

Le aziende implicano una grande quantità di dati e questo rende il problema della loro gestione e del loro trattamento più difficile. Tradizionalmente, l’industria ha utilizzato sistemi RDBMS per decenni, ma con l’avvento dei Big Data nel XXI secolo, i database NoSQL (Not only SQL) sono entrati in gioco per dati non strutturati e semi-strutturati su larga scala.
In questo post, configurerò un cluster MongoDB.
MongoDB è un database di documenti NoSQL gratuito e open-source, ampiamente utilizzato per l’elevato livello di scalabilità e flessibilità che offre.
Per distribuire MongoDB in produzione, si consiglia di utilizzare i Replica Set. I replica set sono l’equivalente in MongoDB di una configurazione Master/Slave nel mondo relazionale, ma al contrario, sono molto semplici da configurare, poiché tutto è integrato. Per saperne di più sui Replica Set, consulta la definizione di TutorialsPoint’s sul processo di replica.
Pianificazione del cluster di server cloud MongoDB
Creerò un cluster a 3 nodi. È importante assegnare loro risorse uguali perché ognuno di essi può diventare il server primario (ovvero master). Questi nodi o macchine possono essere eseguiti su qualsiasi sistema operativo, ma in questo tutorial utilizzerò Ubuntu 18.04 LTS. Su come collegare e configurare l’immagine preinstallata dalla libreria di CloudSigma, puoi fare riferimento a questo tutorial.
Poiché l’intero scopo di un Replica Set è che il cluster sopravviva alla caduta di un singolo nodo, sarebbe piuttosto inutile se tutti i server risiedessero sullo stesso host fisico. Fortunatamente, CloudSigma offre qualcosa chiamato gruppi di disponibilità. Ciò significa che è possibile istruire il sistema a raggruppare tutti e tre i server in gruppi diversi. In questo modo, non risiederanno mai sullo stesso host fisico. Maggiori informazioni su questo e su altre funzionalità di sicurezza e continuità aziendale sono disponibili qui.
È inoltre importante utilizzare una versione a 64 bit di Linux. Il motivo è semplicemente che MongoDB non funziona bene su sistemi a 32 bit (maggiori informazioni a riguardo qui).
Installazione di MongoDB nel Cloud
Questa sezione è piuttosto semplice. Utilizza una delle immagini preconfigurate di Ubuntu 18.04 o installala tu stesso.
La configurazione di CPU, RAM e disco è davvero individuale e dipende dal carico. Per un’installazione di piccole dimensioni, dovrebbero essere sufficienti una CPU da 4 GHz, 4 GB di RAM e 10 GB di disco (per il sistema). Quando colleghi le unità, assicurati di utilizzare VirtIO. Se utilizzi IDE, le prestazioni ne risentiranno in modo significativo. Inoltre, poiché stai creando un Replica Set, è necessario che tutti i nodi (e i server applicativi) si trovino sulla stessa VLAN.
Contrariamente a molti altri fornitori di cloud, non è necessario configurare lo storage con RAID10 o simili per migliorare le prestazioni. Come riferiscono molti dei nostri clienti, otterrai prestazioni straordinarie fin da subito utilizzando sia SSD che dischi magnetici su CloudSigma.
Consiglio comunque di conservare i dati di MongoDB su un’unità separata. Il motivo è semplicemente che a un certo punto potresti dover effettuare alcune ottimizzazioni del file system che non vorresti applicare all’intero file system.
Con questo in mente, la cosa più semplice è aggiungere questa unità dopo la configurazione dei server. Per ora, concentriamoci solo sull’installazione del sistema. Se stai installando autonomamente (invece di utilizzare i sistemi preconfigurati), ti consiglio di premere F4 nel menu di avvio e selezionare ‘Installa una macchina virtuale minima’.
Sto creando 3 macchine, ciascuna con le seguenti specifiche:
- CPU: 4 GHz
- RAM: 4 GB
- SSD: 10 GB (Ubuntu 18.04 LTS), 20 GB (unità aggiuntiva)
Come indicato nella parte relativa all’SSD, sto collegando un’unità da 10 GB con Ubuntu 18.04 LTS installato.
Inoltre, sto collegando un’altra unità vuota da 20 GB per memorizzare i dati di MongoDB. Le dimensioni di questa dipendono molto dal tuo utilizzo, ma per un sistema di piccole dimensioni, 20 GB dovrebbero essere sufficienti. Tuttavia, poiché a volte è difficile prevedere quanti dati memorizzerai, utilizzeremo LVM. Questo ti consentirà di aggiungere semplicemente un altro disco in seguito ed espandere il volume senza dover ricominciare da capo. In alternativa, puoi utilizzare un singolo disco e scalarlo successivamente conresize2fs.
