

Web scraping, a web crawling, a web harvesting vagy a webes adatkinyerés (web data extraction) szinonimák, amelyek az internetes weboldalakról történő adatbányászatot jelentik. A webes adatkaparók (web scrapers) vagy webes keresők (web crawlers) olyan eszközök, amelyek programozottan végigjárják a weboldalakat, és kinyerik a szükséges adatokat. Ezek az adatok, amelyek általában nagy szöveghalmazok, felhasználhatók elemzési célokra, termékek megértésére, vagy egy adott weboldallal kapcsolatos kíváncsiság kielégítésére.
Ha kíváncsi arra, hogyan foghat hozzá a webes kereséshez (web crawling), egy egyszerű adatkészleten keresztül bemutatjuk a web scraping alapjait. A programozási tapasztalatától függetlenül képesnek kell lennie követni ezt az útmutatót. A gyakorlati példához a mi CloudSigma blog-unkat fogjuk használni. Megpróbálunk információkat szerezni a blogoldalunkon található útmutatókról. Mire elolvassa ennek az útmutatónak a befejezését, már egy működő, Python 3 segítségével készült webes adatkaparóval fog rendelkezni, amely több oldalt is bejár a blog szekciónkban, majd megjeleníti az adatokat a képernyőjén.
Az alapvető webes adatkaparó létrehozásából szerzett ismereteket felhasználva továbbfejlesztheti azt, és létrehozhatja saját webes adatkaparóit. Ez szórakoztató lesz, kezdjük el!
Előfeltételek
Ez egy gyakorlati útmutató, így a sikeres követéshez rendelkeznie kell egy helyi fejlesztői környezettel a Python 3-hoz. Először is hivatkozhat az arról szóló útmutatónkra, hogyan kell telepíteni a Python 3-at és beállítani egy helyi programozási környezetet Ubuntu-n.
Scrapy
A web scraping két lépésből áll: az első lépés a weboldalak megtalálása és letöltése, a második lépés pedig a weboldalak bejárása és az információk kinyerése belőlük.
Számos módszer és könyvtár létezik, amellyel a semmiből építhető fel webes adatkaparó számos programozási nyelven. Ez azonban problémákat okozhat a jövőben, amikor a webes adatkaparója bonyolulttá válik, vagy amikor egyszerre több, különböző beállításokkal és mintákkal rendelkező oldalt kell bejárnia. Elég nehéz feladat lehet kitalálni, hogyan alakítsa át a lekapart adatokat különböző formátumok, például CSV, XML vagy JSON között.
Bár egyesek értékelhetik a saját webes adatkaparó semmiből való felépítésének kihívását, jobb, ha nem találja fel újra a spanyolviaszt, hanem egy olyan meglévő könyvtárra épít, amely kezeli mindezeket a problémákat. A Scrapy nevű Python könyvtárat fogjuk használni a Python 3-mal együtt a webes adatkaparó megvalósításához ebben az útmutatóban. A Scrapy egy nyílt forráskódú eszköz, és az egyik legnépszerűbb és legerősebb Python web scraping könyvtár. A Scrapy-t úgy hozták létre, hogy kezelje azokat a közös funkciókat, amelyekkel minden adatkaparónak rendelkeznie kell. Így nem kell újra feltalálnia a spanyolviaszt, amikor webes keresőt szeretne megvalósítani. A Scrapy segítségével az adatkaparó felépítésének folyamata egyszerűvé és szórakoztatóvá válik.
A Scrapy elérhető a PyPi tárhelyről, amelyet általában pip-ként – a Python Package Index-ként – ismernek. A PyPi egy közösségi tulajdonban lévő tárhely, amely a legtöbb Python-csomagot tárolja. Amikor telepíti és beállítja a Python 3-at a helyi fejlesztői környezetében, az a pip-et is telepíti, amelyet a Python-csomagok telepítésére használhat.
