

A vállalkozások rengeteg adatot jelentenek, és ez megnehezíti a kezelésüket és menedzselésüket. Hagyományosan az iparág már évtizedek óta RDBMS rendszereket használ, de a Big Data 21. századi megjelenésével a NoSQL (Not only SQL) adatbázisok is képbe kerültek a nagyméretű strukturálatlan és félig strukturált adatok kezelésére.
Ebben a bejegyzésben egy MongoDB fürtöt fogok beállítani.
MongoDB egy ingyenes és nyílt forráskódú NoSQL dokumentum-adatbázis, amelyet széles körben használnak az általa biztosított magas szintű skálázhatóság és rugalmasság miatt.
A MongoDB éles környezetben történő bevezetéséhez javasolt a Replica Set-ek használata. A Replica Set-ek a MongoDB megfelelői a relációs világ Master/Slave felépítésének, de ezzel ellentétben a beállításuk rendkívül egyszerű, mivel minden be van építve. A Replica Set-ekről bővebben lásd a TutorialsPoint’s replikációs folyamatról szóló definícióját.
A MongoDB felhőszerver-fürt tervezése
Egy 3 csomópontos fürtöt fogok létrehozni. Fontos, hogy egyenlő erőforrásokat biztosítsunk nekik, mert bármelyikük elsődleges (azaz master) szerverré válhat. Ezek a csomópontok vagy gépek bármilyen operációs rendszeren futhatnak, de ebben az útmutatóban az Ubuntu 18.04 LTS-t fogom használni. A CloudSigma’s könyvtárából származó, előre telepített lemezkép csatolásáról és beállításáról részleteket talál ebben az útmutatóban.
Mivel a Replica Set lényege éppen az, hogy a fürt túlélje egyetlen csomópont leállását, meglehetősen értelmetlen lenne, ha az összes szerver ugyanazon a fizikai gazdagépen helyezkedne el. Szerencsére a CloudSigma kínál egy úgynevezett rendelkezésre állási csoportok funkciót. Ez azt jelenti, hogy utasíthatja a rendszert, hogy mindhárom szerverét különböző csoportokba sorolja. Így soha nem fognak ugyanazon a fizikai gazdagépen elhelyezkedni. Erről, valamint az egyéb biztonsági és üzletmenet-folytonossági funkciókról további információkat talál itt.
Szintén fontos a Linux 64 bites verziójának használata. Ennek oka egyszerűen az, hogy a MongoDB nem fut jól 32 bites rendszereken (erről bővebben itt).
A MongoDB telepítése a felhőben
Ez a rész meglehetősen egyszerű. Használja az előre konfigurált Ubuntu 18.04 lemezképek egyikét, vagy telepítse saját maga.
A CPU-, RAM- és lemezkonfiguráció valóban egyéni, és a terheléstől függ. Egy kisebb telepítéshez elegendőnek kell lennie egy 4 GHz-es CPU-nak, 4 GB RAM-nak és 10 GB-os lemeznek (a rendszer számára). A meghajtók csatlakoztatásakor győződjön meg arról, hogy VirtIO-t használ. Ha IDE-t használ, a teljesítmény jelentősen visszaesik. Emellett, mivel Replica Set-et hoz létre, az összes csomópontnak (és alkalmazásszervernek) ugyanazon a VLAN-on kell lennie.
Sok más felhőszolgáltatóval ellentétben itt nincs szükség a tárhely RAID10 vagy hasonló konfigurálására a teljesítmény javítása érdekében. Ahogy arról számos ügyfelünk beszámol, lenyűgöző teljesítményt fog kapni alapértelmezetten az SSD és a mágneses lemezek együttes használatával a CloudSigma-nál.
Ennek ellenére javaslom, hogy a MongoDB adatokat egy külön meghajtón tárolja. Ennek oka egyszerűen az, hogy egy bizonyos ponton olyan fájlrendszer-optimalizálásokat kellhet végrehajtania, amelyeket nem szeretne a teljes fájlrendszerén elvégezni.
