

Questo tutorial ti guiderà nella configurazione di un Kubernetes cluster da zero utilizzando Ansible e Kubeadm e successivamente nel distribuire un'applicazione Nginx containerizzata con esso.
Introduzione
Kubernetes (noto anche come k8s o “kube”) è una piattaforma di orchestrazione di container open-source che automatizza molti dei processi manuali coinvolti nella distribuzione, gestione e scalabilità delle applicazioni containerizzate. Kubernetes ha una comunità open-source in rapida crescita, che contribuisce attivamente al progetto. Dai un'occhiata al nostro post sul blog che ti introdurrà a tutto ciò che c'è da sapere su le basi della piattaforma Kubernetes.
Kubeadm è uno strumento che configura diversi elementi, parti e componenti integrati come l'API server, il Controller Manager e Kube DNS. Aiuta anche ad automatizzare l'installazione. Tuttavia, non crea utenti né gestisce l'installazione delle dipendenze a livello di sistema operativo e la loro configurazione, e non può effettuare il provisioning della tua infrastruttura.
Ansible è uno strumento open-source per il provisioning del software e la distribuzione delle applicazioni. Saltstack è un software open-source per l'automazione dell'information technology guidata dagli eventi. Questi sono i due strumenti che rendono la creazione di cluster aggiuntivi o la ricreazione di cluster esistenti meno vulnerabile agli errori e possono essere utilizzati per queste attività preliminari.
Obiettivi:
Il tuo cluster includerà le seguenti risorse fisiche:
1. Un nodo master:
Un nodo master è un nodo che controlla e gestisce un insieme di nodi worker (runtime dei carichi di lavoro) e assomiglia a un cluster in Kubernetes. Contiene anche il piano delle risorse del nodo per determinare l'azione appropriata per l'evento attivato. Esegue etcd, un archivio chiave-valore distribuito open-source utilizzato per conservare e gestire i dati del cluster tra i componenti che pianificano i carichi di lavoro sui nodi worker.
Ad esempio, lo scheduler determinerebbe quale nodo worker ospiterà un POD appena pianificato.
2. Due nodi worker:
I nodi worker sono i nodi che continuano con il lavoro assegnato anche se il nodo master si arresta una volta completata la pianificazione. I nodi worker sono i server in cui verranno eseguiti i tuoi carichi di lavoro (ovvero applicazioni e servizi containerizzati). Puoi anche aumentare la capacità del cluster aggiungendo worker.
Una volta completato questo tutorial, avrai un cluster completamente funzionante pronto per eseguire carichi di lavoro (ovvero applicazioni e servizi containerizzati), presupponendo che i server nel cluster dispongano di risorse CPU e RAM sufficienti per l'esecuzione delle tue applicazioni. Dopo aver configurato correttamente il cluster, potrai eseguire quasi tutte le tradizionali applicazioni UNIX. Potrebbero essere containerizzate sul tuo cluster, incluse applicazioni web, database, daemon e strumenti da riga di comando.
Il cluster stesso consumerà circa 300-500 MB di memoria e il 10% di CPU su ciascun nodo.
Prerequisiti:
- Devi avere una coppia di chiavi SSH sulla tua macchina Linux locale e sapere come utilizzare le chiavi SSH. Tuttavia, se non hai mai usato le chiavi SSH prima d'ora, puoi consultare questo tutorial per aiutarti a configurare le chiavi SSH sulla tua macchina locale.
- Tre server con Ubuntu 18.04 con almeno 4 GB di RAM e 4 vCPU ciascuno. Dovresti essere in grado di accedere in SSH a ciascun server come utente root con la tua coppia di chiavi SSH. Segui questo tutorial per installare il tuo server Ubuntu.
- Ansible installato sulla tua macchina locale.
- Devi anche avere familiarità con i playbook di Ansible.
- Dovrai anche sapere come avviare un container da un'immagine Docker. Guarda “Passo 5 — Lavorare con le immagini Docker in Ubuntu” in Come installare e utilizzare Docker su Ubuntu 18.04 se hai bisogno di un ripasso.
Passo 1 — Configurazione della directory dello spazio di lavoro e del file di inventario di Ansible
Per prima cosa devi configurare Ansible sulla tua macchina locale. Ti aiuterà a eseguire comandi sul tuo server remoto. Semplifica inoltre lo sforzo di distribuzione manuale automatizzandolo. Per questo, dovrai creare una directory sulla tua macchina locale che fungerà da area di archiviazione digitale temporanea (Spazio di lavoro).
