

Az Elastic Stack (korábbi nevén az ELK Stack) egy hatékony megoldás a központosított naplózásra. Ez egy nyílt forráskódú szoftvergyűjtemény, amelyet a Elastic fejlesztett ki. Lehetővé teszi a rendszergazdák számára, hogy bármilyen forrásból, bármilyen formátumban előállított naplókat keressenek, elemezzenek és vizualizáljanak. Ez a központosított naplózásként ismert gyakorlat egyik formája. A központosított naplózás nagyon hasznos lehet a szerverekkel és alkalmazásokkal kapcsolatos problémák pontos meghatározásakor, mivel lehetővé teszi az összes napló egyetlen helyről történő keresését. Segíthet a több szerveren fellépő problémák azonosításában is, a naplók egy adott időpontban történő korrelálásával.
Ebben az útmutatóban bemutatjuk, hogyan telepítheti az Elastic Stack-et Ubuntu 18.04 rendszerre. Először kövesse az útmutatónkat, hogy egyszerűen telepítse Ubuntu szerverét a CloudSigma-n.
Az Elastic Stack Ubuntu-n
Az Elastic Stack a következő összetevőkből áll:
- Elasticsearch: Egy elosztott RESTful keresőmotor. Ez tárolja az összes összegyűjtött adatot.
- Logstash: Az Elastic Stack adatfeldolgozó része. A bejövő adatokat az Elasticsearch-nek küldi.
- Kibana: Egy webes felület, amely keresési és napló-vizualizációs funkciókat kínál.
- Beats: Egy könnyűsúlyú, egyetlen célra szolgáló adatküldő. Képes adatokat küldeni számos gépről a Logstash vagy az Elasticsearch felé.
A stack minden egyes összetevőjét manuálisan kell telepítenie.
Előfeltételek
Mielőtt továbblépne az Elastic Stack telepítésével, számos rendszerkövetelménynek kell teljesülnie:
- Hardverkövetelmények:
- CPU: 2 CPU (nem root sudo felhasználóval elérhető)
- RAM: 4GB
- OpenJDK 11 (a legújabb Java LTS kiadás). Ennek telepítéséhez tekintse meg a Java beállításáról szóló útmutatónkat Ubuntu 18.04-en.
- Nginx megfelelő konfigurációkkal. Követheti a Nginx Ubuntu 18.04-re történő telepítéséről szóló útmutatónkat a beállításához.
Vegye figyelembe, hogy a tárhely mennyisége az összegyűjtendő és tárolandó naplók számától függ. Emellett az Elastic Stack a szerverrel kapcsolatos értékes információkat is kezel. Az adatátvitel biztonságának megőrzése érdekében erősen javasoljuk egy TLS/SSL tanúsítvány konfigurálását. Kövesse ezt a útmutatót az ingyenes SSL-tanúsítvány beszerzéséhez az Nginx szerverén.
A titkosított szerver mellett a következő lépésekre is szükség lesz:
- Egy FQDN (teljesen minősített tartománynév). Ebben az útmutatóban ez <domain> lesz.
- A következő tartományok mindkét DNS-rekordja a szerverre mutat.
- Egy A rekord, ahol a <domain> a szerver nyilvános IP-címére mutat.
- Egy A rekord, ahol a www.<domain> a szerver nyilvános IP-címére mutat.
Az Elastic Stack telepítése
-
Az Elastic repó konfigurálása
Az Elastic Stack összetevői nem érhetők el közvetlenül a hivatalos Ubuntu repóból. Szerencsére az Ubuntu lehetővé teszi harmadik féltől származó repók használatát a csomagok telepítéséhez. Célunk érdekében hozzáadjuk az Elastic csomagtárolót. A repó az összes Elastic csomag legújabb frissítését kínálja. Minden Elastic csomag az Elasticsearch aláíró kulccsal van aláírva a csomaghamisítás megelőzése érdekében. Először adja hozzá a kulcsot az Ubuntu kulcstartójához:
|
1 |
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - |
Ezután adja hozzá az Elastic forráslistát a „sources.list.d” könyvtár alá. Ez az a dedikált könyvtár, amelyet az APT használ az új források keresésére:
|
1 |
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list |
Végül frissítse az APT gyorsítótárat:
|
1 |
sudo apt update |
A hivatalos dokumentáció szerint ajánlott az egyes összetevőket az ebben az útmutatóban bemutatott sorrendben telepíteni. Ez biztosítja, hogy az egyes termékek által igényelt összetevők a megfelelő helyen legyenek.
