

L'Elastic Stack (precedentemente noto come ELK Stack) è una potente soluzione per la centralizzazione dei log. Si tratta di una raccolta di software open-source sviluppata da Elastic. Consente agli amministratori di cercare, analizzare e visualizzare i log generati da qualsiasi sorgente in qualsiasi formato. È una pratica nota come centralizzazione dei log. La centralizzazione dei log può essere molto utile quando si cerca di individuare problemi con server e applicazioni, poiché consente di effettuare ricerche in tutti i log da un unico punto. Può anche aiutare a identificare problemi su più server correlando i log in un momento specifico.
In questa guida, scopri come installare l'Elastic Stack su Ubuntu 18.04. Per prima cosa, segui il nostro tutorial per installare facilmente il tuo server Ubuntu su CloudSigma.
L'Elastic Stack su Ubuntu
L'Elastic Stack è composto dai seguenti componenti:
- Elasticsearch: un motore di ricerca RESTful distribuito. Memorizza tutti i dati raccolti.
- Logstash: La parte di elaborazione dati dell'Elastic Stack. Invia i dati in entrata a Elasticsearch.
- Kibana: Un'interfaccia web che offre funzionalità di ricerca e visualizzazione dei log.
- Beats: Un trasmettitore di dati leggero e monouso. Può inviare dati da numerose macchine a Logstash o Elasticsearch.
Sarà necessario installare manualmente ogni componente dello stack.
Prerequisiti
Prima di procedere con l'installazione di dell'Elastic Stack, devono essere soddisfatti diversi requisiti di sistema:
- Requisiti hardware:
- CPU: 2 CPU (accessibili da un utente sudo non root)
- RAM: 4GB
- OpenJDK 11 (l'ultima versione Java LTS). Per installarlo, dai un'occhiata al nostro tutorial su come configurare Java su Ubuntu 18.04.
- Nginx con le configurazioni appropriate. Puoi seguire la nostra guida per installare Nginx su Ubuntu 18.04 per configurarlo.
Nota che la quantità di spazio di archiviazione dipende dal numero di log da raccogliere e memorizzare. Inoltre, l'Elastic Stack gestisce anche informazioni preziose sul server. Per mantenere sicura la trasmissione dei dati, consigliamo vivamente di configurare un certificato TLS/SSL. Segui questo tutorial per acquisire un certificato SSL gratuito sul tuo server Nginx.
Oltre a un server crittografato, saranno necessari anche i seguenti passaggi:
- Un FQDN (fully qualified domain name). In questa guida, sarà <domain>.
- Entrambi i record DNS dei seguenti domini puntano al server.
- Un record A con <domain> che punta all'IP pubblico del server.
- Un record A con www.<domain> che punta all'IP pubblico del server.
Installazione dell'Elastic Stack
-
Configurazione del repository Elastic
I componenti dell'Elastic Stack non sono disponibili direttamente dal repository ufficiale di Ubuntu. Fortunatamente, Ubuntu consente a repository di 3e parti di installare pacchetti. Per il nostro scopo, aggiungeremo il repository dei pacchetti Elastic. Il repository offre tutti gli ultimi aggiornamenti di tutti i pacchetti Elastic. Tutti i pacchetti Elastic sono firmati con la chiave di firma di Elasticsearch per prevenire la falsificazione dei pacchetti. Per prima cosa, aggiungi la chiave al portachiavi di Ubuntu:
|
1 |
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - |
Quindi, aggiungi l'elenco dei sorgenti Elastic nella directory “sources.list.d”. È la directory dedicata che APT utilizza per cercare nuovi sorgenti:
|
1 |
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list |
Infine, aggiorna la cache di APT:
|
1 |
sudo apt update |
Secondo la documentazione ufficiale, si raccomanda di installare ciascuno dei componenti nell'ordine mostrato in questa guida. Ciò garantisce che i componenti da cui dipende ciascun prodotto si trovino nel posto giusto.
