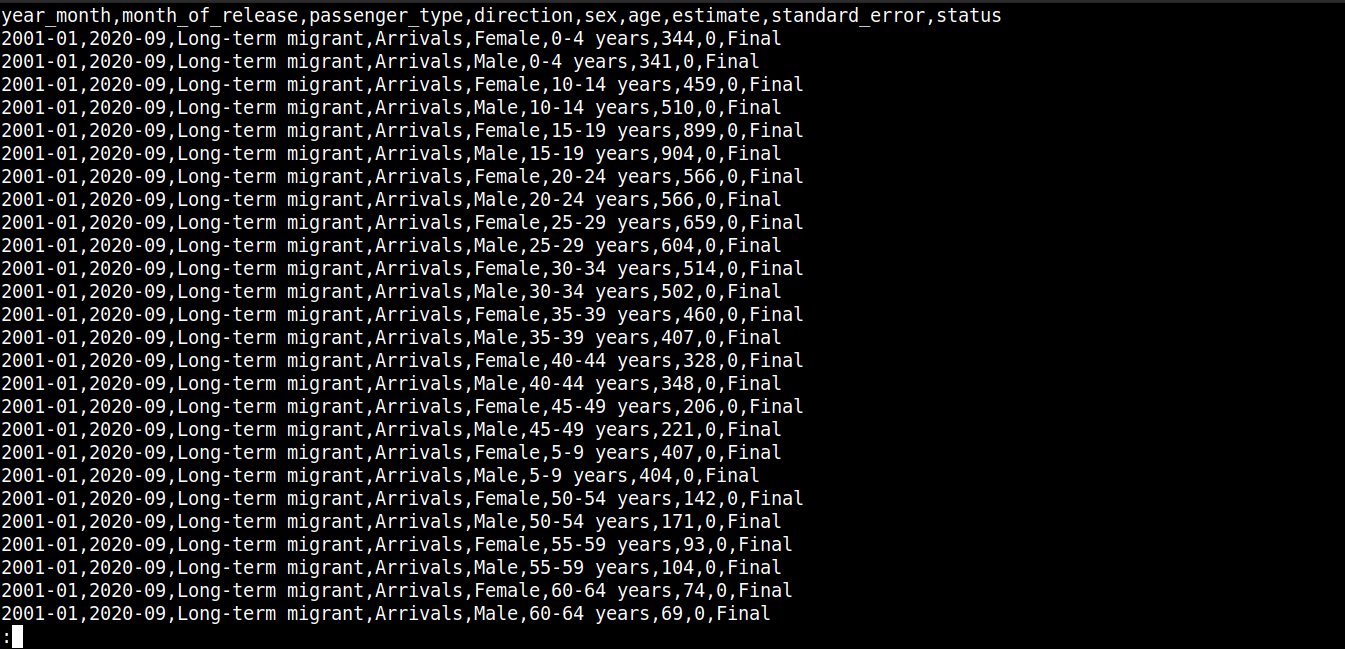
Qui,
-
La prima riga descrive i nomi delle colonne.
-
Le righe successive contengono i valori per questi campi.
-
Ogni riga è separata da una nuova riga (\n).
-
Ogni dato è separato da una virgola (,).
Tuttavia, il formato CSV non si limita all’uso delle virgole come delimitatore. Altri delimitatori comuni includono i due punti (:), i punti e virgola (;) e le tabulazioni (\td).
Passo 3 – Lettura di un CSV
In questa sezione, mostreremo come implementare un programma di esempio che legge e analizza i dati dal file CSV.
Crea un nuovo file JavaScript:
|
1 |
touch read_csv.js |
Apri il file nel tuo editor di testo preferito:
|
1 |
nano read_csv.js |
Per prima cosa, importeremo i moduli fs e csv-parse :
|
1 2 |
const fs = require("fs"); const { parse } = require("csv-parse"); |
Qui,
-
In primo luogo, alla variabile fs viene assegnato l’oggetto fs che restituisce il metodo require() di Node.js all’importazione del modulo.
-
Successivamente, il metodo parse viene estratto dall’oggetto restituito dal metodo require() nella variabile parse utilizzando la sintassi di destrutturazione.