-
Az Elasticsearch telepítése és konfigurálása
Miután az Elastic repó konfigurálva van, az APT készen áll az összes Elastic csomag letöltésére és telepítésére. Futtassa a következő parancsot az Elasticsearch telepítéséhez:
|
1 |
sudo apt install elasticsearch |
Most már konfigurálhatja az Elasticsearch-öt. Az „elasticsearch.yml” fájl konfigurációs beállításokat tartalmaz a fürtökről, csomópontokról, útvonalakról, hálózatokról, memóriáról, átjáróról és egyebekről. A legtöbbjük előre konfigurálva van a fájlban. Ezután nyissa meg az Elasticsearch konfigurációs fájlját egy tetszőleges szövegszerkesztővel:
|
1 |
sudo vim /etc/elasticsearch/elasticsearch.yml |
Az Elasticsearch bárhonnan a 9200-as porton hallgat. Javasoljuk, hogy korlátozza a külső hozzáférést az Elasticsearch-höz, hogy megakadályozza a kívülállókat az adatok olvasásában vagy az Elasticsearch fürtök leállításában a REST API-ján keresztül. Az Elasticsearch-höz való hozzáférés korlátozásához és a biztonság megerősítéséhez törölje a megjegyzést a következő sorból, és cserélje ki az értékét:
|
1 |
network.host: localhost |
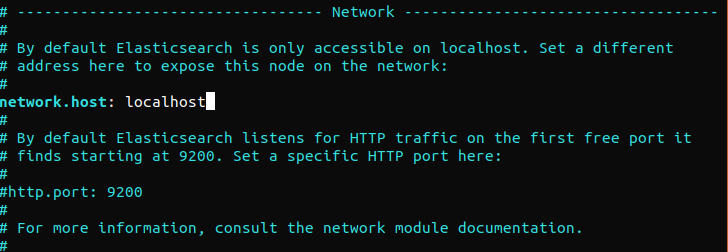
Ha az Elasticsearch-nek egy adott IP-címen kell hallgatnia, cserélje ki a „localhost” értéket a cél IP-címre. Ez a minimális konfigurációs követelmény az Elasticsearch futtatása előtt. Mentse és zárja be a konfigurációs fájlt. Ezután indítsa el az Elasticsearch szolgáltatást. Az Elasticsearch elindítása eltarthat néhány pillanatig:
|
1 |
sudo systemctl start elasticsearch |
Ezt követően gondoskodnia kell arról, hogy az Elasticsearch minden alkalommal elinduljon, amikor a szerver elindul:
|
1 |
sudo systemctl enable elasticsearch |
A következő parancs ellenőrzi, hogy fut-e az Elasticsearch szolgáltatás. Mindössze egy HTTP-kérés elküldésére van szükség:
|
1 |
curl -X GET "localhost:9200" |
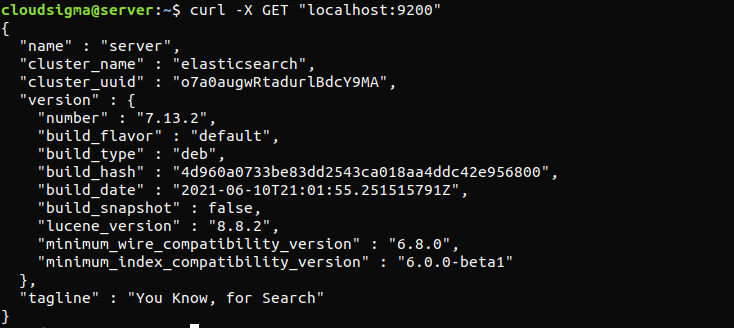
A válasz valahogy így fog kinézni. Ez egy olyan válasz lesz, amely néhány alapvető információt mutat a helyi csomópontról.