-
Installazione e configurazione di Elasticsearch
Una volta configurato il repository Elastic, APT è pronto per scaricare e installare tutti i pacchetti Elastic. Esegui il seguente comando per installare Elasticsearch:
|
1 |
sudo apt install elasticsearch |
Ora puoi configurare Elasticsearch. Il file “elasticsearch.yml” fornisce opzioni di configurazione relative a cluster, nodi, percorsi, reti, memoria, gateway e altro. La maggior parte di esse è preconfigurata nel file. Successivamente, apri il file di configurazione di Elasticsearch con un editor di testo a tua scelta:
|
1 |
sudo vim /etc/elasticsearch/elasticsearch.yml |
Elasticsearch è in ascolto sulla porta 9200 da qualsiasi indirizzo. Consigliamo di limitare l'accesso esterno a Elasticsearch per impedire a utenti esterni di leggere i dati o arrestare i cluster Elasticsearch tramite la sua API REST. Per limitare l'accesso a Elasticsearch e rafforzarne la sicurezza, decommenta la riga seguente e sostituisci il suo valore:
|
1 |
network.host: localhost |
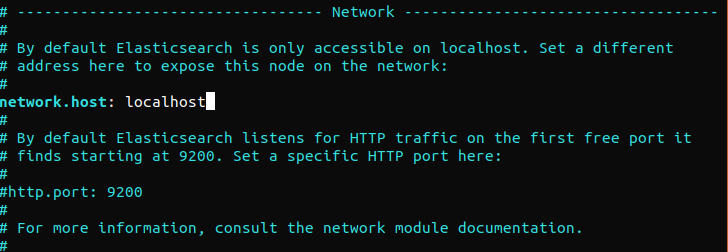
Se Elasticsearch deve essere in ascolto su un indirizzo IP specifico, sostituisci “localhost” con l'indirizzo IP di destinazione. Questo è il requisito minimo di configurazione prima di avviare Elasticsearch. Salva e chiudi il file di configurazione. Successivamente, avvia il servizio Elasticsearch. Potrebbe essere necessario qualche istante per avviare Elasticsearch:
|
1 |
sudo systemctl start elasticsearch |
Dopodiché, devi assicurarti che Elasticsearch si avvii a ogni avvio del server:
|
1 |
sudo systemctl enable elasticsearch |
Il comando seguente verificherà se il servizio Elasticsearch è in esecuzione. Tutto ciò che richiede è l'invio di una richiesta HTTP:
|
1 |
curl -X GET "localhost:9200" |
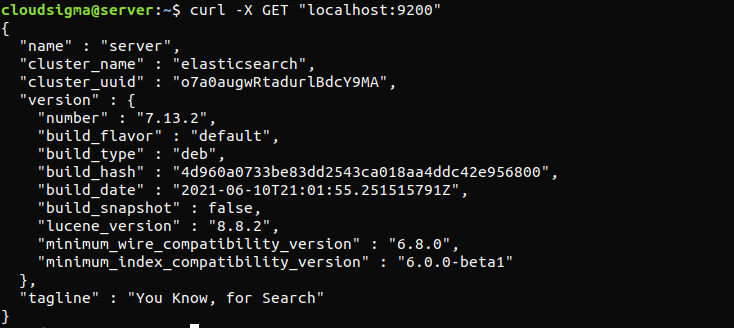
La risposta sarà simile a questa. Sarà una risposta che mostra alcune informazioni di base sul nodo locale.
