

Web scraping, web crawling, web harvesting o web data extraction sono sinonimi che si riferiscono all'atto di estrarre dati da pagine web su Internet. I web scraper o web crawler sono strumenti che analizzano le pagine web in modo programmatico estraendo i dati richiesti. Questi dati, che di solito sono grandi insiemi di testo, possono essere utilizzati a scopo analitico, per comprendere i prodotti o per soddisfare la curiosità su una determinata pagina web.
Se vi state chiedendo come procedere con il web crawling, vi mostreremo le basi del web scraping attraverso un semplice set di dati. Dovreste essere in grado di seguire il tutorial indipendentemente dal vostro livello di competenza nella programmazione. Per l'esempio pratico, utilizzeremo il nostro blog di CloudSigma. Cercheremo di ottenere informazioni sui tutorial presenti nella pagina del nostro blog. Quando arriverete alla conclusione di questo tutorial, avrete un web scraper funzionante realizzato con Python 3 che esegue il crawling di diverse pagine della sezione del nostro blog, per poi mostrare i dati sullo schermo.
Utilizzando le conoscenze acquisite con la creazione di questo web scraper di base, potrete espanderlo e creare i vostri web scraper. Sarà divertente, iniziamo!
Prerequisiti
Questo è un tutorial pratico, quindi per seguirlo al meglio dovreste avere un ambiente di sviluppo locale per Python 3. Per prima cosa, potete fare riferimento al nostro tutorial su come installare Python 3 e configurare un ambiente di programmazione locale su Ubuntu.
Scrapy
Il web scraping prevede due fasi: la prima consiste nel trovare e scaricare le pagine web, la seconda nel navigare ed estrarre informazioni da tali pagine.
Esistono diversi modi e librerie che possono essere utilizzati per creare un web scraper da zero in molti linguaggi di programmazione. Tuttavia, questo potrebbe comportare problemi in futuro, quando il web scraper diventerà complesso o quando sarà necessario eseguire il crawling di più pagine contemporaneamente con impostazioni e pattern diversi. Potrebbe essere un compito piuttosto gravoso capire come trasformare i dati estratti tra diversi formati come CSV, XML o JSON.
Anche se alcuni potrebbero apprezzare la sfida di costruire il proprio web scraper da zero, è meglio non reinventare la ruota e costruirlo invece sopra una libreria esistente che gestisce tutti questi problemi. Utilizzeremo Scrapy, una libreria Python, insieme a Python 3 per implementare il web scraper in questo tutorial. Scrapy è uno strumento open-source e una delle librerie di web scraping in Python più popolari e potenti. Scrapy è stato creato per gestire alcune delle funzionalità comuni che tutti gli scraper dovrebbero avere. In questo modo non dovrete reinventare la ruota ogni volta che vorrete implementare un web crawler. Con Scrapy, il processo di creazione di uno scraper diventa facile e divertente.
Scrapy è disponibile su PyPi, comunemente noto come pip – il Python Package Index. PyPi è un repository di proprietà della community che ospita la maggior parte dei pacchetti Python. Quando installate e configurate Python 3 sul vostro ambiente di sviluppo locale, viene installato anche pip, che potete usare per installare i pacchetti Python.
Passo 1: Come creare un semplice Web Scraper
Per prima cosa, per installare Scrapy, eseguite il seguente comando:
|
1 |
pip install scrapy |
In alternativa, potete seguire le istruzioni ufficiali di installazione di Scrapy dalla pagina della documentazione. Se avete installato Scrapy con successo, create una cartella per il progetto usando un nome a vostra scelta:
|
1 |
mkdir cloudsigma-crawler |
Entrate nella cartella e create il file principale per il codice. Questo file conterrà tutto il codice di questo tutorial:
|
1 |
touch main.py |
Se preferite, potete creare il file utilizzando il vostro editor di testo o IDE invece del comando precedente.
Successivamente, aprite il file e iniziamo creando uno scraper di base che utilizza Scrapy. Creeremo una classe Python che estende scrapy.Spider, una classe spider di base di Scrapy. Questa classe avrà due attributi richiesti, come definito di seguito:
- name — una stringa per identificare lo spider (potete inserire un nome a vostra scelta).
- start_urls — un array contenente un elenco di URL da cui eseguire il crawling. Inizieremo con un solo URL.
Aggiungi il seguente frammento di codice nel file aperto per creare lo spider di base:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
Di seguito è riportata una spiegazione di ciascuna riga di codice:
La prima riga importa Scrapy, consentendoci di utilizzare le varie classi fornite dal pacchetto.