A Kibana irányítópult telepítése és konfigurálása
A Kibana közvetlenül elérhető az Elastic tárolóból. Vegye figyelembe, hogy a Kibana-t csak azután szabad telepítenie, miután már telepítette az Elasticsearch szoftvert. Feltételezve, hogy a tároló már elérhető, az APT közvetlenül le tudja kérni és telepíteni tudja a Kibana-t:
|
1 |
sudo apt install kibana |
A telepítés után engedélyezze és indítsa el a Kibana szolgáltatást:
|
1 2 |
sudo systemctl enable kibana sudo systemctl start kibana |
Alapértelmezés szerint a Kibana úgy van konfigurálva, hogy csak a „localhost”-on hallgasson. A külső hozzáféréshez egy fordított proxy konfigurálása szükséges. Itt az Nginx lesz a fordított proxy. Használja az openssl parancsot egy adminisztrátori Kibana felhasználó létrehozásához. Ez lesz a felhasználói fiók a Kibana webes felületének eléréséhez. Itt a példa felhasználónév a „kibana_admin” lesz. A jobb biztonság érdekében javasoljuk egy nem szabványos felhasználónév használatát. A következő parancs létrehoz egy adminisztrátort a Kibana számára. A felhasználónév és a jelszó generálásra kerül, és a „htpasswd.users” fájlban lesz tárolva. Az Nginx-et úgy kell konfigurálni, hogy ezt a felhasználónevet és jelszót használja:
|
1 |
echo "kibana_admin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users |
Adja meg és erősítse meg a jelszót a felszólításra. Ez a jelszó fontos lesz a Kibana felület eléréséhez. Ezt követően létre kell hoznia egy Nginx szerverblokk-fájlt. A bemutatóhoz ez az example.com lesz. Ez bármilyen más leíró név is lehet. Ha a szerverhez FQDN és DNS rekordok vannak konfigurálva, a fájl neve az FQDN után is elnevezhető:
|
1 |
sudo vim /etc/nginx/sites-available/example.com |
Ha van már meglévő tartalom, távolítsa el azt, és cserélje ki a következő kódsorokkal:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
server { listen 80; server_name example.com; auth_basic "Korlátozott hozzáférés"; auth_basic_user_file /etc/nginx/htpasswd.users; location / { proxy_pass http://localhost:5601; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } } |
Mentse el és zárja be a fájlt. Hozzon létre egy szimbolikus linket az új konfigurációhoz a „sites-enabled” könyvtárban. Ha már létezik azonos nevű link, akkor ez a lépés szükségtelen lehet:
|
1 |
sudo ln -s /etc/nginx/sites-available/example.com /etc/nginx/sites-enabled/example.com |
A következő parancs arra kéri az Nginx-et, hogy ellenőrizze, van-e szintaktikai hiba:
|
1 |
sudo nginx -t |
Ha bármilyen szintaktikai probléma merül fel, ellenőrizze, hogy a fájl tartalma megfelelően lett-e elhelyezve. Ezután indítsa újra az Nginx szolgáltatást:
|
1 |
sudo systemctl restart nginx |
Utasítsa az UFW-t, hogy engedélyezze a kapcsolatot az Nginx-hez:
|
1 |
sudo ufw allow 'Nginx Full' |
A Kibana mostantól elérhető az Elastic Stack szerver FQDN-jén vagy nyilvános IP-címén keresztül. Ellenőrizze a Kibana szerver állapotoldalát:
|
1 |
http://<server_ip>:5601/status |