Installazione e configurazione della dashboard di Kibana
Kibana è disponibile direttamente dal repository di Elastic. Nota che dovresti installare Kibana solo dopo aver già installato Elasticsearch. Supponendo che il repository sia già disponibile, APT può scaricare e installare direttamente Kibana:
|
1 |
sudo apt install kibana |
Una volta installato, abilita e avvia il servizio Kibana:
|
1 2 |
sudo systemctl enable kibana sudo systemctl start kibana |
Per impostazione predefinita, Kibana è configurato per essere in ascolto solo su “localhost”. Per l'accesso esterno, richiede la configurazione di un reverse proxy. Qui, Nginx sarà il reverse proxy. Usa il comando openssl per creare un utente amministratore di Kibana. Sarà l'account utente per accedere all'interfaccia web di Kibana. Qui, il nome utente di esempio sarà “kibana_admin”. Per garantire una migliore sicurezza, consigliamo di utilizzare un nome utente non standard. Il comando seguente creerà un utente amministratore per Kibana. Il nome utente e la password verranno generati e memorizzati nel file “htpasswd.users”. Nginx dovrà essere configurato per utilizzare il nome utente e la password:
|
1 |
echo "kibana_admin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users |
Inserisci e conferma una password al prompt. Questa password sarà importante per accedere all'interfaccia di Kibana. Dopodiché, devi creare un file di blocco server Nginx. A scopo dimostrativo, sarà example.com. Può anche essere qualsiasi altro nome descrittivo. Se per il server sono configurati record FQDN e DNS, il nome del file può anche corrispondere all'FQDN:
|
1 |
sudo vim /etc/nginx/sites-available/example.com |
Se è presente del contenuto preesistente, rimuovilo e sostituiscilo con le seguenti righe di codice:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
server { listen 80; server_name example.com; auth_basic "Accesso limitato"; auth_basic_user_file /etc/nginx/htpasswd.users; location / { proxy_pass http://localhost:5601; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } } |
Salva e chiudi il file. Crea un collegamento simbolico della nuova configurazione nella directory “sites-enabled”. Se esiste già un collegamento preesistente con lo stesso nome file, questo passaggio potrebbe non essere necessario:
|
1 |
sudo ln -s /etc/nginx/sites-available/example.com /etc/nginx/sites-enabled/example.com |
Il comando seguente chiederà a Nginx di verificare se ci sono errori di sintassi:
|
1 |
sudo nginx -t |
In caso di problemi di sintassi, assicurati che i contenuti del file siano stati inseriti correttamente. Successivamente, riavvia il servizio Nginx:
|
1 |
sudo systemctl restart nginx |
Dì a UFW di consentire la connessione a Nginx:
|
1 |
sudo ufw allow 'Nginx Full' |
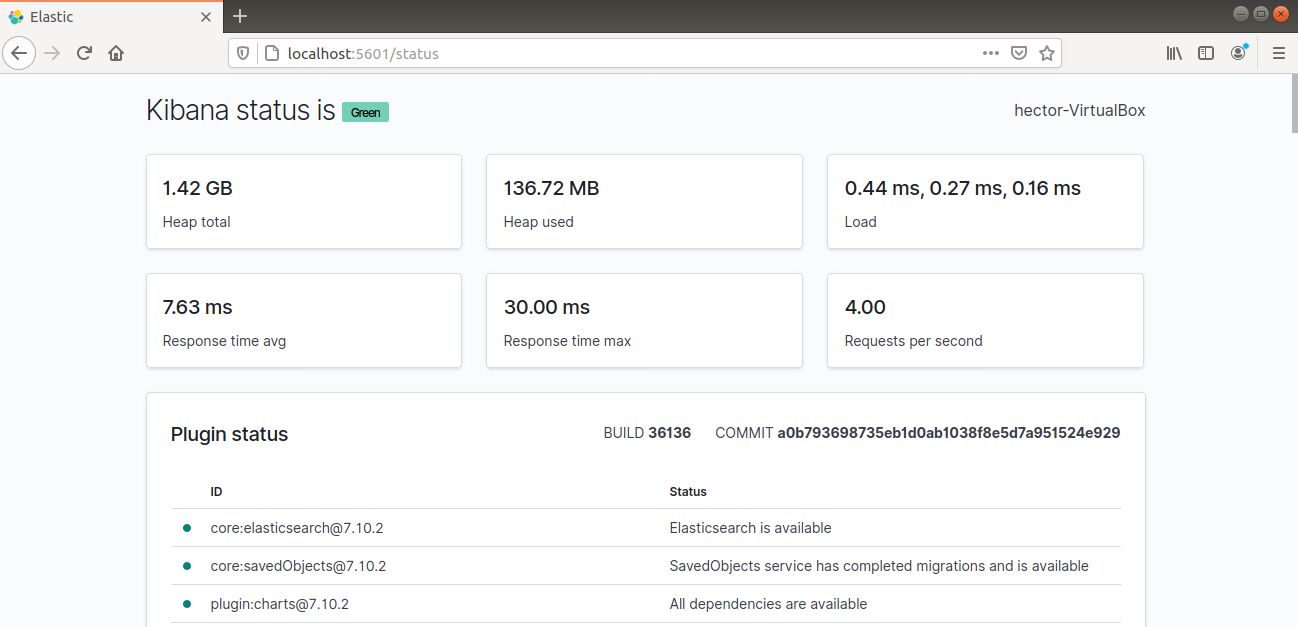
Kibana dovrebbe ora essere accessibile tramite l'FQDN o l'indirizzo IP pubblico del server Elastic Stack. Controlla la pagina di stato del server Kibana:
|
1 |
http://<server_ip>:5601/status |
Installazione e configurazione di Logstash
Sebbene Beats possa inviare direttamente i dati al database di Elasticsearch’s, si consiglia di utilizzare Logstash per l'elaborazione dei dati. Logstash può raccogliere i dati e convertirli in un formato comune prima di esportarli in un altro database. Esegui il seguente comando APT per installare Logstash:
|
1 |
sudo apt install logstash |
Una volta completata l'installazione, è il momento di configurare Logstash. I file di configurazione di Logstash sono in formato JSON. Puoi trovarli tutti nella directory “/etc/logstash/conf.d”. È utile pensare a Logstash come a una pipeline, che riceve i dati da un'estremità, li elabora e li invia alla destinazione. Una pipeline di Logstash richiede due elementi obbligatori – input e output con un elemento opzionale – filter. Il plugin di input riceve i dati, il filter plugin elabora i dati e il output plugin scrive i dati nella destinazione. Il comando seguente creerà un file di configurazione che imposterà Logstash per l'input di Filebeat:
|
1 |
sudo vim /etc/logstash/conf.d/02-beats-input.conf |
Inserisci la seguente configurazione di input. Descrive un input beats che rimarrà in ascolto sulla porta 5044 su TCP:
|
1 2 3 4 5 |
input { beats { port => 5044 } } |
Il passaggio successivo consiste nel creare un file di configurazione chiamato “10-syslog-filter.conf”. Lo useremo per impostare un filtro per syslogs (log di sistema):
|
1 |
sudo vim /etc/logstash/conf.d/10-syslog-filter.conf |
Inserisci il seguente codice di configurazione di syslog. Questo codice è disponibile direttamente dalla Elastic guide. Questo codice spiega la configurazione di input per Logstash:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
input{ beats{ porta => 5044 host => "0.0.0.0" } } filtro { se [fileset][modulo] == "sistema" { se [fileset][nome] == "autenticazione" { grok { corrispondenza => { "messaggio" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] } pattern_definitions => { "GREEDYMULTILINE"=> "(.|\n)*" } remove_field => "message" } date { match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } geoip { source => "[system][auth][ssh][ip]" target => "[system][auth][ssh][geoip]" } } else if [fileset][name] == "syslog" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] } pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" } remove_field => "message" } date { match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } } } } |
Il prossimo file di configurazione si occuperà dell'output. Apri un nuovo file chiamato “30-elasticsearch-output.conf:”
|
1 |
sudo vim /etc/logstash/conf.d/30-elasticsearch-output.conf |
Inserisci il seguente codice. Questo codice spiega la configurazione dell'output per Logstash:
|
1 2 3 4 5 6 7 |
output { elasticsearch { hosts => ["localhost:9200"] manage_template => false index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" } } |
Verifica la configurazione di Logstash. Quindi, esegui il seguente comando:
|
1 |
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t |
Se non ci sono errori, Logstash stamperà il seguente messaggio di successo. Se non ha avuto successo, assicurati che tutti i file di configurazione contengano i codici corretti. Infine, avvia e abilita il servizio Logstash:
|
1 2 |
sudo systemctl start logstash sudo systemctl enable logstash |
Ora che Logstash è in esecuzione con successo ed è completamente configurato, installiamo Filebeat.