Successivamente, aggiungeremo il codice per leggere il file CSV:
|
1 2 3 4 5 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) |
Qui,
-
Stiamo invocando il metodo createReadStream() dal modulo fs e passando come argomento il file CSV che vogliamo leggere. Questo crea un flusso leggibile (readable stream) suddividendo il file più grande in blocchi più piccoli.
-
Dopo aver creato lo stream, il metodo pipe() reindirizza i blocchi di dati dello stream a un altro stream. Questo nuovo stream viene creato invocando il metodo parse() dal modulo csv-module.
-
Il modulo csv-module implementa uno stream di trasformazione leggibile/scrivibile che prende un blocco di dati e lo trasforma in un’altra forma.
-
Il metodo parse() accetta oggetti con proprietà. L’oggetto elabora ulteriormente i dati analizzati. Qui, l’oggetto accetta le seguenti proprietà:
-
delimiter: Il carattere delimitatore per separare i valori. Nel caso del nostro CSV di destinazione, è la virgola (,).
-
from_line: Il numero di riga da cui il parser inizierà l’analisi. Con il valore fornito pari a 2, il parser salterà la riga 1 e inizierà dalla riga 2. Con questa disposizione, evitiamo che i nomi delle colonne vengano integrati nei dati analizzati.
-
Successivamente, collegheremo un evento di streaming utilizzando il metodo on() di Node.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Qui,
-
All’emissione di un determinato evento, un evento di streaming consente a un metodo di consumare un blocco di dati.
-
Quando i dati analizzati dal metodo parse() sono pronti per essere consumati, viene attivato l’evento data.
-
Per accedere ai dati, passiamo una callback al metodo on() che accetta un parametro row.
-
Il parametro row è un blocco di dati sotto forma di array (risultato dell’analisi).
-
Infine, i dati vengono registrati nella console utilizzando console.log().
Per completare il programma, aggiungeremo ulteriori eventi di stream per gestire gli errori e stampare un messaggio di successo quando tutti i dati nel file CSV saranno stati consumati. Aggiorna il codice come segue:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
Qui,
-
L'evento end viene emesso quando tutti i dati nel file CSV vengono consumati. Di conseguenza viene chiamato il console.log() metodo che stampa un messaggio di successo.
-
L'evento error viene emesso quando si riscontra un errore durante l'analisi dei dati CSV. Di conseguenza viene chiamato il console.log() metodo che stampa un messaggio di errore.
Il codice finale dovrebbe essere così:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const fs = require("fs"); const { parse } = require("csv-parse"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { console.log(row); }) .on("end", function () { console.log("finished"); }) .on("error", function (error) { console.log(error.message); }); |
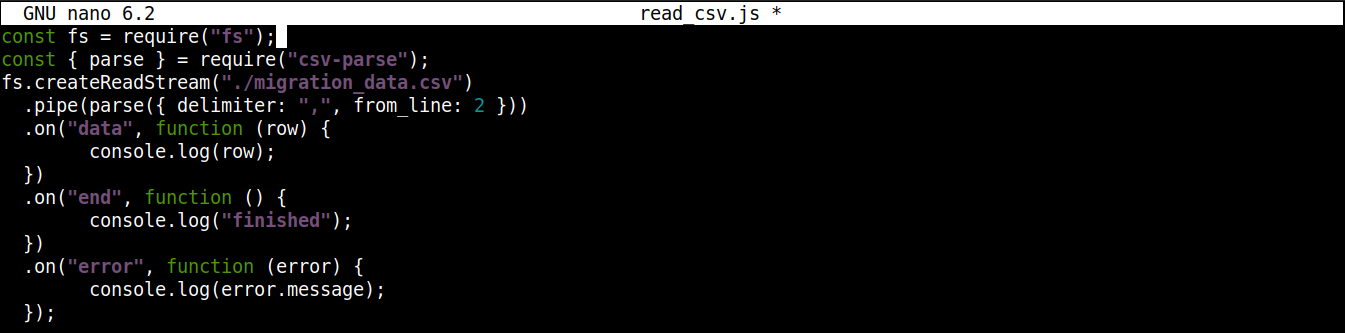
Salva il file e chiudi l'editor. Ora siamo pronti per eseguire il programma. Eseguilo usando Node.js:
|
1 |
node read_csv.js |
L'output dovrebbe apparire simile a questo:

Nota che i dati vengono consumati, trasformati e stampati sulla console. Trattandosi di un processo continuo, sembrerà che i dati vengano scaricati anziché stampare l'output tutto in una volta.