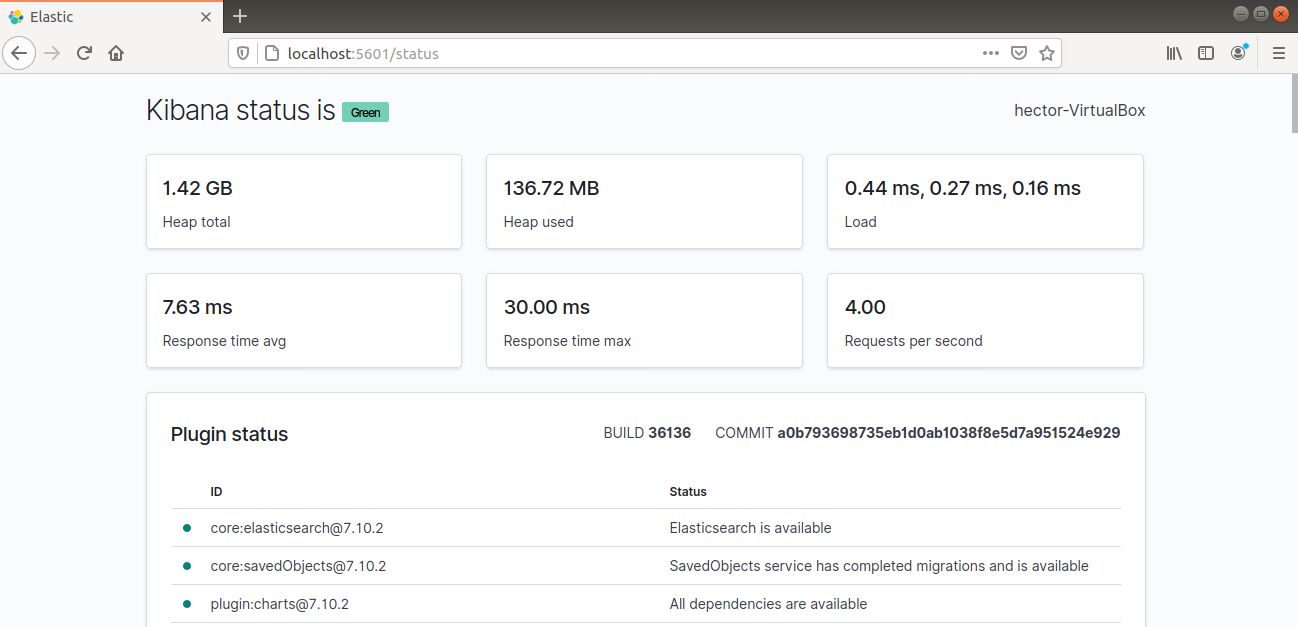
A Logstash telepítése és konfigurálása
Bár a Beats közvetlenül is küldhet adatokat az Elasticsearch’s adatbázisába, az adatok feldolgozásához ajánlott a Logstash használata. A Logstash képes összegyűjteni az adatokat és közös formátumba konvertálni azokat, mielőtt egy másik adatbázisba exportálná. Futtassa a következő APT parancsot a Logstash telepítéséhez:
|
1 |
sudo apt install logstash |
A telepítés befejeztével ideje konfigurálni a Logstash-t. A Logstash konfigurációs fájljai JSON formátumúak. Mindegyik megtalálható az „/etc/logstash/conf.d” könyvtárban. Hasznos úgy gondolni a Logstash-re, mint egy csővezetékre (pipeline), amely az egyik végén fogadja az adatokat, feldolgozza azokat, majd elküldi a célállomásra. Egy Logstash csővezetékhez két kötelező elem szükséges – input és output egy opcionális elemmel – filter. Az input beépülő modul fogadja az adatokat, a filter beépülő modul feldolgozza azokat, az output beépülő modul pedig kiírja az adatokat a célállomásra. A következő parancs létrehoz egy konfigurációs fájlt, amely beállítja a Logstash-t a Filebeat bemenethez (input):
|
1 |
sudo vim /etc/logstash/conf.d/02-beats-input.conf |
Adja meg a következő input konfigurációt. Ez egy olyan beats bemenetet (input) ír le, amely az 5044-es porton fog figyelni TCP-n:
|
1 2 3 4 5 |
input { beats { port => 5044 } } |
A következő lépés a „10-syslog-filter.conf” nevű konfigurációs fájl létrehozása. Ezt egy szűrő (filter) beállítására fogjuk használni a syslogs (rendszernaplók) számára:
|
1 |
sudo vim /etc/logstash/conf.d/10-syslog-filter.conf |
Adja meg a következő syslog konfigurációs kódot. Ez a kód közvetlenül elérhető az Elastic útmutatóból. Ez a kód bemutatja az input konfigurációt a Logstash számára:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
input{ beats{ port => 5044 host => "0.0.0.0" } } filter { if [fileset][module] == "system" { if [fileset][name] == "auth" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$", "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] } pattern_definitions => { "GREEDYMULTILINE"=> "(.|\n)*" } remove_field => "message" } date { match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } geoip { source => "[system][auth][ssh][ip]" target => "[system][auth][ssh][geoip]" } } else if [fileset][name] == "syslog" { grok { match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] } pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" } remove_field => "message" } date { match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } } } } |
A következő konfigurációs fájl a kimenettel fog foglalkozni. Nyisson meg egy új fájlt „30-elasticsearch-output.conf” néven:
|
1 |
sudo vim /etc/logstash/conf.d/30-elasticsearch-output.conf |
Írja be a következő kódot. Ez a kód bemutatja a Logstash kimeneti konfigurációját:
|
1 2 3 4 5 6 7 |
