

A grep parancs egy hatékony eszköz a szöveges minták keresésére. Előre telepítve érkezik minden Linux disztribúcióban. Íme a útmutatónk, amely bemutatja a LAMP Stack - Linux, Apache, MySQL és PHP telepítését.
A grep név a „global regular expression print” (globális reguláris kifejezés nyomtatása) rövidítése. Az eszköz a megadott mintát keresi a bemenetben. Elvileg ez triviálisnak hangzik. Valódi ereje azonban abban rejlik, hogyan határozza meg a mintát. Ez az útmutató részletesen bemutatja, hogyan használható a grep reguláris kifejezésekkel összetett keresések végrehajtására. Kezdjük el!
A Grep használata
A grep parancs önmagában nem bonyolult. Mindössze a mintát és a tartalmat igényli, amelyben a keresést végre kell hajtani. Így néz ki a grep parancs alapszerkezete:
|
1 |
grep <regex> <file> |
Szöveg keresése
Először töltsön le egy mintafájlt, amelyen végrehajthatja a műveletet. Töltse le a GNU General Public License v3.0 licencet (szöveges formátumban). Ez egy meglehetősen nagy szövegfájl, sok szóval és kifejezéssel. Ha Ubuntu rendszert használ, az alábbi fájlban megtalálhatja. Kövesse a gyors és egyszerű Ubuntu telepítésről szóló útmutatónkat.
|
1 |
curl -o gpl.txt https://www.gnu.org/licenses/gpl-3.0.txt |

Ezután elvégezhet egy alapvető szöveges keresést a grep segítségével:
|
1 |
grep <pattern> <text_file> |
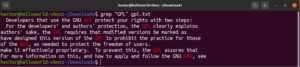
Lehetőség van egy parancs kimenetét a grep-be irányítani (pipe):
|
1 |
cat gpl.txt | grep <pattern> |
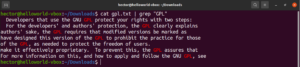
Kis- és nagybetűk megkülönböztetése
Alapértelmezés szerint a grep megkülönbözteti a kis- és nagybetűket. Sok esetben a kis- és nagybetűk figyelmen kívül hagyása lehet az optimális. A kis- és nagybetűk megkülönböztetésének kikapcsolásához használja a „-i” vagy „–ignore-case” jelzőt:
|
1 2 3 |
$ grep -i <pattern> <file> $ grep --ignore-case <pattern> <flag> |
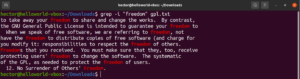
Keresés megfordítása
Alapértelmezés szerint a grep kiírja azokat a sorokat, amelyekben a minta megtalálható. A fordított egyezés (invert match) arra a jelenségre utal, amikor nem szeretné látni a mintára illeszkedő sorokat. A fordított egyezéshez a „-v” vagy „–invert-match” jelzőt kell használnia:
|
1 2 3 |
$ grep -v <pattern> <file> $ grep --invert-match <pattern> <file> |
Sorszám
Ha a grep-et egy nagyon nagy fájlon futtatja, nehéz nyomon követni a keresési eredmény helyét. A dolgok megkönnyítése érdekében a grep képes megjeleníteni a sorszámot. A sorszámozás engedélyezéséhez használja a „-n” vagy „–line-number” jelzőt:
|
1 2 3 |
grep -n <pattern> <file> grep --line-number <pattern> <file> |
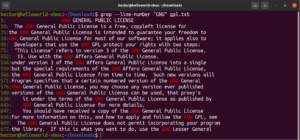
Lehetőség van több grep argumentum kombinálására is. A következő grep parancs fordított egyezést hajt végre, miközben kiírja a sorszámokat is:
|
1 |
grep -nv <pattern> <file> |
Reguláris kifejezés
Az útmutató elején említettük, hogy a grep a „global regular expression print” rövidítése. A „reguláris kifejezés” kifejezés egy olyan speciális karakterláncot jelöl, amely leírja a keresési mintát. A reguláris kifejezéseknek saját szerkezetük és szabályaik vannak.
Számos olyan karakterlánc-kereső algoritmus és eszköz létezik, amely reguláris kifejezéseket (röviden regex) használ a keresési és csere-műveletek végrehajtásához. Bár népszerű, a különböző alkalmazások és programozási nyelvek kissé eltérően implementálják a regexet. Ebben a részben bemutatunk néhány regex módszert a grep használatával.
Szó szerinti egyezés
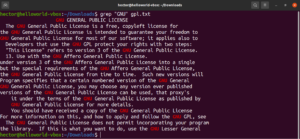
Az előző grep példákban a grep egy adott karakterláncot keresett a megadott szövegfájlban. A grep valójában a legegyszerűbb reguláris kifejezést használta a kereséshez. Azokat a regex mintákat, amelyek egy adott karakterlánc pontos egyezésének keresését határozzák meg, „literáloknak” nevezzük. A név abból a tényből ered, hogy szó szerint, karakterről karakterre illeszkednek a mintára.
A literális egyezés betűkkel és számjegyekkel (valamint néhány speciális karakterrel) működik. Más kifejezési mechanizmusoktól függően azonban ez a viselkedés megváltozhat:
|
1 |
grep "<string>" <file> |
Horgony egyezés
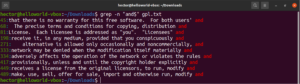
A horgonyok olyan speciális karakterek, amelyek meghatározzák, hogy a találatnak hol kell elhelyezkednie a sorban ahhoz, hogy érvényes egyezés legyen. Íme egy gyors példa az egyszerűsítés kedvéért. Ha csak azokat a sorokat szeretnénk megtalálni, amelyek a „GNU” karakterlánccal kezdődnek, akkor a regex-et használó grep így fog kinézni. Itt a „^” karakter a horgony, amely meghatározza, hogy csak a sor elején lévő egyezések érvényesek:
|
1 |
grep -n "^GNU" <file> |