Passo 4 – Trasferimento dei dati CSV a un database
Finora abbiamo imparato come analizzare un file CSV usando node-csv. Questa sezione mostrerà come trasferire i dati analizzati in un database (SQLite).
Crea un nuovo file JavaScript per interagire con il database:
|
1 |
touch csv-to-sqlite3.js |
Ora apri il file in un editor di testo:
|
1 |
nano csv-to-sqlite3.js |
![]()
Inizieremo il nostro programma con il seguente codice:
|
1 2 3 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; |

Qui,
-
Nella prima riga stiamo importando il fs modulo.
-
Nella terza riga, la variabile filepath contiene il percorso del database SQLite.
-
A questo punto, il database non esiste ancora. Tuttavia, sarà necessario quando si lavora con node-sqlite3.
Successivamente, aggiungi le seguenti righe per stabilire una connessione al database SQLite:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } console.log("Connessione al database riuscita"); }); return db; } } |
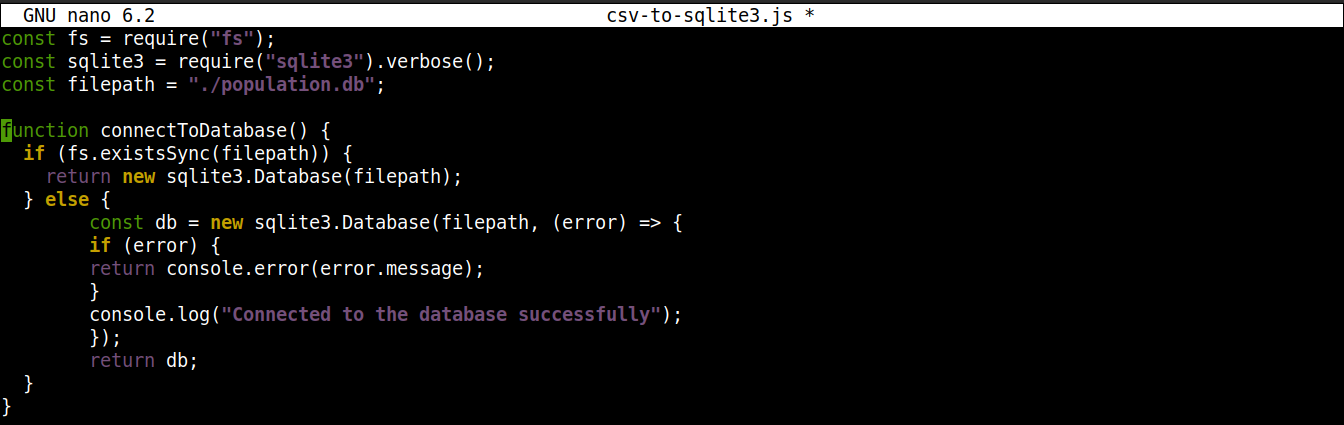
Qui,
-
Il metodo connectoToDatabase() stabilisce una connessione al database.
-
All'interno di connectToDatabase(), stiamo invocando il metodo existsSync() del modulo fs all'interno di un'istruzione if. L'istruzione if verifica l'esistenza del database nella posizione specificata.
-
Se la valutazione della condizione è true, allora la classe Database() del modulo node-sqlite3 viene istanziata. Una volta stabilita la connessione, la funzione restituisce un oggetto ed esce.
-
Se la valutazione della condizione è false (il database non esiste), l'esecuzione passerà al blocco else. Lì, la classe Database() verrà avviata con due argomenti: un percorso al file del database e una callback.