1. lépés: Hogyan építsünk egy egyszerű webes adatkaparót
Először is, a Scrapy telepítéséhez futtassa a következő parancsot:
|
1 |
pip install scrapy |
Tetszés szerint követheti a Scrapy official installation instructions a dokumentációs oldalon. Ha sikeresen telepítette a Scrapy-t, hozzon létre egy mappát a projektnek egy tetszőleges névvel:
|
1 |
mkdir cloudsigma-crawler |
Navigáljon be a mappába, és hozza létre a kód fő fájlját. Ez a fájl fogja tartalmazni az útmutató összes kódját:
|
1 |
touch main.py |
Ha szeretné, a fenti parancs helyett létrehozhatja a fájlt a szövegszerkesztőjével vagy IDE-jével is.
Ezután nyissa meg a fájlt, és kezdjük egy alapvető, Scrapy-t használó adatkaparó létrehozásával. Létrehozunk egy Python osztályt, amely kiterjeszti a scrapy.Spider-t, a Scrapy egyik alapvető spider osztályát. Ennek az osztálynak két kötelező attribútuma lesz, az alábbiak szerint:
- name — egy karakterlánc (string) név a spider azonosítására (tetszőleges nevet megadhat).
- start_urls — egy tömb, amely a bejárandó URL-ek listáját tartalmazza. Egyetlen URL-lel kezdünk.
Adja hozzá a következő kódrészletet a megnyitott fájlhoz az alapvető spider létrehozásához:
|
1 2 3 4 5 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] |
Az alábbiakban az egyes kódsorok magyarázata olvasható:
Az első sor importálja a Scrapy-t, lehetővé téve a csomag által biztosított különféle osztályok használatát.
A következő sorban kiterjesztjük a Scrapy által biztosított Spider osztályt, és létrehozunk egy CloudSigmaCrawler nevű alosztályt. Egy osztály (Spider) kiterjesztésével hozzáférést kapunk az osztály tulajdonságaihoz, amelyeket most már használhatunk a kódunkban. Ebben az esetben a Spider osztály olyan metódusokkal és viselkedésekkel rendelkezik, amelyek meghatározzák, hogyan kell követni az URL-eket és adatokat kinyerni a weboldalakról. Azonban nem tudja, mely URL-eket kell követnie, vagy milyen adatokat kell kinyernie. A kiterjesztésével megadhatjuk a szükséges információkat a metódusoknak. Ha többet szeretne megtudni az alosztályok létrehozásáról és a kiterjesztésről, olvasson tovább Objektumorientált programozási elvek.
A CloudSigmaCrawler-ünkben meghatározzuk a szükséges attribútumokat. Először elnevezzük a spiderünket cloudsigma_crawler-nek. Ezután megadunk egyetlen URL-t, ahonnan elindulhat: https://blog.cloudsigma.com/blog/. Ennek az URL-nek a megnyitása a CloudSigma blog 1. oldalára viszi, amely tartalmaz néhányat a számos oktatóanyag közül.
Ideje tesztelni a scraper-t. Van néhány lehetősége. Ha IDE-t használ, például a PyCharm community edition a JetBrains-től, az valószínűleg tartalmaz egy gombot, amire kattintva futtathatja a szkriptet. Egy másik lehetőség a Python-fájlok parancssorból történő futtatásának tipikus módja: python path/to/file.py, vagy py path/to/file.py. Egy másik lehetőség a Scrapy parancssori felülete. A Scrapy saját parancssori felülettel rendelkezik, amely segít a scraper elindításában. Írja be a következő parancsot a scraper elindításához:
|
1 |
scrapy runspider main.py |
A telepített Scrapy könyvtár verziójától függően a következőhöz hasonló kimenetet kell látnia:
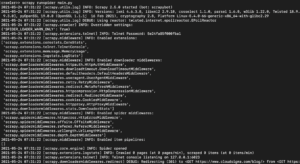
Mint látható, a kimenet meglehetősen hosszú, ezért csak néhány részt emeltünk ki. Íme, mi történt a parancs végrehajtásakor:
- A scraper inicializálva lett. Ezért betöltötte azokat a további összetevőket és kiterjesztéseket, amelyeket az URL-ek követéséhez és az adatok beolvasásához használnia kell.
