

Il comando sed è un'abbreviazione di stream editor. È uno strumento molto popolare sui sistemi Linux/UNIX. Sed non è un editor di testo di per sé. Tuttavia, può eseguire varie modifiche per manipolare un determinato testo. L'input di testo viene inviato come flusso. Sed esegue quindi le azioni istruite sul flusso. Questa guida fornisce una panoramica del sed comando e di come utilizzarlo per manipolare con successo il testo in Linux.
Sed in Linux
Il flusso di input di sed può provenire da un file di testo o da STDIN (standard input). Possiamo lavorare con l'output di un altro comando o lavorare direttamente con un file di testo. Lo sed strumento è preinstallato su tutte le Linux distribuzioni.
Panoramica sull'uso di Sed
Il sed comando segue la seguente struttura:
|
1 |
$ sed <opzioni> <comandi> <file> |
A scopo dimostrativo, abbiamo recuperato la versione di testo della licenza GPL versione 3:
|
1 |
$ wget https://www.gnu.org/licenses/gpl-3.0.txt |

Il seguente sed comando stamperà il contenuto del file di testo:
|
1 |
$ sed '' gpl-3.0.txt |
Qui, sed sta eseguendo le operazioni descritte tra i singoli apici e stampando l'output. Poiché non è definita alcuna opzione, sed eseguirà semplicemente un'operazione vuota e stamperà l'intero contenuto del file.
Sed accetta anche l'output di un comando diverso come flusso di input. Nel prossimo esempio, invia tramite pipe il contenuto del file di testo GPL v3 a sed per eseguire un'operazione vuota:
|
1 |
$ cat gpl-3.0.txt | sed '' |
Come stampare le righe
Senza alcuna opzione specificata, sed stamperà direttamente tutto il contenuto del file. Invece, possiamo inviare esplicitamente il comando di stampa per stampare i risultati direttamente sullo standard output (STDOUT).
Per stampare l'output, usa il carattere p:
|
1 |
$ sed 'p' gpl-3.0.txt |
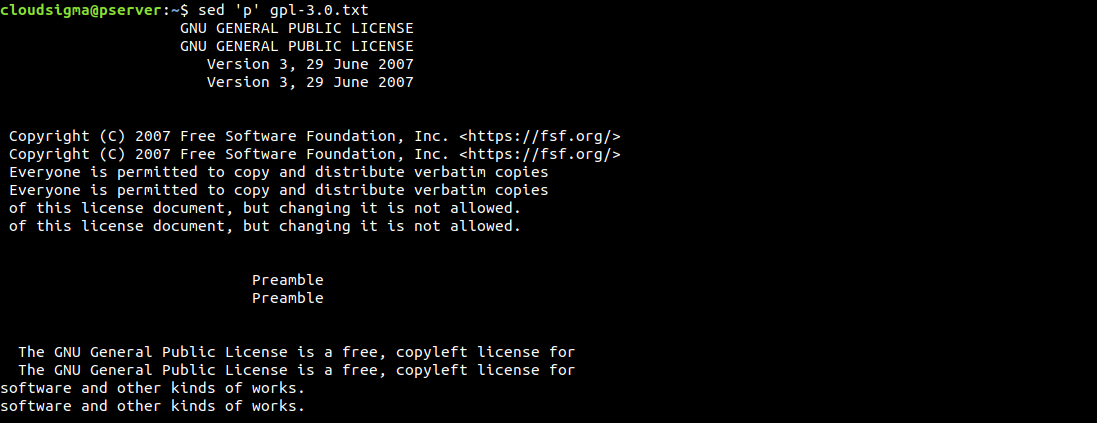
Per impostazione predefinita, sed stampa l'output sullo schermo. Poiché abbiamo utilizzato specificamente il comando di stampa, sed stamperà ogni riga due volte. Sed opera riga per riga. Legge una riga, esegue operazioni specifiche, la stampa e passa alla riga successiva.