Per aggiungere il disco, basta andare alla sezione ‘Drives’, fare clic sull'icona ‘Create a new drive’ in alto, assegnare un nome al nuovo disco e impostarne la dimensione a 20 GB. Una volta salvato, vai alla singola macchina a cui desideri collegarlo e, nella sezione dei dischi dei dettagli di quella macchina, puoi fare clic su ‘Attach a drive’ e selezionare il disco.
Ora che hai tre macchine, puoi procedere al montaggio del disco aggiuntivo che hai aggiunto per l'archiviazione dei dati di MongoDB su ciascuna macchina. Raccomando di aggiungere questo disco come partizione. L'uso del partizionamento consente al sistema operativo di gestire le informazioni in ciascuna regione separatamente. Per aggiungere il disco come partizione, controllerò prima tutti i dischi collegati alla nostra macchina. Per fare ciò, eseguirò il seguente comando:
|
1 |
fdisk -l |
Quando eseguo il comando, ottengo l'output che indica i dischi e i dispositivi sulla mia macchina.
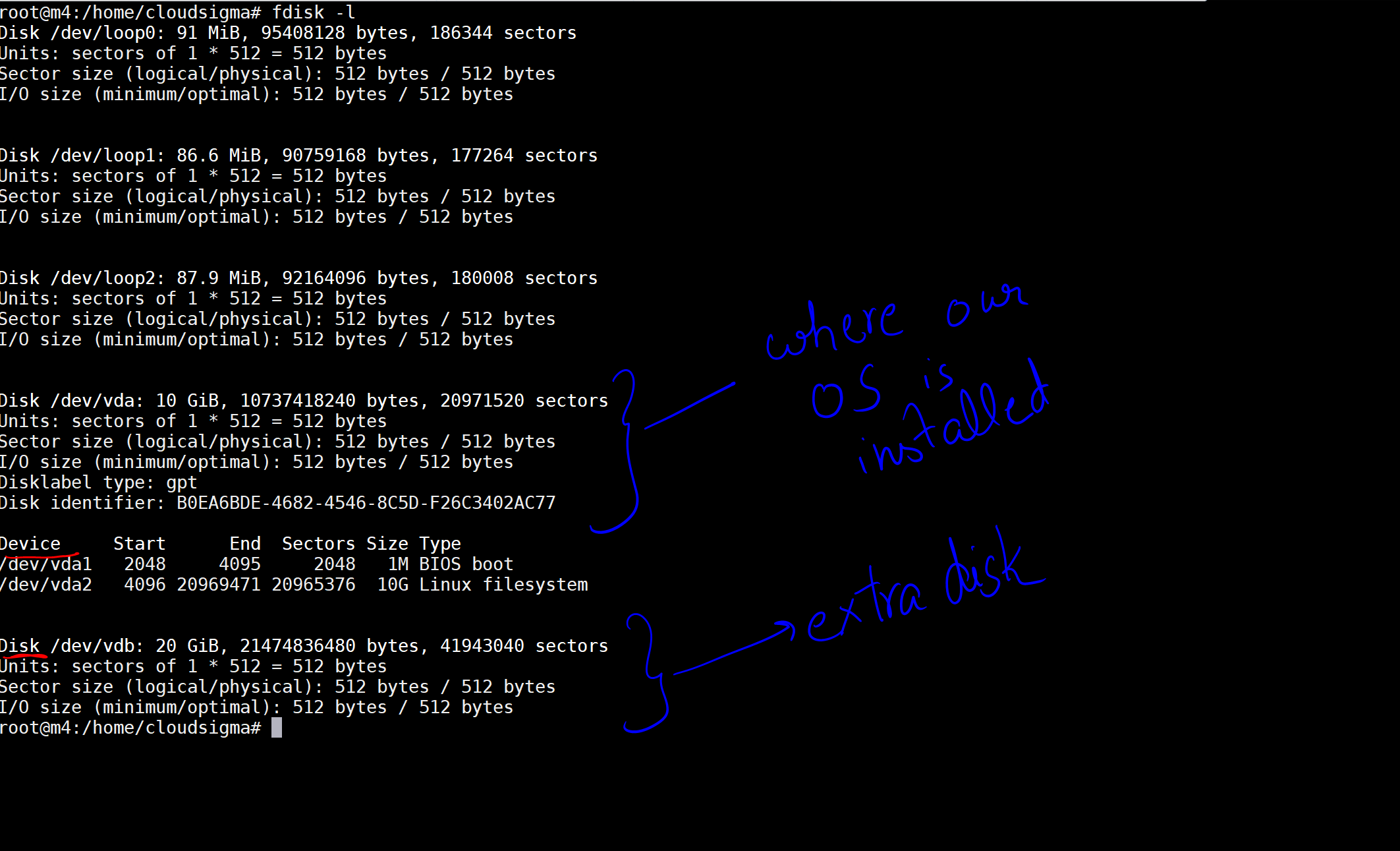
Nell'immagine, ho contrassegnato un disco da 10 GB come quello in cui è installato il nostro sistema operativo. Poi c'è un altro disco da 20 GB che è stato appena collegato. La posizione del disco è /dev/vdb. Puoi creare una partizione su questo disco utilizzando i seguenti comandi:
|
1 |
sudo fdisk /dev/vdb |
Questo aprirà l'utility fdisk, un'utilità da riga di comando che fornisce funzioni di partizionamento del disco, in cui è possibile creare partizioni sul nostro disco. Verrà visualizzato il prompt “Command (m for help):” in cui è necessario inserire n per creare una nuova partizione, e poi continuare a premere invio per accettare i valori predefiniti. E dopo aver creato la partizione, inserisci w per scrivere le modifiche. Apparirà così:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Comando (m per aiuto): <strong>n</strong> Partizione