Hasonlóképpen, ha csak azokat a sorokat szeretnénk megtalálni, amelyek a „works” karakterlánccal végződnek, akkor a regex-et használó grep így fog kinézni. Itt a „$” karakter a horgony, amely meghatározza, hogy csak a sor végén lévő egyezések érvényesek:
|
1 |
grep -n "and$" <file> |
Bármilyen karakterre való egyezés
Szöveges keresés végrehajtásakor előfordulhat, hogy meg szeretné határozni, hogy egy adott helyen bármilyen karakter állhat. A regexben ezt a pont karakter (.) fejezi ki.
Nézze meg ezt a példát. A GNU GPL 3 szöveges fájlban az „accept” és az „except” szavakban közös a „cept” rész. Ráadásul mindkét szóban két karakter áll a „cept” rész előtt. A következő grep parancs minden olyan szóra illeszkedni fog, amelynek két karaktere van a „cept” rész előtt:
|
1 |
grep -n "..cept" <file> |
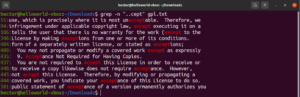
Ezen regex szerint más szavak is érvényes találatok, mint például a suscept, unaccept, unexpected stb.
Szögletes zárójelek
A regexben a szögletes zárójeles kifejezések meghatározzák, hogy a megadott helyen a zárójelen belül deklarált karakterek bármelyike állhat. Nézze meg a következő reguláris kifejezést:
|
1 |
t[wo]o |
Működés közben a too és a two szavak lesznek az érvényes találatok:
|
1 |
grep -n "t[wo]o" <file> |
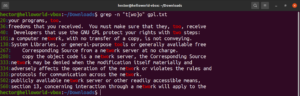
A szögletes zárójeles kifejezés érdekes lehetőségeket nyit meg. A szögletes zárójeles kifejezésekkel megadható, hogy a megadott helyen a zárójelen belül deklarált karaktereken kívül bármilyen más karakter állhat. Nézze meg a következő regex karakterláncot. Az egyezés csak akkor lesz érvényes, ha az „ode” előtt a „c”-től eltérő karakter áll:
|
1 |
"[^c]ode" |
Futtassa a GPL-3 licenc szöveges fájlján:
|
1 |
grep -n "[^c]ode" <file> |

A fájlból származó eredményen kívül más érvényes eredmények lennének a node, abode, anode stb. A szögletes zárójeles kifejezések karaktertartományt is leírhatnak. A következő regex azt mondja meg, hogy az egyezés akkor érvényes, ha a sor kezdete egy nagybetű:
|
1 |
"^[A-Z]" |
Futtassa a GPL-3 licenc szöveges fájlján. Ez a szöveges fájl összes sora lesz:
|
1 |
grep -n "^[A-Z]" <file> |
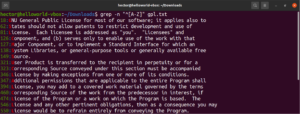
A könnyebb használat érdekében léteznek bizonyos karakterosztályok, amelyek meghatározott címkékkel rendelkeznek. Az előző példában az „A-Z” tartományt használtuk a nagybetűk meghatározására. Ehelyett használhatjuk a „[:upper:]” kifejezést is. Az eredmény ugyanaz lesz:
|
1 |
grep -n "^[[:upper:]]" <file> |
Minta ismétlése
Bizonyos helyzetekben előfordulhat, hogy egy adott mintát vagy regexet nullaszor vagy többször szeretne illeszteni. Ehhez a metakarakter a csillag (*). A következő reguláris kifejezés minden olyan zárójelre illeszkedni fog, amelyben csak betűk és szimpla szóközök vannak. Vegye figyelembe, hogy a kis- és nagybetűkészletek, valamint a szóközök deklarációja írásjelek nélkül, együtt szerepel:
|
1 |
"([a-zA-Z ]*)" |
Tegye működésbe a regexet a grep segítségével:
|
1 |
grep -n "([A-Za-z ]*)" <file> |