- A start_urls listában megadott URL használatával lekérte a HTML-t az oldalról. Ez egy hasonló folyamat, mint amit a böngésző követ a weboldalak megnyitásakor.
- A HTML lekérése után az átadásra kerül a parse metódusnak, amelyet még nem definiáltunk. Egyelőre nem csinál semmit, így a spider egyszerűen kilép mindenféle feldolgozás nélkül. A parse metódus viselkedését a következő lépésben fogjuk meghatározni.
2. lépés: Adatok kinyerése egy oldalról
Az 1. lépésben csak egy alapvető scraper-t valósítottunk meg, amely lekér egy HTML-oldalt, de utána nem csinál semmit. Ebben a részben útmutatást adunk az adatok kinyeréséhez. A CloudSigma Blog oldalon, amelyről adatokat szeretnénk kinyerni, néhány dolgot észrevehet, mint például:
- A fejléc, amely minden oldalon jelen van.
- A navigációs menü és a keresőszűrő doboz.
- Az oktatóanyagok tényleges listája rács formátumban.
A lekaparni kívánt HTML-oldal forráskódjának megtekintése általános képet ad az oldal szerkezetéről. Ez segít a scraper megírásában. A forráskódot úgy tekintheti meg, ha jobb gombbal kattint az oldalra, és kiválasztja a Forráskód megtekintése lehetőséget, vagy megnyomja a Ctrl + U billentyűkombinációt. Íme egy részlet a forráskódból:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Állandó hivatkozás: "Apache biztosítása Let’s Encrypt-tel Ubuntu 18.04-en"">Apache biztosítása Let’s Encrypt-tel Ubuntu 18.04-en</a> </h2> </header> <div class="entry-content excerpt"> <p>A weboldal- és adatbiztonság olyan témák, amelyeket nem lehet félvállról venni. A rendkívül érzékeny információk, amelyek magukban foglalják a pénzügyi feljegyzéseket és az ügyfelek magánjellegű adatait, folyamatosan mozgásban vannak a felhasználó számítógépe és az Ön weboldala között. Ha figyelembe veszi ezt a tényt, nem nehéz belátni, hogy a nem biztonságos weboldalak miért vezethetnek olyan adatszivárgáshoz, amely komolyan károsíthatja vállalkozását. Létezik egy … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Tovább</a></div> </div> </div> ... </article> </div> </body> |
Amint látható, minden blog útmutató egy <article> nevű HTML tag-be van csomagolva. Az oldal lekaparása két lépésből áll majd. Az első lépés az egyes blog útmutatók kinyerése lesz az oldal azon részeinek megkeresésével, amelyek a kívánt adatokat tartalmazzák. A következő lépés a kívánt adatok kinyerése az egyes útmutatókból, amelyeket a HTML tag azonosít.
A Scrapy a megadott szelektorok alapján azonosítja a kinyerni kívánt adatokat. Szelektorok segítségével megtalálhatunk egy vagy több elemet az oldalon, és lekérhetjük a bennük lévő adatokat. A Scrapy támogatja az XPath és CSS szelektorokat.