Ezt szem előtt tartva a legegyszerűbb, ha ezt a meghajtót csak a szerverek beállítása után adja hozzá. Egyelőre fókuszáljunk csak a rendszer telepítésére. Ha saját maga telepíti (ahelyett, hogy az előre konfigurált rendszereket használná), javaslom, hogy nyomja meg az F4 billentyűt a rendszerindító menüben, és válassza a ‘Install a minimal virtual machine’ lehetőséget.
3 gépet hozok létre, mindegyiket az alábbi specifikációkkal:
- CPU: 4 GHz
- RAM: 4 GB
- SSD: 10 GB (Ubuntu 18.04 LTS), 20 GB (extra meghajtó)
Ahogy az az SSD résznél szerepel, egy 10 GB méretű meghajtót csatlakoztatok, amelyre az Ubuntu 18.04 LTS van telepítve.
Ezenkívül egy másik, 20 GB méretű üres meghajtót is csatlakoztatok hozzá a MongoDB adatok tárolására. Ennek mérete nagyban függ a használattól, de egy kis rendszerhez valószínűleg elegendőnek kell lennie 20 GB-nak. Mivel azonban néha nehéz megjósolni, hogy mennyi adatot fog tárolni, az LVM-et fogjuk használni. Ez lehetővé teszi, hogy később egyszerűen hozzáadjon egy másik meghajtót, és bővítse a kötetet anélkül, hogy elölről kellene kezdenie. Alternatív megoldásként használhat egyetlen meghajtót is, és később felskálázhatja aresize2fs.
A lemez hozzáadásához egyszerűen lépjen a ‘Drives’ szakaszba, kattintson a felül található ‘Create a new drive’ ikonra, adjon nevet az új lemeznek, és állítsa a méretét 20 GB-ra. Miután elmentette, lépjen arra a gépre, amelyhez csatlakoztatni szeretné, és a gép részleteinek meghajtók szakaszában kattintson az ‘Attach a drive’ lehetőségre, majd válassza ki a lemezt.
Most, hogy már három gépe van, továbbléphet a MongoDB adattároláshoz hozzáadott extra lemez csatolására mindegyik gépen. Javaslom, hogy ezt a lemezt partícióként adja hozzá. A particionálás lehetővé teszi az operációs rendszer számára, hogy az egyes régiókban lévő információkat külön kezelje. A lemez partícióként való hozzáadásához először ellenőrizni fogom a gépünkhöz csatlakoztatott összes lemezt. Ehhez a következő parancsot fogom végrehajtani:
|
1 |
fdisk -l |