Nella riga successiva, estendiamo la classe Spider fornita da Scrapy e creiamo una sottoclasse chiamata CloudSigmaCrawler. Estendendo una Classe (Spider), otteniamo l'accesso alle proprietà della Classe che ora possiamo utilizzare nel nostro codice. In questo caso, la classe Spider ha metodi e comportamenti che definiscono come seguire gli URL ed estrarre dati dalle pagine web. Tuttavia, non sa quali URL seguire o quali dati estrarre. Estendendola, possiamo fornire le informazioni richieste ai metodi. Per saperne di più sulla creazione di sottoclassi e sull'estensione, continua a leggere principi di programmazione orientata agli oggetti.
Nel nostro CloudSigmaCrawler, definiamo gli attributi richiesti. Innanzitutto, nominiamo il nostro spider cloudsigma_crawler. Quindi, forniamo un singolo URL da cui iniziare: https://blog.cloudsigma.com/blog/. L'apertura di questo URL ti porterà alla pagina 1 del blog di CloudSigma che contiene alcuni dei molti tutorial.
È ora di testare lo scraper. Hai diverse opzioni. Se stai usando un IDE, ad esempio la PyCharm community edition di JetBrains, probabilmente include un pulsante su cui puoi semplicemente fare clic per eseguire lo script. Un'altra opzione consiste nel seguire il modo tipico di eseguire i file Python dalla riga di comando: python path/to/file.py, o py path/to/file.py. Un'altra opzione è l'interfaccia a riga di comando di Scrapy interface. Scrapy viene fornito con la propria interfaccia a riga di comando per aiutare ad avviare uno scraper. Inserisci il seguente comando per avviare lo scraper:
|
1 |
scrapy runspider main.py |
A seconda della versione della libreria di Scrapy installata, dovresti vedere un output simile al seguente:
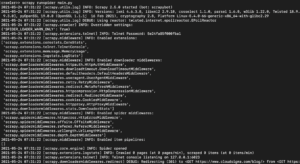
Come puoi vedere, l'output è piuttosto lungo, quindi abbiamo selezionato solo alcune parti. Ecco cosa è successo quando hai eseguito il comando:
- Lo scraper è stato inizializzato. Di conseguenza, ha caricato componenti ed estensioni aggiuntivi necessari per seguire e leggere i dati dagli URL.
- Utilizzando l'URL fornito nell'elenco start_urls, ha recuperato l'HTML dalla pagina. Questo è un processo simile a quello seguito dal browser quando apre le pagine web.
- Dopo aver recuperato l'HTML, questo viene passato al metodo parse che non abbiamo ancora definito. Per ora non fa nulla, quindi lo spider si limita a uscire senza eseguire alcuna elaborazione. Definiremo il comportamento del metodo parse nel passaggio successivo.
Passaggio 2: Come estrarre dati da una pagina
Nel passaggio 1, abbiamo implementato solo uno scraper di base che recupera una pagina HTML ma non fa nulla dopo. In questa sezione, forniremo le istruzioni per estrarre i dati. Sulla pagina del CloudSigma Blog da cui vogliamo estrarre i dati, ci sono alcune cose che puoi notare come:
- L'intestazione, presente su tutte le pagine.
- Il menu di navigazione e la casella del filtro di ricerca.
- L'elenco effettivo dei tutorial in formato griglia.
La visualizzazione del codice sorgente della pagina HTML che intendi raschiare ti offre un'idea generale della struttura della pagina. Questo ti aiuta a scrivere uno scraper. Puoi visualizzare il codice sorgente facendo clic con il pulsante destro del mouse sulla pagina e selezionando Visualizza sorgente pagina, oppure premendo Ctrl + U. Ecco un frammento del codice sorgente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Link permanente a: "Proteggere Apache con Let’s Encrypt su Ubuntu 18.04"">Proteggere Apache con Let’s Encrypt su Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>La sicurezza del sito web e dei dati sono argomenti che non possono essere presi alla leggera. Informazioni altamente sensibili che includono record finanziari e informazioni private dei clienti sono sempre in transito tra il computer dell'utente e il tuo sito web. Quando consideri questo fatto, non è difficile capire perché i siti web non protetti potrebbero causare una violazione in grado di danneggiare seriamente la tua attività. Ci sono … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Leggi di più</a></div> </div> </div> ... </article> </div> </body> |
Come puoi vedere, ogni tutorial del blog è racchiuso all'interno di un tag HTML chiamato <article>. Lo scraping della pagina comporterà due passaggi. Il primo passaggio consisterà nel recuperare ciascun tutorial del blog esaminando le parti della pagina che contengono i dati che desideriamo. Il passaggio successivo consiste nell'estrarre i dati desiderati da ciascun tutorial identificato dal tag HTML.