output { elasticsearch { hosts => ["localhost:9200"] manage_template => false index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}" } } |
Tesztelje a Logstash konfigurációt. Ezután futtassa a következő parancsot:
|
1 |
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t |
Ha nincs hiba, a Logstash a következő sikeres üzenetet fogja kiírni. Ha nem volt sikeres, ellenőrizze, hogy minden konfigurációs fájl a megfelelő kódokat tartalmazza-e. Végül indítsa el és engedélyezze a Logstash szolgáltatást:
|
1 2 |
sudo systemctl start logstash sudo systemctl enable logstash |
Most, hogy a Logstash sikeresen fut és teljesen be van konfigurálva, telepítsük a Filebeatet.
A Filebeat telepítése és konfigurálása
Az Elastic Stack adatküldőket, úgynevezett „Beats”-eket használ az adatok különböző forrásokból történő gyűjtésére és azok Logstash/Elasticsearch felé történő továbbítására. Íme egy rövid lista az Elastic elérhető Beats eszközeiről:
- Filebeat: Naplófájlok gyűjtése/továbbítása.
- Metricbeat: Metrikák gyűjtése/továbbítása rendszerekből és szolgáltatásokból.
- Packetbeat: Hálózati adatok gyűjtése/elemzése.
- Winlogbeat: Windows eseménynaplók gyűjtése.
- Auditbeat: Linux audit keretrendszer adatainak gyűjtése és a fájlintegritás figyelése.
- Heartbeat: Szolgáltatások elérhetőségének figyelése.
Ebben az útmutatóban a Filebeatre lesz szükségünk a helyi naplók Elastic Stackbe történő továbbításához. Először telepítse a Filebeatet:
|
1 |
sudo apt install filebeat |
Most már konfigurálhatja a Filebeat-et. Először is csatlakoznia kell a Logstash-hez. A Filebeat-hez mellékelt példakonfigurációt fogjuk használni. Nyissa meg a konfigurációs fájlt egy szövegszerkesztőben. Vegye figyelembe, hogy mivel a fájl YAML formátumú, a megfelelő behúzás fontos:
|
1 |
sudo vim /etc/filebeat/filebeat.yml |
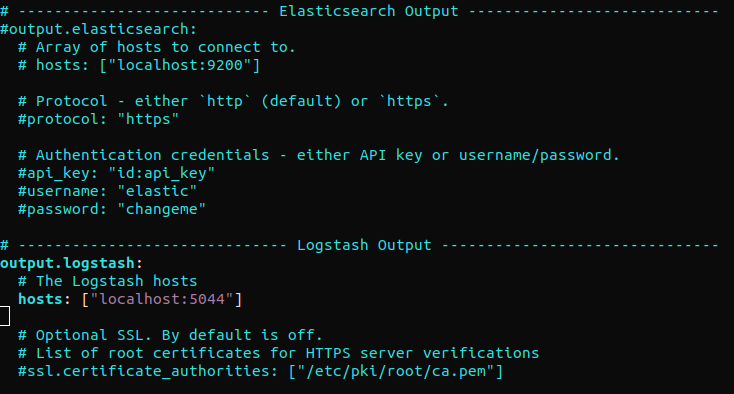
Keresse meg az „output.elasticsearch” szakaszt, és kommentelje ki a következő sorokat. Ez úgy konfigurálja a Filebeat-et, hogy az eseményeket közvetlenül az Elasticsearch/Logstash-nek küldje további feldolgozásra. Ezután ugorjon az „output.logstash” szakaszra. Ezután vegye ki a kommentet a következő sorok elől:
|
1 2 3 4 5 6 7 |
#output.elasticsearch: # Kapcsolódási gazdagépek tömbje. # hosts: ["localhost:9200"] output.logstash: # A Logstash gazdagépek hosts: ["localhost:5044"] |
A Filebeat támogatja a modulokat, amelyek kiterjeszthetik a funkcionalitását. Ebben az útmutatóban a rendszermodult fogjuk használni, amely összegyűjti és elemzi a gyakori Linux disztribúciók rendszernaplózási szolgáltatása által generált naplókat. Engedélyezze a Filebeat rendszermodult:
|
1 |
sudo filebeat modules enable system |
A következő Filebeat parancs kilistázza az összes engedélyezett és letiltott modult:
|
1 |
sudo filebeat modules list |
Alapértelmezés szerint a Filebeat a syslog és az autorizációs naplók alapértelmezett útvonalait követi. A modulok paraméterei a „/etc/filebeat/modules.d/system.yml” konfigurációs fájlban érhetők el.