-
In sostanza, il database verrà creato se non esiste. Tuttavia, se si verifica un errore durante il processo di creazione, imposterà l'oggetto error e stamperà il messaggio di errore.
Successivamente, introdurremo il codice per creare una tabella se il database non esiste:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
const fs = require("fs"); const sqlite3 = require("sqlite3").verbose(); const filepath = "./population.db"; function connectToDatabase() { if (fs.existsSync(filepath)) { return new sqlite3.Database(filepath); } else { const db = new sqlite3.Database(filepath, (error) => { if (error) { return console.error(error.message); } createTable(db); console.log("Connessione al database riuscita"); }); return db; } } function createTable(db) { db.exec(` CREATE TABLE migration ( year_month VARCHAR(10), month_of_release VARCHAR(10), passenger_type VARCHAR(50), direction VARCHAR(20), sex VARCHAR(10), age VARCHAR(50), estimate INT ) `); } module.exports = connectToDatabase(); |
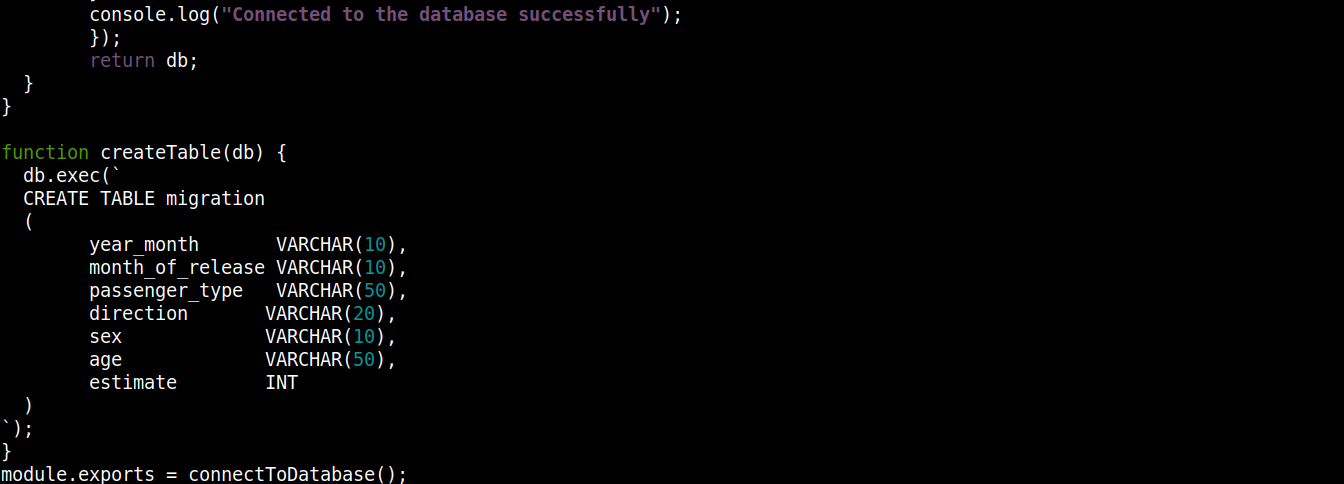
Qui,
-
La funzione connectToDatabase() invoca la funzione createTable() che accetta l'oggetto memorizzato in db come argomento.
-
Al di fuori di connectToDatabase(), abbiamo definito il metodo createTable() che accetta l'oggetto di connessione db come parametro.
-
Il metodo exec() su db accetta un'istruzione SQL come argomento. All'interno di questa istruzione SQL, abbiamo definito la creazione di una tabella migration con 7 colonne, ciascuna corrispondente alle intestazioni di colonna nel file migration_data.csv .
-
Infine, stiamo invocando la funzione connectToDatabase() metodo ed esportando l'oggetto di connessione che restituisce in modo da poterlo utilizzare in altri file.
Salva il file e chiudi l'editor.
