

A CloudSigma lehetővé teszi az ügyfelek számára, hogy GPU-kat adjanak virtuális gépeikhez, és olyan nagy teljesítményű, költséghatékony számítástechnikát használjanak, amely a legigényesebb munkaterheléseknek is megfelel. A CloudSigma GPU-kínálatának szíve a HPC-re, AI-ra és adatelemzésre optimalizált NVIDIA A100 Tensor Core GPU. Az A100 felülmúlja az NVIDIA TESLA V100-at, és olyan új funkciókkal rendelkezik, amelyeket az AI-alkalmazások teljes mértékben kihasználhatnak. Lehetővé tesszük az ügyfelek számára, hogy könnyen optimalizált NVIDIA A100 VM-eket építsenek passthrough módban, így a VM-példányok közvetlen vezérléssel rendelkeznek a GPU(k) és azok beépített memóriája felett.
Felhasználási esetek
A felhőben futó számításigényes alkalmazások növekedése ösztönözte a GPU-gyorsított felhőalapú számítástechnika közelmúltbeli robbanásszerű növekedését. Ezek az alkalmazások magukban foglalják az AI mélytanulási betanítást és következtetést (inference), az adatelemzést, a tudományos számításokat, a genomikát, a grafikai renderelést és a játékokat, hogy csak néhányat említsünk. Az AI-betanítás és a tudományos számítások felskálázásától (scale-up) a következtetési alkalmazások horizontális skálázásáig (scale-out) a valós idejű társalgási AI lehetővé tételéig a GPU-k biztosítják a szükséges teljesítményt a felhőben futó számos összetett és kiszámíthatatlan munkaterhelés felgyorsításához.
Az NVIDIA A100 Tensor Core GPU óriási lépést jelent előre, példátlan gyorsulást biztosítva az AI, az adatelemzés és a HPC számára minden léptékben. Az NVIDIA Ampere architektúrára épülő A100 akár 20-szor nagyobb teljesítményt nyújt, mint az előző generáció. A CloudSigma elérhetővé teszi a 80 GB-os memória-verziót, amely a világ leggyorsabb, másodpercenként több mint 2 terabájtos (TB/s) sávszélességét biztosítja a legnagyobb modellek és adatkészletek futtatásához.
Az NVIDIA GPU-k a vezető számítási motorok közé tartoznak, amelyek az AI-t hajtják, jelentős gyorsulást biztosítva az AI-betanítási és következtetési munkaterhelésekhez. Emellett az NVIDIA GPU-k számos típusú HPC és adatelemző alkalmazást és rendszert gyorsítanak fel, az adatokat felismerésekké alakítva.
AI és HPC
Tanítson összetett gépi tanulási modelleket gyorsabban és hatékonyabban a GPU-gyorsítással. Birkózzon meg az adatintenzív feladatokkal, és érjen el áttöréseket az AI-vezérelt innovációban. Az NVIDIA AI Enterprise egy végpontok közötti, felhőalapú AI- és adatelemző szoftvercsomag, amelyet úgy optimalizáltak, hogy bármely szervezet számára lehetővé tegye az AI használatát. Tanúsítvánnyal rendelkezik a nyilvános felhőben való üzembe helyezéshez, és globális vállalati támogatást tartalmaz az AI-projektek megfelelő mederben tartásához. Az A100 lehetővé teszi a kutatók számára, hogy gyorsan valós eredményeket érjenek el, és a megoldásokat nagy léptékben üzembe helyezzék a termelésben.
MÉLYTANULÁSI BETANÍTÁS
Az AI-modellek betanítása hatalmas számítási kapacitást és skálázhatóságot igényel. A Tensor Float (TF32) technológiával ellátott NVIDIA A100 Tensor Core-ok akár 20-szor nagyobb teljesítményt nyújtanak az NVIDIA Volta-hoz képest kódmódosítás nélkül, és további 2-szeres növekedést az automatikus vegyes pontosság (mixed precision) és az FP16 révén.
Egy olyan betanítási munkaterhelést, mint a BERT, 2048 darab A100 GPU kevesebb mint egy perc alatt képes megoldani nagy léptékben, ami világrekord a megoldási idő tekintetében.