Una volta creata una directory, creerai un hosts file per memorizzare tutte le informazioni sugli indirizzi IP e sul gruppo di ciascun server. Ti aiuterà a memorizzare le informazioni sull'inventario al suo interno. Come accennato in precedenza, ci saranno tre server, un master e due worker. Il server master sarà il master con un IP visualizzato come master_ip. Gli altri due server saranno worker e avranno gli IP worker_1_ip e worker_2_ip.
Devi creare una directory denominata ~/kube-cluster nella home directory della tua macchina locale ed entrare nella directory usando il comando cd:
|
1 2 |
mkdir ~/kube-cluster cd ~/kube-cluster |
La directory ~/kube-cluster fungerà ora da area di archiviazione digitale temporanea (workspace) all'interno della quale eseguirai tutti i comandi locali per creare un cluster Kubernetes utilizzando kubeadm. La directory conterrà tutti i tuoi playbook Ansible e verrà utilizzata per il resto del tutorial.
Creazione del file Hosts
Crea un file denominato ~/kube-cluster/hosts utilizzando nano o il tuo editor di testo preferito:
|
1 |
nano ~/kube-cluster/hosts |
Ora dovrai aggiungere il seguente testo, che specificherà le informazioni sulla struttura logica del tuo cluster:
|
1 2 3 4 5 6 7 8 9 |
[masters] master ansible_host=master_ip ansible_user=root [workers] worker1 ansible_host=worker_1_ip ansible_user=root worker2 ansible_host=worker_2_ip ansible_user=root [all:vars] ansible_python_interpreter=/usr/bin/python3 |
Come accennato, quel file di inventario ti aiuterà a memorizzare tutte le informazioni sugli indirizzi IP dei tuoi server e sui gruppi a cui appartiene ciascun server. ~/kube-cluster/hosts sarà il tuo file di inventario e (masters e workers) saranno i due gruppi Ansible che hai aggiunto ad esso specificando la struttura logica del tuo cluster.
Il Master è il gruppo che specifica che Ansible deve eseguire comandi remoti come utente root. Elenca anche l'IP del nodo master (master_ip) che può essere elencato dalla voce del server denominata “master”. Allo stesso modo, il gruppo Workers ha due voci per i server worker (worker_1_ip e worker_2_ip) che specificano anche ansible_user come root.
L'ultima riga del file indica ad Ansible di utilizzare gli interpreti Python 3 dei server remoti per le sue operazioni di gestione. Infine, devi salvare e chiudere il file dopo aver aggiunto il testo. Dopo aver configurato la directory del workspace e il file di inventario di Ansible, passiamo al passaggio successivo di installazione delle dipendenze a livello di sistema operativo e creazione delle impostazioni di configurazione.
Passaggio 2 — Creazione di un utente non root su tutti i server remoti
In questo passaggio, imparerai come creare un utente non root con privilegi sudo su tutti i server in modo da poterti connettere ad essi tramite SSH manualmente come utente non privilegiato.
Questo può essere utile per le operazioni eseguite di frequente per la preservazione di un cluster. Inoltre, questo passaggio ti aiuterà a eseguire l'attività in modo più accurato e con meno errori, riducendo le possibilità di alterare o eliminare involontariamente file importanti. Se desideri modificare la configurazione dei file di proprietà di root o visualizzare le informazioni di sistema con comandi come top/htop e visualizzare un elenco di container in esecuzione, il passaggio seguente ti aiuterà a eseguire tutte le attività.
Creazione del Playbook
Crea un file denominato ~/kube-cluster/initial.yml nel workspace:
|
1 |
nano ~/kube-cluster/initial.yml |
Successivamente, devi aggiungere il seguente play. Un play in Ansible è una raccolta di passaggi da eseguire che hanno come target server e gruppi specifici. Possono esserci uno o più play in un playbook.