A parancs végrehajtásakor megkapom a gépemen lévő lemezeket és eszközöket felsoroló kimenetet.
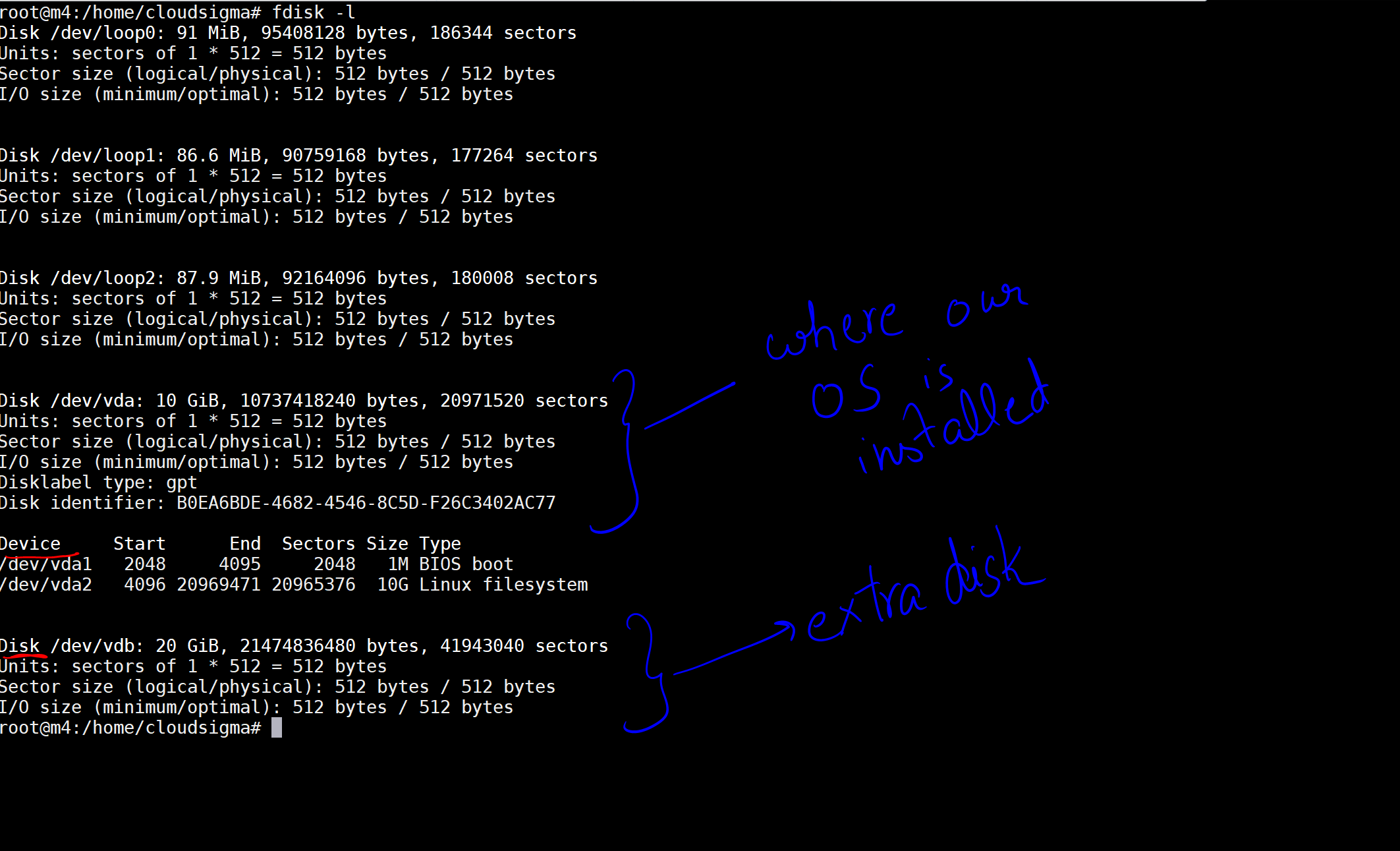
A képen egy 10 GB-os lemezt jelöltem meg, mint amelyre az operációs rendszerünk telepítve van. Ezután van egy másik, 20 GB-os lemez, amely most lett csatlakoztatva. A lemez helye: /dev/vdb. Ezen a lemezen a következő parancsokkal hozhat létre partíciót:
|
1 |
sudo fdisk /dev/vdb |
Ez megnyitja az fdisk segédprogramot, egy parancssori eszközt, amely lemezparticionálási funkciókat biztosít, és amelyben partíciókat hozhat létre a lemezünkön. Megjelenik egy “Command (m for help):” felszólítás, ahol be kell írnia a következőt: n egy új partíció létrehozásához, majd nyomja meg folyamatosan az Entert az alapértelmezett értékek elfogadásához. Miután pedig létrehozta a partíciót, írja be a következőt: w a változtatások mentéséhez. Ez így fog kinézni:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Parancs (m a súgóhoz): <strong>n</strong> Partíció típusa p elsődleges (0 elsődleges, 0 kiterjesztett, 4 szabad) e kiterjesztett (tároló a logikai partíciókhoz) Kiválasztás (alapértelmezett p): Az alapértelmezett válasz használata p. Partíció száma (1-4, alapértelmezett 1): Első szektor (2048-41943039, alapértelmezett 2048): Utolsó szektor, +szektorok vagy +méret{K,M,G,T,P} (2048-41943039, alapértelmezett 41943039): Létrehozva egy új partíció 1 of típussal 'Linux' és of mérettel 20 GiB. Parancs (m a súgóhoz): <strong>w</strong> A partíciós tábla módosítva lettaltered. Az ioctl() () hívása a partíciós -tábla újraolvasásáhoztable. Lemezek szinkronizálása. |
Létrehozott egy új, 1-es számú, ‘Linux’ típusú és 20 GiB méretű partíciót. Most, hogy a partíció létrejött, hozzunk létre egy LVM poolt:
|
1 2 3 |
sudo pvcreate /dev/vdb1 sudo vgcreate mongodb /dev/vdb1 sudo lvcreate -n db -L 19.5g mongodb |
A ‘19.5g’ értéket adtam meg, mivel a partícióm mérete 20g. Ezután hajtsa végre a következő parancsot a lemez nevének kiderítéséhez:
|
1 |
fdisk -l | grep mongo | awk '{print $2'} |