Installazione e configurazione di Filebeat
Elastic Stack utilizza dei mittenti di dati, noti come “Beats”, per raccogliere dati da varie sorgenti e trasportarli a Logstash/Elasticsearch. Ecco un breve elenco dei Beats disponibili da Elastic:
- Filebeat: Raccolta/invio di file di log.
- Metricbeat: Raccolta/invio di metriche da sistemi e servizi.
- Packetbeat: Raccolta/analisi di dati di rete.
- Winlogbeat: Raccolta di log degli eventi di Windows.
- Auditbeat: Raccolta di dati del framework di audit di Linux e monitoraggio dell'integrità dei file.
- Heartbeat: Monitoraggio della disponibilità dei servizi.
Ai fini di questo tutorial, avremo bisogno di Filebeat per inviare i log locali a Elastic Stack. Per prima cosa, installa Filebeat:
|
1 |
sudo apt install filebeat |
Ora puoi configurare Filebeat. Innanzitutto, deve connettersi a Logstash. Utilizzeremo la configurazione di esempio fornita con Filebeat. Apri il file di configurazione in un editor di testo. Nota che poiché il file è in formato YAML, una corretta rientranza è importante:
|
1 |
sudo vim /etc/filebeat/filebeat.yml |
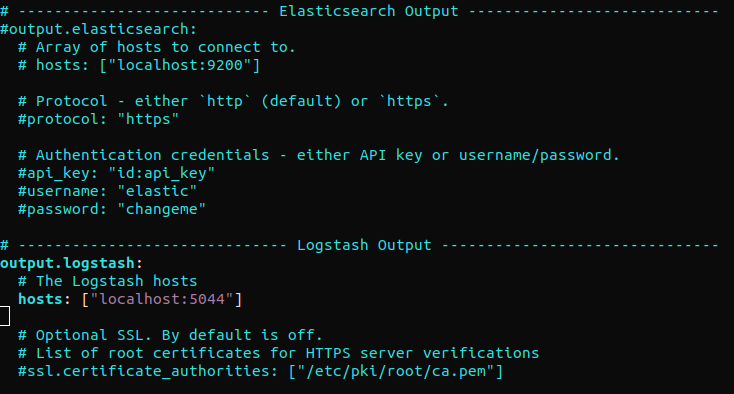
Trova la sezione “output.elasticsearch” e commenta le seguenti righe. Questo configurerà Filebeat per inviare direttamente gli eventi a Elasticsearch/Logstash per un'ulteriore elaborazione. Successivamente, passa alla sezione “output.logstash.” Quindi, decommenta le righe:
|
1 2 3 4 5 6 7 |
#output.elasticsearch: # Array di host a cui connettersi. # hosts: ["localhost:9200"] output.logstash: # Gli host Logstash hosts: ["localhost:5044"] |
Filebeat supporta moduli che possono estendere le sue funzionalità. In questo tutorial, utilizzeremo il modulo system che raccoglie e analizza i log generati dal servizio di logging di sistema delle comuni distribuzioni Linux. Abilita il modulo system di Filebeat:
|
1 |
sudo filebeat modules enable system |
Il seguente comando Filebeat elencherà tutti i moduli abilitati e disabilitati:
|
1 |
sudo filebeat modules list |
Per impostazione predefinita, Filebeat è configurato per seguire i percorsi predefiniti per i log di syslog e di autorizzazione. I parametri dei moduli sono disponibili nel file di configurazione “/etc/filebeat/modules.d/system.yml”.