Il seguente play creerà un utente sudo non root:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
- hosts: all become: yes tasks: - name: crea l' utente 'ubuntu' user: name=ubuntu append=yes state=present createhome=yes shell=/bin/bash - name: consenti a 'ubuntu' di avere sudo senza password lineinfile: dest: /etc/sudoers line: 'ubuntu ALL=(ALL) NOPASSWD: ALL' validate: 'visudo -cf %s' - name: configura le chiavi autorizzate per l'utente ubuntu authorized_key: user=ubuntu key="{{item}}" with_file: - ~/.ssh/id_rsa.pub |
Di seguito è riportata una descrizione dettagliata di ciò che fa il nostro playbook:
- Questo playbook creerà l'utente non root
ubuntu. - Poiché è necessario eseguire i comandi
sudosenza che venga richiesta la password, questo play configurerà il filesudoersper consentire all'utenteubuntudi farlo. - Lo scopo principale dell'attività precedente era consentirti di accedere in SSH a ciascun server come utente
ubuntu. Questo playbook aggiunge la chiave pubblica della tua macchina locale (di solito~/.ssh/id_rsa.pub) all'elenco delle chiavi autorizzate dell'utenteubunturemoto.
Ora, dopo aver aggiunto il testo, è necessario salvare e chiudere il file.
Esecuzione del playbook
Dopodiché, dobbiamo eseguire il nostro playbook che creerà l'utente non root ubuntu semplicemente eseguendo sulle macchine locali:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/initial.yml |
L'esecuzione di questo comando richiederà del tempo, dopodiché vedrai il seguente output:
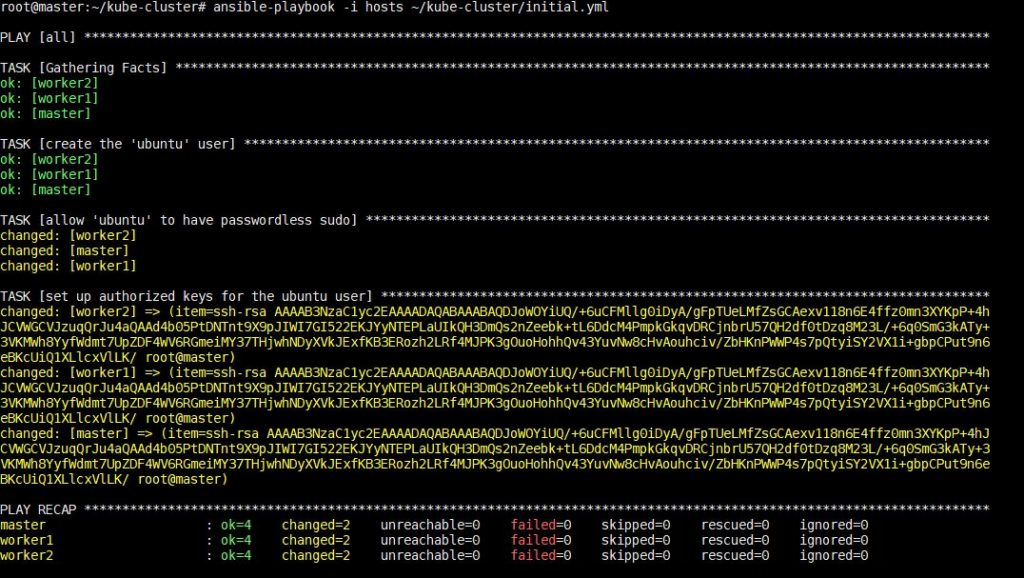
Una volta completato questo passaggio, puoi passare all'installazione delle dipendenze specifiche di Kubernetes nel passaggio successivo.
Passo 3 — Installazione delle dipendenze di Kubernetes
In questo passaggio, imparerai come installare i pacchetti a livello di sistema operativo richiesti da Kubernetes con il gestore dei pacchetti di Ubuntu.
Questi pacchetti sono:
- Docker: Docker è una piattaforma e uno strumento per creare, distribuire ed eseguire container Docker. Puoi configurare facilmente Docker seguendo il nostro tutorial su come installare & utilizzare Docker su Ubuntu nel cloud pubblico. Tuttavia, il supporto per altri runtime come rkt è in fase di sviluppo attivo in Kubernetes.
Kubeadm: kubeadm è uno strumento CLI che esegue le azioni necessarie per avviare e rendere operativo un cluster minimo vitale. Questo ti aiuterà a installare e compilare vari componenti del cluster in modo standard.kubelet: Il kubelet è l'“agente di nodo” primario che viene eseguito su ciascun nodo e gestisce le operazioni a livello di nodo.kubectl: kubectl è anche uno strumento CLI che comunica con il cluster e invia comandi tramite il suo API Server.