A következő lépés az indexsablon betöltése az Elasticsearch-be. Egy Elasticsearch index hasonló tulajdonságokkal rendelkező dokumentumok gyűjteményét jelöli. Minden indexhez tartozik egy név. A név szükséges a benne végzett különböző műveletek végrehajtásakor. Az indexsablon automatikusan alkalmazásra kerül minden alkalommal, amikor új index jön létre. Ezután töltse be a sablont:
|
1 |
sudo filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]' |
A Filebeat alapértelmezés szerint tartalmaz egy minta irányítópultot a Kibana számára. Ez segít a Filebeat adatok vizualizálásában a Kibanában. Az irányítópult használata előtt azonban létre kell hozni az indexmintát, és be kell tölteni az irányítópultokat a Kibanába. Amíg az irányítópultok betöltődnek, a Filebeat kapcsolatba lép az Elasticsearch-csel a verzióinformációkért. Az irányítópultok betöltéséhez, ha a Logstash engedélyezve van, a Logstash kimenetet le kell tiltani, az Elasticsearch kimenetet pedig engedélyezni kell. A következő parancs elvégzi a feladatot:
|
1 |
sudo filebeat setup -e -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601 |
Végül elindíthatja a Filebeat-et:
|
1 2 |
sudo systemctl start filebeat sudo systemctl enable filebeat |
Most itt az ideje tesztelni az Elastic Stack konfigurációját. Ha megfelelően lett konfigurálva, a kimenet valahogy így fog kinézni:
|
1 |
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty' |
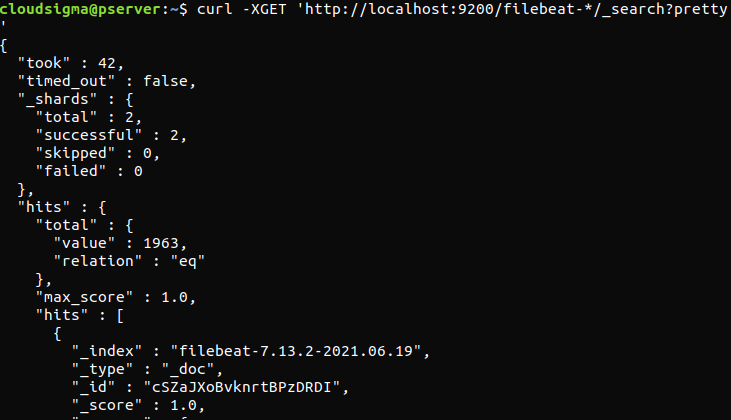
Ha a kimenet összesen 0 találatot jelez, az Elasticsearch nem tölt be naplókat a keresett index alatt. Ez azt jelzi, hogy hiba történt a konfigurációban. Ha a kimenet a vártnak megfelelő volt, akkor az Elastic Stack sikeresen be van konfigurálva.