Successivamente, creeremo un altro programma per inserire i dati analizzati nel database:
|
1 |
nano insert_data.js |
Inserisci il seguente codice in insert_data.js:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const fs = require("fs"); const { parse } = require("csv-parse"); const db = require("./csv-to-sqlite3"); fs.createReadStream("./migration_data.csv") .pipe(parse({ delimiter: ",", from_line: 2 })) .on("data", function (row) { db.serialize(function () { db.run( `INSERT INTO migration VALUES (?, ?, ? , ?, ?, ?, ?)`, [row[0], row[1], row[2], row[3], row[4], row[5], row[6]], function (error) { if (error) { return console.log(error.message); } console.log(`Row inserted, ID: ${this.lastID}`); } ); }); }); |
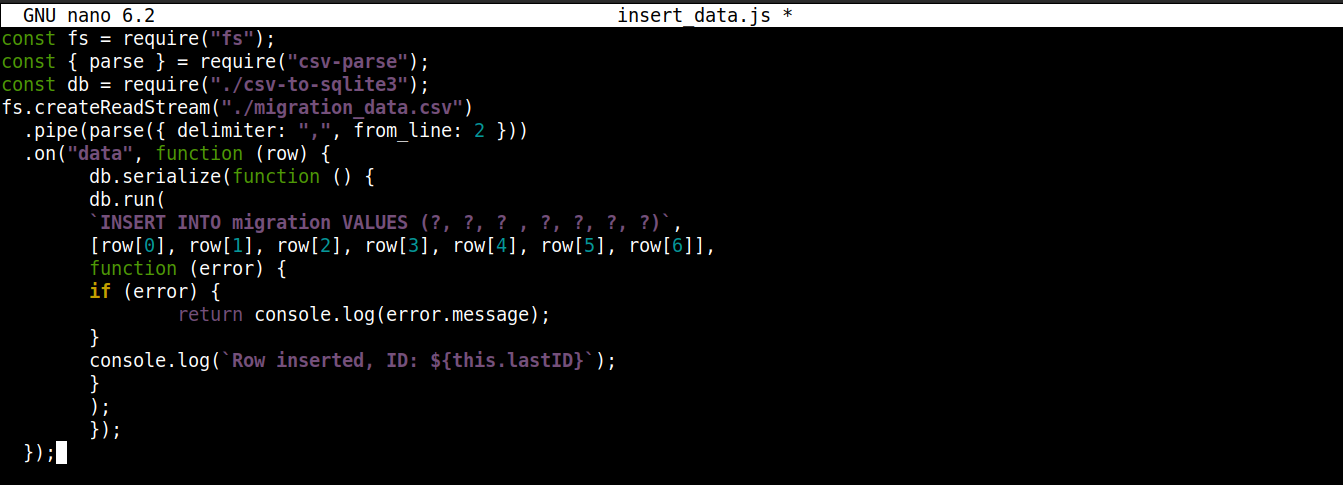
Here,
-
Stiamo memorizzando l'oggetto di connessione ottenuto da csv-to-sqlite3.js nella variabile db.
-
All'interno della callback dell'evento data (collegata allo stream del modulo fs), stiamo invocando il serialize() metodo sull'oggetto di connessione. Assicura che l'esecuzione di un'istruzione SQL termini prima dell'inizio della successiva, prevenendo race condition nel database (il sistema che esegue operazioni concorrenti simultaneamente).
-
Il serialize() accetta tre argomenti:
-
Il primo argomento è l'istruzione SQL.
-
Il secondo argomento è un array.
-
Il terzo argomento è una callback che viene eseguita quando i dati vengono inseriti con successo o meno nel database.