A korábban megtekintett forráskód alapján a CSS szelektorok egyszerűbbnek tűnnek. Ezért ezt a lehetőséget választjuk, mivel ez segít megtalálni az oldalon található összes útmutatót. Az HTML forráskódból látható, hogy minden útmutató a post nevű CSS osztályon belül van meghatározva. A CSS osztályneveket általában .class_name (pont class_name) formátumban azonosítjuk. Így a .post-ot fogjuk használni CSS szelektorunkként. A main.py kaparó forráskódunkban átadjuk a .post osztályt a response objektumnak, így a fájl most így fog kinézni:
|
1 2 3 4 5 6 7 8 9 10 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): pass |
Ez a kódrészlet összegyűjti az összes oktatóanyagot az oldalon a megadott start_urls címmel, és végigmegy az oktatóanyagokon az adatok kinyeréséhez. A következő lépésben ki szeretné majd nyerni és megjeleníteni ezeket az adatokat. Ha újra megvizsgálja a CloudSigma blog forráskódját, látni fogja, hogy az egyes oktatóanyagok címe egy <a> tagen belül van tárolva, amely egy <h2> tagen belül található, például:
|
1 2 3 4 5 |
<h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04"">Securing Apache with Let’s Encrypt on Ubuntu 18.04</a> </h2> |
Minden egyes oktatóanyag-objektum, amelyen végighaladunk, tartalmaz egy CSS metódust, amelynek átadhatunk egy szelektorokat a gyermekelemek megkereséséhez és kinyeréséhez. Ebben a példában a címet szeretnénk kinyerni, amely az <a> tagen belül található. Ez a tag a <h2> tagen belül, az .entry-header osztályon belül, az .entry-wrap osztályon belül van. Ezeket a CSS szelektorokat átadhatjuk az objektum metódusának a cím kinyeréséhez, módosítsa a kódot az alábbiak szerint:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), } |
Az extract_first() utáni záró vessző nem elírás, mivel a szakasz alá további kódokat fogunk hozzáadni.
Néhány megjegyzendő pont a fenti forráskódból:
- ::text a szelektorhoz fűzve – ez egy CSS álszelektor , amely arra utasítja a kódot, hogy a tagen belüli szöveget kérje le, ne pedig magát a taget.
- extract_first() metódushívás az objektumon belül – arra utasítja a kódot, hogy csak az első olyan elemet válassza ki, amely illeszkedik a szelektorra. Így egy karakterláncot kapunk az elemek listája helyett.
Ezután mentse el a fájlt, és futtassa a kódot a következő parancs beírásával a terminálba:
|
1 |
scrapy runspider main.py |
A kimenetben az útmutatók címeit kell látnia:
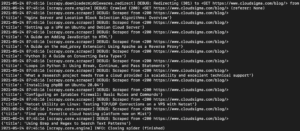
Ezt tovább bővíthetjük újabb szelektorok hozzáadásával, hogy az útmutató egyéb részleteit is kinyerjük, mint például az útmutató URL-címét, kiemelt képét és feliratát.
Vizsgáljuk meg újra egyetlen útmutató HTML-kódját:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<body> <div id="x-iso-container" class="x-iso-container x-iso-container-posts cols-3"> <article id="post-51691" class="post-51691 post type-post status-publish format-standard has-post-thumbnail hentry category-blog-posts category-tutorials tag-apache tag-certbot tag-cloud-guide tag-cloud-tutorial tag-https tag-lets-encrypt tag-ssl tag-ssl-certification tag-tutorial tag-ubuntu"> <div class="entry-featured"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="entry-thumb" title="Permalink to: "Securing Apache with Let’s Encrypt on Ubuntu 18.04""> <img width="1000" height="522" src="data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%201000%20522'%3E%3C/svg%3E" class="attachment-entry-fullwidth size-entry-fullwidth wp-post-image" alt="Let’s Encrypt" loading="lazy" data-lazy-srcset="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg 1000w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-300x157.jpg 300w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-768x401.jpg 768w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-610x318.jpg 610w, /media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04-100x52.jpg 100w" data-lazy-sizes="(max-width: 1000px) 100vw, 1000px" data-lazy-src="/media/wp-content/uploads/How-To-Secure-Apache-with-Lets-Encrypt-on-Ubuntu-18.04.jpg"/> </a> </div> <div class="entry-wrap"> <header class="entry-header"> <h2 class="entry-title"> <a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" title="Állandó hivatkozás ide: "Az Apache biztosítása Let’s Encrypt-tel Ubuntu 18.04-en"">Az Apache biztosítása Let’s Encrypt-tel Ubuntu 18.04-en</a> </h2> </header> <div class="entry-content excerpt"> <p>A weboldal- és adatbiztonság olyan témák, amelyeket nem lehet félvállról venni. A rendkívül érzékeny információk, amelyek pénzügyi feljegyzéseket és az ügyfelek magánjellegű adatait is magukban foglalják, folyamatosan mozgásban vannak a felhasználó számítógépe és az Ön weboldala között. Ha ezt a tényt figyelembe vesszük, nem nehéz belátni, hogy a nem biztonságos weboldalak olyan biztonsági rést eredményezhetnek, amely komolyan károsíthatja vállalkozását. Számos … </p> <div><a href="https://blog.cloudsigma.com/securing-apache-with-lets-encrypt-on-ubuntu-18-04/" class="more-link">Olvass tovább</a></div> </div> </div> </article> </div> </body> |
Szeretnénk megpróbálni kinyerni a kiemelt részeket, azaz a leírás URL-jét, a kiemelt képet és a képaláírást.