Il passo successivo consiste nel caricare il modello di indice in Elasticsearch. Un indice Elasticsearch indica una raccolta di documenti che condividono caratteristiche simili. Ogni indice ha un nome. Il nome è necessario quando si eseguono varie operazioni al suo interno. Il modello di indice viene applicato automaticamente ogni volta che viene generato un nuovo indice. Successivamente, carica il modello:
|
1 |
sudo filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]' |
Filebeat contiene una dashboard di esempio per Kibana per impostazione predefinita. Aiuta a visualizzare i dati di Filebeat in Kibana. Tuttavia, prima di utilizzare la dashboard, è necessario creare il pattern di indice e caricare le dashboard in Kibana. Mentre le dashboard si caricano, Filebeat contatta Elasticsearch per informazioni sulla versione. Per caricare le dashboard, mentre Logstash è abilitato, è necessario avere l'output di Logstash disabilitato e l'output di Elasticsearch abilitato. Il seguente comando eseguirà l'operazione:
|
1 |
sudo filebeat setup -e -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601 |
Infine, puoi avviare Filebeat:
|
1 2 |
sudo systemctl start filebeat sudo systemctl enable filebeat |
Ora è il momento di testare la configurazione di Elastic Stack. Se è stata configurata correttamente, l'output sarà simile a questo:
|
1 |
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty' |
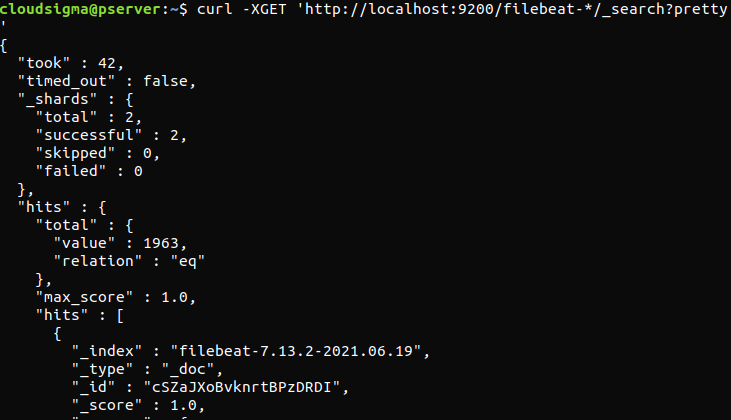
Se l'output riporta 0 hit totali, Elasticsearch non sta caricando alcun log nell'indice che abbiamo cercato. Ciò indica che si è verificato un errore con la configurazione. Se l'output è quello previsto, allora Elastic Stack è configurato correttamente.