Kibana irányítópultok áttekintése
Most itt az ideje felfedezni a már telepített Kibana webes felületet. Először nyissa meg a Kibana irányítópultot. Ennek az Elastic Stack szerver FQDN-jén vagy nyilvános IP-címén kell lennie:
|
1 |
http://<server_ip>:5601 |
Adja meg a korábban generált bejelentkezési adatokat. A bejelentkezés után az irányítópult így fog kinézni:
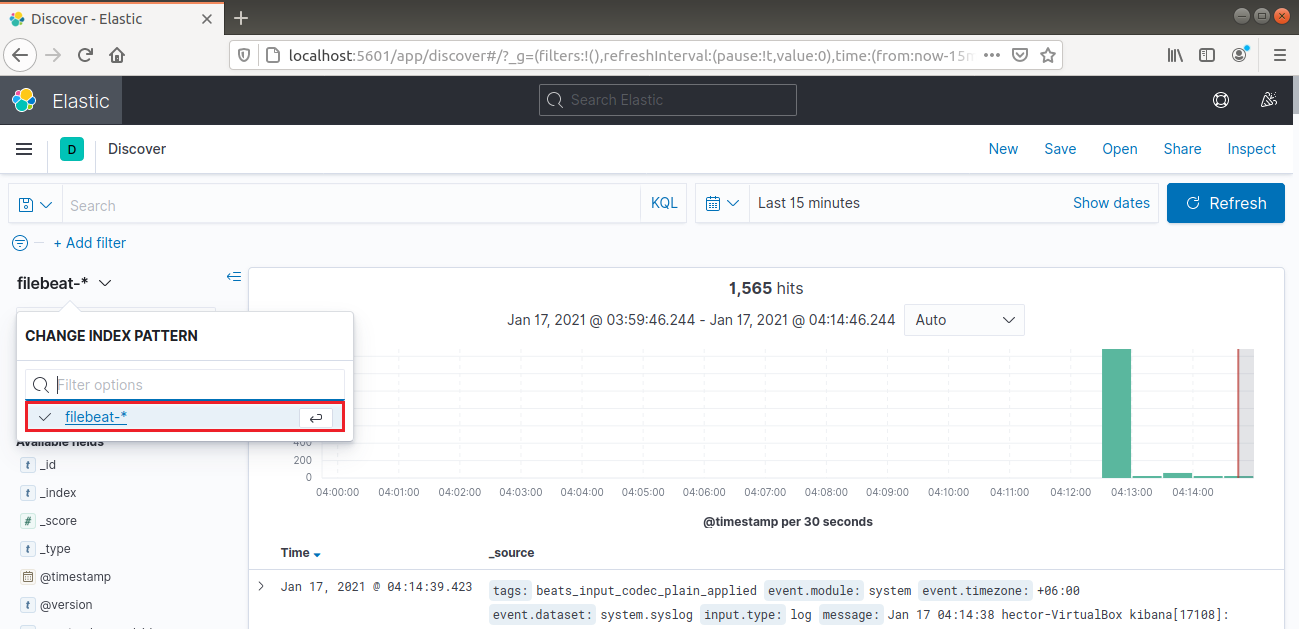
A bal oldali navigációs sávból válassza a „Discover” lehetőséget. Ezután válassza ki a „filebeat-*” mintát. Ez az elmúlt 15 percben összegyűjtött összes naplót mutatja. Lehetőség van a naplók keresésére és böngészésére, valamint az irányítópult testreszabására:
A bal oldali navigációs sávból lépjen a Dashboard >> Filebeat System menüpontra. Itt a Filebeat rendszermoduljának összes minta irányítópultja elérhető.