Creazione del playbook
Crea un file denominato ~/kube-cluster/kube-dependencies.yml nell'area di lavoro:
|
1 |
nano ~/kube-cluster/kube-dependencies.yml |
Ora devi aggiungere i seguenti play al file per installare questi pacchetti sui tuoi server:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
- hosts: all become: yes tasks: - name: installa Docker apt: name: docker.io state: present update_cache: true - name: installa APT Transport HTTPS apt: name: apt-transport-https state: present - name: aggiungi Kubernetes apt-key apt_key: url: https://packages.cloud.google.com/apt/doc/apt-key.gpg validate_certs: false state: present - name: aggiungi il repository APT di Kubernetes' APT repository apt_repository: repo: deb http://apt.kubernetes.io/ kubernetes-xenial main state: present filename: 'kubernetes' - name: installa kubelet apt: name: kubelet=1.16.0-00 state: present update_cache: true - name: installa kubeadm apt: name: kubeadm=1.16.0-00 state: present - hosts: master become: yes tasks: - name: installa kubectl apt: name: kubectl=1.16.0-00 state: present force: yes |
Il primo play nel playbook fa quanto segue:
- Questo play ti aiuterà a installare i pacchetti a livello di sistema operativo, Docker – il runtime del container.
- Installa
apt-transport-https, che consente di aggiungere sorgenti HTTPS esterne al tuo elenco di sorgenti APT. - Aggiunge la apt-key del repository APT di Kubernetes per la verifica delle chiavi.
- Aggiunge il repository APT di Kubernetes all'elenco delle sorgenti APT dei tuoi server remoti.
- Installa
kubeletekubeadm.
Il secondo play esegue un compito importante e singolo che include l'installazione di kubectl sul tuo nodo master. Ora, dopo aver aggiunto il testo, devi salvare e chiudere il file.
Esecuzione del playbook
Dopodiché, dobbiamo eseguire il nostro playbook semplicemente eseguendo sulle macchine locali:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/kube-dependencies.yml |
L'esecuzione di questo comando richiederà del tempo, dopodiché vedrai il seguente output:
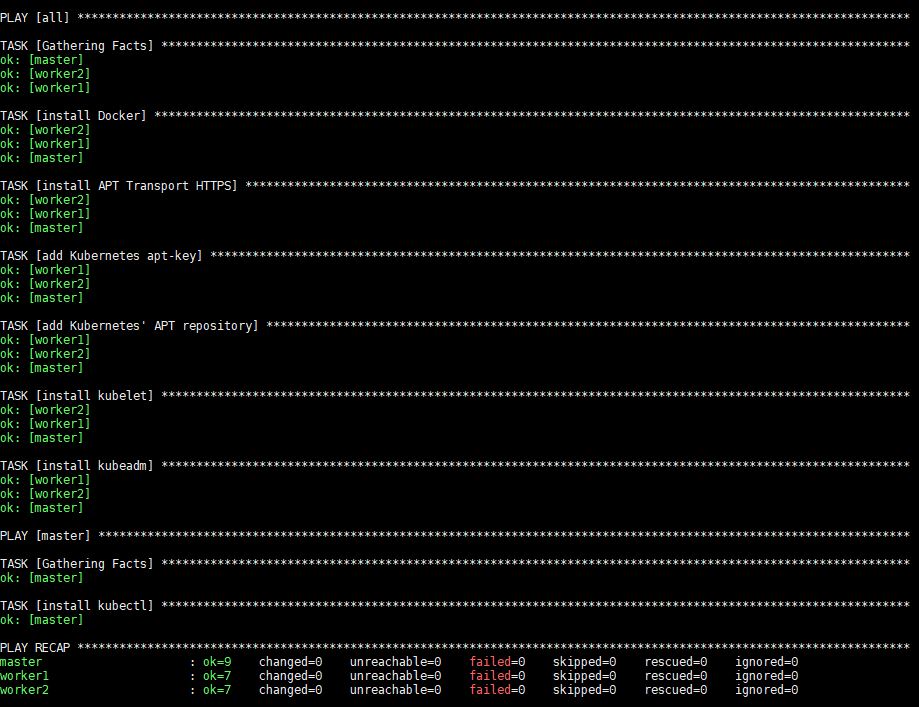
Dopo l'esecuzione, Docker, kubeadm e kubelet saranno installati su tutti i server remoti. Kubectl non è un componente richiesto ed è necessario solo per l'esecuzione dei comandi del cluster. Installarlo solo sul nodo master ha senso in questo contesto poiché eseguirai i comandi kubectl solo dal master. Nota, tuttavia, che kubectl i comandi possono essere eseguiti da qualsiasi nodo worker o da qualsiasi macchina in cui sia possibile installarli e configurarli per puntare a un cluster.