tipo p primaria (0 primaria, 0 estesa, 4 libera) e estesa (contenitore per logiche partizioni) Seleziona (predefinito p): Utilizzo predefinita risposta p. Partizione numero (1-4, predefinito 1): Primo settore (2048-41943039, predefinito 2048): Ultimo settore, +settori o +dimensione{K,M,G,T,P} (2048-41943039, predefinito 41943039): Creata una nuova partizione 1 di tipo 'Linux' e di dimensione 20 GiB. Comando (m per aiuto): <strong>w</strong> La tabella delle partizioni è stata modificata. Chiamata a ioctl() per ri-leggere la tabella delle partizioni. Sincronizzazione dei dischi. |
È stata creata una nuova partizione 1 di tipo ‘Linux’ e di dimensioni pari a 20 GiB. Ora che la partizione è stata creata, creiamo un pool LVM:
|
1 2 3 |
sudo pvcreate /dev/vdb1 sudo vgcreate mongodb /dev/vdb1 sudo lvcreate -n db -L 19.5g mongodb |
Ho inserito ‘19.5g’ poiché la dimensione della mia partizione è di 20g. Successivamente, esegui il seguente comando per scoprire il nome del disco:
|
1 |
fdisk -l | grep mongo | awk '{print $2'} |
Dopodiché, formatta il disco utilizzando il metodo ext4 con il seguente comando:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
sudo mkfs.ext4 /dev/mapper/mongodb-db Output: root@m4:/home/cloudsigma# sudo mkfs.ext4 /dev/mapper/mongodb-db mke2fs 1.44.1 (24-Mar-2018) Creazione del filesystem con 5217280 4k blocchi e 1305600 inode Filesystem UUID: 695a62e6-021d-4fc0-945c-cc51a92d86da Backup dei superblock memorizzati sui blocchi: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 Allocazione delle tabelle dei gruppi: fatto Scrittura delle tabelle degli inode: fatto Creazione dei blocchi del (32768 journal): fatto Scrittura dei superblock e delle informazioni di accounting del filesystem: fatto |
Successivamente, creiamo una posizione in cui montare il disco e una cartella in cui conservare i dati di MongoDB.