A következő példában a syslog üzenetek alapján részletez különböző statisztikákat:
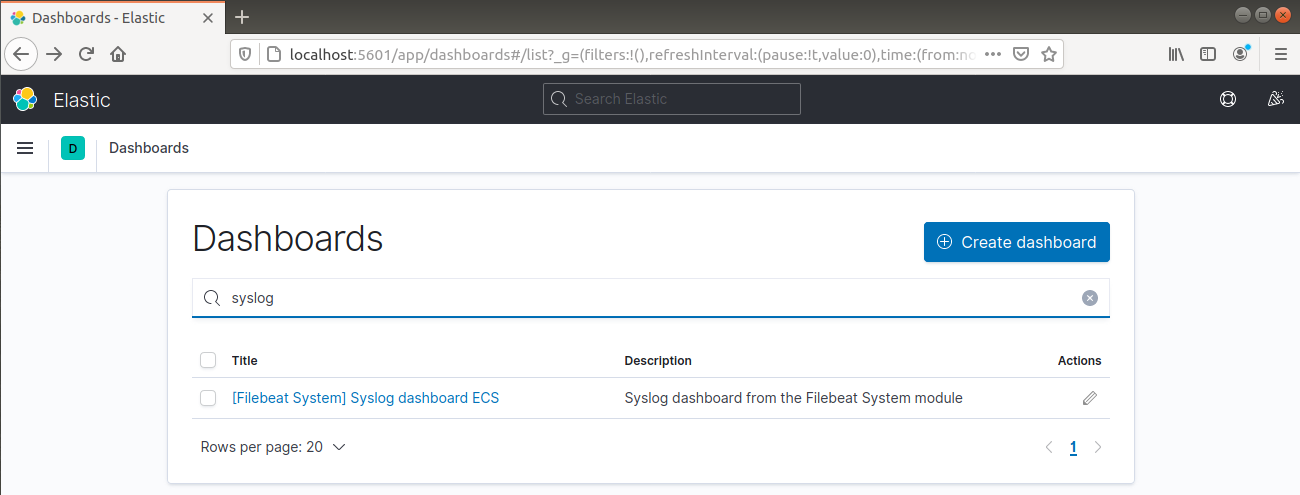
Azt is képes jelenteni, hogy mely felhasználók hajtottak végre parancsokat a sudo segítségével:
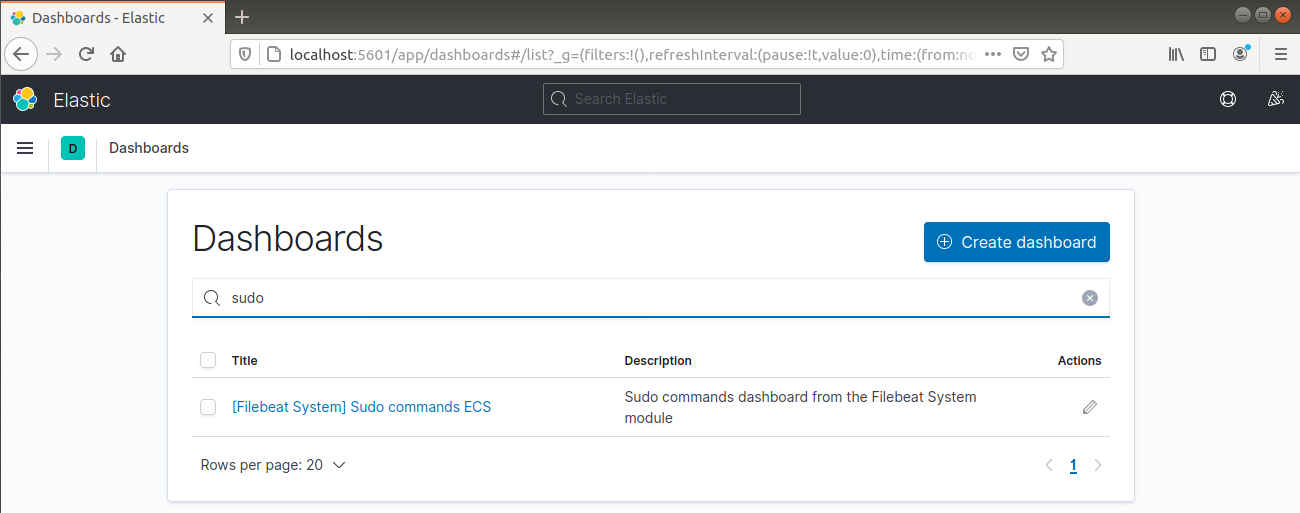
Végezetül a Kibana lehetőséget ad számos egyéb funkció, például a grafikonok és a szűrés felfedezésére, úgyhogy bátran kísérletezzen egyedül is.
Záró gondolatok
Az Elastic Stack egy hatékony megoldás a rendszernaplók elemzésére. Tartsa szem előtt, hogy bár bármilyen napló vagy indexelt adat elküldhető a Logstash-nek a Beats segítségével, az még hasznosabbá válik, ha a Logstash szűrőkön keresztül elemezzük és strukturáljuk.
Kellemes számítógépezést!
Hozzászólások
Még nincsenek hozzászólások. Legyen Ön az első.