-
Siamo pronti per eseguire il programma. Esegui insert_data.js utilizzando Node.js:
|
1 |
node insert_data.js |
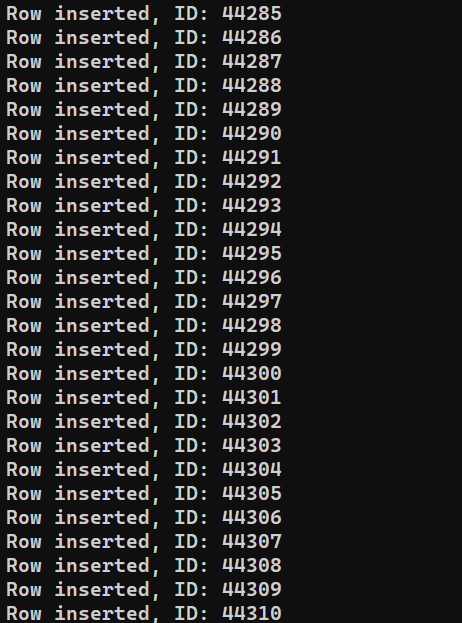
A seconda delle prestazioni del sistema, il processo potrebbe richiedere del tempo per terminare. Tuttavia, al completamento, l'output dovrebbe apparire simile a questo:
Step 5 – Scrittura dei dati in CSV
Dopo l'ultima sezione, abbiamo un database contenente tutti i record che abbiamo analizzato da migration_data.csv. In questa sezione, leggeremo i dati dal database e li scriveremo in un file CSV separato.
Crea un nuovo file JavaScript per memorizzare il programma:
|
1 |
nano write_csv.js |
Innanzitutto, aggiungi le seguenti righe per importare fs e csv-stringify insieme all'oggetto di connessione del database da csv-to-sqlite3.js:
|
1 2 3 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); |
Successivamente, aggiungeremo una variabile che contiene il nome del file CSV in cui scrivere insieme a un flusso di scrittura (writable stream):
|
1 2 3 4 5 6 7 8 9 10 11 |
const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; |
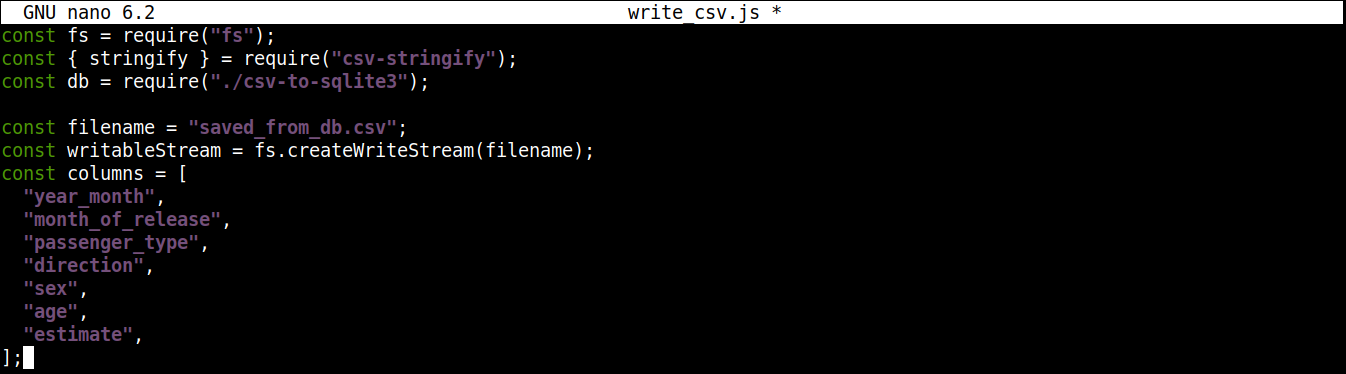
Qui,
-
Il metodo createWriteStream() accetta come argomento il nome del file in cui scrivere. Chiameremo il file saved_from_db.csv.
-
La variabile column memorizza un array che contiene tutti i nomi delle intestazioni per i dati CSV.