Ezt követően formázza a lemezt az ext4 módszerrel a következő paranccsal:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
sudo mkfs.ext4 /dev/mapper/mongodb-db Output: root@m4:/home/cloudsigma# sudo mkfs.ext4 /dev/mapper/mongodb-db mke2fs 1.44.1 (24-Már-2018) Létrehozás: fájlrendszer a következővel: 5217280 4k blokk és 1305600 inode-ok Fájlrendszer UUID: 695a62e6-021d-4fc0-945c-cc51a92d86da Szuperblokk biztonsági mentések tárolva itt: blokkok: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 Lefoglalás: csoport táblák: kész Írás: inode táblák: kész Létrehozás: napló (32768 blokkok): kész Írás: szuperblokkok és fájlrendszer elszámolási információk: kész |
Ezután hozzunk létre egy helyet a lemez csatolásához, valamint egy mappát, amelyben a MongoDB adatokat tároljuk.
|
1 |
sudo mkdir -p /mongodb/data |
Ahhoz, hogy bejegyzést adjon az fstab-hoz a csatolandó új lemezről, közvetlenül használhatja az alábbi parancsot:
|
1 |
echo -e "` blkid | grep mongodb | awk {'print $2'}`\t/mongodb\text4 auto,noexec,rw,sync,nouser\t0\t0" >> /etc/fstab |
A parancsban a blkid megadja az egyes lemezek UUID-ját – univerzálisan egyedi azonosítóját. Itt kigyűjtöm (grep) a MongoDB lemezhez tartozót, és ezt az UUID-t kombinálom a csatolási mappa helyével, a fájlrendszer típusával és a lemez egyéb beállításaival. Ezt a sort hozzáadom az /etc/fstab fájlhoz. Ha ezt nem teszi meg, hibaüzenetet kap a lemez csatolásakor. A bejegyzés így néz ki:
UUID=”695a62e6-021d-4fc0-945c-cc51a92d86da” /mongodb ext4 auto,noexec,rw,sync,nouser 0 0
Most már csatolhatja a lemezt a /mongodb helyre:
|
1 |
sudo mount /mongodb |
Installing MongoDB
A rendszer előkészítése után térjünk át a MongoDB telepítésére. Bár az Ubuntu kínál egy MongoDB verziót a saját tárolójában, javaslom, hogy inkább a hivatalos MongoDB verziót használja. Ennek az az oka, hogy az Ubuntu tárolója meglehetősen le van maradva a kiadások terén, így ha a legtöbbet szeretné kihozni a MongoDB-ből, a hivatalos kiadásokhoz kell fordulnia.