Scrapy identifica i dati da recuperare in base ai selettori forniti. Possiamo usare i selettori per trovare uno o più elementi su una pagina e ottenere i dati all'interno degli elementi. Scrapy supporta i selettori XPath e CSS.
Dal codice sorgente che abbiamo visto in precedenza, i selettori CSS sembrano essere più semplici. Pertanto, questa sarà l'opzione che sceglieremo in quanto ci aiuterà a trovare tutti i tutorial sulla pagina. Dal codice sorgente HTML, ogni tutorial è specificato all'interno della classe CSS chiamata post. I nomi delle classi CSS sono solitamente identificati con .nome_classe (punto nome_classe). Pertanto, useremo .post per il nostro selettore CSS. All'interno del codice sorgente del nostro scraper main.py, passeremo la classe .post all'oggetto response, in modo che il tuo file si presenti ora così:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
Questo frammento di codice catturerà tutti i tutorial sulla pagina con gli start_urls specificati e scorrerà i tutorial per estrarre i dati. Nel passaggio successivo vorrai estrarre e visualizzare questi dati. Se esamini nuovamente il codice sorgente del blog di CloudSigma vedrai che il titolo di ciascun tutorial è memorizzato all'interno di un tag <a> che si trova all'interno di un tag <h2>, ad esempio:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
Ogni oggetto tutorial su cui stiamo iterando contiene un metodo CSS a cui possiamo passare un selettore per individuare ed estrarre gli elementi figli. Per questo esempio, vogliamo estrarre il titolo che è racchiuso all'interno del tag <a>. Questo tag si trova all'interno del tag <h2> all'interno della classe .entry-header all'interno della classe .entry-wrap. Possiamo passare questi selettori CSS al metodo dell'oggetto per estrarre il titolo, modificando il codice in questo modo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
La virgola finale dopo extract_first() non è un errore di battitura, poiché aggiungeremo altro codice sotto questa sezione.
Alcuni punti da notare dal codice sorgente sopra includono:
- ::text aggiunto al selettore – questo è un pseudo-selettore CSS che indica al codice di recuperare il testo all'interno del tag e non il tag stesso.
- chiamata al metodo extract_first() all'interno dell'oggetto – indica al codice di selezionare solo il primo elemento che corrisponde al selettore. Di conseguenza, otteniamo una stringa anziché un elenco di elementi.
Successivamente, salva il file ed esegui il codice inserendo il seguente comando nel terminale:
|
1 |
scrapy runspider main.py |
Nell'output dovresti vedere i titoli dei tutorial:
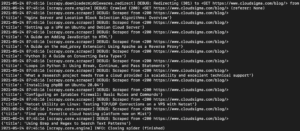
Possiamo continuare a espandere questo aggiungendo altri selettori per ottenere altri dettagli su un tutorial, come l'URL del tutorial, l'immagine in evidenza e la didascalia.
Esaminiamo di nuovo il codice HTML di un singolo tutorial:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="Permalink a: "Proteggere Apache con Let’s Encrypt su Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Mettere in sicurezza Apache con Let’s Encrypt su Ubuntu 18.04</a> </h2> </header> <div class="entry-content excerpt"> <p>La sicurezza del sito web e dei dati sono argomenti che non possono essere presi alla leggera. Le informazioni altamente sensibili che includono dati finanziari e informazioni private dei clienti sono sempre in transito tra il computer dell'utente e il tuo sito web. Se si considera questo fatto, non è difficile capire perché i siti web non protetti potrebbero causare una violazione in grado di danneggiare seriamente la tua attività. Ci sono … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Leggi di più</a></div> </div> </div> </article> </div> </body> |
Vogliamo provare a estrarre le parti evidenziate, ovvero l'URL del tutorial, l'immagine in evidenza e la didascalia.
- Dallo snippet di codice sopra, l'immagine per il blog è memorizzata all'interno dell'attributo data-lazy-src di un tag img all'interno di un tag <a> all'interno di un tag div all'inizio del tutorial del blog. Possiamo usare un selettore CSS per recuperare il valore come abbiamo fatto con i titoli dei tutorial.
- Ottenere l'URL del tutorial è semplice, poiché abbiamo il tag <a> all'interno dell'elemento <div>.