Tutte le dipendenze di sistema sono ora installate. Configuriamo il nodo master e inizializziamo il cluster.
Passo 4 — Configurazione del Nodo Master
In questo passo, imparerai alcuni concetti come Pod e Plugin di rete dei Pod poiché il tuo cluster includerà entrambi una volta configurato il nodo master.
I Pod sono gli oggetti distribuibili più piccoli e di base in Kubernetes. I Pod contengono uno o più container, come i container Docker. Quando un Pod esegue più container, i container vengono gestiti come una singola entità e condividono le risorse del Pod.
Ogni pod ha il proprio indirizzo IP e un pod su un nodo dovrebbe essere in grado di accedere a un pod su un altro nodo utilizzando l’IP del pod. Tuttavia, la comunicazione tra i pod è più complessa. Richiede un componente separato in grado di instradare in modo trasparente il traffico da un pod su un nodo a un pod su un altro. I plugin di rete dei pod vengono utilizzati per questa funzionalità. Sono disponibili molti plugin di rete dei pod, ma utilizzeremo Flannel in quanto è un'opzione stabile ed efficiente.
Creazione del Playbook
Crea un playbook Ansible chiamato master.yml sulla tua macchina locale:
|
1 |
nano ~/kube-cluster/master.yml |
Inoltre, devi aggiungere il seguente play al file per inizializzare il cluster e installare Flannel:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
- hosts: master become: yes tasks: - name: inizializza il cluster shell: kubeadm init --pod-network-cidr=10.244.0.0/16 >> cluster_initialized.txt args: chdir: $HOME creates: cluster_initialized.txt become: yes become_user: root - name: crea .kube directory become: yes become_user: ubuntu file: path: $HOME/.kube state: directory mode: 0755 - name: copia admin.conf nella configurazione 'kube dell'utente copy: src: /etc/kubernetes/admin.conf dest: /home/ubuntu/.kube/config remote_src: yes owner: ubuntu - name: installa la rete dei Pod become: yes become_user: ubuntu shell: kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/2140ac876ef134e0ed5af15c65e414cf26827915/Documentation/kube-flannel.yml >> pod_network_setup.txt args: chdir: $HOME creates: pod_network_setup.txt |
Ecco un’analisi di questo play:
- Il primo task in questo play configurerà il cluster eseguendo
kubeadm init. Per specificare la subnet privata a cui verranno assegnati gli IP dei pod, passiamo l'argomento--pod-network-cidr=10.244.0.0/16. Flannel utilizza la subnet sopra indicata per impostazione predefinita. Lo stiamo usando per dire akubeadmdi utilizzare la stessa subnet. - Il secondo task viene utilizzato per creare una directory
.kubein/home/ubuntu. Le informazioni di configurazione, come i file delle chiavi di amministrazione, necessari per connettersi al cluster, e l'indirizzo API del cluster, saranno contenute in questa directory. - Il terzo task viene utilizzato per copiare il file
/etc/kubernetes/admin.confgenerato dakubeadm initnella home directory del tuo utente non root. Questo ti permetterà di utilizzarekubectlper accedere al cluster appena creato. - L'ultimo task esegue
kubectl applyper installareFlannel.kubectl apply -f descriptor.[yml|json]è la sintassi per dire akubectldi creare gli oggetti descritti nel filedescriptor.[yml|json]. Il filekube-flannel.ymlcontiene le descrizioni degli oggetti richiesti per configurareFlannelnel cluster.
Ora, dopo aver aggiunto il testo, devi salvare e chiudere il file.