Successivamente, aggiungi le seguenti righe di codice per leggere i dati dal database e scriverli in saved_from_db.csv:
|
1 2 3 4 5 6 7 8 9 10 11 |
const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("finished writing to CSV"); |
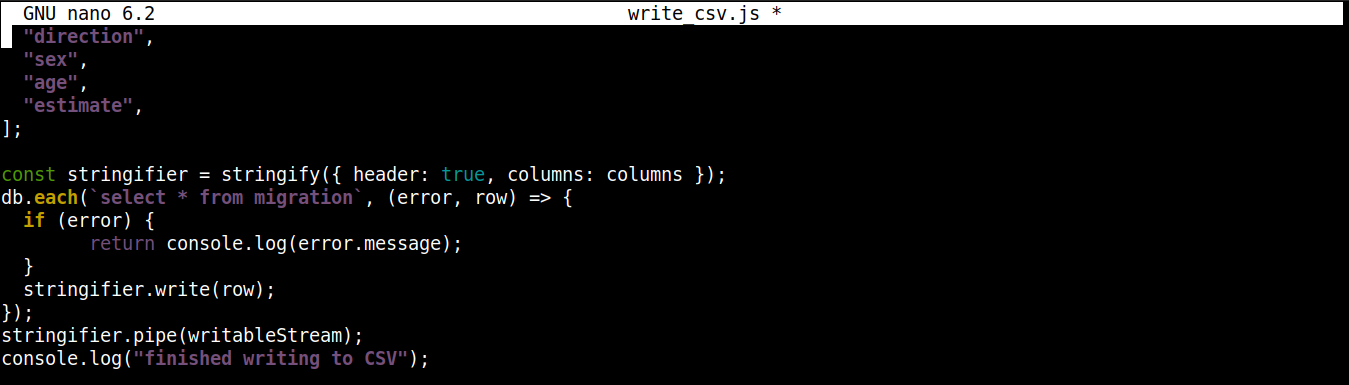
Qui,
-
Invochiamo il metodo stringify() con un oggetto come argomento. Ciò produce un flusso di trasformazione (transform stream) che converte i dati da un oggetto al formato CSV. L'oggetto passato a stringify() ha due proprietà:
-
header: accetta un valore booleano. Se il valore è true, viene generata un'intestazione.
-
columns: accetta un array che contiene i nomi delle colonne da scrivere nella prima riga del file CSV se header è true.
-
-
Il metodo each() dell'oggetto di connessione csv-to-sqlite3 viene invocato con due argomenti: l'istruzione SQL (che legge i dati dal database) e una callback (che gestisce il successo/errore).
-
Ad ogni iterazione di each(), pipe() (dal flusso stringifier ) inizia a inviare dati a blocchi (chunks) al flusso di scrittura writableStream. Ogni blocco di dati viene quindi scritto in saved_from_db.csv.
-
Quando tutti i dati sono stati scritti nel file CSV, viene stampato un messaggio di successo sulla schermata della console.
Il codice finale dovrebbe apparire così:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const fs = require("fs"); const { stringify } = require("csv-stringify"); const db = require("./csv-to-sqlite3"); const filename = "saved_from_db.csv"; const writableStream = fs.createWriteStream(filename); const columns = [ "year_month", "month_of_release", "passenger_type", "direction", "sex", "age", "estimate", ]; const