|
1 |
sudo mkdir -p /mongodb/data |
Per aggiungere una voce a fstab relativa al nuovo disco da montare, puoi utilizzare direttamente il comando seguente:
|
1 |
echo -e "` blkid | grep mongodb | awk {'print $2'}`\t/mongodb\text4 auto,noexec,rw,sync,nouser\t0\t0" >> /etc/fstab |
Nel comando, blkid fornisce un UUID – Universally Unique Identifier (identificatore univoco universale) per ciascun disco. Qui estraggo tramite grep quello per il disco di MongoDB e unisco questo UUID rispettivamente con la posizione della cartella di montaggio, il tipo di filesystem e altre opzioni per il disco. Sto aggiungendo questa riga a /etc/fstab. Se non lo fai, riceverai un errore durante il montaggio del disco. La voce si presenta così:
UUID=”695a62e6-021d-4fc0-945c-cc51a92d86da” /mongodb ext4 auto,noexec,rw,sync,nouser 0 0
Ora puoi montare il disco nella posizione /mongodb:
|
1 |
sudo mount /mongodb |
Installazione di MongoDB
Con il sistema preparato, passiamo all'installazione di MongoDB. Sebbene Ubuntu offra una versione di MongoDB nel proprio repository, ti consiglio di utilizzare invece la versione ufficiale di MongoDB. Il motivo è che il repository di Ubuntu è piuttosto indietro con le versioni, quindi se vuoi ottenere il massimo da MongoDB, dovrai ricorrere alle versioni ufficiali.
Poiché MongoDB offre il proprio repository, puoi semplicemente aggiungerlo al tuo sistema e poi installare MongoDB normalmente. Ecco i passaggi da seguire:
Per prima cosa, importa la chiave pubblica utilizzata dal sistema di gestione dei pacchetti:
|
1 |
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4 |
Quindi, creo un file di elenco. Questo conterrà il repository in cui si trova MongoDB, in modo che il tuo sistema possa scaricarlo da lì:
|
1 |
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list |
Ora sto aggiornando il database dei pacchetti locale per tenere conto delle modifiche.
|
1 |
sudo apt-get update |
Ora posso semplicemente installare il pacchetto utilizzando il comando seguente:
|
1 |
sudo apt-get install -y mongodb-org |
Ho installato MongoDB su ciascuna delle macchine.
|
1 |
sudo service mongod start |
Ora MongoDB è attivo e funzionante, con i dati sull'unità creata. Se si prevede un carico pesante e/o molte connessioni, potrebbe essere necessario aumentare i valori di ulimit.
Se desideri ottenere maggiori informazioni sui tuoi dati, potresti anche voler registrarti a MMS, che è un servizio di monitoraggio gratuito basato su cloud per MongoDB.
Creazione del Replica Set per il tuo Cloud MongoDB
Ora creiamo un replica set. Prima di ciò, devi assicurarti che ciascuna delle macchine possa comunicare con le altre. A tale scopo, aggiungeremo queste voci in /etc/hosts
|
1 2 3 |
IP-1 m1.mongo.cluster m1 IP-2 m2.mongo.cluster m2 IP-3 m3.mongo.cluster m3 |
Per verifica, puoi provare a fare il ping delle macchine usando l'hostname. Quindi, se l'IP della mia macchina 1 è IP-1, ad esempio, 213.189.123.12, invece di scrivere
|
1 |
ping 123.189.123.12 |
scriverò,
|
1 2 3 |
ping m1.mongo.cluster o ping m1. |
Se hai attivato il firewall (cosa che dovresti assolutamente fare), assicurati che i nodi possano inviare e ricevere traffico TCP sulle porte 28017 e 27017 sull'interfaccia interna.
Ora, su ciascuna macchina, procedi e avvia il servizio mongod usando i seguenti comandi.
Sulla macchina m1,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m1.mongo.cluster |
Successivamente, sulla macchina m2,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m2.mongo.cluster |
Sulla macchina m3,
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m3.mongo.cluster |
Qui,
mongod è il nome del servizio
dbpath è la posizione della directory del nostro database
replSet è il nome del nostro set di repliche. Dovrebbe essere lo stesso per ciascuna delle macchine nello stesso set di repliche
bind_ip è l'hostname della macchina su cui lo stai eseguendo.
Una volta avviato il servizio mongod, vai sul server primario (nel mio caso ho scelto m1) ed esegui mongo.
|
1 |
mongo |
Avvierà il terminale MongoDB. Sul terminale, avvia il replicaSet usando il comando seguente. Creerà il replicaSet con le configurazioni predefinite:
|
1 |
rs.initiate() |
Ora, aggiungiamo semplicemente le altre due macchine come repliche usando i seguenti comandi:
|
1 2 |
rs.add("m2.mongo.cluster") rs.add("m3.mongo.cluster") |
Puoi monitorare lo stato usando il comando:
|
1 |
rs.status() |
Questo è davvero tutto. Ora dovresti essere operativo con il tuo cluster MongoDB sul velocissimo cloud di CloudSigma’s.
Commenti
Ancora nessun commento. Scrivi il primo.