Esecuzione del Playbook
Dopodiché, devi eseguire il nostro playbook semplicemente avviando sulle macchine locali:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/master.yml |
L'esecuzione di questo comando richiederà del tempo, dopodiché vedrai il seguente output:
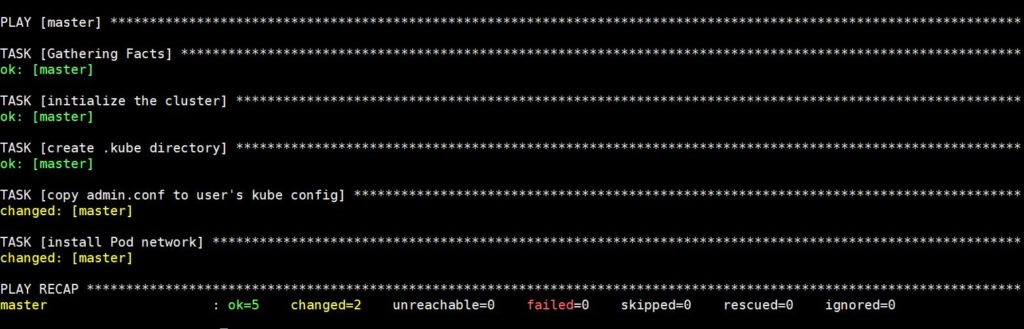
Ora connettiti in SSH con il seguente comando per verificare lo stato del nodo master:
|
1 |
ssh ubuntu@master_ip |
Una volta all'interno del nodo master, esegui:
|
1 |
kubectl get nodes |
Ora vedrai il seguente output:

Una volta ottenuto l'output sopra indicato, puoi considerare che tutte le attività di configurazione sono state completate dal nodo master, il quale può iniziare ad accettare i nodi worker e a eseguire i task non appena entra nello stato Ready. Ora puoi aggiungere i worker dalla tua macchina locale.
Passo 5 — Configurazione dei nodi worker
Dopo aver configurato il nodo master, possiamo passare al passaggio successivo di configurazione dei nodi worker. L'aggiunta dei nodi worker al cluster può essere eseguita semplicemente avviando un singolo comando su ciascun server worker. In questo comando sono incluse informazioni importanti come l'indirizzo IP, la porta del server API del master e un token sicuro. Tuttavia, tieni presente che non tutti i nodi potranno unirsi al cluster, ma solo quelli che trasmettono il token sicuro.
Creazione del playbook
Questo comando ti aiuterà a tornare alla tua area di lavoro e a creare un playbook chiamato workers.yml:
|
1 |
nano ~/kube-cluster/workers.yml |
Aggiungi il seguente testo al file per aggiungere i worker al cluster:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
- hosts: master become: yes gather_facts: false tasks: - name: ottieni comando di join shell: kubeadm token create --print-join-command register: join_command_raw - name: imposta comando di join set_fact: join_command: "{{ join_command_raw.stdout_lines[0] }}" - hosts: workers become: yes tasks: - name: unisci al cluster shell: "{{ hostvars['master'].join_command }} >> node_joined.txt" args: chdir: $HOME creates: node_joined.txt |
Ecco cosa fa il playbook. Ci sono due play nel codice sopra:
- Il primo play viene utilizzato per ottenere il comando di unione che deve essere eseguito sui nodi worker. Il formato del comando sarà:
kubeadm join --token sha256:<hash><token><master-ip>:<master-port> --discovery-token-ca-cert-hash sha256:<hash>;. Il task deve ottenere i valori corretti di token e hash. Una volta ottenuto l'input corretto, il task lo imposta come fact in modo che il secondo play possa accedere a tale informazione. - Il secondo play è scritto solo per eseguire un singolo task – per rendere i due nodi worker parte del cluster semplicemente eseguendo il comando join su tutti i nodi worker.
Dopo aver aggiunto il testo, è necessario salvare e chiudere il file.