Metakarakterek használata literális karakterként
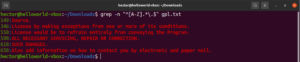
Eddig megismerkedtünk különféle metakarakterekkel, mint például a csillag (*), a pont (.), a horgonyok (^ és $), stb. Mindegyikük egyedi funkciót jelöl a regex kontextusában. A probléma akkor merül fel, ha literálként kell használni őket, nem pedig metakarakterként. Ilyen esetekben a metakarakter előtt álló visszaperjel (\\) azt jelzi, hogy szó szerinti értelemben kell használni, nem pedig metakarakterként. Nézze meg ezt a regex példát. Ez illeszkedni fog minden olyan sorra, amely nagybetűvel kezdődik és ponttal végződik:
|
1 |
grep -n "^[A-Z].*\.$" <file> |
Alternáció
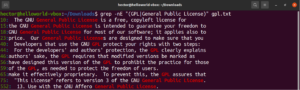
A szögletes zárójeles kifejezések használatával különböző lehetséges választásokat adhatunk meg egyetlen karakter illesztéséhez. A regex képes ugyanezt megtenni szavakkal és kifejezésekkel is. Az alternáció jelzésére a cső karaktert (|) használjuk. Az opciók zárójelek között maradnak, míg a cső karakter elválasztja őket egymástól. Két vagy több lehetséges opció is lehet ahhoz, hogy az egyezés érvényes legyen. Tekintse meg a következő regex példát. Ez a „GPL” és a „General Public License” kifejezésekre is illeszkedni fog:
|
1 |
grep -nE "(GPL|General Public License)" <file> |
Kvantorok
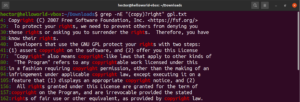
A csillag (*) metakarakter használatával képesek voltunk egy mintát nullaszor vagy többször megismételni. Azonban van még mivel dolgozni. A kvantorokat egyszerűbb egy példával elmagyarázni. A következő reguláris kifejezés azt írja le, hogy mind a „copyright” és a „right” érvényes egyezés. A kérdőjel (?) azt jelzi, hogy a „copy” rész opcionális az illeszkedés szempontjából:
|
1 |
grep -nE "(copy)?right" <file> |
A következő kvantor a pluszjel (+). Hasonlóan viselkedik, mint a csillag. A meghatározott mintának azonban legalább egyszer illeszkednie kell. A következő példában a reguláris kifejezés a „soft” szóra fog illeszkedni egy vagy több nem szóköz karakterrel:
|
1 |
grep -nE "soft[^[:space:]]+" <file> |
Az ismétlődések számának megadása
Lehetőség van az illeszkedés ismétlődésének számát is megadni. Ehhez használja a kapcsos zárójeleket ({}). A következő reguláris kifejezés minden olyan szóra illeszkedni fog, amely legalább három magánhangzót tartalmaz:
|
1 |
grep -nE "[aeiouAEIOU]{3}" <file> |

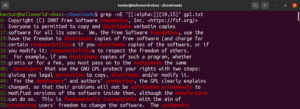
Ez a funkció lehetővé teszi az illeszkedés hosszának alsó és felső határának meghatározását is. A következő példában a regex minden olyan szóra illeszkedni fog, amely 10-15 karakter hosszú:
|
1 |
grep -nE "[[:alpha:]]{10,15}" <file> |
Összegzés
A szöveges fájlokban való keresés a grep segítségével meglehetősen praktikus. A reguláris kifejezések még érdekesebbé és hasznosabbá teszik a grep-pel való keresést. Ezenkívül a keresési mintát is pontosan az Ön igényeihez igazítják.
Bár bemutattunk néhányat a gyakori reguláris kifejezések közül, ez még csak a kezdet. Léteznek fejlettebb reguláris kifejezések is, amelyek a legfinomabb irányítást biztosítják a keresési viselkedés felett. A grep mellett a reguláris kifejezéseket más eszközök és programozási nyelvek is széles körben használják.
Kellemes számítógép-használatot!
Hozzászólások
Még nincsenek hozzászólások. Legyen Ön az első.