- La didascalia è racchiusa all'interno del tag <p> che si trova all'interno del tag <div>.
Useremo le classi CSS per ottenere ciò che vogliamo. Modifichiamo il codice in modo che si presenti così:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
Salva le modifiche ed esegui il codice con il seguente comando:
|
1 |
scrapy runspider main.py |
Vedrai più dati nell'output, come l'URL, l'immagine e la didascalia che abbiamo aggiunto:

Questo è tutto per il crawling di una singola pagina. Successivamente, vediamo come creare uno scraper che segue i link.
Passaggio 3: Come eseguire il crawling di più pagine
Fino a questo punto, abbiamo creato uno scraper in grado di ottenere dati da una singola pagina. Tuttavia, vogliamo di più. Desideri uno spider in grado di seguire i link ed estrarre dati da più pagine di un sito web in modo programmatico.
Se vai in fondo alla pagina del blog di CloudSigma, noterai i link di paginazione e una piccola freccia rivolta verso destra che indica la pagina successiva. Ecco lo snippet di codice HTML:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Pagina 1 di 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Ultima pagina">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Lo snippet mostra diversi link di navigazione delle pagine all'interno dei tag <li>, sotto il tag <div> con la classe CSS .x-pagination. La nostra attenzione è rivolta al link che punta alla pagina successiva. Si trova nel tag <a> dell'ultimo <li> nel tag <ul>.
Il link che punta alla pagina successiva ha la classe .prev-next all'interno del tag <a>, come si vede nello snippet sopra. Tuttavia, se passi alla pagina successiva, noterai anche che i link alla pagina precedente e successiva hanno questa classe CSS. Considera questo snippet per la Pagina 2:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Pagina 2 di 45</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Ultima pagina">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Se usiamo il metodo extract_first() di Scrapy, funzionerà sulla prima pagina. Quando raggiunge la pagina successiva, selezionerà il primo link con la classe .prev-next, che nello snippet sopra punta alla prima pagina. Questo causerà un loop. Pertanto, useremo il metodo extract() di Scrapy. Questo metodo estrae tutti gli elementi corrispondenti a un caso d'uso e li inserisce in un array. Da questo array, possiamo selezionare l'ultimo elemento che conterrà il link effettivo che punta alla pagina successiva. Modifica il tuo codice in questo modo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Esaminiamo il codice per la selezione di next_page.
Definiamo prima un selettore per i link della pagina successiva e precedente. Utilizziamo poi il metodo extract() per estrarre gli URL e inserirli in un array. La variabile next_page sarà un array con due elementi come:
|
1 |
next_page = [prev_page_url, next_page_url] |
Poiché stiamo navigando verso la pagina successiva, sceglieremo l'ultimo elemento dell'array. Next_page[-1] seleziona l'ultimo elemento dell'array.
Il blocco if controlla se la variabile next_page contiene qualcosa, quindi chiama il metodo scrapy.Request(). Nel nostro codice, istruiamo questo metodo a scansionare la pagina con l'URL fornito e a passarla nuovamente al metodo parse() in modo da poterla analizzare per estrarre i dati e ripetere il processo per la pagina successiva. Questo processo viene ripetuto finché non trova un link alla pagina successiva, o meglio se il blocco fallisce, allora si ferma.
Salva il codice ed eseguilo. Noterai che l'iterazione continua a scorrere le pagine man mano che trova altre pagine da scansionare. Questo è il modo in cui definiresti uno scraper che segue i link su un sito web. Il nostro esempio è piuttosto semplice. Stiamo solo andando su una pagina, trovando il link alla pagina successiva e ripetendo il processo. In altri casi d'uso, potresti voler seguire tag o link che rimandano a fonti esterne e altro ancora. Ecco il codice sorgente completo per il web scraper di base in Python 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Conclusione
In questo tutorial, abbiamo creato un web scraper di base in grado di eseguire il crawling della directory del blog di CloudSigma e mostrare alcune informazioni sui tutorial del blog in sole 27 righe di codice circa.
Naturalmente, questo è possibile perché lo abbiamo creato basandoci sulla libreria Python Scrapy. Questa è solo una base che dovrebbe aiutarti a creare scraper più complessi che seguono più tag, risultati di ricerca di siti web e altro ancora. Puoi consultare la documentazione ufficiale di Scrapy per ulteriori informazioni sull'utilizzo di Scrapy.
Buon computing!
Commenti
Ancora nessun commento. Scrivi il primo.