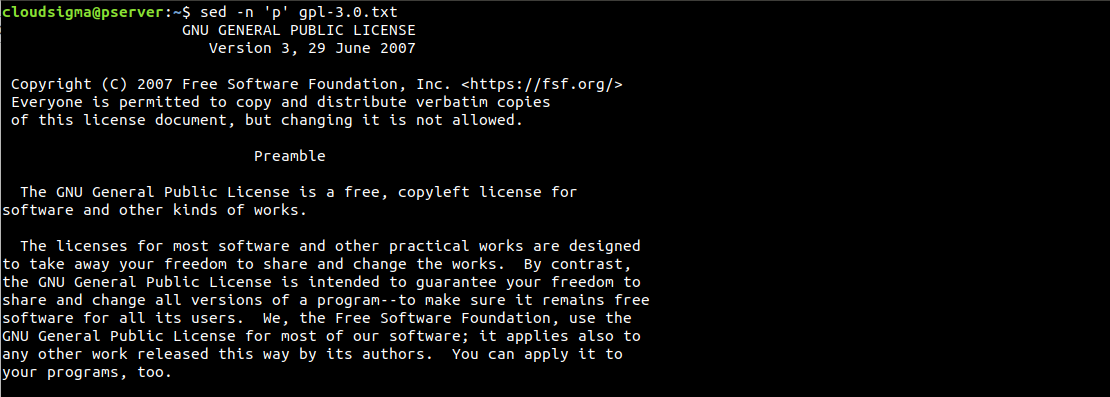
Come possiamo vedere, ogni riga viene stampata due volte. Se il risultato è confuso in questo modo, possiamo ripulirlo usando l'opzione -n. Essa sopprime la funzione di stampa automatica. Poiché stiamo inviando il comando di stampa, non abbiamo bisogno che la funzione di stampa dell'output predefinita sia abilitata:
|
1 |
$ sed -n 'p' gpl-3.0.txt |
Classi di caratteri delle espressioni regolari (Regex)
Nelle espressioni regolari esistono varie classi di caratteri. Ognuna di queste classi ha un intervallo. Molte classi hanno anche più espressioni. La maggior parte delle classi sono intervalli di caratteri:
-
- [a-z]: Carattere minuscolo
-
- [A-Z]: Carattere maiuscolo
-
- [0-9]: Cifre
-
- [a-zA-z]: Alfabeto
-
- [a-zA-z0-9]: Qualsiasi carattere alfanumerico
Queste classi di caratteri hanno anche notazioni diverse:
-
- [:lower:]: Carattere minuscolo
-
- [:upper:]: Carattere maiuscolo
-
- [:digit:]: Cifre
-
- [:alpha:]: Alfabeto
-
- [:alphanum:]: Carattere alfanumerico
Ad esempio, il seguente comando stamperà tutte le righe che contengono almeno una cifra:
|
1 |
$ sed -n 's/[[:digit:]]/&/p' gpl-3.0.txt |
Intervalli di indirizzi
Possiamo specificare la parte specifica del flusso di testo con cui lavorare. Può essere la posizione statica di una riga o un intervallo di righe. Nel primo esempio, stamperemo la riga 5 dal file di testo GPL v3:
|
1 |
$ sed -n '5p' gpl-3.0.txt |

Invece di una singola riga, possiamo anche specificare un intervallo di righe con cui lavorare. Qui abbiamo fornito l'intervallo di indirizzi dalla riga 5 alla riga 9 (in totale 5 righe) su cui sed lavorerà:
|
1 |
$ sed -n '5,9p' gpl-3.0.txt |

Esistono anche diversi modi per specificare l'indirizzo della riga. Invece di determinare noi stessi i numeri di riga, possiamo riorganizzare l'esempio precedente in modo che sed parta dalla riga 5 e operi sulle successive 5 righe:
|
1 |
$ sed -n '5,+5p' gpl-3.0.txt |

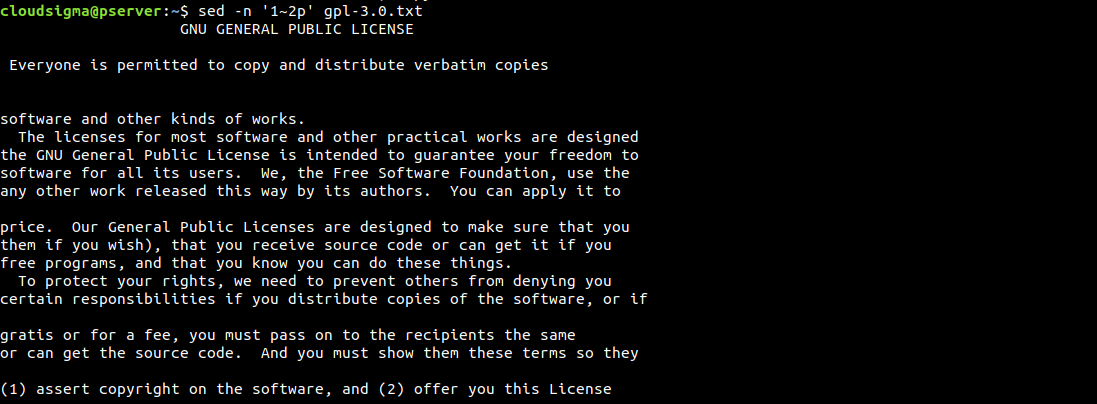
Un altro modo per specificare le righe è utilizzare gli intervalli. Nel prossimo esempio, sed partirà dalla riga 1 e opererà a righe alterne:
|
1 |
$ sed -n '1~2p' gpl-3.0.txt |
Eliminazione del testo
Finora abbiamo lavorato sulla stampa delle righe di testo di destinazione. Invece di stamparle, possiamo rimuovere le righe dall'output. Nel seguente esempio, rimuoveremo più righe dall'inizio. Qui non abbiamo bisogno di usare l'opzione -n perché vogliamo che sed stampi tutto il resto che non viene eliminato. Per l'eliminazione delle righe, useremo l'opzione d:
|
1 |
$ sed '1~2d' gpl-3.0.txt |
Nota che il file sorgente è ancora intatto. Sed sta solo eseguendo l'eliminazione delle righe durante l'output. Se vuoi, puoi salvare l'output di sed in un file. Puoi sovrascrivere il file originale o salvarlo come un file diverso:
|
1 |
$ sed '1~2d' gpl-3.0.txt > gpl-3.0.modified.txt |
Invece di scrivere manualmente l'output in un file, sed può eseguire una modifica sul posto sul file originale. In breve, sed modificherà il file originale e scriverà le modifiche apportate. Questo metodo sovrascriverà il file originale, quindi dovrebbe essere usato con cura:
|
1 |
$ sed -i '1~2d' gpl-3.0.txt |
Poiché la modifica sul posto è pericolosa, sed include una funzionalità di backup. Quando si eseguono modifiche sul posto, usa -i.bak invece di -i per creare un backup prima della modifica. Sed creerà il file di backup con .bak come estensione:
|
1 |
$ sed -i.bak '1~2d' gpl-3.0.txt |
Sostituzione del testo
Questa è, di gran lunga, una delle implementazioni più comuni di sed. Cerca un pattern di testo e lo sostituisce con un testo specificato. Qui, il pattern di testo è descritto in espressioni regolari (regex in breve). Per saperne di più sull'uso delle regex, segui questo tutorial che spiega come usare Grep con le regex per cercare pattern di testo nei file.
Ecco un esempio della sostituzione di testo più elementare utilizzando le regex:
|
1 |
$ 's/<search_pattern>/<replacement>' |
Qui, s è il comando per la sostituzione. Le barre sono delimitatori per il pattern e la sostituzione. Mettiamolo in pratica:
|
1 |
$ echo "hello world" | sed 's/hello/HELLO/' |
![]()
Il prossimo esempio mostrerà l'uso del carattere di sottolineatura (_). Qui, i caratteri di sottolineatura fungeranno da delimitatori:
|
1 |
$ echo http://example.com/index.html | sed 's_com/index_net/home_' |
Qui stiamo cercando com/index da sostituire con net/home. Nota il posizionamento dei caratteri di sottolineatura poiché sono cruciali. Ad esempio, se manca l'ultimo carattere di sottolineatura, sed restituirà un errore:
|
1 |
$ echo "http://www.example.com/index.html" | sed 's_com/index_net/home' |
![]()
Abbiamo bisogno di un file fittizio per fare pratica con alcune sostituzioni. Qui ho una versione ritagliata del file di testo GPL v3:
|
1 |
$ cat gpl-3.0.cropped.txt |
Eseguiamo alcune sostituzioni di testo di base:
|
1 |
$ cat gpl-3.0.cropped.txt | sed 's/GNU/GNU is Not Unix/' |
Diamo un'occhiata al prossimo esempio. Vogliamo cambiare tutte le istanze di the in THE :
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/' |
![]()
Noti qualcosa? Sed non ha cambiato tutte le istanze di the. In effetti, ha cambiato solo la prima istanza. Cosa sta succedendo? Questo è il comportamento predefinito dell'opzione s. Corrisponde solo alla prima istanza di una determinata riga e passa alla successiva. Per garantire che sed controlli l'intera riga per il pattern di ricerca, dobbiamo usare un flag opzionale g. Correggiamo il comando:
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/g' |
Ora funziona come previsto. Un altro modo interessante di usare il comando è specificare il numero di istanze da modificare. Nell'esempio precedente, c'erano 3 istanze di the, giusto? Che ne dici di specificare di modificare solo la 3ª istanza? La modifica avverrà in corrispondenza del flag opzionale:
|
1 |
$ echo "the the quick brown fox jumps over the lazy dog" | sed 's/the/THE/3' |
Se stai lavorando con un file di testo di grandi dimensioni, potrebbe essere utile se sed stampasse solo le righe in cui sono avvenute le sostituzioni. Per ottenere questo, dobbiamo aggiungere un altro flag aggiuntivo p:
|
1 |
$ sed -n 's/GNU/GNU is Not Unix/gp' gpl-3.0.txt |

Distinzione tra maiuscole e minuscole
Per impostazione predefinita, tutte le sed operazioni sono sensibili alle maiuscole. Il seguente comando mostrerà il comportamento predefinito della distinzione tra maiuscole e minuscole:
|
1 |
$ echo "HELLO WORLD" | sed 's/hello/hElLo/' |
![]()
A causa della mancata corrispondenza tra maiuscole e minuscole, non c'è alcun cambiamento. In una situazione del genere, possiamo dire a sed di disabilitare la distinzione tra maiuscole e minuscole. Per farlo, aggiungi il flag opzionale i:
|
1 |
$ echo "HELLO WORLD" | sed 's/hello/hElLo/i' |
Come sostituire e fare riferimento ai testi
La potenza di sed risiede principalmente nella sua capacità di utilizzare le espressioni regolari. Con pattern regex più avanzati e complessi, possiamo fare molto di più. Ad esempio, possiamo sostituire il testo dall'inizio di un file fino a una determinata posizione. Dai un'occhiata alla seguente espressione:
|
1 |
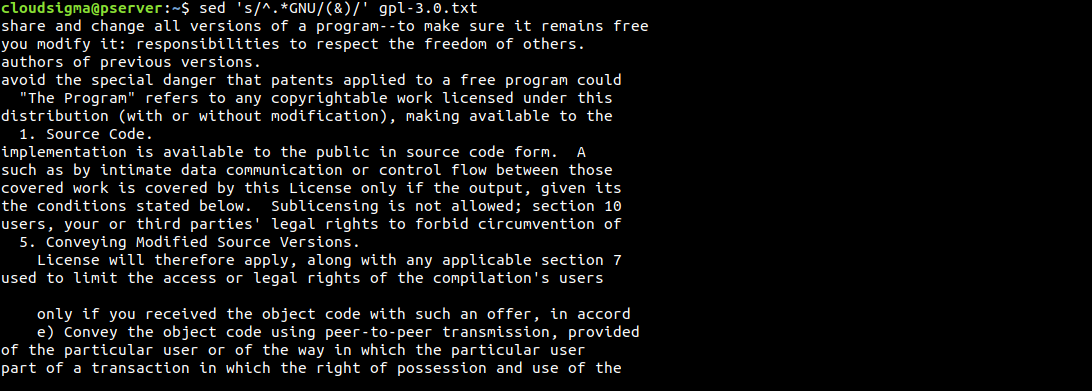
$ sed 's/^.*GNU/GNU_replaced/' gpl-3.0.txt |
Qui, il testo dell'accento circonflesso (^) indica l'inizio della riga. L'operatore che corrisponde a qualsiasi carattere è indicato dal punto fermo (.). L'asterisco (*) è l'espressione jolly, che corrisponde dall'inizio della riga fino a GNU.
Un altro trucco interessante è l'uso del simbolo &. Possiamo usarlo per evidenziare le aree che sed trova con il pattern di ricerca:
|
1 |
$ sed 's/^.*GNU/(&)/' gpl-3.0.txt |
Considerazioni finali
In questo tutorial, abbiamo esplorato le basi del comando sed . Abbiamo imparato come stampare righe specifiche, cercare testi, eliminare e sostituire testi, sovrascrivere testi e utilizzare le espressioni regolari. Un comando sed correttamente costruito può trasformare radicalmente un documento di testo. Ora puoi manipolare con successo il testo in Linux con l'aiuto di sed.
Buon computing!
Commenti
Ancora nessun commento. Scrivi il primo.