- A fenti kódrészletből látható, hogy a blog képe egy <a> tagen belüli img tag data-lazy-src attribútumában van tárolva, egy div tagen belül a blogútmutató elején. Használhatunk egy CSS-szelektort az érték kinyeréséhez, ahogy azt a leírások címeivel is tettük.
- A leírás URL-jének lekérése egyszerű, mivel az <a> tag a <div> elemen belül található.
- A képaláírás a <p> tagen belül található, amely a <div> tagen belül van.
A CSS-osztályokat fogjuk használni, hogy megkapjuk, amit szeretnénk. Módosítsuk a kódot úgy, hogy így nézzen ki:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } |
Mentse el a változtatásokat, és futtassa a kódot a következő paranccsal:
|
1 |
scrapy runspider main.py |
Több adatot fog látni a kimenetben, például a hozzáadott URL-t, képet és feliratot:

Ennyi egyetlen oldal bejárása. Ezután lássuk, hogyan hozhatunk létre olyan crawlert, amely követi a linkeket.
3. lépés: Hogyan járjunk be több oldalt
Eddig a pontig egy olyan crawlert hoztunk létre, amely egyetlen oldalról képes adatokat gyűjteni. Mi azonban ennél többet szeretnénk. Olyan spidert szeretne, amely képes követni a linkeket, és programozottan kinyerni az adatokat egy webhely több oldaláról.
Ha a CloudSigma blogoldal aljára lép, észre fogja venni az oldalszámozási linkeket és egy kis jobbra mutató nyilat, amely a következő oldalt jelzi. Íme a HTML-kódrészlet:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">Page 1 of 45</span></li> <li></li> <li><span class="current">1</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="single_page" title="2">2</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Last Page">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/2/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
A kódrészlet több oldalnavigációs linket mutat az <li> tageken belül, a .x-pagination CSS-osztállyal rendelkező <div> tag alatt. Mi a következő oldalra mutató linkre összpontosítunk. Ez az <ul> tag utolsó <li> tagjének <a> tagjében található.
A következő oldalra mutató link a .prev-next osztállyal rendelkezik az <a> tagen belül, amint az a fenti kódrészletben látható. Ha azonban a következő oldalra lép, azt is észre fogja venni, hogy az előző és a következő oldalra mutató linkek is ezzel a CSS-osztállyal rendelkeznek. Tekintse meg ezt a kódrészletet a 2. oldalhoz:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<div class="x-pagination"> <ul class="center-list center-text"> <li><span class="pages">2. oldal a 45-ből</span></li> <li><a href="https://blog.cloudsigma.com/blog/" class="prev-next hidden-phone">←</a></li> <li><a href="https://blog.cloudsigma.com/blog/" class="single_page" title="1">1</a></li> <li><span class="current">2</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="single_page" title="3">3</a></li> <li><span class="expand">...</span></li> <li><a href="https://blog.cloudsigma.com/blog/page/45/" class="last" title="Utolsó oldal">45</a></li> <li><a href="https://blog.cloudsigma.com/blog/page/3/" class="prev-next hidden-phone">→</a></li> </ul> </div> |
Ha a Scrapy extract_first() metódusát használjuk, az az első oldalon működni fog. Amikor eléri a következő oldalt, a .prev-next osztállyal rendelkező első linket fogja kiválasztani, amely a fenti kódrészletben az első oldalra mutat. Ez egy végtelen ciklust eredményez. Ezért a Scrapy extract() metódusát fogjuk használni. Ez a metódus kinyeri az összes olyan elemet, amely megfelel egy adott használati esetnek, és egy tömbbe helyezi őket. Ebből a tömbből kiválaszthatjuk az utolsó elemet, amely a következő oldalra mutató tényleges linket fogja tartalmazni. Módosítsa a kódot az alábbiak szerint:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Menjünk végig a next_page kiválasztásához tartozó kódon.