Panoramica delle dashboard di Kibana
Ora è il momento di esplorare l'interfaccia web di Kibana che abbiamo già installato. Innanzitutto, apri la dashboard di Kibana. Dovrebbe trovarsi all'FQDN o all'indirizzo IP pubblico del server Elastic Stack:
|
1 |
http://<server_ip>:5601 |
Inserisci le credenziali di accesso che abbiamo generato in precedenza. Una volta effettuato l'accesso, la dashboard apparirà così:
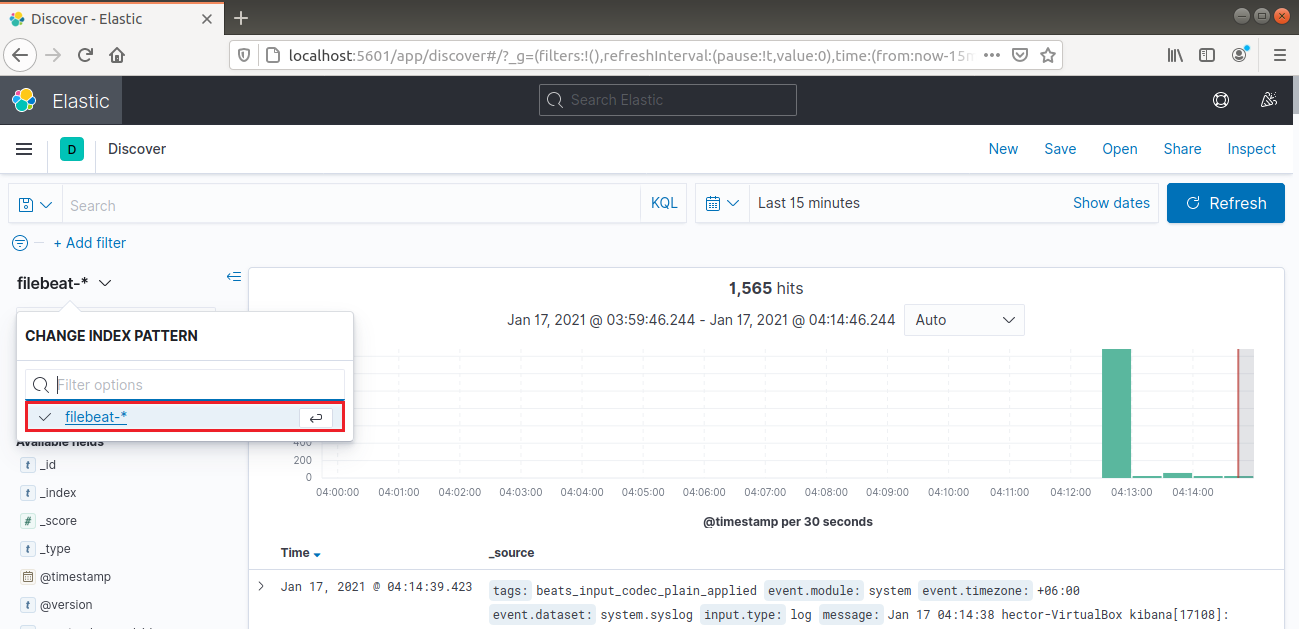
Dalla barra di navigazione a sinistra, seleziona “Discover”. Quindi, seleziona il pattern “filebeat-*”. Mostra tutti i log raccolti negli ultimi 15 minuti. È possibile cercare e sfogliare i log e personalizzare la dashboard:
Dalla barra di navigazione a sinistra, vai su Dashboard >> Filebeat System. Qui sono disponibili tutte le dashboard di esempio del modulo di sistema di Filebeat.