Esecuzione del playbook
Dopodiché, dobbiamo eseguire il nostro playbook eseguendo il seguente comando sulle macchine worker:
|
1 |
ansible-playbook -i hosts ~/kube-cluster/workers.yml |
L'esecuzione di questo comando richiederà un po' di tempo, dopodiché vedrai il seguente output:
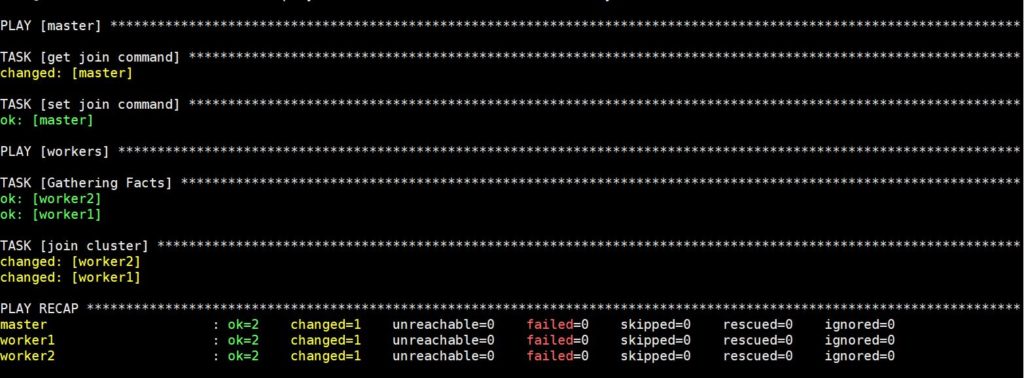
Ora, il tuo cluster Kubernetes è completamente configurato e funzionante con i worker pronti a eseguire i carichi di lavoro. Prima di passare al passaggio successivo, verifichiamo che il cluster funzioni come previsto.
Passaggio 6 — Verifica del cluster
Potrebbero esserci casi in cui un cluster fallisce durante la configurazione. Potrebbe essere dovuto a un errore di rete tra il master e il worker, o a un problema del nodo. Quindi dobbiamo verificare il cluster prima di pianificare le applicazioni e assicurarci che non si verifichino malfunzionamenti. Per fare questo, dovrai controllare lo stato attuale del cluster dal nodo master per assicurarti che i nodi siano pronti. Puoi ripristinare la connessione con il seguente comando se i nodi non sono pronti o se ti disconnetti:
|
1 |
ssh ubuntu@master_ip |
Usa i seguenti comandi per ottenere lo stato del cluster:
|
1 |
kubectl get nodes |
L'esecuzione di questo comando richiederà un po' di tempo, dopodiché vedrai il seguente output:

Devi verificare se tutti i nodi che fanno parte del cluster sono nello stato Ready. Se alcuni nodi hanno Not Ready come STATUS, significa che i nodi worker non hanno ancora terminato la loro configurazione. Tuttavia, prima di eseguire nuovamente kubectl get nodes e controllare l'output aggiornato dovresti attendere altri cinque o dieci minuti. Se alcuni nodi mostrano ancora Not Ready come stato, dovresti andare a verificare i passaggi precedenti e rieseguire i comandi. Solo se i nodi hanno il valore Ready per STATUS, fanno parte del cluster e sono pronti per eseguire i carichi di lavoro. Dopo aver eseguito con successo il sesto passaggio, il tuo cluster è ora verificato. Ora pianifichiamo un'applicazione Nginx di esempio sul cluster.
Passaggio 7 — Esecuzione di un'applicazione sul cluster
Creazione del Deployment
Dopo aver creato con successo il cluster, puoi distribuire qualsiasi applicazione containerizzata sul tuo cluster. Puoi utilizzare i comandi seguenti per altre applicazioni containerizzate se ti trovi all'interno del nodo master. Successivamente, esegui il seguente comando per creare un deployment chiamato nginx :
|
1 |
kubectl create deployment nginx --image=nginx |
È necessario modificare il nome dell'immagine Docker e tutti i flag pertinenti (come porte e volumi). Per mantenere le cose familiari, puoi distribuire Nginx utilizzando deployment e servizi per vedere come le applicazioni possono essere distribuite nel cluster.
Un deployment di Kubernetes è un oggetto risorsa in Kubernetes che fornisce aggiornamenti dichiarativi alle applicazioni. Un deployment consente di descrivere il ciclo di vita di un'applicazione, come l'immagine del container, le repliche e la strategia di aggiornamento. Un deployment garantisce che il numero desiderato di pod sia in esecuzione e disponibile in ogni momento. Se un pod si arresta in modo anomalo durante il ciclo di vita del cluster, lo genera nuovamente. Anche il processo di aggiornamento viene interamente registrato e versionato con opzioni per sospendere, continuare e ripristinare le versioni precedenti. Il comando precedente per creare un deployment denominato Nginx ti aiuterà a distribuire un pod con un container dall'immagine Docker Nginx del registro Docker.