Mivel a MongoDB saját tárolót kínál, ezt egyszerűen hozzáadhatja a rendszeréhez, majd a szokásos módon telepítheti a MongoDB-t. A követendő lépések a következők:
Először importálja a csomagkezelő rendszer által használt nyilvános kulcsot:
|
1 |
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 9DA31620334BD75D9DCB49F368818C72E52529D4 |
Ezután létrehozok egy listafájlt. Ez tartalmazza majd azt a tárolót, ahol a MongoDB található, így a rendszere onnan tudja letölteni:
|
1 |
echo "deb [ arch=amd64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.0.list |
Most frissítem a helyi csomagadatbázisomat, hogy figyelembe vegyem a változásokat.
|
1 |
sudo apt-get update |
Most már telepíthetem a csomagot a következő paranccsal:
|
1 |
sudo apt-get install -y mongodb-org |
Telepítettem a MongoDB-t mindegyik gépre.
|
1 |
sudo service mongod start |
Most már a MongoDB fut, és az adatok a létrehozott meghajtón vannak. Ha nagy terhelés és/vagy sok kapcsolat várható, szükség lehet a ulimit értékek növelésére.
Ha szeretne mélyebb betekintést nyerni az adataiba, érdemes regisztrálnia a MongoDB MMS szolgáltatására is, amely egy ingyenes, felhőalapú megfigyelő szolgáltatás a MongoDB-hez.
A replikakészlet (Replica Set) létrehozása a MongoDB felhőhöz
Most hozzunk létre egy replikakészletet. Ezt megelőzően biztosítania kell, hogy a gépek kommunikálni tudjanak egymással. Ebből a célból adja hozzá ezeket a bejegyzéseket az /etc/hosts fájlhoz
|
1 2 3 |
IP-1 m1.mongo.cluster m1 IP-2 m2.mongo.cluster m2 IP-3 m3.mongo.cluster m3 |
A hitelesítéshez megpróbálhatja pingelni a gépeket a gépnév használatával. Tehát ha az 1-es gépem IP-címe az IP-1, mondjuk 213.189.123.12, akkor ahelyett, hogy ezt írná:
|
1 |
ping 123.189.123.12 |
ezt fogom írni:
|
1 2 3 |
ping m1.mongo.cluster vagy ping m1. |
Ha aktiválta a tűzfalat (amit valóban meg kellene tennie), győződjön meg arról, hogy a csomópontok képesek TCP-forgalmat küldeni és fogadni a belső interfész 28017-es és 27017-es portján.
Most mindegyik gépen indítsa el a mongod szolgáltatást a következő parancsokkal.
Az m1 gépen:
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m1.mongo.cluster |
Ezután az m2 gépen:
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m2.mongo.cluster |
Az m3 gépen:
|
1 |
mongod --dbpath /mongodb/data --replSet rs0 --bind_ip localhost,m3.mongo.cluster |
Itt,
mongod a szolgáltatás neve
dbpath az adatbázis-könyvtárunk helye
replSet a replikációs készletünk neve. Ennek meg kell egyeznie az ugyanabban a replikakészletben lévő összes gép esetében
bind_ip azon gép gépneve, amelyen futtatja.
Miután elindította a mongod szolgáltatást, lépjen az elsődleges szerverre (az én esetemben az m1-et választottam), és futtassa a mongo parancsot.
|
1 |
mongo |
Ez elindítja a MongoDB terminált. A terminálon indítsa el a replicaSet-et az alábbi paranccsal. Ez létrehozza a replicaSet-et az alapértelmezett konfigurációkkal:
|
1 |
rs.initiate() |
Most pedig adjuk hozzá a másik két gépet replikaként a következő parancsokkal:
|
1 2 |
rs.add("m2.mongo.cluster") rs.add("m3.mongo.cluster") |
A státuszt a következő paranccsal kísérheti figyelemmel:
|
1 |
rs.status() |
Ez minden. Most már működnie kell a MongoDB klaszterének a CloudSigma rendkívül gyors felhőjében.
Hozzászólások
Még nincsenek hozzászólások. Legyen Ön az első.