Nel seguente esempio, vengono dettagliate varie statistiche basate sui messaggi di syslog:
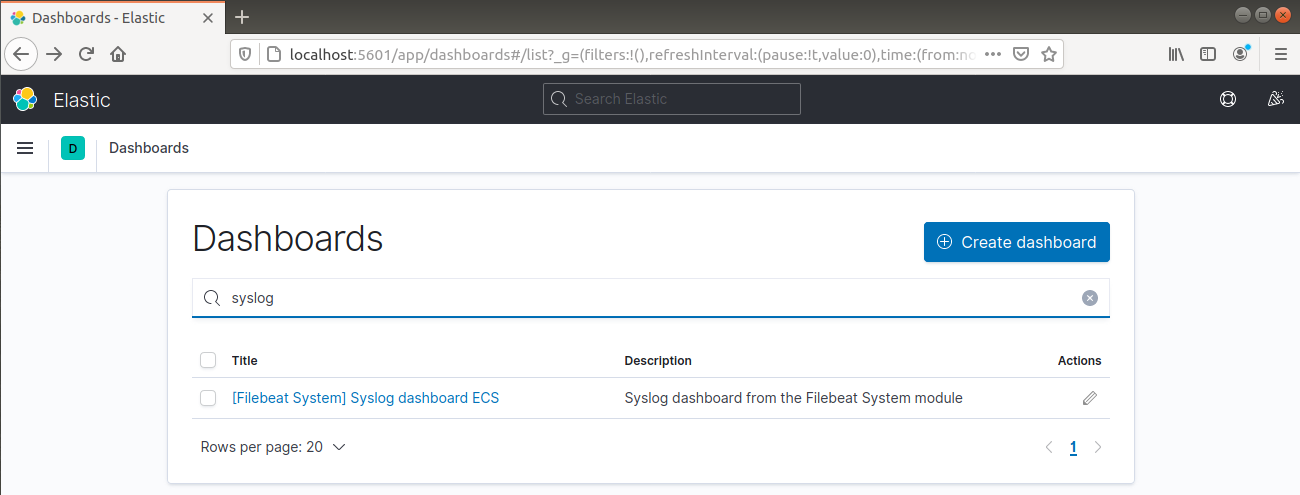
Può anche segnalare quali utenti hanno eseguito comandi con sudo:
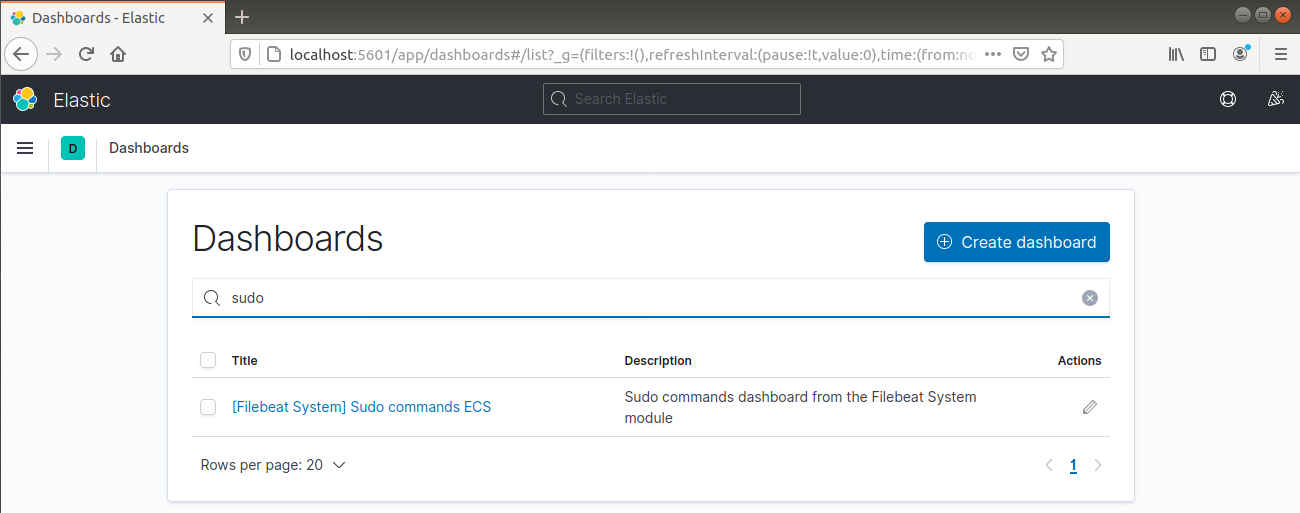
Infine, Kibana ti offre l'opportunità di esplorare molte altre funzionalità come grafici e filtri, quindi sentiti libero di esplorare da solo.
Considerazioni finali
Elastic Stack è una soluzione potente per l'analisi dei log di sistema. Tieni presente che, sebbene qualsiasi log o dato indicizzato possa essere inviato a Logstash utilizzando Beats, diventa più utile quando viene analizzato e strutturato attraverso i filtri di Logstash.
Buon divertimento con l'informatica!
Commenti
Ancora nessun commento. Scrivi il primo.