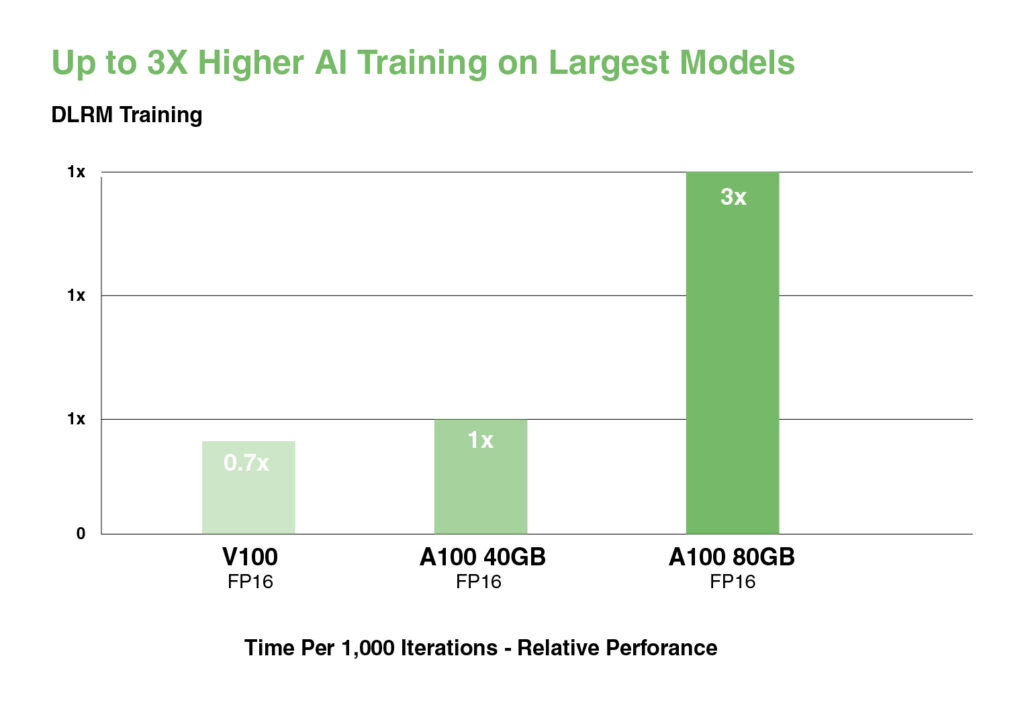
A hatalmas adattáblákkal rendelkező legnagyobb modellek, például a mélytanulási ajánlómodellek (DLRM) esetében az A100 80GB csomópontonként akár 1,3 TB egyesített memóriát is elér, és akár 3-szoros átviteli növekedést biztosít az A100 40GB-hoz képest.
Az NVIDIA piacvezető szerepe az MLPerf-ben, több teljesítményrekordot felállítva az iparági szintű AI-betanítási teljesítménymérésben.
MÉLYTANULÁSI KÖVETKEZTETÉS
Az A100 úttörő funkciókat vezet be a következtetési (inference) munkaterhelések optimalizálására. A pontosság teljes tartományát felgyorsítja az FP32-től az INT4-ig. A Multi-Instance GPU (MIG) technológia lehetővé teszi, hogy több hálózat működjön egyidejűleg egyetlen A100-on a számítási erőforrások optimális kihasználása érdekében. A strukturális ritkaság (structural sparsity) támogatása pedig akár 2-szer nagyobb teljesítményt nyújt az A100 egyéb következtetési teljesítménynövekedésein felül.
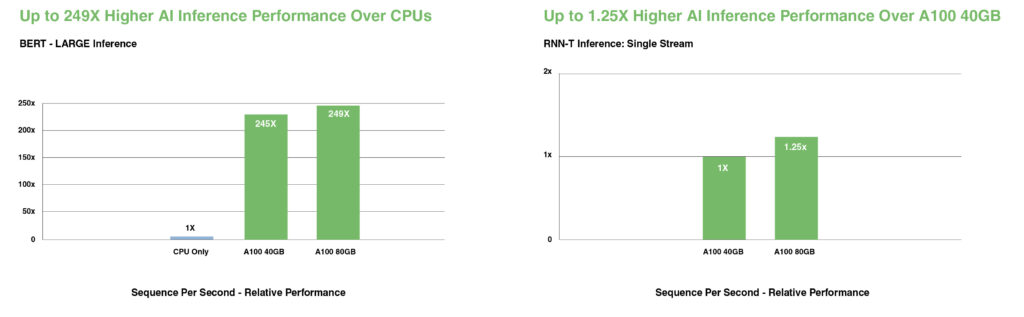
A legmodernebb társalgási AI-modelleken, mint például a BERT, az A100 akár 249-szeresére gyorsítja fel a következtetési átviteli sebességet a CPU-khoz képest.
A legösszetettebb, kötegméret-korlátos (batch-size constrained) modelleknél, mint például az automatikus beszédfelismerésre szolgáló RNN-T, az A100 80GB megnövelt memóriakapacitása megduplázza az egyes MIG-ek méretét, és akár 1,25-ször nagyobb átviteli sebességet biztosít az A100 40GB-hoz képest.
Az NVIDIA piacvezető teljesítménye bemutatkozott az MLPerf Inference-ben is. Az A100 20-szor nagyobb teljesítményt nyújt, hogy tovább erősítse ezt a vezető szerepet.