Configurazione di Node Port
Successivamente, dobbiamo creare un NodePort. NodePort è una porta aperta su ogni nodo del cluster. Kubernetes instrada in modo trasparente il traffico in entrata sulla NodePort al tuo servizio, anche se l'applicazione è in esecuzione su un altro nodo. Per questo possiamo usare questo comando per creare una risorsa NodePort chiamata Nginx che esporrà l'app pubblicamente:
|
1 |
kubectl expose deploy nginx --port 80 --target-port 80 --type NodePort |
Un servizio è un altro oggetto Kubernetes responsabile dell'esposizione di un'interfaccia a tali pod, che consente l'accesso alla rete dall'interno del cluster o tra processi esterni e il servizio. Può essere definito come un'astrazione sopra il pod che fornisce un singolo indirizzo IP e un nome DNS tramite i quali è possibile accedere ai pod. Con il servizio, è molto semplice gestire la configurazione del bilanciamento del carico.
Esegui il seguente comando:
|
1 |
kubectl get services |
Questo produrrà un output simile al seguente:

Dopo aver ottenuto l'output, Kubernetes assegnerà automaticamente una porta casuale superiore a 30000 assicurandosi al contempo che la porta assegnata non sia già occupata da un altro servizio. La terza riga dell'output sopra ti aiuterà a recuperare la porta su cui è in esecuzione Nginx.
Per verificare che funzioni, visita http://worker_1_ip:nginx_port o http://worker_2_ip:nginx_port tramite un browser sulla tua macchina locale. Vedrai la familiare pagina di benvenuto di Nginx.
Rimozione del Deployment
Se desideri rimuovere l'applicazione Nginx, devi prima eliminare il servizio nginx dal nodo master:
|
1 |
kubectl delete service nginx |
Per verificare che l'applicazione sia stata effettivamente eliminata, devi eseguire questo comando:
|
1 |
kubectl get services |
Otterrai il seguente output:

Successivamente, devi eliminare il deployment utilizzando il seguente comando:
|
1 |
kubectl delete deployment nginx |
Puoi usare questo comando per verificare se il deployment è stato effettivamente eliminato:
|
1 |
kubectl get deployments |
![]()
Conclusione:
Questo tutorial ti aiuterà a configurare correttamente un cluster su Ubuntu 18.04 utilizzando Kubeadm e Ansible. Ora che il tuo cluster è configurato, puoi iniziare facilmente a distribuire le tue applicazioni e i tuoi servizi.
Ecco un elenco di link con dettagli aggiuntivi che ti guideranno nel processo:
- Dockerizzare le applicazioni – Questo link contiene esempi che ti guidano su come caricare applicazioni utilizzando Docker. Come la dockerizzazione di PostgreSQL, un servizio CouchDB, ecc.
- Panoramica dei Pod – Questo link mostra dettagli su come utilizzare un pod, il funzionamento dei pod e come i pod sono correlati ad altri oggetti Kubernetes. I pod sono una parte importante di Kubernetes, quindi comprenderli ti aiuterà a completare con successo il tuo compito.
- Panoramica dei Deployment – Ti aiuterà a conoscere i deployment. Un deployment fornisce aggiornamenti dichiarativi per Pod e ReplicaSet. Imparerai come aggiornare, eseguire il rollover e il rollback di un deployment.
- Panoramica dei Servizi - Questo link ti guiderà sui servizi, che sono un altro oggetto frequentemente utilizzato nei cluster Kubernetes. Un servizio in Kubernetes è un'astrazione che definisce un insieme logico di Pod e una policy tramite la quale è possibile accedervi. Comprendere i tipi di servizi e le opzioni disponibili è essenziale per eseguire sia applicazioni stateless che stateful.
Inoltre, dai un'occhiata agli altri nostri tutorial incentrati su Docker e Kubernetes che puoi trovare sul nostro blog:
- Conoscere Kubernetes
- Pulizia delle risorse Docker – Immagini, container e volumi
- Come eseguire Docker su CloudSigma (con CloudInit) Aggiornato
- Installazione e configurazione di Docker su CentOS 7
- Come installare & gestire Docker su Ubuntu nel cloud pubblico
Ci sono anche molti altri concetti importanti come Volumi, Ingressi, e Segreti che puoi utilizzare durante il deployment di applicazioni in produzione.
Buon computing!
Commenti
Ancora nessun commento. Scrivi il primo.