stringifier = stringify({ header: true, columns: columns }); db.each(`select * from migration`, (error, row) => { if (error) { return console.log(error.message); } stringifier.write(row); }); stringifier.pipe(writableStream); console.log("scrittura su CSV completata"); |
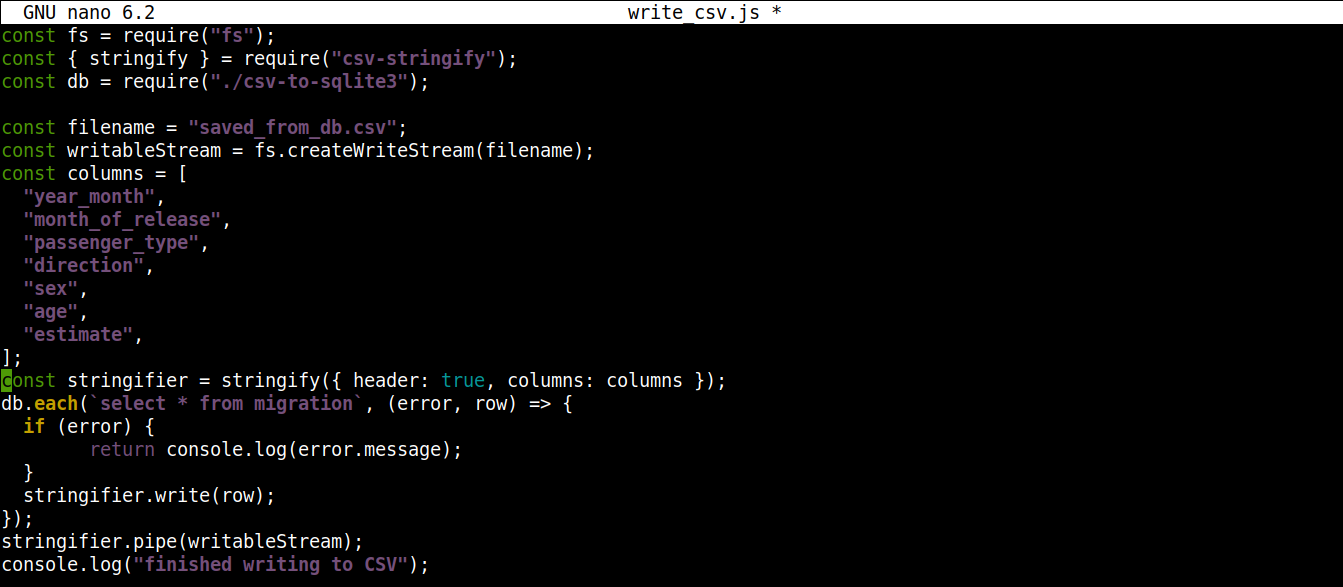
Salva il file e chiudi l'editor. Ora possiamo eseguire il programma usando Node.js:
|
1 |
node write_csv.js |
Per confermare se i dati sono stati esportati con successo, controlla il contenuto di saved_from_db.csv:
|
1 |
cat saved_from_db.csv | less |
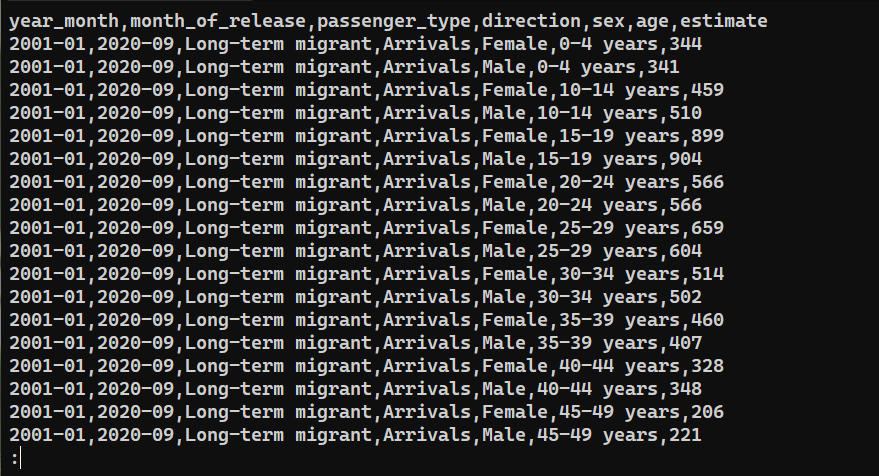
Considerazioni finali
In questa guida, abbiamo mostrato come lavorare con i file CSV in Node.js utilizzando i moduli node-csv e node-sqlite3. Abbiamo creato diversi programmi per svolgere vari compiti, ad esempio, analizzare i dati da un CSV, inserire i dati in un database SQLite e scrivere i dati in un nuovo file CSV.
Questa guida mostra solo una piccola parte delle funzionalità del node-csv modulo. Scopri di più su tutte le sue funzionalità su CSV Project. Per saperne di più su node-sqlite3, dai un'occhiata alla documentazione ufficiale su GitHub. Un altro modulo che vale la pena menzionare è event-stream per semplificare il lavoro con gli stream.
Vuoi far crescere ulteriormente il tuo progetto Node.js? Ecco alcuni tutorial su Node.js che dovresti consultare:
-
Utilizzo dei moduli Node.js con npm e package.json: un tutorial
-
Come distribuire un'app Node.js (Express.js) con Docker su Ubuntu 20.04
-
Collegare PostgreSQL con le applicazioni Node.js: un tutorial
Buona programmazione!
Commenti
Ancora nessun commento. Scrivi il primo.