NAGY TELJESÍTMÉNYŰ SZÁMÍTÁSTECHNIKA
A következő generációs felfedezések elérése érdekében a tudósok szimulációk segítségével igyekeznek jobban megérteni a minket körülvevő világot.
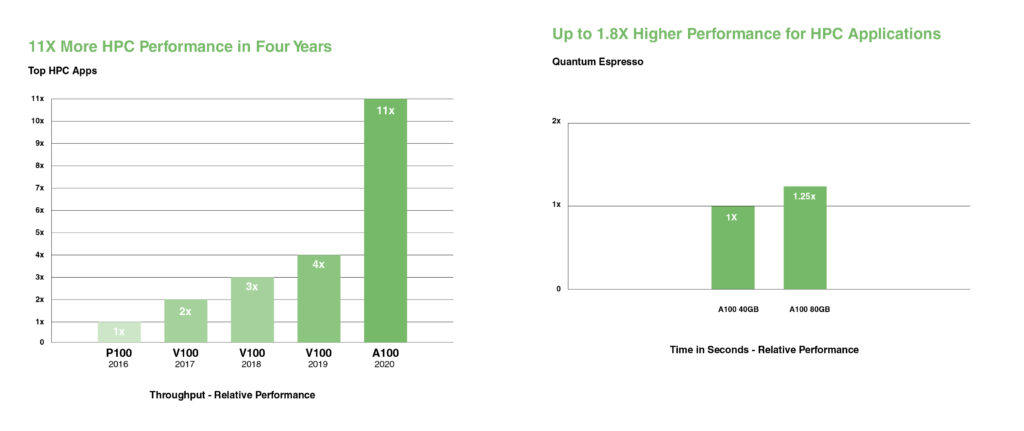
Az NVIDIA A100 bemutatja a kétszeres pontosságú Tensor Cores technológiát, amely a GPU-k bevezetése óta a legnagyobb ugrást jelenti a HPC-teljesítményben. A leggyorsabb, 80 GB-os GPU-memóriával a kutatók egy 10 órás, kétszeres pontosságú szimulációt kevesebb mint négy órára csökkenthetnek az A100-on. A HPC-alkalmazások a TF32 segítségével akár 11X nagyobb átviteli sebességet érhetnek el az egyszeres pontosságú, sűrű mátrixszorzási műveleteknél.
A legnagyobb adatkészletekkel rendelkező HPC-alkalmazások esetében az A100 80GB extra memóriája akár 2X-es átviteli sebességnövekedést biztosít a Quantum Espresso anyagszimulációval. Ez a hatalmas memória és a példátlan sávszélesség teszi az A100 80GB-ot a következő generációs munkaterhelések ideális platformjává.
NAGY TELJESÍTMÉNYŰ ADATELEMZÉS
Az adatkutatóknak képesnek kell lenniük a hatalmas adatkészletek elemzésére, vizualizálására és hasznos információkká alakítására. A horizontálisan skálázható (scale-out) megoldásokat azonban gyakran lelassítják a több szerveren szétszórt adatkészletek.
Az A100-zal gyorsított szerverek biztosítják a szükséges számítási teljesítményt – hatalmas memóriát, több mint 2 TB/sec memóriasávszélességet, valamint az NVIDIA® NVLink® és NVSwitch™ segítségével történő skálázhatóságot – ezen munkaterhelések kezeléséhez. Az InfiniBand, az NVIDIA Magnum IO™ és a RAPIDS™ nyílt forráskódú könyvtárcsomaggal (beleértve a GPU-gyorsított adatelemzéshez használható RAPIDS Accelerator for Apache Spark szoftvert) kombinálva az NVIDIA adatközponti platformja példátlan teljesítmény- és hatékonysági szinten gyorsítja fel ezeket a hatalmas munkaterheléseket.
Egy big data elemzési benchmarkon az A100 80GB 2X-es növekedést ért el az adatok kinyerésében az A100 40GB-hoz képest, így ideálisan alkalmas a robbanásszerűen növekvő adatkészlet-méretű, új típusú munkaterhelésekhez.
TUDOMÁNYOS SZIMULÁCIÓK: Gyorsítsa fel a tudományos kutatásokat és szimulációkat, lehetővé téve a gyorsabb felismeréseket és felfedezéseket a fizika, a kémia és a környezettudomány területén.
MÉDIA ÉS SZÓRAKOZTATÁS: Rendereljen nagy felbontású grafikákat, videókat és animációkat villámgyorsan. Nyújtson kivételes vizuális élményt közönségének a minőség feláldozása nélkül.
PÉNZÜGYI MODELLEZÉS: Elemezzen hatalmas adatkészleteket és végezzen összetett pénzügyi modellezést páratlan sebességgel, kritikus fontosságú információkat biztosítva a megalapozott döntéshozatalhoz.
Hozzászólások
Még nincsenek hozzászólások. Legyen Ön az első.