Először meghatározunk egy szelektor a következő és az előző oldal linkjeihez. Ezután az extract() metódust használjuk az URL-ek kinyerésére és egy tömbbe helyezésére. A next_page változó egy két elemből álló tömb lesz, például így:
|
1 |
next_page = [prev_page_url, next_page_url] |
Mivel a következő oldalra navigálunk, a tömb utolsó elemét fogjuk választani. A next_page[-1] a tömb utolsó elemét választja ki.
Az if blokk ellenőrzi, hogy a next_page változó tartalmaz-e valamit, majd meghívja a scrapy.Request() metódust. A kódunkban arra utasítjuk ezt a metódust, hogy térképezze fel a megadott URL-lel rendelkező oldalt, és adja vissza a parse() metódusnak, hogy elemezni tudjuk az adatok kinyeréséhez, majd megismételjük a folyamatot a következő oldalon. Ez a folyamat addig ismétlődik, amíg nem talál linket a következő oldalra, vagy pontosabban, ha a blokk sikertelen, akkor leáll.
Mentse el a kódot, és futtassa. Észre fogja venni, hogy az iteráció folytatja az oldalak bejárását, ahogy újabb lekaparható oldalakat talál. Így határozhat meg egy olyan scraper-t, amely követi a linkeket egy weboldalon. A példánk meglehetősen egyszerű. Csak elmegyünk egy oldalra, megkeressük a következő oldalra mutató linket, és megismételjük a folyamatot. Más felhasználási esetekben előfordulhat, hogy külső forrásokra mutató címkéket vagy linkeket szeretne követni, és így tovább. Íme a Python 3 alapvető web scraper teljes forráskódja:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import scrapy class CloudSigmaCrawler(scrapy.Spider): name = "cloudsigma_crawler" start_urls = ['https://blog.cloudsigma.com/blog'] def parse(self, response): SET_SELECTOR = '.post' for tutorial in response.css(SET_SELECTOR): NAME_SELECTOR = '.entry-wrap .entry-header > h2 > a ::text' URL_SELECTOR = '.entry-featured > a ::attr(href)' IMG_SELECTOR = 'img ::attr(data-lazy-src)' CAPTION_SELECTOR = '.entry-content > p::text' yield { 'title': tutorial.css(NAME_SELECTOR).extract_first(), 'image': tutorial.css(IMG_SELECTOR).extract_first(), 'url': tutorial.css(URL_SELECTOR).extract_first(), 'caption': tutorial.css(CAPTION_SELECTOR).extract_first(), } NEXT_PAGE_SELECTOR = '.x-pagination > ul.center-list > li > a.prev-next::attr("href")' next_page = response.css(NEXT_PAGE_SELECTOR).extract() if next_page: yield scrapy.Request( response.urljoin(next_page[-1]), callback=self.parse ) |
Összegzés
Ebben az útmutatóban egy olyan alapvető webes adatkaparót építettünk fel, amely képes bejárni a CloudSigma blog könyvtárat, és mindössze körülbelül 27 sornyi kódban jelenít meg néhány információt a blog útmutatóiról.
Ez természetesen azért lehetséges, mert a Scrapy Python könyvtárra építettük. Ez csak egy alap, amely segíthet összetettebb kaparók készítésében, amelyek több címkét, webhelyek keresési eredményeit és egyebeket követnek. Megtekintheti a Scrapy hivatalos dokumentációját a Scrapy használatával kapcsolatos további információkért.
Kellemes számítástechnikát!
Hozzászólások
Még nincsenek hozzászólások. Legyen Ön az első.